机器学习(2)--sklearn库写决策树(分类树)
目录
一、决策树概述
二、sklearn建立决策树
1、sklearn.tree模块
2、DecisionTreeClassfier
2.1重要参数
2.2criterion
3、红酒数据集建立决策树
3.1导入库
3.2根据数据集中任意三个特征,绘制Axes3D图
3.3建立决策树
3.4graphviz画决策树
3.5利用不同属性剪枝
3.6clf的重要接口
注
一、决策树概述
决策树是一种非参数的监督学习方法,能够从一系列有特征和标签的数据中,总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。决策树算法易于理解,并适用于跟中数据在解决各种问题时都有良好表现。
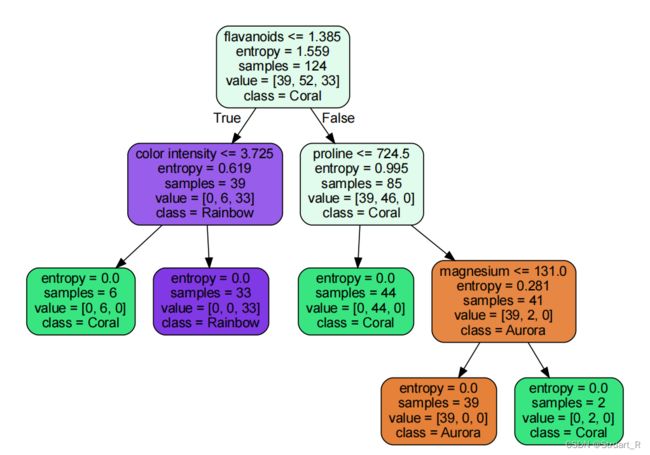 基于红酒数据集的决策树
基于红酒数据集的决策树
决策树作为一种树形结构,由根节点,分支,叶节点构成。上图基于红酒数据集的13个属性建立决策树,以entropy(信息熵)作为唯一的不再分支的结束条件。
决策树最核心的两个问题:如何从数据集中找出最佳结点和最佳分枝?如何让决策树停止分支,防止过拟合?
二、sklearn建立决策树
1、sklearn.tree模块
| tree.DecisionTreeClassifier | 分类树 |
| tree.DecisionTreeRegressor | 回归树 |
| tree.export.graphviz | 生成决策树DOT格式,画图 |
| tree.ExtraTreeClassifier | 高随机的分类树 |
| tree.ExtraTreeRegressor | 高随机的回归树 |
分类树的基本代码模型:
from sklearn import tree #导入sklearn.tree模块
clf=tree.DecisionTreeClassfier() #分类树实例化
clf=clf.fit(x_train,y_train) #训练集训练模型
score=clf.score(x_test,y_test) #导入测试集,获取acc值2、DecisionTreeClassfier
sklearn.tree._classes.DecisionTreeClassifier
def __init__(self,
*,
criterion: Any = "gini",
splitter: Any = "best",
max_depth: Any = None,
min_samples_split: Any = 2,
min_samples_leaf: Any = 1,
min_weight_fraction_leaf: Any = 0.0,
max_features: Any = None,
random_state: Any = None,
max_leaf_nodes: Any = None,
min_impurity_decrease: Any = 0.0,
class_weight: Any = None,
ccp_alpha: Any = 0.0) -> None
2.1重要参数
| criterion | 用来衡量分枝质量的指标,不纯度指标,输入“entropy”为信息增益,“gini”为基尼系数 |
| splitter | 确定每个节点的分枝策略,输入“random”为最佳随机分枝,“best”为最佳分枝 |
| random_state | 类似于random.seed,随机生成树种子 |
| max_depth | 树的最大深度,默认为None,即生成树所有叶节点不纯度为0,或者直到每个叶节点的所含样本量均小于参数min_samples_split值 |
| min_samples_split | 一个中间结点要分枝为所需要的最小样本量,如果一个节点包含的样本量小于min_samples_split值,则该节点的分枝不会发生。 默认=2,可填整型或浮点型 输入的为浮点型作为分枝比例,即分枝所需最小样本量:输入模型数据集的样本量。 |
| min_sample_leaf | 一个叶节点要存在所需要的最小样本量,如果一个节点在分枝后的每个子节点中,必须包含至少min_sample_leaf个训练样本,否则该结点不能分枝。 默认=1,可填整型或浮点型 输入的为浮点型作为分枝比例,即分枝后叶节点所需最小样本量:输入模型数据集的样本量。 |
min_impurity_decrease |
最小不纯度差,即根节点不纯度值与叶子结点的不纯度值至少为min_impurity_decrease值 |
2.2criterion
决定不纯度的计算方法在sklearn中有两种:
(1)输入"entropy",使用信息熵
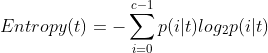
(2)输入"gini",使用基尼系数

信息熵对不纯度更加敏感,对不纯度惩罚最强。但在实际使用中,两者效果基本相同。
信息熵计算比基尼系数缓慢,对于涉及高维数据或者噪音很多的数据,信息熵很容易过拟合,而基尼系数的效果更好,但不是绝对的。
3、红酒数据集建立决策树
3.1导入库
sklearn下载时一定要写scikit-learn,而非sklearn.
from sklearn import tree #导入tree库
from sklearn.datasets import load_wine #导入红酒数据集
from sklearn.model_selection import train_test_split #导入数据集分割模块3.2根据数据集中任意三个特征,绘制Axes3D图
import matplotlib.pyplot as plt #导入plt库和Axes3D库
from mpl_toolkits.mplot3d import Axes3D
wine=load_wine() #红酒数据集
X = wine['data']
y = wine['target']
# 选取三个特征查看wine数据分布
ax = Axes3D(plt.figure())
for c, i, target_name in zip('>o*', [0, 1, 2], wine.target_names):
ax.scatter(X[y == i, 0], X[y == i, 1], X[y == i, 2], marker=c, label=target_name)
ax.set_xlabel(wine.feature_names[0])
ax.set_ylabel(wine.feature_names[1])
ax.set_zlabel(wine.feature_names[2])
ax.set_title("wine")
plt.legend()
plt.show()
3.3建立决策树
clf=tree.DecisionTreeClassifier(criterion="entropy" #gini和entropy
,random_state=30 #类似于seed的随机种子
,splitter="best" #best(会选择更重要的特征进行分枝)
#,max_depth=3 #最大深度为3,根节点为0
#,min_samples_leaf=10 #叶节点样本数至少为10
#,min_samples_split=30 #结点样本大于等于30才能分枝
#,min_impurity_decrease=0.01 #最小信息增益为0.01,即两层之间结点的信息熵或gini的差为0.01
)
clf=clf.fit(Xtrain,Ytrain)
score=clf.score(Xtest,Ytest)
print(score) #输出acc值3.4graphviz画决策树
graphviz安装代码(0.8.4版本):
conda install python-graphvizgraphviz画图会出现中文乱码,尽量使用英文。
import graphviz
feature_name = ['alcohol','malic-acid','ash','alcalinity of ash','magnesium','total phenols','flavanoids','noflavanoid phenols','proanthocyanins','color intensity','hue','od280/od315ofdiluted wines','proline']
dot_data=tree.export_graphviz(clf
,feature_names=feature_name
,filled=True
,rounded=True
,class_names=["Aurora","Coral","Rainbow"]
)
graph=graphviz.Source(dot_data)
graph.view()
3.5利用不同属性剪枝
当max_depth(即样本集某一属性)随次数增加而acc值不在变化时,该参数值最优。
可以利用这一方式对过大的决策树,基于多个决策树参数进行剪枝。
#以max_depth作为x,acc作为y,建立图像
score_list=[]
for i in range(20):
clf=tree.DecisionTreeClassifier(criterion="gini"
,splitter="best"
,random_state=20
,max_depth=i+1
)
clf=clf.fit(Xtrain,Ytrain)
score=clf.score(Xtest,Ytest)
score_list.append(score)
plt.plot(range(1,21),score_list,color='r',label='max_depth')
plt.grid()
plt.show()3.6clf的重要接口
clf.feature_importances_ #返回测试集不同特征对决策树的重要性
clf.predict(Xtest) #返回每个测试集样本所在叶子结点的索引
clf.apply(Xtest) #返回每个测试样本的分类结果