Python爬虫何如抓包?这三个案例手把手教会你,非常详细...
文章目录
- 哔,老年卡
- 某牙直播抓包
- 某博抓包
- 某手短视频抓包
哔,老年卡
很多小伙伴总是问我,数据来源怎么找啊,怎么抓包,其实很简单,多操作几遍就记住了。
今天咱们通过三个案例来展示一下
某牙直播抓包
首先咱们进入目标网页,随便找一个视频,通过开发者工具抓包分析。
首先按F12或者点击右键选择检查,打开开发者工具,依次选择 network(网络面板) → AII (全部)
然后刷新网页,让当前网页内容重新加载出来。

以前是可以直接选择 media (媒体文件)就能看到了,现在不行了,所以说,互联网更新迭代很快,网站经常更新,技术也需要时刻准备更新,我们也是学习不能停,一停就落伍。

但是刷新后的数据太多,我们如何确定哪一条是咱们的目标呢?
以当前某牙为例, 视频改成了m3u8格式,它会把完整视频分成很多个视频片段,这些ts文件都是m3u8格式视频片段。

我们把URL复制到新窗口打开,它就直接把片段下载下来了。

我们完整的视频是2.26分,但是每一个片段只有几秒钟。
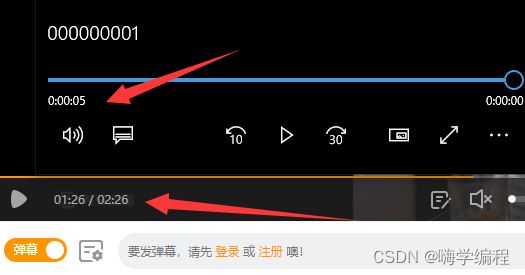
那么计算一下,平均一个五秒,2.26分差不多要17个视频,还得自己手动合并,多麻烦。
但是它有一个专门的m3u8格式的文件,保存了所有的ts文件内容。
我们直接点击左上角搜索框,直接搜索 m3u8 ,然后看到一个get开头的文件,点击它,再点击preview (预览数据) ,视频的标题等信息都可以看到。
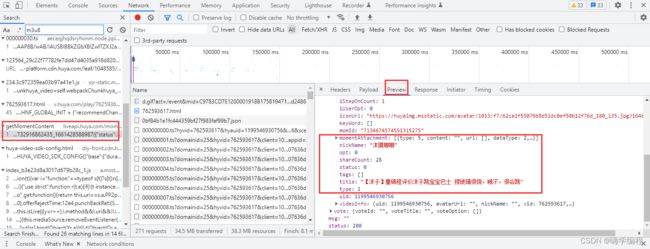
找到这个 definitions 展开 ,m3u8的视频就在里面了,原画、超清、流畅。
可以看到,它也有完整的url地址在这,可以直接用。

我都注释一下吧
这是直播视频的数据查找方式
接下来看看微博视频
某博抓包
第一步详细介绍,后面就不做太多截图一一展示了,只展示大概流程了,所以如果忘了,建议多看看第一步的,当然,两个网站之间不一样的地方,我都会一一截图展示。
确定目标网址,打开一个视频播放页面。


有点过份暴露,这是我没想到的,简单的打个码。
按F12 打开开发者工具,点击network 点击Aii ,刷新网页。
然后此时发生了一件愉快的事情
刷新一下视频不见了,于是我又去搜博主名字
啊这
我太南了,算了 ,换一个吧…
编辑推荐的每一个都很给力,我先用第四个给你们展示吧,展示完,我再都去看一遍

好了,咱们言归正传。
对于绝大部分网站来说,他的第一个数据包就是当前网页。除了一少部分特殊网址不一样。
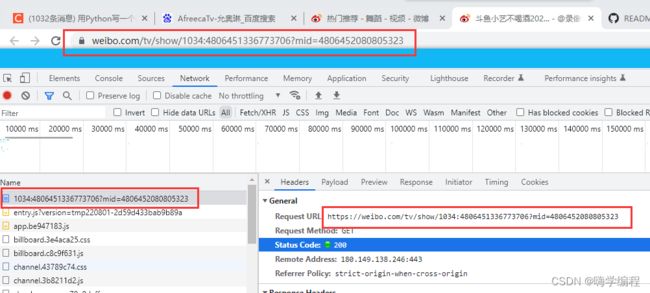
今天的目标它的视频不一定在第一个网页源代码中,即使复制了url能进入,也还是不一定在。
因为有一些数据,它是会动态加载的,或者说不在同一个数据包里面。
第二种方法,我们把当前目标的标题复制到搜索框,然后回车,当然,也有可能搜不到。
第三种方法,我们直接点击 fetch/XHR 动态数据抓包,这里面是实时加载的。
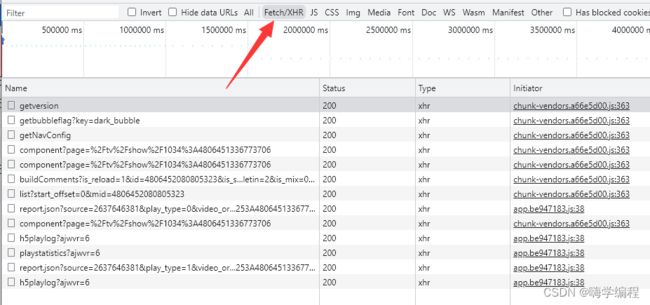
我真的会谢,视频又没了…
算了,我再找新的吧。
我们可以看到,左边有那么多数据,那么谁才是我们需要的呢?
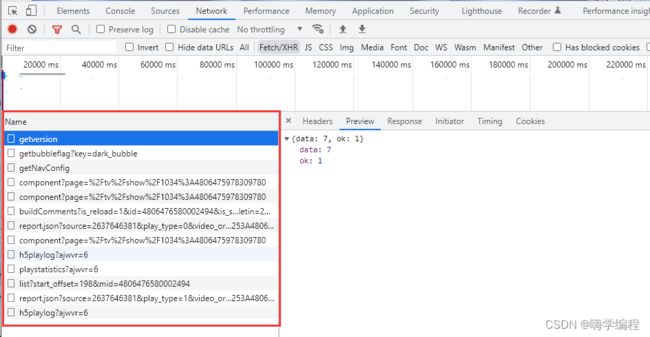
这时候需要我们一个个点,一般是这两个,有时候也不一定,所以需要一个个点。
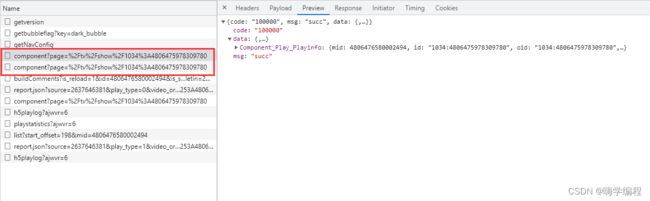
然后点击右边的倒三角,一一展开,往下拉,找到这个urls,就可以看到视频地址了,各个清晰度的都有。
 然后视频的ID 、标题等等都在这里。
然后视频的ID 、标题等等都在这里。
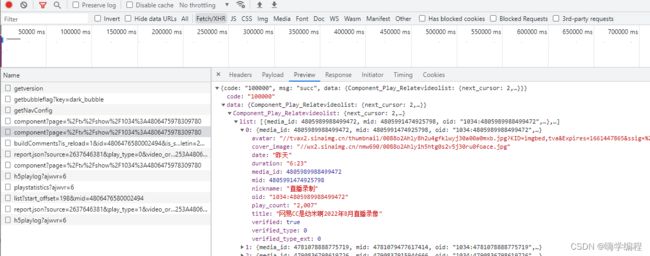
为什么说要一个个点,你看这两个长得一样的, 我刚刚点的是第一个,现在看看第二个。
这里面都是右边推荐栏的封面,标题,视频id等等。
某手短视频抓包
接下来来到某手,这次咱们正经一点,找个正经的视频来示范。

emmm … 这个正经多了,我们直接进入主页。
还是一样的操作,打开开发者工具,点开network,刷新,选择AII 。
这次咱们直接复制这个小姐姐的名字搜索
搜索之后,这里有两个一样的选项,咱们需要一个个点击打开看看,确定哪一个是咱们需要的。
一个是博主的ID简介等等,另外一个就是视频的数据了。
这里我直接点第一个graphql → preview 总共是21个视频,可以看到,下图最下方的protourl就是视频的url,photoH265Url 则是音频url 。
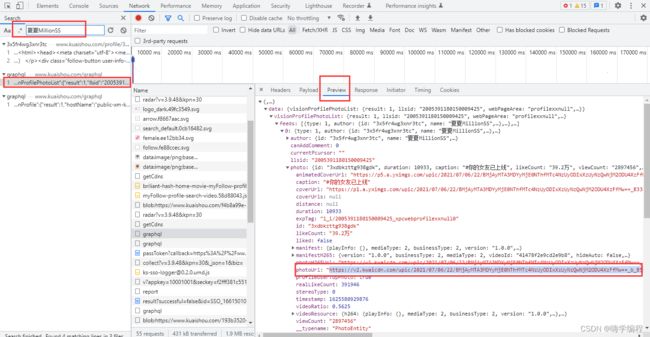
为什么只有21个?因为没加载出来,刷新后默认只给你加载那么多,所以爬的时候,可以用selenium自动翻页,就能自己加载了。
最后给大家推荐一套视频正好实战一下:代码总是学完就忘记?100个爬虫实战项目!让你沉迷学习丨学以致用丨下一个Python大神就是你!
好了,兄弟们,今天的分享就到这里,思古白~