深入理解group by报错注入
文章目录
- 深入理解group by报错注入
-
- 一、理解floor,group by +count(*),rand,count函数的作用
-
- 1.group by+count(*)
- 2.rand()
- 3.floor()
- 4.count()返回指定列的值的数量
- 5.floor(rand()*2)
- 二、group by分组的原理
- 三、group by报错注入
-
- group by报错原理:
深入理解group by报错注入
users表中的数据

一、理解floor,group by +count(*),rand,count函数的作用
1.group by+count(*)
group by 主要用来对数据进行分组(相同的分为一组)。

2.rand()
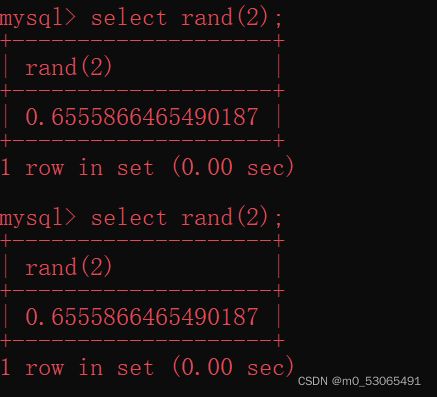
rand函数用于产生一个0到1之间的随机数

注意:当调用一个整数参数时,rand()使用该随机数发生器种子值。每次在给定值种子生成,RAND()会产生一个可重复的一系列数字
例如:
3.floor()
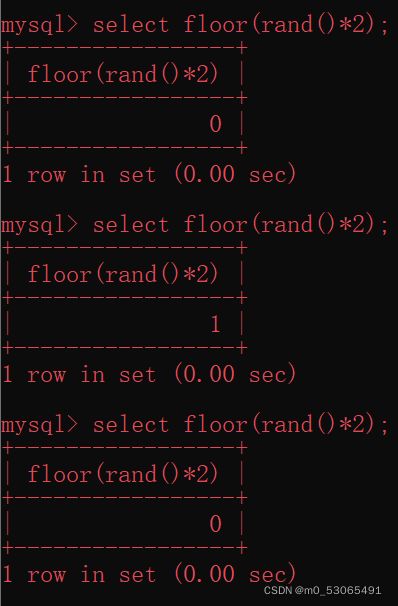
floor()用于向下取整

*rand()2代表了随机数范围是0-2
4.count()返回指定列的值的数量
5.floor(rand()*2)
*rand()2生成0-2之间的数,floor()向下取整,意思就是取出一组不固定的0或者1

**floor(rand(0)2),与floor(rand()2)不同的是,前者加了种子值,那么前者生成的就是一组固定的0或者1

二、group by分组的原理
首先先看两个查询语句之间的区别
select username,count(*) from username group by username;
select username,count(*) from username group by "username";
1.select username,count(*) from username group by username;

2.select username,count(*) from username group by "username";
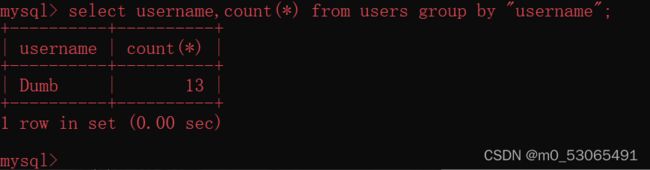
第一条查询语句原因是由于group by在分组时,会依次取出查询表中的记录并创建一个临时表(表中有两个字段,分别是key和count()),group by的对象就是该临时表的主键。如果临时表中已经存在该主键,则count()的值+1,如果表中不存在则将主键插入到临时表中。例如:group by username时,取username字段的第一个值admin,这使会在临时表中的主键key中查询admin这条数据,如果找到就使count()值加1,如果没找到就插入admin,并让count()加1
第二条group by的对象是一个字符串“username”,对于字符串来说,group by 在进行分组时,会直接将该字符串当做主键插入到临时表中,如果临时表中存在该主键,则count()的值+1。轮到第二条 数据Angelina时也是将字符串“username”当做主键插入到临时表,但此时临时表中已经存在该主键,则count()的值直接加1,最终结果就是上图。
三、group by报错注入
1.select count(*) from information_schema.tables group by concat(database(),floor(rand(0)*2));
2.select count(*) from information_schema.tables group by concat(database(),floor(rand()*2));

*可以看到,第一条语句每次都会爆出users表所在的数据库,而第二条并不是百分百爆出,原因就在于floor(rand(0)2)这一部分的区别
group by报错原理:
以第一条为例:select count(*) from information_schema.tables group by concat(database(),floor(rand(0)*2));
- floor(rand(0)*2)产生的随机数前6位一定是 0 1 1 0 1 1
- concat()用于将字符串连接
- concat(database(),floor(rand(0)*2))生成database()+"0"或database()+"1"的数列,而前六位的顺序一定是
- database()+"0"
- database()+"1"
- database()+"1"
- database()+"0"
- database()+"1"
- database()+"1"
报错具体过程:
- 建立临时表
- 取第一条记录,执行concat(database(),floor(rand(0)*2))(第一次执行),结果为database()+“0”,查询临时表,发现database()+"0"这个主键不存在,则准备执行插入,此时又会在执行一次concat(database(),floor(rand(0)*2))(第二次执行),结果是database()+“1”,然后将该值作为主键插入到临时表。*(真正插入到临时表中的主键是database()+“1”,concat(database(),floor(rand(0)2)) 执行了两次)
- 取第二条记录,执行concat(database(),floor(rand(0)2))(第三次执行),结果为database+“1”,查询临时表,发现该主键存在,count()的值加1
- 取第三条记录,执行concat(database(),floor(rand(0)*2))(第四次执行),结果为database()+“0”,查询临时表发现该主键不存在,则准备执行插入动作,此时又会在执行一次concat(database(),floor(rand(0)*2))(第五次执行),结果是database()+“1”,然后将该值作为主键插入到临时表。但由于临时表已经存在database()+"1"这个主键,就会爆出主键重复,同时也带出了数据库名,这就是group by报错注入的原理
由以上过程可以发现,总共取了三条记录,所以表中的数据至少要为三条才可以注入成功!!!