pytorch张量创建、变换
张量基本概念
张量是一个高维数组
在 pytorch0.4.0之前,torch.autograd 包中存在 Variable 这种数据类型,主要是用于封装 Tensor,进行自动求导 。
构建神经网络的计算图时,需用torch.autograd.Variable将Tensor包装起来,形成计算图中的节点。backward()自动计算出所有需要的梯度。来针对某个变量执行grad获得想要的梯度值。
import torch
from torch.autograd import Variable
x=Variable(torch.randn(2,2),requires_grad=True)
y=x+3
z=y*y*3
out=z.mean()
out.backward()
print(x.grad)Variable具有以下几个属性。
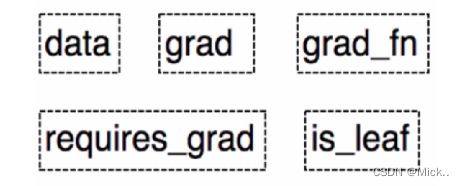
在 PyTorch 0.4.0 之后,Variable 并入了 Tensor。在之后版本的 Tensor 中,除了具有上面 Variable的5个属性,还有另外3个属性。
张量的创建
直接创建
torch.tensor()
torch.tensor(data,
dtype=None,
device=None,
requires_grad=False,
pin_memory=False) -> Tensor
- data:数据,可以是list,也可以是numpy
- dtype:数据类型,默认和data一致
- device:tensor所在的设备
- requires_grad:是否需要梯度,默认False,在搭建神经网络时需要将求导的参数设为True
torch.from_numpy()
将ndarray转换成tensor,两者共享内存,当修改一个数据时另一个也会被修改
import torch
import numpy as np
array_b = np.array([1, 2, 3, 4])
tensor_b = torch.from_numpy(array_b)
print(array_b,tensor_b)
###两者共用内存,其中一个改变另一个也会改变
array_b[0]=111
print(array_b,tensor_b)依数值创建
torch.zeros()依size创建全0的张量
torch.zeros(*size,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False) -> Tensor
其他,例如torch.ones(),torch.eyes(),torch.arange()
依概率创建
torch.normal()生成正态分布
torch.randn()生成标准正态分布
torch.rand()生成均匀分布
torch.randperm()生成0-n-1的随机排列,常用于生成索引
torch.bernoulli()以input为概率生成伯努利分布
张量的操作
张量的拼接
● torch.cat()将tensor序列按维度进行拼接,不会扩张张量的维度
● torch.stack()将tensor序列在新建的维度上进行拼接,会扩张张量的维度
import torch
a = torch.rand((2,3))
print(a.shape)
b=torch.cat([a,a],dim=1)
#b=torch.stack([a,a],dim=0)
print(b.shape)张量的切分
torch.chunk():将张量按维度进行平均切分,返回值是张量列表
import torch
a = torch.rand((2, 6))
a_chunk = torch.chunk(a, dim=1, chunks=6)
for idx, t in enumerate(a_chunk):
print('第{}个张量:{},shape is {}'.format(idx, t, t.shape))torch.split() 按维度dim将张量进行切分
import torch
a = torch.rand((2, 6))
a_chunk = torch.split(a, [2,2,1,1],dim=1)
for idx, t in enumerate(a_chunk):
print('第{}个张量:{},shape is {}'.format(idx, t, t.shape))
张量变换
.transpose()交换张量的两个维度。常用于图像的变换,比如把chw变换为hwc
.permute:可以对多个维度进行变换
.squeeze()压缩长度为1的维度,dim若为None,移除所有长度为1的轴,若指定维度,当且仅当该轴的长度为1时,可以被移除
.unsqueeze():依据dim扩张维度
.reshape()变换张量的形状,当张量在内存中是连续时,新张量和input共享数据内存
.view()只能改变连续的(contiguous)张量,返回的张量和原张量共享基础数据