【自然语言处理(NLP)】基于ERNIE语言模型的文本语义匹配
【自然语言处理(NLP)】基于ERNIE语言模型的文本语义匹配

作者简介:在校大学生一枚,华为云享专家,阿里云专家博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【自然语言处理(NLP)】基于ERNIE语言模型的文本语义匹配
- 前言
-
- (一)、任务描述
- (二)、数据来源
- 一、PaddleHub加载自定义数据集
- 二、语义预训练模型ERNIE优化文本匹配
-
- (一)、PaddleHub一键加载ERNIE
- (二)、选择Tokenizer读取数据
- (三)、选择优化策略和运行配置
- (四)、选择运行配置
- (五)、组建Finetune Task
- 三、组建Task
- 四、开始Finetune
- 五、使用模型进行预测
- 总结
前言
(一)、任务描述
文本匹配一直是自然语言处理(NLP)领域一个基础且重要的方向,一般研究两段文本之间的关系。文本相似度计算、自然语言推理、问答系统、信息检索等,都可以看作针对不同数据和场景的文本匹配应用。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配,对话系统可以归结为前一句对话和回复的匹配,机器翻译则可以归结为两种语言的匹配。

(二)、数据来源
数据集为天池“公益AI之星”挑战赛-新冠疫情相似句对判定大赛提供的数据集。
面对疫情抗击,疫情知识问答应用得到普遍推广。如何通过自然语言技术将问答进行相似分类仍然是一个有价值的问题。如识别患者相似问题,有利于理解患者真正诉求,帮助快速匹配准确答案,提升患者获得感;归纳医生相似答案,有助于分析答案规范性,保证疫情期间问诊规范性,避免误诊。
比赛主打疫情相关的呼吸领域的真实数据积累,数据粒度更加细化,判定难度相比多科室文本相似度匹配更高,同时问答数据也更具时效性。问题限制在20字以内,形成相对规范的句对。
数据集示例:
# 解压数据集
!tar -zxvf /home/aistudio/data/data48492/COVID19_sim_competition.tar.gz
# 查看数据集样例
!head -n 5 COVID19_sim_competition/train.tsv
输出结果如下图1所示:

数据集给出了文本对(text_a、text_b,text_a为query,text_b为title)以及类别(label)。其中label为1,表示text_a、text_b的文本语义相似,否则表示不相似。
PaddleHub 1.8.0版本之后内置了文本匹配任务。文本匹配任务可以分为pointwise和pairwise类型。
- pointwise,每一个样本通常由两个文本组成(query,title)。类别形式为0或1,0表示query与title不匹配; 1表示匹配。
- pairwise,每一个样本通常由三个文本组成(query,positive_title, negative_title)。positive_title比negative_title更加匹配query。
根据本数据集示例,该匹配任务为pointwise类型。
接下来本教程展示如何利用PaddleHub结合预训练模型ERNIE完成pointwise文本匹配任务。
Pairwise文本匹配任务可以参考教程:
https://aistudio.baidu.com/aistudio/projectdetail/709472
一、PaddleHub加载自定义数据集
加载文本匹配任务自定义数据集,用户仅需要继承TextMatchingDataset类,替换数据集存放地址即可。 下面代码示例展示如何将自定义数据集加载进PaddleHub使用。这样我们只需要在小数据集上微调(Fine-tune)预训练模型即可。
# 安装PaddleHub 1.8.1版本
!pip install paddlehub==1.8.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
from paddlehub.dataset.base_nlp_dataset import TextMatchingDataset
class COVID19Competition(TextMatchingDataset):
def __init__(self, tokenizer=None, max_seq_len=None):
base_path = 'COVID19_sim_competition'
super(COVID19Competition, self).__init__(
is_pair_wise=False, # 文本匹配类型,是否为pairwise
base_path=base_path,
train_file="train.tsv", # 相对于base_path的文件路径
dev_file="dev.tsv", # 相对于base_path的文件路径
train_file_with_header=True,
dev_file_with_header=True,
label_list=["0", "1"],
tokenizer=tokenizer,
max_seq_len=max_seq_len)
二、语义预训练模型ERNIE优化文本匹配
如果你对预训练模型感兴趣,如谷歌的 BERT 模型,或者百度的 ERNIE 模型,也值得在自己的任务试一试效果。
百度的预训练模型ERNIE经过海量的数据训练后,其特征抽取的工作已经做的非常好。借鉴迁移学习的思想,我们可以利用其在海量数据中学习的语义信息辅助小数据集(如本示例中的医疗文本数据集)上的任务。

PaddleHub提供了丰富的预训练模型,并且可以便捷地获取PaddlePaddle生态下的所有预训练模型。下面展示如何使用PaddleHub一键加载ERNIE,优化文本匹配任务。
(一)、PaddleHub一键加载ERNIE
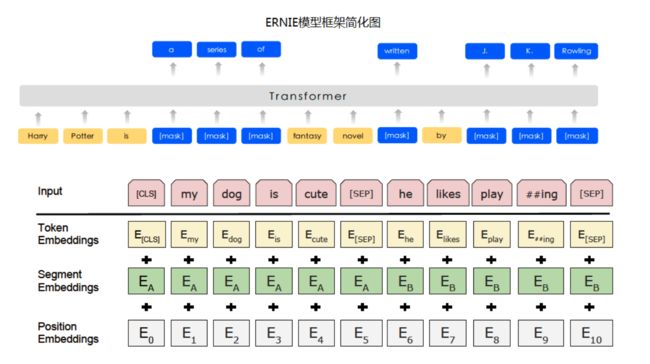
import paddlehub as hub
import paddle
paddle.enable_static()
module = hub.Module(name="ernie")
# Pointwise任务需要: query, title_left (2 slots)
inputs, outputs, program = module.context(
trainable=True, max_seq_len=128, num_slots=2)
其中最大序列长度max_seq_len是可以调整的参数,建议值128,根据任务文本长度不同可以调整该值,但不要超过512。
num_slots: 文本匹配任务输入文本的数据量。pointwise文本匹配任务num_slots应为2,表示query和title。 pairtwise文本匹配任务num_slots应为3。
如果想尝试其他语义模型(如ernie_tiny, RoBERTa等),只需要更换Module中的name参数即可。
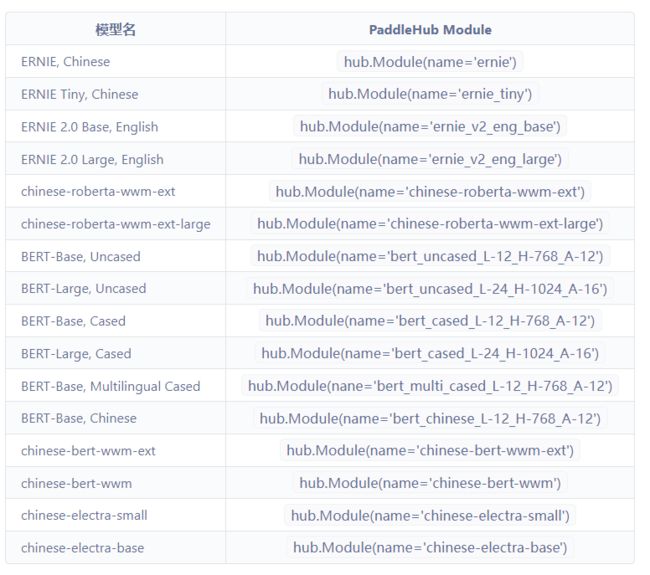
(二)、选择Tokenizer读取数据
tokenizer = hub.BertTokenizer(vocab_file=module.get_vocab_path(), tokenize_chinese_chars=True)
dataset = COVID19Competition(tokenizer=tokenizer, max_seq_len=128)
module.get_vocab_path() 会返回预训练模型对应的词表;
tokenize_chinese_chars 是否切分中文文本
NOTE:
- 如果使用Transformer类模型(如ERNIE、BERT、RoBerta等),则应该选择
hub.BertTokenizer. - 如果使用非Transformer类模型(如word2vec_skipgram、tencent_ailab_chinese_embedding_small等),则应该选择
hub.CustomTokenizer - 创建dataset对象时,
max_seq_len必须与第一步中module.context接口max_seq_len保持一致。 - 在这里,取出一条数据打印出来看看,可以用 docs 获取数据的list,用 labels 获取数据的label值,打印出来对数据有一个初步的印象。
(三)、选择优化策略和运行配置
适用于ERNIE/BERT这类Transformer模型的迁移优化策略为AdamWeightDecayStrategy。
详情请查看Strategy。
AdamWeightDecayStrategy的参数:
learning_rate: 最大学习率lr_scheduler: 有linear_decay和noam_decay两种衰减策略可选warmup_proprotion: 训练预热的比例,若设置为0.1, 则会在前10%的训练step中学习率逐步提升到learning_rateweight_decay: 权重衰减,类似模型正则项策略,避免模型overfitting
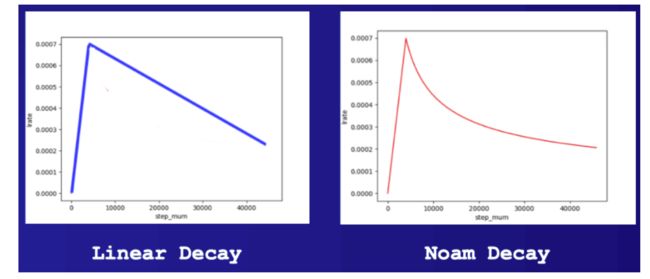
strategy = hub.AdamWeightDecayStrategy(
weight_decay=0.01,
warmup_proportion=0.1,
learning_rate=5e-5)
PaddleHub提供了许多优化策略,如AdamWeightDecayStrategy、ULMFiTStrategy、DefaultFinetuneStrategy等,详细信息参见策略
(四)、选择运行配置
在进行Finetune前,我们可以设置一些运行时的配置,例如如下代码中的配置,表示:
-
use_cuda:设置为False表示使用CPU进行训练。如果您本机支持GPU,且安装的是GPU版本的PaddlePaddle,我们建议您将这个选项设置为True; -
num_epoch:Finetune时遍历训练集的次数,; -
batch_size:每次训练的时候,给模型输入的每批数据大小为32,模型训练时能够并行处理批数据,因此batch_size越大,训练的效率越高,但是同时带来了内存的负荷,过大的batch_size可能导致内存不足而无法训练,因此选择一个合适的batch_size是很重要的一步; -
checkpoint_dir:训练的参数和数据的保存目录; -
eval_interval:每隔100step在验证集上进行一次性能评估; -
strategy:Fine-tune策略;
更多运行配置,请查看RunConfig
config = hub.RunConfig(
eval_interval=300,
use_cuda=True,
num_epoch=3,
batch_size=32,
checkpoint_dir='ckpt_ernie_pointwise_matching',
strategy=strategy)
(五)、组建Finetune Task
使用预训练模型ERNIE完成pointwise文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取CLS特征(pooled_output),之后输出全连接层,进行二分类。如下图BERT用于句对分类任务的用法:
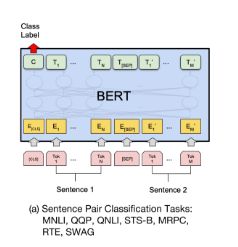
然而,以上用法的问题在于,ERNIE的模型参数非常庞大,导致计算量非常大,预测的速度也不够理想。从而达不到线上业务的要求。针对该问题,PaddleHub内置文本匹配网络结果采用了sentence-bert的结构。
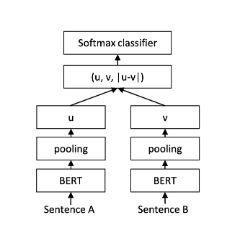
sentence-bert采用了双塔(Siamese)的网络结构。Query和Title分别输入ERNIE,共享一个ERNIE参数,得到各自的sequence_output特征。之后对sequence_output进行pooling(PaddleHub默认使用mean pooling操作。PaddleHub作者经过大量实验对比发现,mean_pooling和max_pooling对实验效果差异不大),之后输出分别记作u,v。之后将三个表征(u,v,|u-v|)拼接起来,进行二分类。网络结构如上图所示。
更多关于Sentence-BERT的信息可以参考论文:https://arxiv.org/abs/1908.10084
那么Sentence-BERT采用Siamese的网路结构,是如何提升预测速度呢?
Siamese的网络结构好处在于query和title分别输入同一套网络。如在信息搜索任务中,此时就可以将数据库中的title文本提前计算好对应sequence_output特征,保存在数据库中。当用户搜索query时,只需计算query的sequence_output特征与保存在数据库中的title sequence_output特征,通过一个简单的mean_pooling和全连接层进行二分类即可。从而大幅提升预测效率,同时也保障了模型性能。
关于匹配任务常用的Siamese网络结构可以参考:https://blog.csdn.net/thriving_fcl/article/details/73730552
三、组建Task
有了合适的预训练模型和准备要迁移的数据集后,我们开始组建一个Task。
- 获取module的上下文环境,包括输入和输出的变量,以及Paddle Program;
- 从输出变量中找到用于文本匹配的单词级特征sequence_output;
- 在sequence_output后面接入一个匹配网络,生成Task;
PointwiseTextMatchingTask的参数有:
-
dataset:数据; -
query_feature:从预训练提取的query对应特征; -
title_feature:从预训练提取的title对应特征; -
tokenizer:数据处理器 -
config: 运行配置;
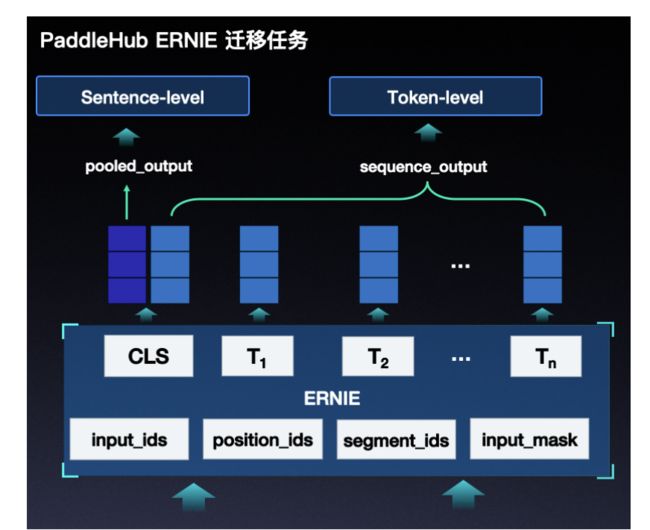
# 构建迁移网络,使用ERNIE的token-level输出
query = outputs["sequence_output"]
title = outputs['sequence_output_2']
# 创建pointwise文本匹配任务
pointwise_matching_task = hub.PointwiseTextMatchingTask(
dataset=dataset,
query_feature=query,
title_feature=title,
tokenizer=tokenizer,
config=config)
四、开始Finetune
我们选择finetune_and_eval接口来进行模型训练,这个接口在finetune的过程中,会周期性的进行模型效果的评估,以便我们了解整个训练过程的性能变化。

run_states=pointwise_matching_task.finetune_and_eval()
五、使用模型进行预测
当Finetune完成后,我们使用模型来进行预测,整个预测流程大致可以分为以下几步:
- 构建网络
- 生成预测数据的Tokenizer
- 切换到预测的Program
- 加载预训练好的参数
- 运行Program进行预测
预测数据样例,代码如下:
# 预测数据样例
text_pairs = [
[
"小孩吃了百令胶囊能打预防针吗", # query
"小孩吃了百令胶囊能不能打预防针", # title
],
[
"请问呕血与咯血有什么区别?", # query
"请问呕血与咯血异同?", # title
]
]
results = pointwise_matching_task.predict(
data=text_pairs,
max_seq_len=128,
label_list=dataset.get_labels(),
return_result=True,
accelerate_mode=False)
for index, text in enumerate(text_pairs):
print("data: %s, prediction_label: %s" % (text, results[index]))
输出结果如下图2所示:

总结
本系列文章内容为根据清华社出版的《自然语言处理实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~
