【OpenCV图像处理12】特征检测与匹配
文章目录
- 十二、特征检测与匹配
-
- 1、特征检测
-
- 1.1 Harris角点检测
-
- 1.1.1 算法原理
- 1.1.2 实际应用
- 1.2 Shi-Tomasi角点检测
- 1.3 SIFT关键点检测
-
- 1.3.1 算法原理
- 1.3.2 实际应用
- 1.3.3 关键点和描述子
- 1.4 SURF特征检测
- 1.5 ORB特征检测
- 2、特征匹配
-
- 2.1 暴力特征匹配
- 2.2 FLANN特征匹配
- 3、图像查找
十二、特征检测与匹配
1、特征检测
特征检测是计算机视觉和图像处理中的一个概念。
它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征检测的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点、连续的曲线或者连续的区域。
特征检测包括:
- 边缘检测
- 角检测
- 区域检测
- 脊检测
特征检测应用场景:
- 图像搜索,比如以图搜图
- 拼图游戏
- 图像拼接
- …
以拼图游戏为例来说明特征检测的应用流程:

- 寻找特征
-
特征是唯一的
-
特征是可追踪的
-
特征是能比较的
-
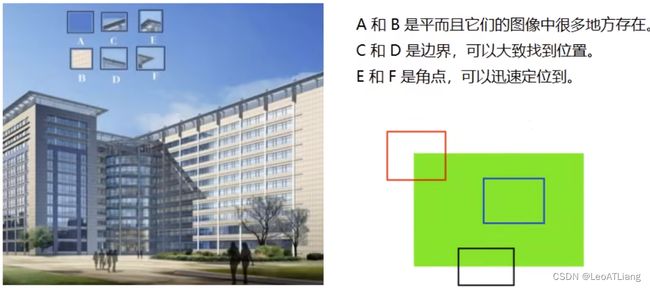
我们发现:
- 平坦部分很难找到它在原图中的位置
- 边缘相比平坦要好找一些,但是也不能一下确定
- 角点可以一下就找到其在原图中的位置
图像特征就是值有意义的图像区域,具有独特性,易于识别性,比较角点、斑点以及高密度区。
在图像特征中最重要的就是角点,但哪些是角点呢?
- 灰度梯度的最大值对应的像素
- 两条线的交点
- 极值点(一阶导数最大,二阶导数为0)
1.1 Harris角点检测
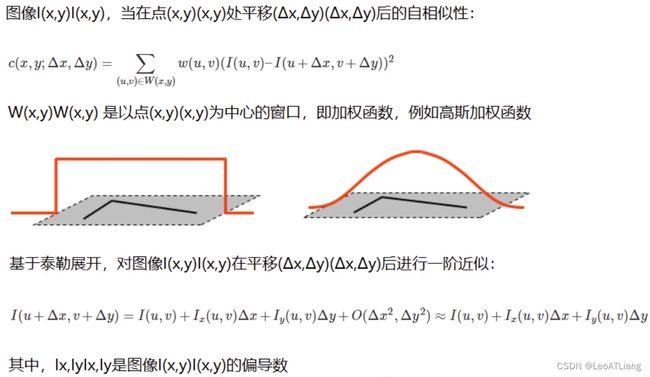
1.1.1 算法原理
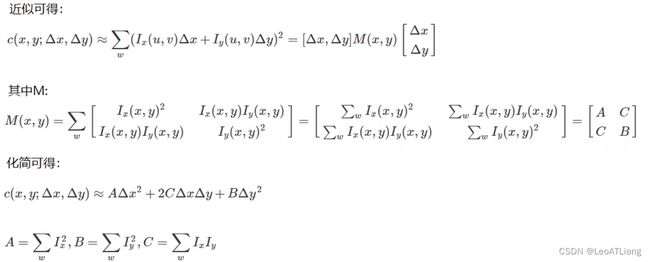
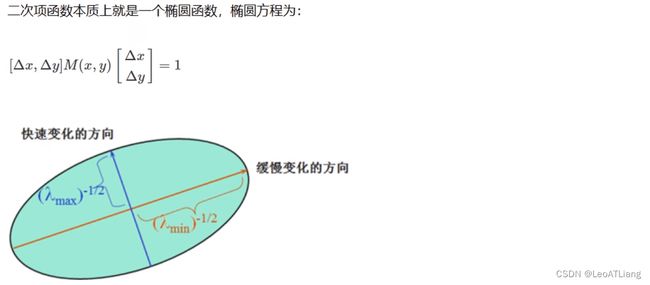


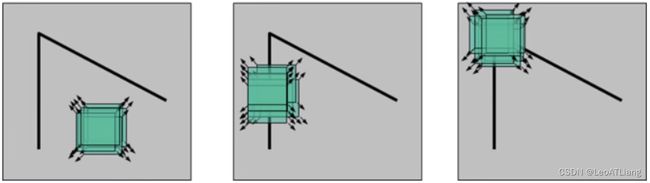
检测窗口在图像上移动,上图对应着三种情况:
- 在平坦区域,无论向哪个方向移动,衡量系统变换不大。
- 在边缘区域,向垂直边缘移动时,衡量系统变换剧烈。
- 在角点处,往哪个方向移动,衡量系统都变换剧烈。
1.1.2 实际应用
cornerHarris()用法:
cv2.cornerHarris(src, blockSize, ksize, k, dst: None, borderType: None)
参数说明:
- blockSize:检测窗口大小
- ksize:Sobel的卷积核
- k:权重系数,即上面公式中的 α \alpha α ,是个经验值,一般取0.04~0.06之间(默认为0.04)。
代码实现:
import cv2
img = cv2.imread('../resource/chess.bmp')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Harris角点检测
# blockSize没有要求必须是奇数
dst = cv2.cornerHarris(gray, blockSize=2, ksize=3, k=0.04)
# 返回的东西叫做角点响应,每一个像素点都能计算出一个角点响应来
print(img.shape)
print(gray.shape)
# print(dst)
print(dst.shape)
# 显示角点
# 我们认为角点响应大于0.01倍的dst.max()就可以认为是角点
img[dst > 0.01 * dst.max()] = [0, 0, 255]
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()

1.2 Shi-Tomasi角点检测
Shi-Tomasi是对Harris角点检测的改进。
Harris角点检测计算的稳定性和 K 有关,而 K 是一个经验值,不太好设定最佳的K值。
Shi-Tomasi发现,角点的稳定性其实和矩阵 M 的较小特征值有关,于是直接用较小的那个特征值作为分数,这样就不用调整 K 值了。
- Shi-Tomasi将分数公式改为如下形式: R = m i n ( λ 1 , λ 2 ) R = min(\lambda_1, \lambda_2) R=min(λ1,λ2)
- 和Harris一样,如果该分数大于设定的阈值,我们就认为它是一个角点。
goodFeaturesToTrack()用法:
cv2.goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance, corners: None, mask: None, blockSize: None, useHarrisDetector: None, k: None)
参数说明:
- maxCorners:角点的最大数,值为0表示无限制
- qualityLevel:角点质量,小于1.0的整数,一般在0.01~0.1之间
- minDistance:角点之间最小欧式距离,忽略小于此距离的点
- mask:感兴趣的区域
- blockSize:检测窗口的大小
- useHarrisDetector:是否使用Harris算法
- k:默认是0.04
代码实现:
import cv2
import numpy as np
img = cv2.imread('../resource/chess.bmp')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray, maxCorners=0, qualityLevel=0.01, minDistance=10)
corners = np.int0(corners)
# Shi-Tomasi绘制角点
for i in corners:
x, y = i.ravel()
cv2.circle(img, (x, y), 3, (255, 0, 0), -1)
cv2.imshow('Shi-Tomasi', img)
cv2.waitKey(0)
cv2.destroyAllWindows()

1.3 SIFT关键点检测
SIFT,即尺度不变特征变换(Scale-invariant feature transform,SIFT),是用于图像处理领域的一种描述。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。
Harris角点具有旋转不变的特性,但是缩放后,原来的角点有可能就不是角点了。
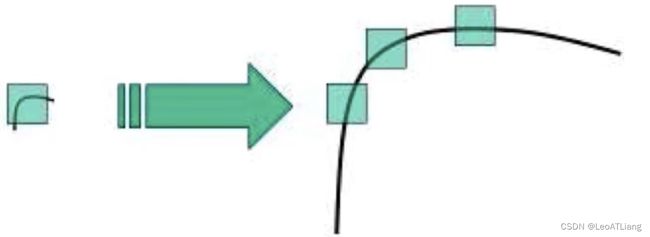
1.3.1 算法原理
- 图像尺度空间
- 在一定的范围内,无论物体是大还是小,人眼都可以分辨出来,然而计算机要有相同的能力却很难,所以要让机器能够对物体在不同尺度下有一个统一的认知,就需要考虑图像在不同尺度下都存在的特点。
- 尺度空间的获取通常使用高斯模糊来实现。
- 不同的 σ \sigma σ 的高斯函数决定了对图像的平滑程度,越大的 $\sigma $ 值对应的图像越模糊。


- 多分辨率金字塔

- 高斯差分金字塔(DOG)
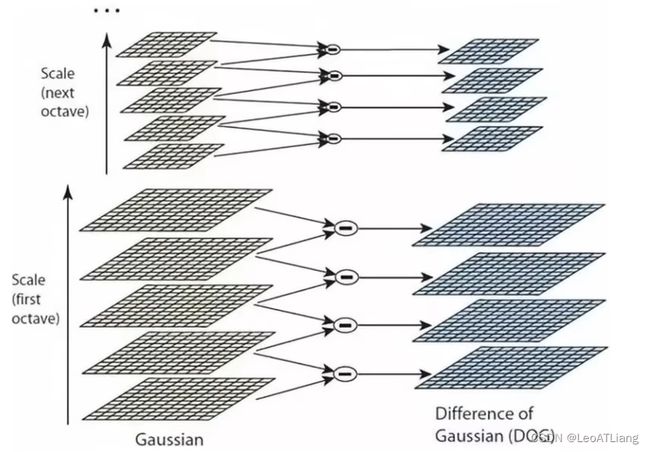
- DOG空间极值检测
- 为了寻找尺度空间的极值点,每个像素要和其图像域(同一尺度空间)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或者小于)所有相邻点时,该点就是极值点。
- 如下图所示,中间的检测点要和其所在图像 3 * 3 邻域的8个像素点,以及其相邻的上下两层的 3 * 3 邻域的18个像素点,共26个像素点进行比较。
DOG定义公式:
D ( x , y , σ ) = [ G ( x , y , k σ ) − G ( x , y , σ ) ] ∗ I ( x , y ) = L ( x , y , k σ ) − L ( x , y , σ ) D(x, y, \sigma) = [G(x, y, k\sigma) - G(x, y, \sigma)] * I(x, y) = L(x, y, k\sigma) - L(x, y, \sigma) D(x,y,σ)=[G(x,y,kσ)−G(x,y,σ)]∗I(x,y)=L(x,y,kσ)−L(x,y,σ)

- 关键点的精确定位
- 这些候选关键点是DOG空间的局部极值点,而且这些极值点均为离散的点,精确定位极值点的一种方法是:对尺度空间DOG函数进行曲线拟合,计算其极值点,从而实现关键点的精确定位。
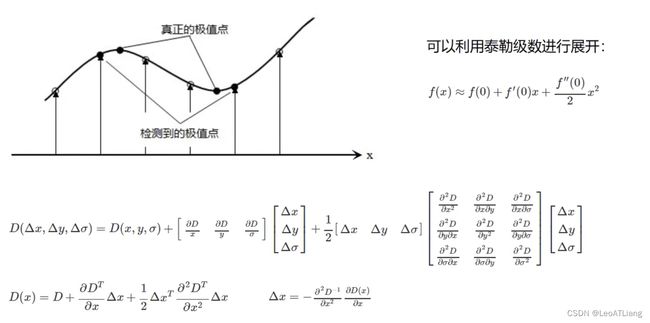
- 消除边界响应

- 特征点的主方向
- 每个特征点可以得到三个信息 ( x , y , σ , θ ) (x, y, \sigma, \theta) (x,y,σ,θ) ,即位置、尺度和方向。具有多个方向的关键点可以被复制成多份,然后将方向值分别赋给赋值后的特征点,一个特征点就产生了多个坐标、尺度相等,但是方向不同的特征点。

- 生成特征描述
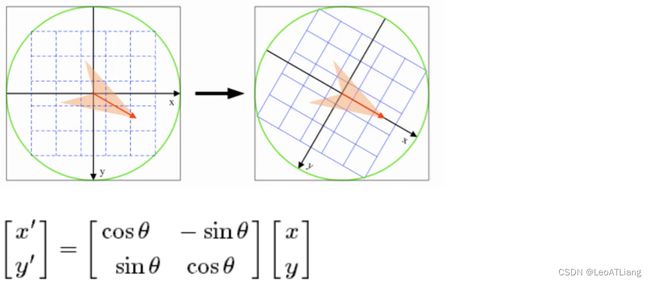
- 为了保证特征矢量的旋转不变性,要以特征点为中心,在附近邻域内将坐标轴旋转 θ \theta θ 角度,即将坐标轴旋转为特征点的主方向。
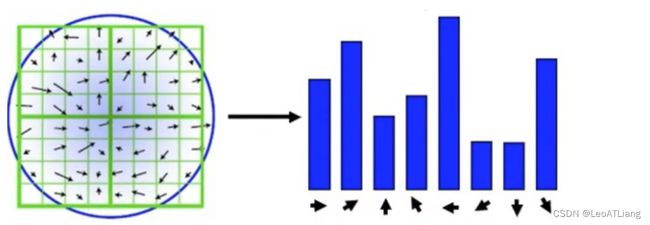
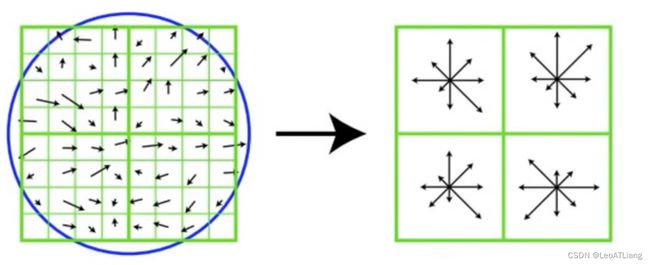
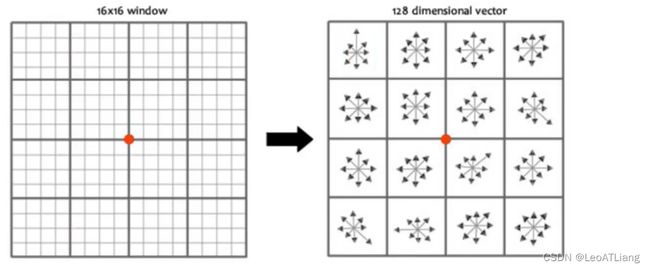
- 旋转之后的主方向为中心取 8 * 8 的窗口,求每个像素的梯度幅值和方向,箭头方向代表梯度方向,长度代表梯度幅值,然后利用高斯窗口对其进行加权运算,最后在每个 4 * 4 的小块上绘制 8 个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点,即每个特征点由 4 个种子点组成,每个种子点由 8 个方向的向量信息。
- 论文中建议对每个关键点使用 4 * 4 共 16 个种子点来描述,这样一个关键点就会产生 128 维的SIFT特征向量。
1.3.2 实际应用
使用SIFT的步骤:
- 创建SIFT对象:
sift = cv2.xfeatures2d.SIFT_create() - 进行检测:
kp = sift.detect(gray) - 绘制关键点:
cv2.drawKeypoints(gray, kp, img)
代码实现:
import cv2
img = cv2.imread('../resource/chess.bmp')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SIFT对象
# 注意:xfeatures2d是OpenCV的扩展包中的内容,需要安装opencv-contrib-python
sift = cv2.xfeatures2d.SIFT_create()
# 进行检测
kp = sift.detect(gray)
# kp是一个列表,存放的是封装的KeyPoint对象
print(kp)
# 绘制关键点
cv2.drawKeypoints(gray, kp, img)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()

1.3.3 关键点和描述子
关键点:位置、大小和方向
关键点描述子:记录了关键点周围对其有共享的像素点的一组向量值,其不受仿射变换、光照变换等影响,描述子的作用就是进行特征匹配,在后面进行特征匹配的时候会用上。
1、计算描述子
kp, des = sift.compute(img, kp)
其作用是进行特征匹配。
2、同时计算关键点和描述子
kp, des = sift.detectAndCompute(img, ...)
mask:指明对img中哪个区域进行计算。
代码实现:
import cv2
img = cv2.imread('../resource/chess.bmp')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SIFT对象
sift = cv2.xfeatures2d.SIFT_create()
# 进行检测
kp = sift.detect(gray)
# 检测关键点,并计算描述子
kp, des = sift.compute(img, kp)
# 或者一步到位,把关键点和描述子一起检测出来
# kp, des = sift.detectAndCompute(img, None)
print(kp)
print(len(kp))
print(type(des))
print(des)
print(des.shape)
(<KeyPoint 000001A931FBFE40>, <KeyPoint 000001A931FBFE70>, <KeyPoint 000001A931FBFEA0>, <KeyPoint 000001A931FBFED0>, <KeyPoint 000001A931FBFF00>, <KeyPoint 000001A931FBFF30>, <KeyPoint
...
000001A931FC47E0>)
391
<class 'numpy.ndarray'>
[[ 0. 0. 9. ... 0. 0. 0.]
[ 0. 2. 20. ... 0. 0. 0.]
[ 0. 0. 26. ... 0. 0. 0.]
...
[ 0. 0. 9. ... 0. 0. 0.]
[ 0. 0. 7. ... 0. 0. 0.]
[ 0. 5. 29. ... 0. 0. 0.]]
(391, 128)
1.4 SURF特征检测
Speed Up Robust Features(SURF,加速稳健特征),是一种稳健的局部特征点检测和描述算法。
最初由Herbert Bay发表在2006年的欧洲计算机视觉会议(European Conference on Computer Vision,ECCV)上,并在2008年正式发表在Computer Vision and Image Understanding期刊上。
SURF是对David Lowe在1999年提出的SIFT算法的改进,提升了算法的执行效率,为算法在实时计算机视觉系统中应用提供了可能。
如果想对一系列的图像进行快速的特征检测,使用SIFT会非常慢。因此SIFT最大的问题就是速度慢,所以才有了SURF。
注意:SURF在较新版本的OpenCV中已经申请专利。需要降OpenCV版本才能使用,降到3.4.1.15就可以使用了。
使用SURF的步骤:
-
创建SURF对象:
surf = cv2.xfeatures2d.SURF_create() -
进行检测:
kp, des = surf.detectAndCompute(img, mask) -
绘制关键点:
cv2.drawKeypoints(gray, kp, img)
代码实现:
import cv2
img = cv2.imread('../resource/chess.bmp')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SURF对象
surf = cv2.xfeatures2d.SURF_create()
# 进行检测
kp, des = surf.detectAndCompute(gray, None)
print(des[0])
# 绘制关键点
cv2.drawKeypoints(gray, kp, img)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
版权问题,运行不出来,降OpenCV版本也出错了。
1.5 ORB特征检测
ORB(Oriented FAST and Rotated BRIEF),可以做到实时检测。
FAST:可以做到特征点的实时检测。
BRIEF:对已经检测到的特征点进行描述,加快了特征描述符建立的速度,同时也极大的降低了特征匹配的时间。
使用ORB的步骤:
- 创建ORB对象:
orb = cv2.ORB_create() - 进行检测:
kp, des = orb.detectAndCompute(gray, None) - 绘制关键点:
cv2.drawKeypoints(gray, kp, img)
代码实现:
import cv2
img = cv2.imread('../resource/chess.bmp')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建ORB对象
orb = cv2.ORB_create()
# 进行检测
kp, des = orb.detectAndCompute(gray, None)
print(des[0])
# 绘制关键点
cv2.drawKeypoints(gray, kp, img)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
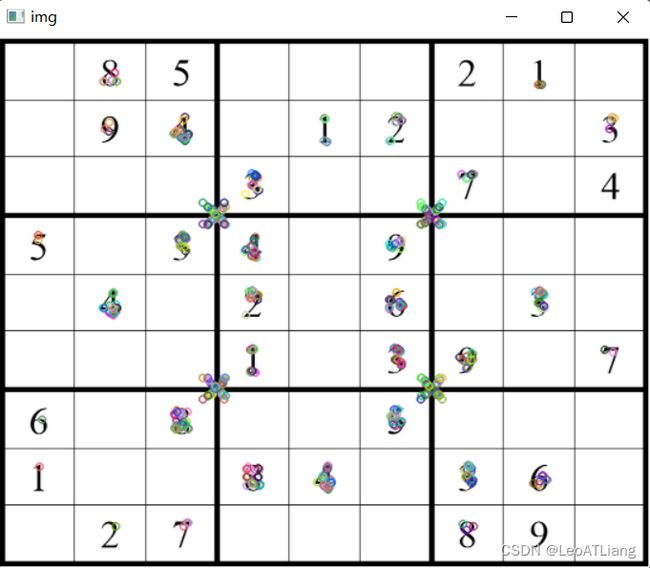
2、特征匹配
2.1 暴力特征匹配
BF(Brute-Force),暴力特征匹配方法。它使用第一组中的每个特征的描述子,与第二组中的所有特征描述子进行匹配,计算它们之间的差距,然后将最接近一个匹配返回。
基本步骤:
- 创建匹配器:
cv2.BFMatcher() - 进行特征匹配:
bf.match() - 绘制匹配点:
cv2.drawMatches()
BFMatcher()用法:
bf = cv2.BFMatcher(normType: None, crossCheck: None)
- normType:NORM_L1,NORM_L2 (默认),NORM_HAMMING,NORM_HAMMING2,…
- NORM_L1:取描述子的绝对值进行加法运算
- NORM_L2:欧氏距离
- HAMMING:通过判断二进制位
L1andL2norms are preferable choices for SIFT and SURF descriptors,
NORM_HAMMINGshould be used with ORB, BRISK and BRIEF,NORM_HAMMING2should be used with ORB whenWTA_K==3or4.
- crossCheck:是否进行交叉匹配,默认为False
match()用法: 对两幅图的描述子进行计算
match = bf.match(queryDescriptors, trainDescriptors, mask: None)
参数为:SIFT、SURF、ORB等计算的描述子
drawMatches()用法:
cv2.drawMatches(img1, keypoints1, img2, keypoints2, matches1to2, outImg, matchColor: None, singlePointColor: None, matchesMask: None, flags: None)
参数为:搜索img, kp;匹配图img,kp;match()方法返回的结果match。
代码实现:
import cv2
img1 = cv2.imread('../resource/cv.bmp')
img2 = cv2.imread('../resource/cv.webp')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 创建SIFT特征检测器
sift = cv2.xfeatures2d.SIFT_create()
# 进行检测,计算描述子与特征点
kp1, des1 = sift.detectAndCompute(gray1, None)
kp2, des2 = sift.detectAndCompute(gray2, None)
# 创建匹配器
bf = cv2.BFMatcher(cv2.NORM_L1)
# 进行特征匹配
match = bf.match(des1, des2)
# 绘制匹配点
img = cv2.drawMatches(img1, kp1, img2, kp2, match, None)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()

2.2 FLANN特征匹配
FLANN优缺点:
- 在进行批量特征匹配时,FLANN速度更快。
- 由于它使用的是邻近近似值,所以精度较差。
基本步骤:
- 创建FLANN匹配器:
cv2.FlannBasedMatcher() - 进行特征匹配:flann.match/knnMatch
- 绘制匹配点:cv2.drawMatches()/drawMatchesKnn()
FlannBasedMatcher()用法:
# index_params = dict(algorithm=cv2.FLANN_INDEX_KDTREE, tress=5)
index_params = dict(algorithm=1, tress=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
-
index_params字典:匹配算法 KDTREE(SIFT,SURF)、LSH(ORB)
-
search_params字典:指定KDTREE算法中遍历树的次数
knnMatch()用法:
match = cv2.knnMatch(queryDescriptors, trainDescriptors, k, mask: None, compactResult: None)
-
queryDescriptors, trainDescriptors:SIFT,SURF,ORB等计算的描述子
-
k:表示取欧氏距离最近的前k个关键点
-
返回的是匹配的结果DMatch对象
-
DMatch的内容:
-
distance:描述子之间的距离,值越低越好
-
queryIdx:第一幅图像的描述子索引值
-
trainIdx:第二幅图像的描述子索引值
-
imgIdx:第二幅图像的索引值
-
-
drawMatchesKnn()用法:
cv2.drawMatchesKnn(img1, keypoints1, img2, keypoints2, matches1to2, outImg, matchColor: None, singlePointColor: None, matchesMask: None, flags: None)
参数为:搜索img,kp;匹配图img,kp;match()方法返回的匹配结果match。
代码实现:
import cv2
# 读取两幅图像
img1 = cv2.imread('../resource/cv.bmp')
img2 = cv2.imread('../resource/cv.webp')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 创建SIFT特征检测器
sift = cv2.xfeatures2d.SIFT_create()
# 进行检测,计算描述子与特征点
kp1, des1 = sift.detectAndCompute(gray1, None)
kp2, des2 = sift.detectAndCompute(gray2, None)
# 创建匹配器
# index_params = dict(algorithm=cv2.FLANN_INDEX_KDTREE, tress=5)
index_params = dict(algorithm=1, tress=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 进行特征匹配
match = flann.knnMatch(des1, des2, k=2)
# 优化
good = []
for i, (m, n) in enumerate(match):
if m.distance < 0.7 * n.distance:
good.append(m)
# 绘制匹配点
ret = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
cv2.imshow('ret', ret)
cv2.waitKey(0)
cv2.destroyAllWindows()

3、图像查找
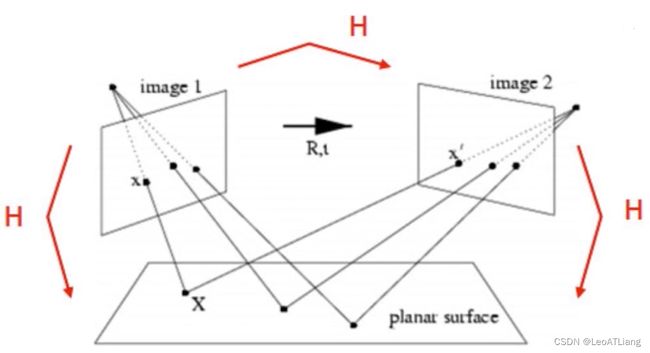
单应性的作用(一):

单应性的作用(二):

代码实现: 特征匹配 + 单应性矩阵
import cv2
import numpy as np
# 读取两幅图像
img1 = cv2.imread('../resource/cv.bmp')
img2 = cv2.imread('../resource/cv.webp')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 创建SIFT特征检测器
sift = cv2.xfeatures2d.SIFT_create()
# 进行检测,计算描述子与特征点
kp1, des1 = sift.detectAndCompute(gray1, None)
kp2, des2 = sift.detectAndCompute(gray2, None)
# 创建匹配器
# index_params = dict(algorithm=cv2.FLANN_INDEX_KDTREE, tress=5)
index_params = dict(algorithm=1, tress=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 进行特征匹配
match = flann.knnMatch(des1, des2, k=2)
# 优化
good = []
for i, (m, n) in enumerate(match):
if m.distance < 0.7 * n.distance:
good.append(m)
# 做判断
if len(good) >= 4:
# 单应性矩阵
srcPts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
dstPts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
H, _ = cv2.findHomography(srcPts, dstPts, cv2.RANSAC, 5.0)
# 透视变换
h, w = img1.shape[:2]
pts = np.float32([[0, 0], [0, h - 1], [w - 1, h - 1], [w - 1, 0]]).reshape(-1, 1, 2)
dst = cv2.perspectiveTransform(pts, H)
# 用线框出来
cv2.polylines(img2, [np.int32(dst)], True, (255, 0, 255), 3)
else:
print('The number of good is less than 4.')
exit()
# 绘制匹配点
ret = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
cv2.imshow('ret', ret)
cv2.waitKey(0)
cv2.destroyAllWindows()
