极智AI | 一文看懂昇腾达芬奇架构计算单元
本文详细解释了昇腾达芬奇架构中计算单元的架构与计算原理。
文章目录
-
- 1、达芬奇架构概览
- 2、矩阵计算单元
-
- 2.1 矩阵相乘
- 2.2 矩阵计算单元的计算方式
- 2.3 向量计算单元的计算方式
- 2.4 标量计算单元的计算方式
1、达芬奇架构概览
达芬奇架构是一种 “ 特定域架构 ” (Domin Specific Architecture,DSA) 芯片。
昇腾AI处理器的计算核心主要由 AI Core 构成,包含三种基础计算资源:矩阵计算单元(Cube Unit)、向量计算单元(Vector Unit)和标量计算单元(Scalar Unit),负责执行张量、矢量、标量计算。AI Core 中的矩阵计算单元支持 Int8 和 fp16 的计算,向量计算单元支持 fp16 和 fp32 的计算。AI Core 基本结构如下:
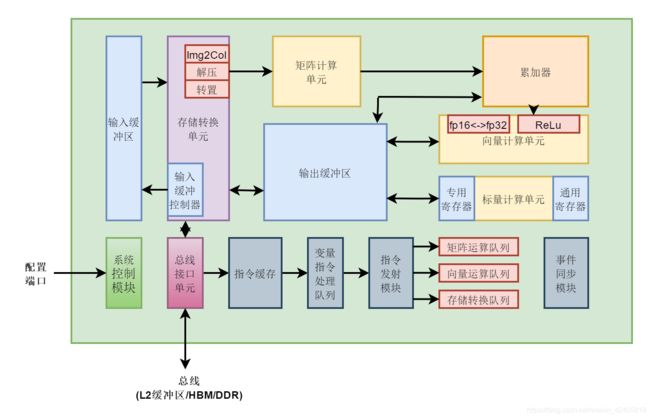
这里主要讲解 AI Core 中的计算单元,也就是上图中的黄色部分(矩阵计算单元、向量计算单元、标量计算单元及累加器模块),其他模块在这里就不展开说了。
2、矩阵计算单元
2.1 矩阵相乘
这里可以先参考一下我之前的文章《【模型推理】一文看懂Img2Col卷积加速算法》。
由于现代的CNN网络算法中使用了大量的矩阵计算,达芬奇架构中也针对矩阵计算进行了深度优化,而矩阵计算单元就是支持高吞吐量矩阵计算的硬件单元。
举个例子,下图表示两个矩阵 A、B 乘法,即 C = A x B,其中 A 的维度为 (M, K),B 的维度为 (K, N)。

在 CPU 上可以用如下代码表示上述计算过程:
for(int m = 0; m < M; m++)
for(int n = 0; n < N; n++)
for(int k = 0; k < K; k++)
C[m][n] += A[m][k] * B[k][n]
上述代码在单发射的CPU上至少需要 M * K * N 个时钟周期才能完成。在 CPU 的计算过程中,我们期望矩阵 A 需按行扫描,矩阵 B 需按列扫描,考虑到典型的矩阵存储方式,无论矩阵 A 还是矩阵 B 都会按照行的方式进行存放,也就是 Row-Major。在读取内存数据时,会打开内存中相应的一整行并把同一行中的所有数都读取出来,这种内存读取方式对矩阵 A 是十分友好的,但对矩阵 B 却很鸡肋。如果能让矩阵 B 按列存储该多好,就像这样:
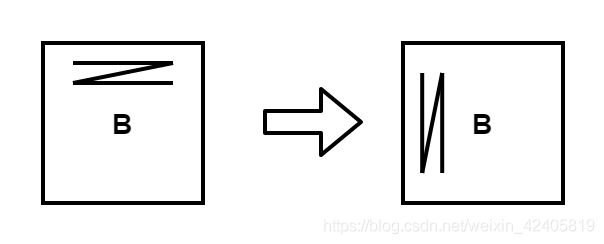
所以在矩阵乘计算中往往通过改变某个矩阵的存储方式来提升矩阵计算的效率。
2.2 矩阵计算单元的计算方式
一般在矩阵较大时,由于芯片上计算和存储的资源有限,需要对矩阵分块平铺处理 (Tiling),如下图。
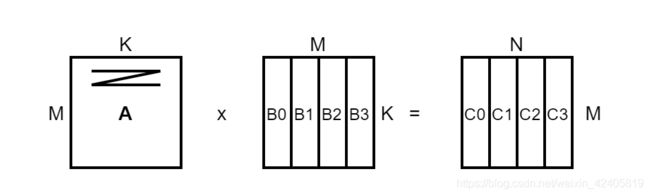
受限缓存资源,将矩阵 B 切分为 B0、B1、B2、B3 子矩阵,每个子矩阵的大小都适合一次性存储到芯片上的缓存中并与矩阵 A 进行计算,从而得到结果子矩阵。矩阵分块的优点是充分利用了缓存的容量,并最大程度利用了数据计算过程中的局部性特征,可以高效的实现大规模的矩阵乘法计算,这是一种常见的优化方式。
在 CNN 网络中,常见的卷积加速是将卷积运算转换为矩阵运算。GPU 采用 GEMM 来实现矩阵运算的加速,如要实现一个 16 x 16 的矩阵乘法,需启 256 个并行线程,每个线程独立计算输出结果矩阵中的一个点,假设每个线程在一个时钟周期内可以完成一次乘加运算,则 GPU 完成整个矩阵乘运算需要 16 个时钟周期,这个延时是传统 GPU 无法避免的瓶颈(没提 tensorcore 感觉不太公平)。昇腾达芬奇架构针对这个问题做了深度优化,矩阵计算单元可以用一条指令完成两个 16 x 16 矩阵的相乘预算(也就是16的立方,这也是 Cube 名称的由来),相当于在极短时间内做了 4096 次乘加运算。
同样是上面的矩阵乘例子,达芬奇矩阵计算单元在进行 A x B 矩阵乘运算时,会将 A 按行存入输入缓冲区,将 B 按列存入输入缓冲区,得到的结果矩阵 C 按行存入输出缓冲区。其中,C 的第一个元素由 A 的第一行的 16 个元素与 B 的第一列的 16 个元素通过矩阵计算单元子电路进行 16 次乘和 15 次加运算得到。达芬奇矩阵计算单元中共有 256 个矩阵计算子电路,可以由一条指令并行完成 C 的 256 个元素的计算。在达芬奇架构概览中可以看到矩阵计算单元后面跟了一组累加器,这是为了通常矩阵运算后面后加偏置的场景。
矩阵计算单元可以快速完成 16 x 16 的矩阵乘法,但当输入超过 16 x 16 的矩阵相运算时,需要进行分块处理,如下图。
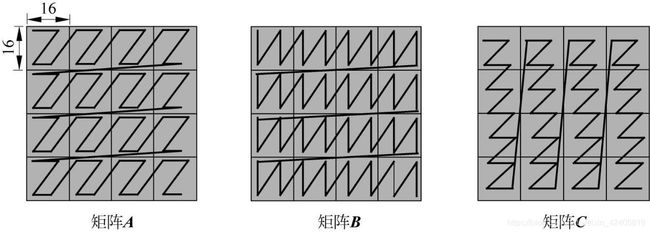
矩阵 A 的 Layout 为 大Z小Z(大Z的意思是 A 的各个分块之间按行排序,小Z的意思是每个块内部按行排序),矩阵 B 的 Layout 为 大 Z 小 N,得到的结果矩阵 C 的 Layout 为 大N小Z。
除了支持 fp16精度,矩阵计算单元还可以支持 Int8 精度,对于 Int8 精度,矩阵计算单元可以一次完成一个 16 x 32 矩阵与一个 32 x 16 矩阵相乘的运算,可以根据神经网络对于精度要求来适当调整矩阵计算单元的运算精度,以获得更加出色的性能。
2.3 向量计算单元的计算方式
AI Core 中的向量计算单元主要负责完成和向量相关的运算,能够实现向量和标量 / 向量与向量之间的计算,包括 fp32、fp16、int32、int8 精度的计算。向量计算单元能够快速完成两个 fp16 类型的向量计算,如下图。
向量计算单元的输入和输出都保存在输出缓冲区中,对于向量计算单元来说,输入的数据可以不连续,这取决于输入数据的寻址模式。向量计算单元支持的寻址模型包括向量连续寻址和固定间隔寻址,特殊的情况下,针对地址不规律的向量,也提供了向量地址寄存器寻址来实现向量的不规则寻址。在前面的达芬奇架构总览中可以看到,向量计算单元可以作为矩阵计算单元和输出缓冲区之间的数据通路。矩阵计算完成后的结果在向输出缓冲区传输的过程中,向量计算单元可以顺便完成 Relu、池化等层的格式转换。经过向量计算单元处理后的数据可以被写回到输出缓冲区或矩阵计算单元中,以备下次计算,与矩阵计算单元形成功能互补,完善了 AI Core 对非矩阵类型数据计算的能力。
2.4 标量计算单元的计算方式
标量计算单元负责完成 AI Core 中与标量相关的运算,相当于一个微型 CPU,控制整个 AI Core 的生命活动。标量计算单元可以对程序中的循环进行控制,可以实现分支判断,其结果可以通过在事件同步模块中插入同步符的方式来控制 AI Core 中其他单元的执行。它还为矩阵计算单元和向量计算单元提供数据地址和相关参数的计算,且能够实现基本的算术运算。其他复杂度较高的标量运算则由专门的 AI CPU 完成。
在标量计算单元周围配备了多个通用寄存器 (General Purpose Register, GPR) 和专用寄存器 (Special Purpose Register, spr),通用寄存器可以用于变量或地址的寄存,为算术逻辑运算提供输入操作数和存储中间计算结果;专用寄存器可以支持指令集中一些指令的特殊功能,一般不可以直接访问,只有部分可以通过指令读写。
关于昇腾达芬奇架构的解说就到这里了,咱们下篇再见~
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !
