使用python实现反欺诈模型,不平衡采样so easy!
小天导语: 周五的夜晚,各位亲们是不是开始期待双休呢?小天今天会在不平衡数据基础上,利用python建立反欺诈模型和分析数据,模拟分类预测模型中因变量分类出现不平衡的情况并解决反欺诈以及客户违约和疾病监测等问题。只要是因变量中各分类占比悬殊,就可对其使用一定的采样方法,来提升除模型调优外的精度。
研究方向: python,反欺诈模型
原理介绍
与其花大量的时间对建好的模 型进行各种调优操作,不如在一开始就对源数据进行系统而严谨的处理。而数据处理背后的算法原理又常是理解代码的支撑。所以本节将详细介绍不平衡采样的多种方法。
在以往的学习中,数据大多是 对称分布 的,就像下图一样,即正负样本的数量相当。
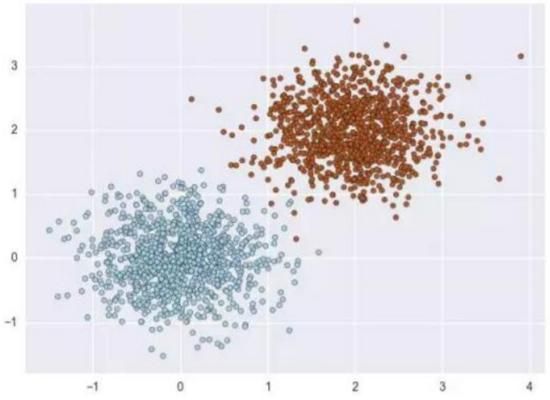
这样可以更好的把注意力集中在特定的算法上,而不被其他问题干扰。以分离算法为例,它的目标是尝试学习出一个能够分辨二者的分离器(分类器)。根据不同的数学、统计或几何假设,达成这一目标的方法很多:逻辑回归,岭回归,决策树,和各种聚类算法等。
但当我们开始面对真实的、未经加工过的数据时,很快就会发现这些数据要嘈杂且不平衡得多。真实数据看起来更像是如下图般毫无规律且零散。对于不平衡类的研究通常认为 “不平衡” 意味着少数类只占 10% ~ 20%。但其实这已经算好的了,在现实中的许多例子会更加的不平衡(1~2%),如规划中的客户信用卡欺诈率,重大疾病感染率等。就像下图一样
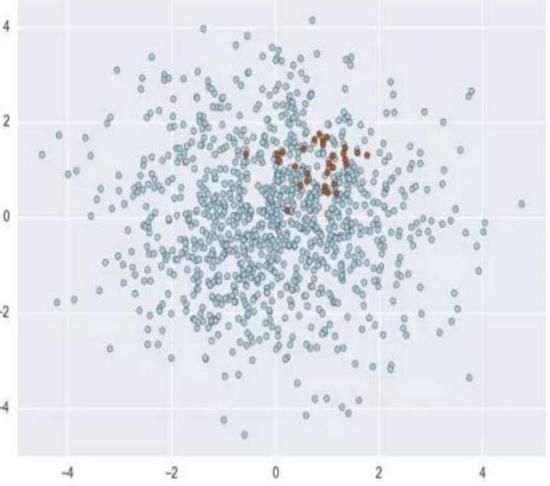
如果我们拿到像上图那样的数据,哪怕经过了清洗,已经非常整洁了,之后把它们直接丢进逻辑回归或者决策树和神经网络模型里面的话,效果一定会见得好吗?。以根据患者体征来预测其得某种罕见病为例:可能模型在预测该患者不得病上特准,毕竟不得病的数据占到了98%,那把剩下的得病的那 2% 也都预测成了不得病的情况下模型的整体准确度还是非常高...但整体准确度高并不代表模型在现实情况就能有相同的优良表现,所以最好还是能够拿到 1:1 的数据,这样模型预测出来的结果才最可靠。
所以对于这类数据,常见而有效的处理方式有基本的数据处理、调整样本权重与使用模型等三类。
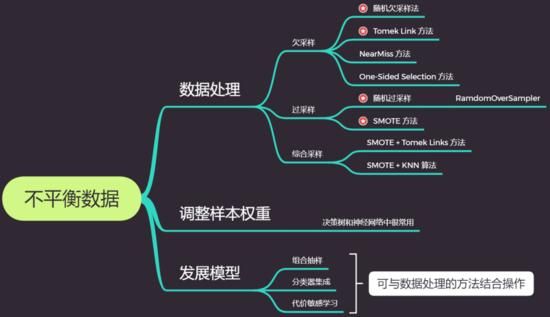
本文将专注于从数据处理的角度来解决数据不平衡问题,后续推文会涉及使用模型来处理。
注意事项:
- 评估指标:使用精确度(Precise Rate)、召回率(Recall Rate)、Fmeasure或ROC曲线、准确度召回曲线(precision-recall curve);不要使用准确度(Accurate Rate)
- 不要使用模型给出的标签,而是要概率估计;得到概率估计之后,不要盲目地使用0.50的决策阀值来区分类别,应该再检查表现曲线之后再自己决定使用哪个阈值。
问:为什么数据处理的几种采样方法都只对训练集进行操作?
答:因为原始数据集的 0-1 比为 1:99,所以随即拆分成的训练集和测试集的 0-1 比也差不多是 1:99,又因为我们用训练集来训练模型,如果不对训练集的数据做任何操作,得出来模型就会在预测分类0的准度上比1高,而我们希望的是两者都要兼顾,所以我们才要使用欠采样或者过采样对训练集进行处理,使训练集的 0-1 比在我们之前聊到的 1:1 ~ 1:10 这个比较合适的区间,用这样的训练集训练出来的模型的泛化能力会更强。以打靶作为比喻,靶心面积很小,对应了占比小的违约客户群体。在 0-1 比为 1:99 的测试集的严酷考验下,模型打中靶心(成功预测违约客户)与打中靶心周围(成功预测履约客户)的概率都得到了保证。
欠采样与过采样
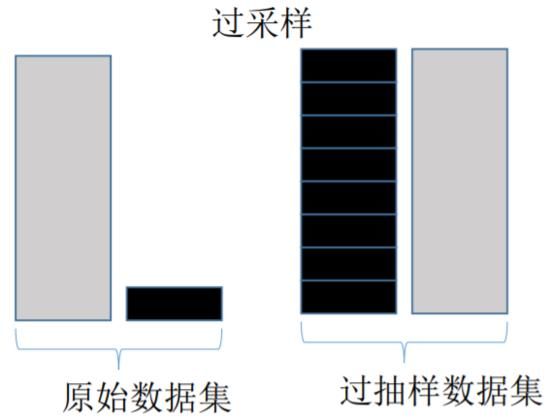
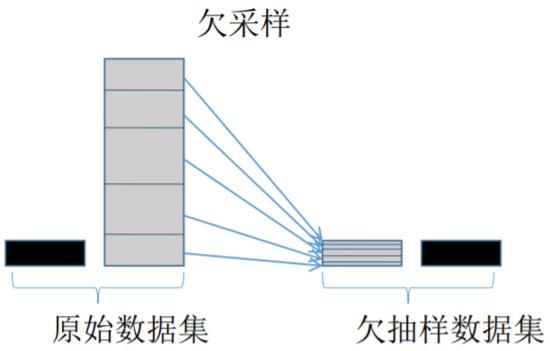
过采样会随机复制少数样例以增大它们的规模。欠采样则随机地少采样主要的类。一些数据科学家(天真地)认为过采样更好,因为其会得到更多的数据,而欠采样会将数据丢掉。但请记住复制数据不是没有后果的——因为其会得到复制出来的数据,它就会使变量的方差表面上比实际上更小。而过采样的好处是它也会复制误差的数量:如果一个分类器在原始的少数类数据集上做出了一个错误的负面错误,那么将该数据集复制五次之后,该分类器就会在新的数据集上出现六个错误。相对地,欠采样会让独立变量(independent variable)的方差看起来比其实际的方差更高。
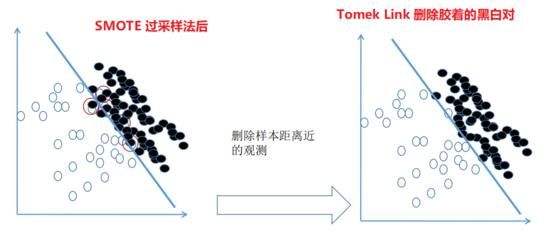
Tomek Link 法欠采样
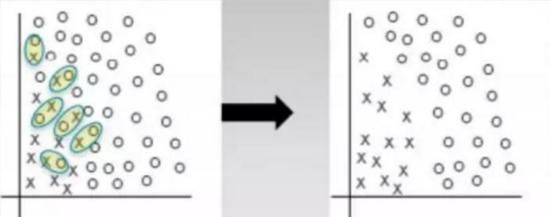
上图为 Tomek Link 欠采样法的核心。不难发现左边的分布中 0-1 两个类别之间并没有明显的分界。Tomek Link 法处理后,将占比多的一方(0),与离它(0)最近的一个少的另一方 (1) 配对,而后将这个配对删去,这样一来便如右边所示构造出了一条明显一些的分界线。所以说欠采样需要在占比少的那一类的数据量比较大的时候使用(大型互联网公司与银行),毕竟一命抵一命...
Random Over Sampling 随机过采样
随机过采样并不是将原始数据集中占比少的类简单的乘个指定的倍数,而是对较少类按一定比例进行一定次数的随机抽样,然后将每次随机抽样所得到的数据集叠加。但如果只是简单的随机抽样也难免会出现问题,因为任意两次的随机抽样中,可能会有重复被抽到的数据,所以经过多次随机抽样后叠加在一起的数据中可能会有不少的重复值,这便会使数据的变异程度减小。所以这是随机过采样的弊端。
SMOTE 过采样
SMOTE 过采样法的出现正好弥补了随机过采样的不足,其核心步骤如下图
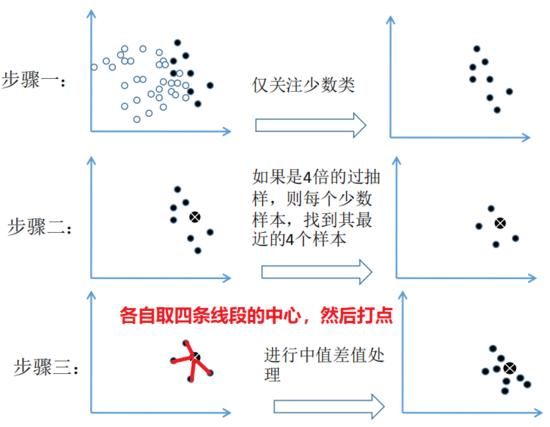
但SMOTE 并不是一点坏处都没有。上图的数据分布 SMOTE 方法的步骤示意图是比较理想的情况(两个类别分得还比较开),通常数据不平衡的散点图应该是像下面这样的:
而这个时候如果我们依然使用 SMOTE 来过采样的话就会出现下面的问题
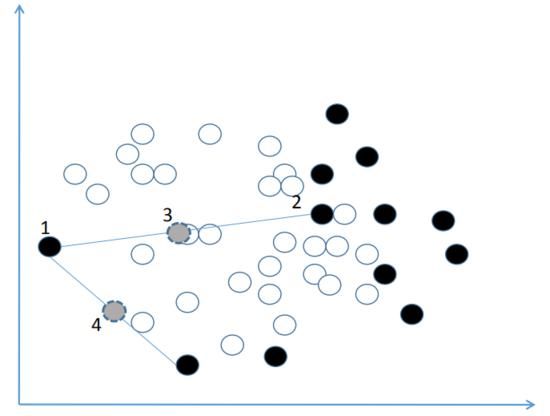
理想情况下的图中我们可以看出黑点的分布似乎是可以用一条线连起来的,而现实情况中的数据往往太过分散,比如上图中的黑点是呈现U型曲线的分布,在这个情况下,SMOTE 算法的第四步作中间插值后,可能这个新插入的点刚好就是某个白点所在的点。本来是 0 的地盘,密密集集的0当中突然给生硬的插进去了一个1......这就使数据又重复了
综合采样
综合采样的核心:先使用过采样,扩大样本后再对处在胶着状态的点用 Tomek Link 法进行删除,有时候甚至连 Tomek Link 都不用,直接把离得近的对全部删除,因为在进行过采样后,0 和 1 的样本量已经达到了 1:1。
Python实战
数据探索
首先导入相关包
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
为了方便叙述建模流程,这里准备了两个脱敏数据集:一个训练集一个测试集
train = pd.read_csv('imb_train.csv')
test = pd.read_csv('imb_test.csv')
print(f'训练集数据长度:{len(train)},测试集数据长度:{len(test)}')
train.sample(3)
稍微解释下参数:
- X1 ~ X5:自变量,
- cls:因变量 care life of science - 科学关爱生命 0-不得病,1-得病
现在查看测试集与训练集的因变量分类情况
print('训练集中,因变量 cls 分类情况:')
print(train['cls'].agg(['value_counts']).T)
print('='*55 + '\n')
print('测试集中,因变量 cls 分类情况:')
print(test['cls'].agg(['value_counts']).T)

可知训练集和测试集中的占比少的类别 1 实在是太少了,比较严重的不平衡,我们还可以使用 Counter 库统计一下两个数据集中因变量的分类情况,不难发现数据不平衡问题还是比较严重
from collections import Counter
print('训练集中因变量 cls 分类情况:{}'.format(Counter(train['cls'])))
print('测试集因变量 cls 分类情况:{}'.format(Counter(test['cls'])))
#训练集中因变量 cls 分类情况:Counter({0: 13644, 1: 356})
#测试集因变量 cls 分类情况:Counter({0: 5848, 1: 152})
不同的抽样方法对训练集进行处理
在处理前再次重申两点:
- 测试集不做任何处理!保留严峻的比例考验来测试模型。
- 训练模型时用到的数据才是经过处理的,0-1 比例在 1:1 ~ 1:10 之间拆分自变量与因变量
拆分自变量与因变量
y_train = train['cls']; y_test = test['cls'] X_train = train.loc[:, :'X5']; X_test = test.loc[:, :'X5'] X_train.sample(), y_train[:1] #( X1 X2 X3 X4 X5 # 9382 -1.191287 1.363136 -0.705131 -1.24394 -0.520264, 0 0 # Name: cls, dtype: int64)
抽样的几种方法
- Random Over Sampling:随机过抽样
- SMOTE 方法过抽样
- SMOTETomek 综合抽样
我们将用到imbalance learning这个包, pip install imblearn 安装一下即可,下面是不同抽样方法的核心代码,具体如何使用请看注释
from imblearn.over_sampling import RandomOverSampler
print('不经过任何采样处理的原始 y_train 中的分类情况:{}'.format(Counter(y_train)))
# 采样策略 sampling_strategy = 'auto' 的 auto 默认抽成 1:1,
## 如果想要另外的比例如杰克所说的 1:5,甚至底线 1:10,需要根据文档自行调整参数
## 文档:https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.RandomOverSampler.html
# 先定义好好,未开始正式训练拟合
ros = RandomOverSampler(random_state=0, sampling_strategy='auto')
X_ros, y_ros = ros.fit_sample(X_train, y_train)
print('随机过采样后,训练集 y_ros 中的分类情况:{}'.format(Counter(y_ros)))
# 同理,SMOTE 的步骤也是如此
from imblearn.over_sampling import SMOTE
sos = SMOTE(random_state=0)
X_sos, y_sos = sos.fit_sample(X_train, y_train)
print('SMOTE过采样后,训练集 y_sos 中的分类情况:{}'.format(Counter(y_sos)))
# 同理,综合采样(先过采样再欠采样)
## # combine 表示组合抽样,所以 SMOTE 与 Tomek 这两个英文单词写在了一起
from imblearn.combine import SMOTETomek
kos = SMOTETomek(random_state=0) # 综合采样
X_kos, y_kos = kos.fit_sample(X_train, y_train)
print('综合采样后,训练集 y_kos 中的分类情况:{}'.format(Counter(y_kos)))

不难看出两种过采样方法都将原来 y_train 中的占比少的分类 1 提到了与 0 数量一致的情况,但因为综合采样在过采样后会使用欠采样,所以数量会稍微少一点点
决策树建模
看似高大上的梯度优化其实也被业内称为 硬调优 ,即每个模型参数都给几个潜在值,而后让模型将其自由组合,根据模型精度结果记录并输出最佳组合,以用于测试集的验证。首先导入相关包
from sklearn.tree import DecisionTreeClassifier from sklearn import metrics from sklearn.model_selection import GridSearchCV
现在创建决策树类,但并没有正式开始训练模型
clf = DecisionTreeClassifier(criterion='gini', random_state=1234)
# 梯度优化
param_grid = {'max_depth':[3, 4, 5, 6], 'max_leaf_nodes':[4, 6, 8, 10, 12]}
# cv 表示是创建一个类,还并没有开始训练模型
cv = GridSearchCV(clf, param_grid=param_grid, scoring='f1')
如下是模型的训练数据的组合,注意!这里的数据使用大有玄机,第一组数据X,y_train是没有经过任何操作的,第二组 ros 为随机过采样,第三组 sos 为SMOTE过采样,最后一组 kos 则为综合采样
data = [[X_train, y_train],
[X_ros, y_ros],
[X_sos, y_sos],
[X_kos, y_kos]]
现在对四组数据分别做模型,要注意其实 recall 和 precision 的用处都不大,看 auc 即可,recall:覆盖率,预测出分类为0且正确的,但本来数据集中分类为0的占比本来就很大。而且recall是以阈值为 0.5 来计算的,那我们就可以简单的认为预测的欺诈概率大于0.5就算欺诈了吗?还是说如果他的潜在欺诈概率只要超过 20% 就已经算为欺诈了呢?
for features, labels in data:
cv.fit(features, labels) # 对四组数据分别做模型
# 注意:X_test 是从来没被动过的,回应了理论知识:
## 使用比例优良的(1:1~1:10)训练集来训练模型,用残酷的(分类为1的仅有2%)测试集来考验模型
predict_test = cv.predict(X_test)
print('auc:%.3f' %metrics.roc_auc_score(y_test, predict_test),
'recall:%.3f' %metrics.recall_score(y_test, predict_test),
'precision:%.3f' %metrics.precision_score(y_test, predict_test))
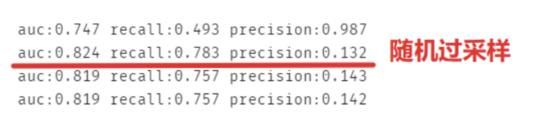
可以发现并不一定是综合采样就一定高分,毕竟每份数据集都有属于它自己的特征,不过一点都不处理的模型的 auc 是最低的。
源码获取加群:850591259