【查找算法】二分查找(C# + 递归、非递归和变种形式)
【查找算法】二分查找(C# + 递归、非递归和变种形式)
写在前面:
本文主要介绍二分查找算法,通过图片解析每一次查找的情况。代码通过C#实现,分别有递归、非递归和变种三种形式。其中变种主要解决数组出现重复数据的问题。最后,我们还分析了二分查找的局限性。
活动地址:CSDN21天学习挑战赛
本文关键字:经典算法、查找算法、二分查找、图解、C#
文章目录
- 【查找算法】二分查找(C# + 递归、非递归和变种形式)
-
-
- 一、算法效率
-
- 1. 时间复杂度
- 2. 空间复杂度
- 二、查找算法
-
- 1. 顺序(线性)查找
- 2. 二分查找/折半查找
- 3.插值查找
- 4.斐波那契查找
- 三、算法实践
-
- 1. 图解算法原理
- 2. 算法实现
-
- 非递归实现
- 递归实现
- 3. 二分查找变种
- 3.时间复杂度
- 4.空间复杂度
- 四、局限性
-
一、算法效率
1. 时间复杂度
度量一个程序(算法)执行时间的两种方法。
-
事后统计的方法
这种方法可行,但有两个问题:一是要想对设计的算法的运行性能进行评测,需要事件运行该程序;二是所得时间的统计量依赖于计算机的硬件、软件等环境因素。
-
事前估算的方法
通过分析某个算法的时间复杂度来判断哪个算法更优。
-
时间频度
一个算法花费的时间与算法中语句的执行次数成正比。一个算法中的语句执行次数称为语句频度或者时间频度。记为T(n)。
此处引用清华大学《数据结构》课程的一段话,一般情况下,算法中的基本操作语句的重复执行次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n) / f(n) 的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作 T(n)=O( f(n) ),称O( f(n) ) 为算法的渐进时间复杂度,简称时间复杂度。
2. 空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度。有的算法需要占用的临时工作单元数与解决问题的规模n有关,它随着n的增大而增大,当n较大时,将占用较多的存储单元。
二、查找算法
1. 顺序(线性)查找
最简单的查找方法。思路也很简单,从数组的一边开始,逐个进行元素的比较,如果与给定的待查找元素相同,则查找成功;如果整个扫描结束后,仍未找到相匹配的元素,则查找失败。
2. 二分查找/折半查找
是一种效率相对较高的查找方法。使用该算法的前提要求是有序数组,因为算法的核心思想是尽快的缩小搜索区间,这就需要保证在缩小范围的同时,不能有元素的遗漏。
3.插值查找
插值查找算法类似于二分查找,不同的是插值查找每次从自适应mid处开始查找。
4.斐波那契查找
斐波那契查找原理与前两种相似,仅仅改变了中间结点(mid)的位置,mid不再是中间或插值得到,而是位于黄金分割点附近。
三、算法实践
1. 图解算法原理
二分查找的思想非常简单,有点类似分治的思想。二分查找针对的是一个有序的数据集合,每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为 0。
下面通过一个动图来看一看二分查找的原理,图中也反应了二分查找与遍历查找的效率。
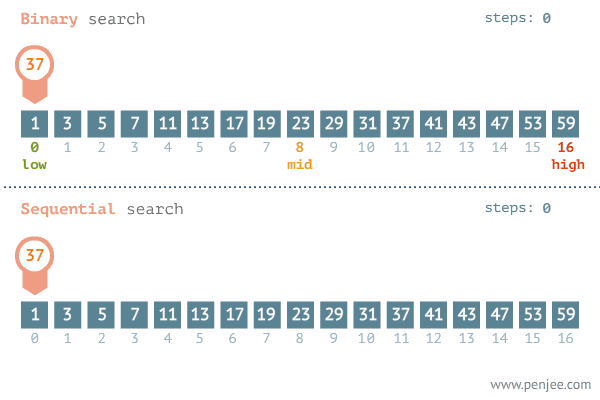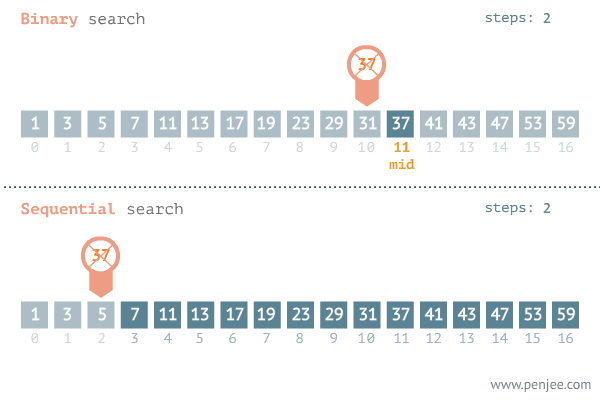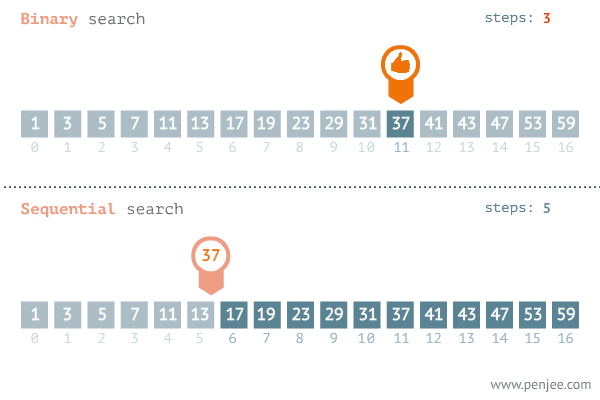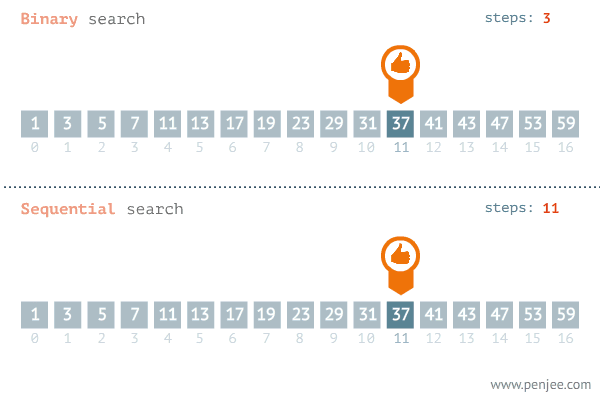
图片来源网络
二分查找的前提要求是有序数组
图中展示了二分查找的原理
图中反应二分查找与遍历查找的效率对比
那么,具体是如何查找的,我们以上面动图的数组[1,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53,59]为例。
假设我们有数组[1,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53,59],要求查找到37的索引号。
-
第
1趟
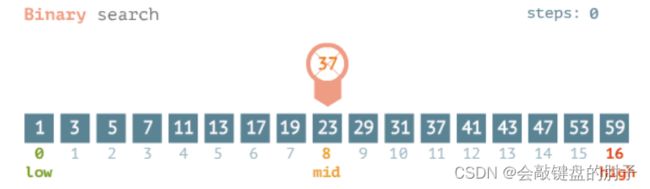
令
low = 0, high = 16,求出mid = low + (high - low) / 2 = 0 + (16 - 0) / 2 = 8。此时索引号8对应的数值是23,23 小于37,则区间变成右半部分,[9, 16]。 -
第
2趟
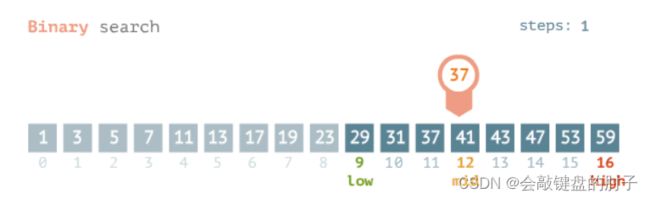
令
low = 9, high = 16,求出mid = low + (high - low) / 2 = 9 + (16 - 9) / 2 = 12。此时索引号12对应的数值是41,41大于37,则区间变成左半部分,[9, 11]。 -
第
3趟
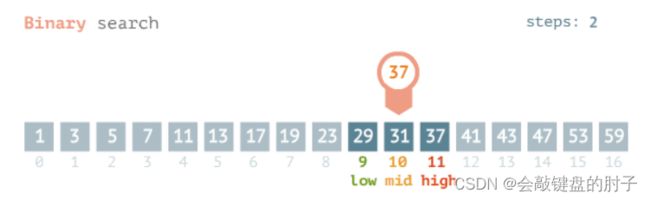
令
low = 9, high = 11,求出mid = low + (high - low) / 2 = 9 + (11 - 9) / 2 = 10。此时索引号10对应的数值是31,31小于37,则区间变成右半部分,[11, 11]。 -
第
4趟

此时low = high,返回索引号11。

与mid值相等:直接返回对应的位置(对于有重复元素的情况,会在其他子专栏中说明)。
比mid值大:由于元素有序,要查找的元素一定在左侧(如有),于是搜索区间变为左一半。
比mid值小:由于元素有序,要查找的元素一定在右侧(如有),于是搜索区间变为右一半。
2. 算法实现
首先,我们假设有序数组中不存在重复元素。
非递归实现
///
/// 二分查找静态类
///
class BinarySearch
{
///
/// 二分查找非递归方法
///
///
///
/// class Program
{
static void Main(string[] args)
{
int[] intArray = new int[] { 1, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59 };
int value = 37;
int index = BinarySearch.BinarySearchMethod(intArray,value);
Console.WriteLine($"{value}的索引号是{index}");
}
}
==============运行结果===============
查找次数3
37的索引号是11
递归实现
///
/// 二分查找递归方法
///
///
///
/// class Program
{
static void Main(string[] args)
{
int[] intArray = new int[] { 1, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59 };
int value = 37;
int index = BinarySearch.BinarySearchRecursionMethod(intArray,0, intArray.Length - 1, value);
Console.WriteLine($"{value}的索引号是{index}");
}
}
==============运行结果===============
查找次数3
37的索引号是11
3. 二分查找变种
当一个有序数组中,有多个相同的数值时,如何将所有的数值都查找到。
思路分析
- 在找到mid 索引值,不要马上返回
- 向mid 索引值的左边扫描,将所有相同的值的元素的下标,加入到集合ArrayList
- 向mid 索引值的右边扫描,将所有相同的值 的元素的下标,加入到集合ArrayList
- 将Arraylist返回
///
/// 二分查找递归方法变种
///
///
///
/// BinarySearchRecursionVarietyMethod(int[] arr, int low, int high, int value)
{
// 当 low > high 时,说明递归整个数组,但是没有找到
if (low > high)
{
return new List();
}
int mid = (high - low) / 2 + low;
int midVal = arr[mid];
if (value > midVal)
{ // 向 右递归
return BinarySearchRecursionVarietyMethod(arr, mid + 1, high, value);
}
else if (value < midVal)
{ // 向左递归
return BinarySearchRecursionVarietyMethod(arr, low, mid - 1, value);
}
else
{
List resIndexlist = new List();
//向mid 索引值的左边扫描,将所有满足的元素的下标,加入到集合List
int temp = mid - 1;
while (true)
{
if (temp < 0 || arr[temp] != value)
{//退出
break;
}
//否则,就temp 放入到 resIndexlist
resIndexlist.Add(temp);
temp -= 1; //temp左移
}
resIndexlist.Add(mid);
//向mid 索引值的右边扫描,将所有满足的元素的下标,加入到集合ArrayList
temp = mid + 1;
while (true)
{
if (temp > arr.Length - 1 || arr[temp] != value)
{//退出
break;
}
//否则,就temp 放入到 resIndexlist
resIndexlist.Add(temp);
temp += 1; //temp右移
}
return resIndexlist;
}
}
int[] intArray = new int[] { 1, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37,37,37, 41, 43, 47, 53, 59 };
int value = 37;
System.Collections.Generic.List index = BinarySearch.BinarySearchRecursionVarietyMethod(intArray,0, intArray.Length - 1, value);
此时结果输出一个List,值分别是11、12、13。
3.时间复杂度
每次比较后查找区间会呈等比数列缩小,且每一次缩小操作只涉及两个数据的大小比较,所以,经过了k 次区间缩小操作,时间复杂度就是 O(k),最终区间大小为n/2^k=1,我们可以求得 k=log2n,所以时间复杂度就是 O(logn)。
因为logn是一个非常“恐怖”的数量级,即便 n 非常非常大,对应的 logn 也很小。比如 n=2^32,这个数很大了吧?大约是 42 亿。也就是说,如果我们在 42 亿个数据中用二分查找一个数据,最多需要比较 32 次。
我们用大 O 标记法表示时间复杂度的时候,一般会省略掉常数、系数和低阶。对于常量级时间复杂度的算法来说,O(1) 有可能表示的是一个非常大的常量值,比如 O(1000)、O(10000)。所以,常量级时间复杂度的算法有时候可能还没有 O(logn) 的算法执行效率高。
上述动态图也很好的反应了这个结论:常量级时间复杂度的算法有时候可能还没有 O(logn) 的算法执行效率高。
4.空间复杂度
算法执行过程中,只需要一个临时变量来进行存储插入值,所以空间复杂度是O(1)。
四、局限性
前面我们分析过,二分查找的时间复杂度是 O(logn),查找数据的效率非常高。常量级时间复杂度的算法有时候可能还没有 O(logn) 的算法执行效率高。但是二分查找也有很大的局限性。
-
二分查找依赖的是顺序表结构
二分查找算法需要按照下标随机访问元素,只能用在数据是通过顺序表来存储的数据结构上。如果你的数据是通过其他数据结构存储的,则无法应用二分查找。
-
二分查找针对的是有序数据
如果我们的数据集合有频繁的插入和删除操作,要想用二分查找,要么每次插入、删除操作之后保证数据仍然有序,要么在每次二分查找之前都先进行排序。针对这种动态数据集合,无论哪种方法,维护有序的成本都是很高的。
-
数据量太小不适合二分查找
如果要处理的数据量很小,完全没有必要用二分查找,顺序遍历就足够了。比如我们在一个大小为 10 的数组中查找一个元素,不管用二分查找还是顺序遍历,查找速度都差不多。
-
数据量太大也不适合二分查找
二分查找的底层需要依赖数组这种数据结构,而数组为了支持随机访问的特性,要求内存空间连续,对内存的要求比较苛刻。比如,我们有 1GB 大小的数据,如果希望用数组来存储,那就需要 1GB 的连续内存空间。
写在结尾:
文章中出现的任何错误请大家批评指出,一定及时修改。
希望看到这里的小伙伴能给个三连支持!