PyTorch深度学习实践概论笔记12-循环神经网络基础篇
上一讲链接在这PyTorch深度学习实践概论笔记11-卷积神经网络高级篇。接下来12讲,来讨论一下基本的RNN(循环神经网络)。

RNN其实是对之前神经网络的复用。
0 Revision
0.1 Revision:DNN
回顾之前的DNN(深度神经网络)。
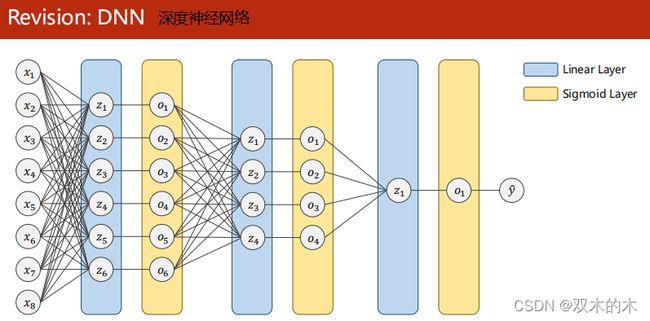
Dense网络是稠密网络,Dense连接就是指全连接。有很多线性层对输入数据进行空间上的变换,又叫DNN。输入x1,x2,…,x8是数据样本的不同特征。
考虑这样一个场景:比如预测天天气,就需要知道之前几天的数据,每一天的数据都包含若个特征(温度、气压、雨天),如果你已知今天的温度、气压等特征去预测有没有雨,这是没有用的,徐提前预测,需要之前若干天的数据作为输入。
假设现在取前3天,每一天有3个特征(温度、气压、雨天),如何预测第4天是否有雨?
第一种方法:把x1,x2,x3拼成有9个维度的长向量,然后去训练最后一天是否有雨。用全连接稠密网络进行预测,如果输入序列很长,而且每一个序列维度很高的话,对网络训练有很大挑战,因为稠密网络(全连接网络)实际上权重是最多的。对于卷积层:比如输入通道是128个,输出通道是64个,如果用55的卷积,权重数就是 25*64*188=204800,卷积层的输入输出只与通道数和卷积核的大小有关,全连接层和变换之后的数据大小有关,比如3阶张量经过一系列的卷积变换还剩下4096个元素,4096我们很少直接降成1维或者10维,而是先降成1024维,全连接层的权重为4096*1024=4194304,所以相比起来,卷积层的权重并不多,而全连接层的权重较多。全连接层是在网络的全部参数中占大头的。
为什么卷积神经网络的权重比较少呢?因为使用了权重共享的概念,做卷积时,整个图像的卷积核是共享的,并不是图像上的每一个像素要和下一层的featureMap建立连接,权重数量就少。处理视频的时候,每一帧就少一张图像,我们需要把一组图像做成一个集合,如果用全连接网络的话,使用到的权重的数量就是一个天文数字,极大可能难以处理。
所以RNN专门用来处理带有序列模式的数据,也使用权重共享减少需要训练的权重的数量。我们把x1,x2,x3看成是一个序列,不仅考虑x1,x2之间的连接关系,还考虑x1,x2的时间上的先后顺序(x2依赖于x1,x3依赖于x2),下一天的天气状况部分依赖于前一天的天气状况,RNN主要处理这种具有序列连接的数据。
天气,股市,金融,自然语言处理都是序列数据。
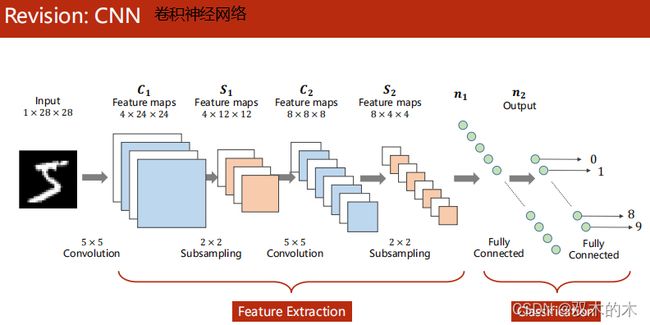
0.2 Revision:CNN
以及之前的CNN(卷积神经网络)。
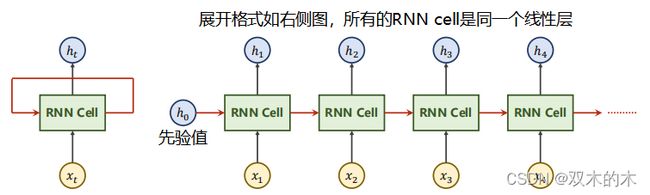
1 What is RNNs?
RNN Cell本质是一个线性层(linear),把一个维度映射到另一个维度(比如把输入的3维向量xt变成输出5维向量ht)。 这个线性层与普通的线性层的区别是这个线性层是共享的。
左侧展开就是右侧图(其中所有的RNN cell是同一个线性层,因为是展开的),h0是先验值,没有就设置成0向量(纬度和h1一样)。
RNN具体的计算过程:
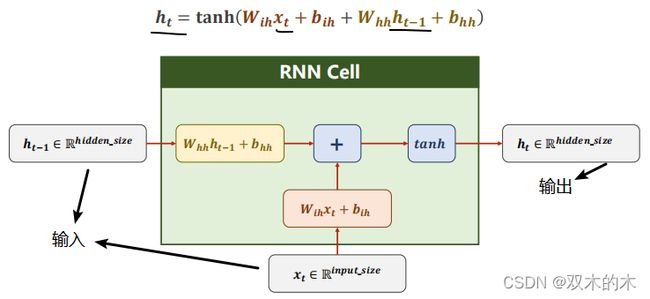
输入xt先做线性变换,h t-1也是,xt的维度是input_size,h t-1的维度是hidden_size,输出ht的维度是hidden_size。我们需要先把xt的维度变成hidden_size,所以Wih应该是一个 hidden_size*input_size的矩阵,Wihxt得到一个 hidden_size的矩阵(就是维度为hidden_size的向量),bih是偏置。输入权重矩阵Whh是一个hidden_size*hidden_size的矩阵。
whhh t-1+bhh和Wihxt+bih都是维度为hidden_size的向量,然后两个向量相加,就把信息融合起来了,融合之后用tanh做激活,循环神经网络的激活函数用的是tanh(为什么呢?因为tanh的取值在-1到+1之间),算出结果得到这一层的隐藏层输出ht。完整写出来的公式就是上图第一行的公式。
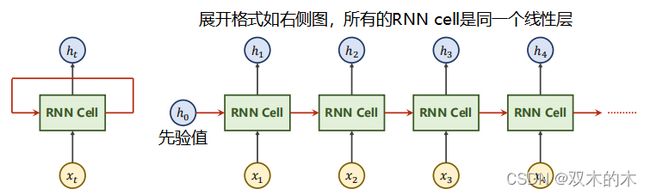
把RNN Cell以循环的方式把序列(x1,x2,…)一个一个送进去,然后依次算出隐藏层(h1,h2…)的过程,每一次算出来的h会作为下一个RNN Cell的输入,这就叫循环神经网络。
如果我们要构造RNN,在pytorch中有两种方式,我们看一下:
1.1 RNN Cell in PyTorch
方式一:构建cell
使用torch.nn.RNNCell(),需要设定输入的值input_size和隐层的值hidden_size,就能确定权重W的维度和偏置b的维度。
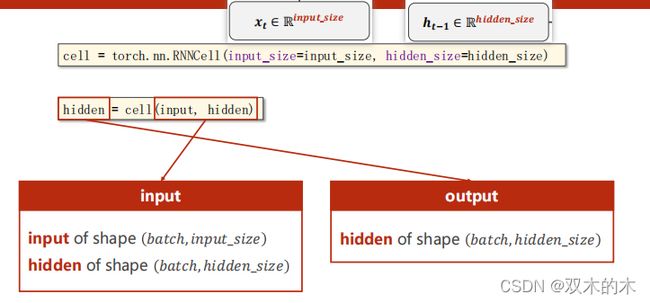
如上图,RNN本质上还是一个线性层,要弄清楚纬度。代码如下:
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
#实例化Cell后,需要给定当前的输入input以及当前的hidden,所以需要用循环来处理
hidden = cell(input, hidden)1.2 How to use RNNCell
具体看一下例子。

- batchSize表示批量大小
- seqLen=3表示每一个样本都有x1,x2,x3这些特征
- inputSize=4表示每一个特征都是4维的
- hoddenSize=2表示每一个隐藏层是2维的
代码如下:
import torch
#参数设置
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
#构造RNN单元
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
# 设置dataset的维度为(seq, batch, features)
dataset = torch.randn(seq_len, batch_size, input_size)
#初始化h0为0
hidden = torch.zeros(batch_size, hidden_size)
for idx, input in enumerate(dataset):
print('=' * 20, idx, '=' * 20)
print('Input size: ', input.shape)#Input size: torch.Size([1, 4])
hidden = cell(input, hidden)
print('outputs size: ', hidden.shape)#outputs size: torch.Size([1, 2])
print(hidden)结果如下:

将来使用RNN的时候一定要先把纬度搞清楚,RNN比之前多了一个seq_len(序列)的纬度。
方式二:直接使用RNN
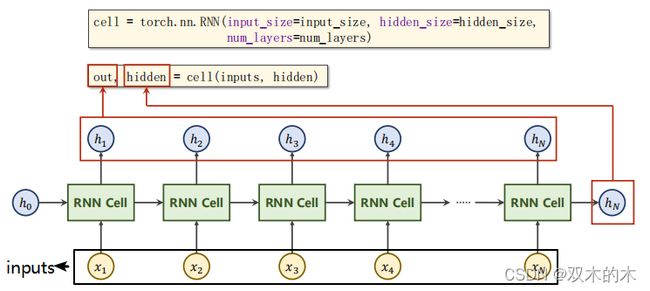
直接使用torch.nn.RNN()需要知道input_size、hidden_size和num_layers(RNN有多少层,默认为1)。cell(inputs,hidden)中 inputs指包含整个输入序列(x1,x2,x3,...xN),hidden指h0。
代码如下:
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size,num_layers=num_layers)
out,hidden = cell(inputs,hidden)具体看看上述代码的维度要求:
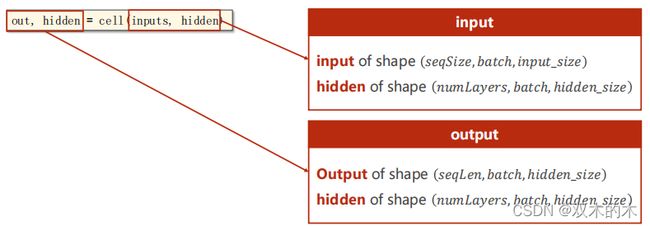
用RNN不用自己写循环,它自动循环,所以输入的时候要把所有的序列都送进去,然后给定h0,然后我们就会得到所有的隐层输出以及最后一层的输出。
看一个栗子,假设有下面的信息:

1.2.1 How to use RNN - numLayers
那么什么是numLayers?
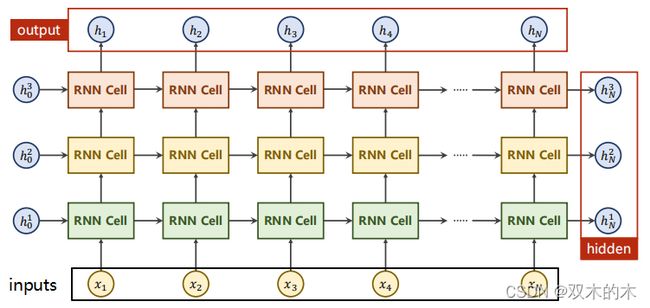
当RNN有多层,同样颜色的RNNCell是同一个,所以上图是有3个线性层(一个RNNCell是一个线性层)。这样就能解释为什么隐藏层h的纬度需要numLayers参数,因为每一层都需要。看看代码:

代码如下:
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers)
# (seqLen, batchSize, inputSize)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, hidden = cell(inputs, hidden)
print('Output size:', out.shape)
print('Output:', out)
print('Hidden size: ', hidden.shape)
print('Hidden: ', hidden)注意:如果初始化RNN时,把batch_first设置成了TRUE,那么inputs的参数batch_size和seq_len需要调换一下位置,batch_size变成第一个纬度。

代码如下:

2 Example
下面看看分别用两种构造RNN的方法来解决一个小问题。
2.1 Example 12-1
2.1.1 Example 12-1: Using RNNCell
看一个小栗子,seq到seq。训练一个模型:输入hello,输出ohlol。
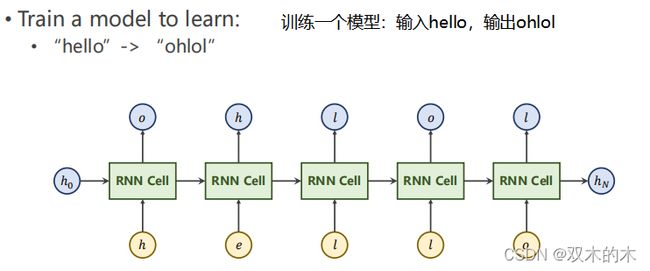
RNN Cell 的输入是向量,第一步先把字符转成向量。

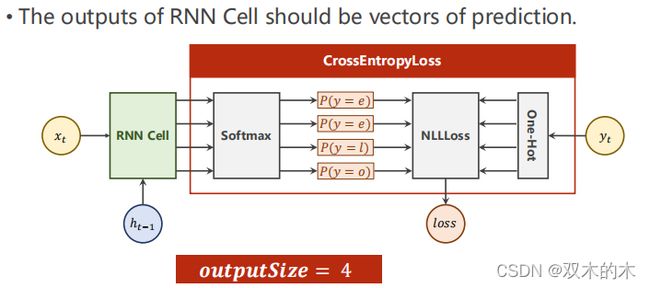
在NLP中,先根据字符构造一个词典(Dictionary),然后根据indeces转换成相应的one-hot向量。这里inputsize=4,因为输入有4个字符(e h l o)这相当于一个多分类问题,输出就是一个4维的向量,每一维代表是某一个字符的概率,接交叉熵就能输出概率了。
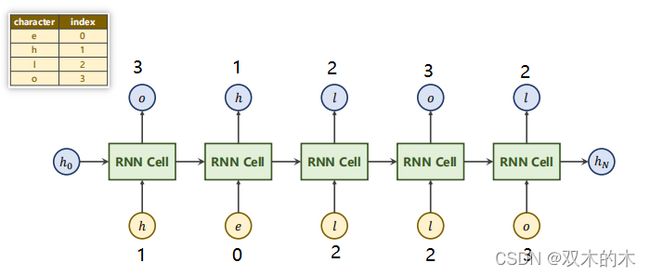
输出的output_size=4
2.1.2 Example 12-1: Code-Parameters
具体看看代码实现,如下:
#Parameters
import torch
input_size = 4
hidden_size = 4
batch_size = 1
#Prepare Data
idx2char = ['e', 'h', 'l', 'o']#字典dictionary
x_data = [1, 0, 2, 2, 3]#输入序列"hello"
y_data = [3, 1, 2, 3, 2]#输出序列"ohlol"
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]#将indice转换成one-hot向量,纬度为seq*inputsize
#改变inputs的维度为(seqLen,batchSize,inputSize)
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
#改变标签labels的维度为(seqLen,1)
labels = torch.LongTensor(y_data).view(-1, 1)
#Design Model
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
#初始化参数
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
#input维度为(batchSize,inputSize)
#hidden维度为(batchSize,hiddenSize)
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,
hidden_size=self.hidden_size)
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden)
return hidden
def init_hidden(self):
#工具方法,用来生成默认的初始化hidden
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
#Loss and Optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
#train
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print('Predicted string: ', end='')
#inputs的维度为(seqLen,batchSize,inputSize)
#input维度为(batchSize,inputSize)
#labels的维度为(seqLen,1)
#label的维度为(1)
for input, label in zip(inputs, labels):
hidden = net(input, hidden)#RNN模型
loss += criterion(hidden, label) #注意这里不要用item()!!!!因为loss是用来构造计算图的,可以直接相加
_, idx = hidden.max(dim=1)#输出预测,找到最大值的下标
print(idx2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(', Epoch [%d/15] loss=%.4f' % (epoch+1, loss.item()))结果如下:
Predicted string: eeeee, Epoch [1/15] loss=7.0864
Predicted string: ohloe, Epoch [2/15] loss=5.8847
Predicted string: ohloe, Epoch [3/15] loss=5.0372
Predicted string: ohlol, Epoch [4/15] loss=4.3152
Predicted string: ohlol, Epoch [5/15] loss=3.7545
Predicted string: ohlol, Epoch [6/15] loss=3.3624
Predicted string: ohlol, Epoch [7/15] loss=3.0933
Predicted string: ohlol, Epoch [8/15] loss=2.9041
Predicted string: ohlol, Epoch [9/15] loss=2.7653
Predicted string: ohlol, Epoch [10/15] loss=2.6594
Predicted string: ohlol, Epoch [11/15] loss=2.5755
Predicted string: ohlol, Epoch [12/15] loss=2.5040
Predicted string: ohlol, Epoch [13/15] loss=2.4336
Predicted string: ohlol, Epoch [14/15] loss=2.3505
Predicted string: ohlol, Epoch [15/15] loss=2.2406PPT结果:

2.2 Example 12-2
2.2.1 Example 12-2: Using RNN Module
接下来直接使用RNN,就简单许多。
2.2.2 Example 12-2:Change Model
代码如下:
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(Model, self).__init__()
#input_size = 4
#hidden_size = 4
#num_layers = 1
#batch_size = 1
#seq_len = 5
self.num_layers = num_layers#1
self.batch_size = batch_size#1
self.input_size = input_size#4
self.hidden_size = hidden_size#4
self.rnn = torch.nn.RNN(input_size=self.input_size,
hidden_size=self.hidden_size,num_layers=num_layers)
def forward(self, input):
#hidden维度为(, , )
hidden = torch.zeros(self.num_layers,
self.batch_size,
self.hidden_size)
out, _ = self.rnn(input, hidden)
#out维度为( × , )
return out.view(-1, self.hidden_size)
net = Model(input_size, hidden_size, batch_size, num_layers)2.2.3 Example 12-2:Change Data
代码如下:
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
#inputs的维度为(seqLen,batchSize,inputSize)
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
#labels的维度为(seqLen*batchSize,1)
labels = torch.LongTensor(y_data)训练代码:
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
#训练
optimizer.zero_grad()
outputs = net(inputs)#inputs纬度seq,batchsize,inputsize
loss = criterion(outputs, labels)#lables纬度seq,batchsize,1
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))结果如下:
Predicted: ooooo, Epoch [1/15] loss = 1.334
Predicted: ooooo, Epoch [2/15] loss = 1.200
Predicted: ooool, Epoch [3/15] loss = 1.082
Predicted: ohool, Epoch [4/15] loss = 0.992
Predicted: ohlol, Epoch [5/15] loss = 0.928
Predicted: ohlol, Epoch [6/15] loss = 0.880
Predicted: ohlol, Epoch [7/15] loss = 0.842
Predicted: ohlol, Epoch [8/15] loss = 0.807
Predicted: ohlol, Epoch [9/15] loss = 0.771
Predicted: ohlol, Epoch [10/15] loss = 0.732
Predicted: ohlol, Epoch [11/15] loss = 0.694
Predicted: ohlol, Epoch [12/15] loss = 0.660
Predicted: ohlol, Epoch [13/15] loss = 0.633
Predicted: ohlol, Epoch [14/15] loss = 0.615
Predicted: ohlol, Epoch [15/15] loss = 0.601PPT结果:

2.2.4 Associate a vector with a word/character
接下来看看在nlp中的one-hot向量。

因为one-hot encoding存在高维度、离散、硬编码的问题,我们一般采用一个更流行、更高效的方式——embedding。
2.2.5 One-hot vs Embedding
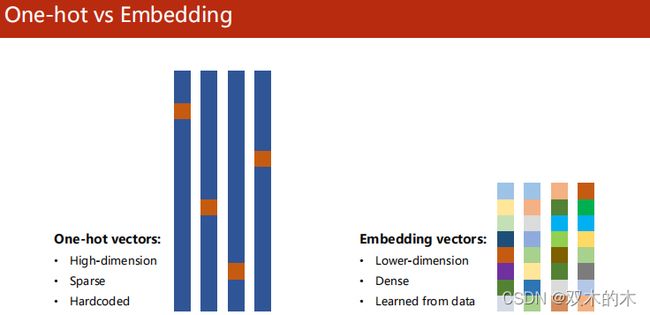
embedding将高维离散的数据映射到加低维稠密的空间,就是常说的数据降维。在输入层和RNN层之中。
2.3 Example 12-3
2.3.1 Example 12-3:Using embedding and linear layer
接下来看看加入了嵌入层然后写代码。
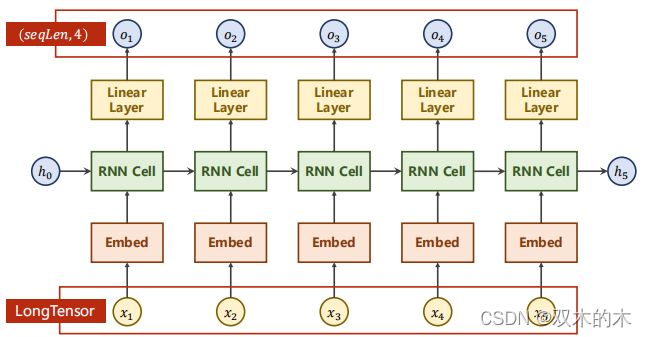
最后连接一个线性层是为了保证输出一致。
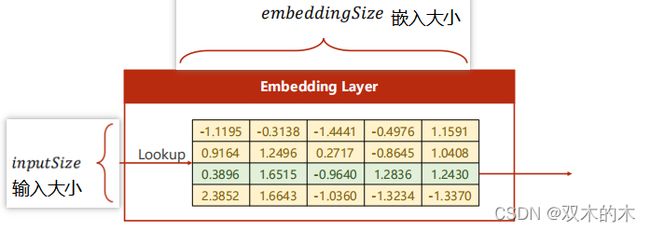
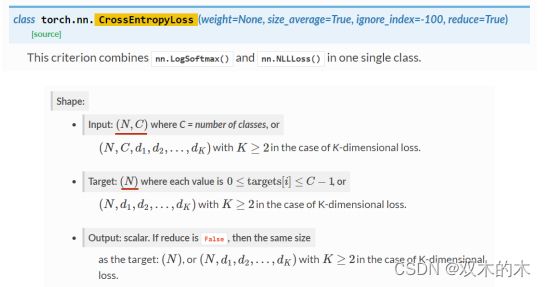
下面查看官方文档,注意各个维度的匹配问题。Input的纬度是seq*batchsize。
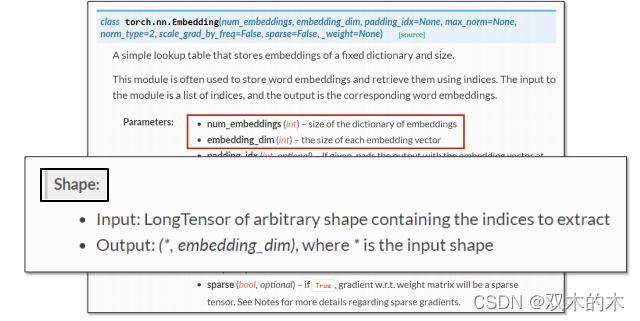
torch.nn.Embedding:
torch.nn.Linear:

torch.nn.CrossEntropyLoss:
网络结构的代码如下:
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
#embedding矩阵大小
self.emb = torch.nn.Embedding(input_size, embedding_size) #4,5
#RNN输入维度为(, , embedding)
#RNN输出维度为(, , )
self.rnn = torch.nn.RNN(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)#batchSize在input和output维度第一位
#FC输入维度为(, , )
#FC输出维度为(, , )
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x) #输入纬度为(batchSize,seqLen),输出维度为(batchSize, seqLen, embeddingSize)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
#Reshape result to use Cross Entropy Loss:( × , )
return x.view(-1, num_class)
# parameters
num_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]] # (batch, seq_len)
y_data = [3, 1, 2, 3, 2] # (batch * seq_len)
#Input should be LongTensor:(, )
#Target should be LongTensor:( × )
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
#构造模型
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))结果如下:

Predicted: lllll, Epoch [1/15] loss = 1.412
Predicted: lllll, Epoch [2/15] loss = 1.038
Predicted: lhlll, Epoch [3/15] loss = 0.799
Predicted: ohlol, Epoch [4/15] loss = 0.652
Predicted: ohloo, Epoch [5/15] loss = 0.548
Predicted: ohlol, Epoch [6/15] loss = 0.459
Predicted: ohlol, Epoch [7/15] loss = 0.381
Predicted: ohlol, Epoch [8/15] loss = 0.313
Predicted: ohlol, Epoch [9/15] loss = 0.248
Predicted: ohlol, Epoch [10/15] loss = 0.188
Predicted: ohlol, Epoch [11/15] loss = 0.136
Predicted: ohlol, Epoch [12/15] loss = 0.098
Predicted: ohlol, Epoch [13/15] loss = 0.072
Predicted: ohlol, Epoch [14/15] loss = 0.055
Predicted: ohlol, Epoch [15/15] loss = 0.043在此基础上还可以构建更为复杂的LSTM和GRU模块。
3 Exercise
3.1 Exercise 12–1:Using LSTM
练习12-1 使用LSTM(可解释性不强)
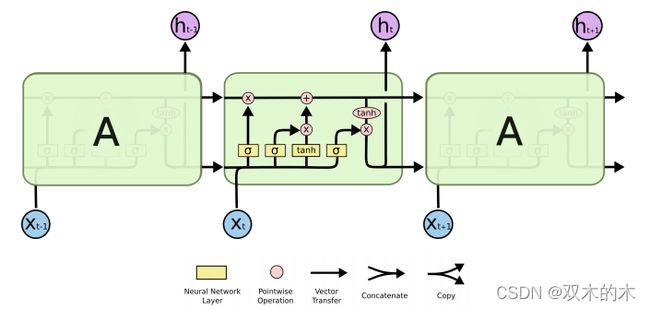
torch.nn.LSTM()源码:

ref:torch.nn — PyTorch 1.10.1 documentation
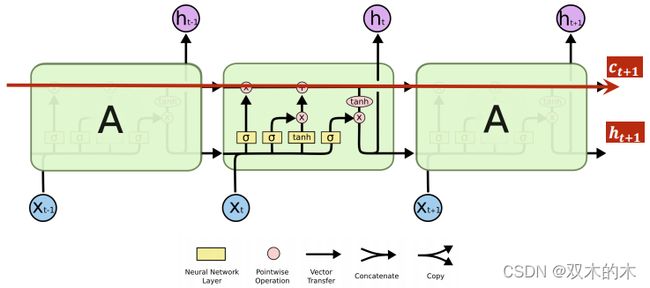
上图可以减少梯度传播的症状(可解释)。
源码:

一般来说,LSTM比RNN效果好,但计算复杂,运算性能比较低,现在更流行的是GRU。
3.2 Exercise 12–2:Using GRU
练习12-1 使用GRU,下面是公式实现:
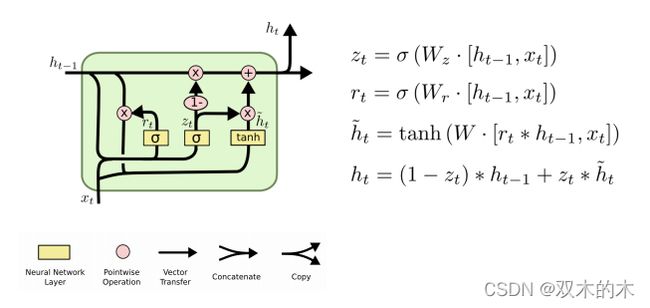
torch.nn.GRU()源码:

ref:https://pytorch.org/docs/stable/nn.html#gru

总结:使用RNN首先要理解序列数据的纬度,然后理解循环过程的权重共享机制。 第3节练习之后会补上,留意评论区。
说明:记录学习笔记,如果错误欢迎指正!写文章不易,转载请联系我。