记录大佬面经第四周
第一天
顺丰一二面
一面(4月7号)武汉java岗
由于网络延迟,从笔记本视频面试转电话面试,期间网络一直不好,连联通的信号也不好,就听到了几个问题。
1.数组转list的方式
解:
List list = Arrays.asList(strArr); 2.hashset相关
3.为什么重写equals要重写hashcode方法
解:我们知道判断的时候先根据hashcode进行的判断,相同的情况下再根据equals()方法进行判断。如果只重写了equals方法,而不重写hashcode的方法,会造成hashcode的值不同,而equals()方法判断出来的结果为true。
4.spring如何控制事务
解:spring的事务是通过“声明式事务”的方式对事务进行管理,即在配置文件中进行声明,通过AOP将事务切面切入程序。
5.和项目相关,springcloud中feign如何配置连接超时时间,hystrix的工作原理
总耗时为30min,和面试官沟通不畅,面试官说给我个机会,但是分数不高,确实,按照前端小伙伴们的查询方法,一面才3.0分
二面(4月13号)
该面面试官说时间不够不用自我介绍,直接开问
1.hashmap(让我别说太细,大概就好,怕时间不够)
2.多线程
3.synchronized锁的底层原理(升级后的策略)
4.volatile以及cas原理,cas底层实现
5.string以及stringbuffer
6.计算机网络,tcp拥塞控制
7.红黑树,b+树原理,数据库为什么选择b+
8.数据库事务
9.mybatis # $区别
解:#{}:占位符号,可以防止sql注入(替换结果会增加单引号‘’)。
例子:select * from user where name = #{name}; 解析成 select * from user where name = ?
${ } 仅仅为一个纯碎的 string 替换,替换结果不会增加单引号‘’
例子:select * from user where name = ${name}; 解析成:select * from user where name = “jack”;
sql预编译:
- JDBC 中使用对象 PreparedStatement 来抽象预编译语句,使用预编译。
- 预编译阶段可以优化 sql 的执行。预编译之后的 sql 多数情况下可以直接执行,DBMS 不需要再次编译,越复杂的sql,编译的复杂度将越大,预编译阶段可以合并多次操作为一个操作。
- 预编译语句对象可以重复利用。把一个 sql 预编译后产生的 PreparedStatement 对象缓存下来,下次对于同一个sql,可以直接使用这个缓存的 PreparedState 对象。
- mybatis 默认情况下,将对所有的 sql 进行预编译。
10.快排的思想
11.redis为啥快(答了个基于内存,他不满意)
解:(1)、完全基于内存
(2)、单线程工作模式(需要注意的是,这里的单线程指的是,Redis处理网络请求的时候只有一个线程,而不是整个Redis服务是单线程的),在Redis中由于是基于内存的数据库,它处理单个读写请求的速度非常快,若使用的是多线程在任务调度和线程维护上的消耗远大于处理请求的时间,这样会造成资源的浪费。
(3)、IO多路复用、
传统的方式是每检测到一个客户端连接服务器就分配一个线程去处理。
多路复用模型中,单个线程通过记录和跟踪socket连接状态来管理多个IO流,这里的IO指网络IO,多路指网络连接,复用指复用一个线程。
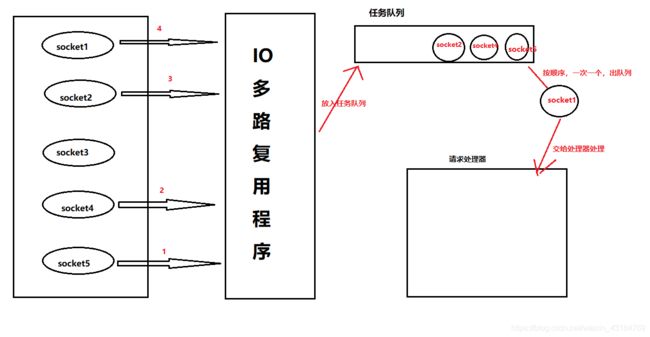
12.spring相关内容
13.熟悉的设计模式,具体实现
14.数据库的左联右联
15.开始问项目,其中微服务相关问题,以及docker使用情况
还有几个问题有点想不起来了
二面节奏很快,一直强调不要答太细,思考的时间不超过30秒,总耗时21min,结束后说等通知。按照前端小伙伴的方法,二面的成绩还刷不出来。
春招面试不容易呀,给个offer吧,期待能有hr面。
第二天
美团一面
1.项目,问的比较细,技术用来干嘛,怎么处理的
2.docker-compose部署,怎么设置环境变量,nginx作用是什么
解:在docker-compose.yml中设置环境变量
environment:
MYSQL_DATABASE: "my_database"
MYSQL_PASSWORD: "mysql"
- 1.这里的环境变量为启动容器时,传入容器的环境变量
- 2.此时镜像已经构建完成
3.JVM垃圾回收,从可达性分析到引用类型到回收算法
4.有了垃圾回收机制还需要注意什么(堆大小设置?垃圾回收器选择?)
4.1Java的finalize()方法。
https://blog.csdn.net/rsljdkt/article/details/12242007?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
5.数据库事务的理解
6.进程线程,为什么用多线程
7.redis数据类型以及用处
8.编程题,1000内素数,并且各位数之和为偶数
9.RocketMQ作用,项目中用来干嘛了,有什么好处
10.如何做一个生产者消费者模型,要注意什么?
package com.atguigu;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @program: Juc
* @description:生产者,消费者
* @author: Li huachang
* @create: 2019-12-27 16:06
*/
public class TestProAndConLock {
public static void main(String[] args) {
ClerkLock clerk=new ClerkLock();
productLock product=new productLock(clerk);
consumperLock consumper=new consumperLock(clerk);
new Thread(product).start();
new Thread(consumper).start();
}
}
//店员
class ClerkLock{
int product=10;
Lock lock=new ReentrantLock();
Condition condition= lock.newCondition();
//进货
public void get(){
lock.lock();
try {
while (product>=10){
System.out.println("产品已满");
try {
condition.await();
} catch (InterruptedException e) {
}
}
System.out.println(Thread.currentThread().getName()+" : "+ ++product);
condition.signalAll();
} finally {
lock.unlock();
}
}
//出货
public void sale(){
lock.lock();
try {
while (product<=0){
System.out.println("产品缺货");
try {
condition.await();
} catch (InterruptedException e) {
}
}
System.out.println(Thread.currentThread().getName()+" : "+ --product);
condition.signal();
} finally {
lock.unlock();
}
}
}
//生产者
class productLock implements Runnable{
ClerkLock clerk;
public productLock(ClerkLock clerk) {
this.clerk=clerk;
}
@Override
public void run() {
for (int i = 0; i < 20; i++) {
clerk.get();
}
}
}
//消费者
class consumperLock implements Runnable{
ClerkLock clerk;
public consumperLock(ClerkLock clerk) {
this.clerk = clerk;
}
@Override
public void run() {
for (int i = 0; i < 20; i++) {
clerk.sale();
}
}
}11.微服务的思想
12.微服务好处,坏处
13.最近学什么技术
14.如何看待共享单车经营
15.如何看待互联网加班
第三天
【Java后端】菜鸟一面+二面
1.项目数据库做了什么优化(提到了慢查询和explain,举例子遇到过什么慢查询,最后怎么优化的),explain一般看哪几个字段;mysql表大概有多少数据量。
解:建立索引(那些字段适合建立索引)
explain+sql语句。

具体键mmi文件
2.mysql索引底层数据结构聚簇索引和非聚簇索引叶子结点存的值分别是什么。
解:聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。注意:对于mysql数据库目前只有innodb数据引擎支持聚簇索引,而Myisam并不支持聚簇索引。
为什么用B+树而不用其他的(B树,红黑树)ICP对于聚簇索引能生效吗?
mysql事务隔离级别。
可重复读会去加什么锁,比如说查询某个字段的时候(应该是next-key lock,但是没有复习到,提到了MVCC),MVCC底层原理。
RR级别写怎么加锁,锁是锁数据还是锁索引。
间隙索引了解过吗?
3.为什么项目中用了mysql还用了hbase,如果说一条数据插入mysql成功插hbase失败怎么办?
4.分布式事务 ,有哪些常见的解决方案
5.hbase做持久化,有没有考虑过mysql分库分表。
分库分表怎么实现的(有个表很大,要分成1024份表,根据什么字段分表)。
假设已经分表了,按某个查询去查,查出来的结果希望是按照某字段有序的,那在不同表中查询出来的结果如何保证有序( union,orderby,limit),要union一千多张表呢?
6.一个链表奇数位升序,偶数位降序,如何将链表最终变成降序的。
有一个文件,80个G,每一行都是一个ip地址,在大文件中找出出现次数最多的前50个ip地址,内存最多1G。
n种硬币,比如说有面值1,5,20,25的四种硬币,每一种数量无限多,要给定一个整数,比如40,想求出最少用多少个硬币使得硬币的面值之和刚好是40。(DP)
7.TCP如何实现可靠传输的(三次握手完传输数据的过程中如何保证可靠性传输)。
四次挥手为什么要在TIME_WAIT后还要等一段时间才彻底的close掉。
解:(1)、为了保证客户端发送的最后一个ACK报文段能够到达服务器
(2)、避免新旧连接混淆(等待2MSL可以让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接请求不会出现旧的连接请求报文)
8.java线程安全的机制有哪些。
JDK的lock类如何实现公平锁和非公平锁的。
解:以ReentrantLock为例子。
ReentrantLock中主要定义了三个内部类:Sync、NonfairSync、FairSync。
abstract static class Sync extends AbstractQueuedSynchronizer {}
static final class NonfairSync extends Sync {}
static final class FairSync extends Sync {}(1)抽象类Sync实现了AQS的部分方法;
(2)NonfairSync实现了Sync,主要用于非公平锁的获取;
(3)FairSync实现了Sync,主要用于公平锁的获取。
主要属性
| 1 |
|
主要属性就一个sync,它在构造方法中初始化,决定使用公平锁还是非公平锁的方式获取锁。
主要构造方法
| 1 2 3 4 5 6 7 8 |
|
(1)默认构造方法使用的是非公平锁;
(2)第二个构造方法可以自己决定使用公平锁还是非公平锁;
上面我们分析了ReentrantLock的主要结构,下面我们跟着几个主要方法来看源码。
1.公平锁
这里我们假设ReentrantLock的实例是通过以下方式获得的:
ReentrantLock reentrantLock = new ReentrantLock(true);
// ReentrantLock.lock()
public void lock() {
// 调用的sync属性的lock()方法
// 这里的sync是公平锁,所以是FairSync的实例
sync.lock();
}
// ReentrantLock.FairSync.lock()
final void lock() {
// 调用AQS的acquire()方法获取锁
// 注意,这里传的值为1
acquire(1);
}
// AbstractQueuedSynchronizer.acquire()
public final void acquire(int arg) {
// 尝试获取锁
// 如果失败了,就排队
if (!tryAcquire(arg) &&
// 注意addWaiter()这里传入的节点模式为独占模式
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
// ReentrantLock.FairSync.tryAcquire()
protected final boolean tryAcquire(int acquires) {
// 当前线程
final Thread current = Thread.currentThread();
// 查看当前状态变量的值
int c = getState();
// 如果状态变量的值为0,说明暂时还没有人占有锁
if (c == 0) {
// 如果没有其它线程在排队,那么当前线程尝试更新state的值为1
// 如果成功了,则说明当前线程获取了锁
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
// 当前线程获取了锁,把自己设置到exclusiveOwnerThread变量中
// exclusiveOwnerThread是AQS的父类AbstractOwnableSynchronizer中提供的变量
setExclusiveOwnerThread(current);
// 返回true说明成功获取了锁
return true;
}
}
// 如果当前线程本身就占有着锁,现在又尝试获取锁
// 那么,直接让它获取锁并返回true
else if (current == getExclusiveOwnerThread()) {
// 状态变量state的值加1
int nextc = c + acquires;
// 如果溢出了,则报错
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
// 设置到state中
// 这里不需要CAS更新state
// 因为当前线程占有着锁,其它线程只会CAS把state从0更新成1,是不会成功的
// 所以不存在竞争,自然不需要使用CAS来更新
setState(nextc);
// 当线程获取锁成功
return true;
}
// 当前线程尝试获取锁失败
return false;
}
// AbstractQueuedSynchronizer.addWaiter()
// 调用这个方法,说明上面尝试获取锁失败了
private Node addWaiter(Node mode) {
// 新建一个节点
Node node = new Node(Thread.currentThread(), mode);
// 这里先尝试把新节点加到尾节点后面
// 如果成功了就返回新节点
// 如果没成功再调用enq()方法不断尝试
Node pred = tail;
// 如果尾节点不为空
if (pred != null) {
// 设置新节点的前置节点为现在的尾节点
node.prev = pred;
// CAS更新尾节点为新节点
if (compareAndSetTail(pred, node)) {
// 如果成功了,把旧尾节点的下一个节点指向新节点
pred.next = node;
// 并返回新节点
return node;
}
}
// 如果上面尝试入队新节点没成功,调用enq()处理
enq(node);
return node;
}
// AbstractQueuedSynchronizer.enq()
private Node enq(final Node node) {
// 自旋,不断尝试
for (;;) {
Node t = tail;
// 如果尾节点为空,说明还未初始化
if (t == null) { // Must initialize
// 初始化头节点和尾节点
if (compareAndSetHead(new Node()))
tail = head;
} else {
// 如果尾节点不为空
// 设置新节点的前一个节点为现在的尾节点
node.prev = t;
// CAS更新尾节点为新节点
if (compareAndSetTail(t, node)) {
// 成功了,则设置旧尾节点的下一个节点为新节点
t.next = node;
// 并返回旧尾节点
return t;
}
}
}
}
// AbstractQueuedSynchronizer.acquireQueued()
// 调用上面的addWaiter()方法使得新节点已经成功入队了
// 这个方法是尝试让当前节点来获取锁的
final boolean acquireQueued(final Node node, int arg) {
// 失败标记
boolean failed = true;
try {
// 中断标记
boolean interrupted = false;
// 自旋
for (;;) {
// 当前节点的前一个节点
final Node p = node.predecessor();
// 如果当前节点的前一个节点为head节点,则说明轮到自己获取锁了
// 调用ReentrantLock.FairSync.tryAcquire()方法再次尝试获取锁
if (p == head && tryAcquire(arg)) {
// 尝试获取锁成功
// 这里同时只会有一个线程在执行,所以不需要用CAS更新
// 把当前节点设置为新的头节点
setHead(node);
// 并把上一个节点从链表中删除
p.next = null; // help GC
// 未失败
failed = false;
return interrupted;
}
// 是否需要阻塞
if (shouldParkAfterFailedAcquire(p, node) &&
// 真正阻塞的方法
parkAndCheckInterrupt())
// 如果中断了
interrupted = true;
}
} finally {
// 如果失败了
if (failed)
// 取消获取锁
cancelAcquire(node);
}
}
// AbstractQueuedSynchronizer.shouldParkAfterFailedAcquire()
// 这个方法是在上面的for()循环里面调用的
// 第一次调用会把前一个节点的等待状态设置为SIGNAL,并返回false
// 第二次调用才会返回true
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 上一个节点的等待状态
// 注意Node的waitStatus字段我们在上面创建Node的时候并没有指定
// 也就是说使用的是默认值0
// 这里把各种等待状态再贴出来
//static final int CANCELLED = 1;
//static final int SIGNAL = -1;
//static final int CONDITION = -2;
//static final int PROPAGATE = -3;
int ws = pred.waitStatus;
// 如果等待状态为SIGNAL(等待唤醒),直接返回true
if (ws == Node.SIGNAL)
return true;
// 如果前一个节点的状态大于0,也就是已取消状态
if (ws > 0) {
// 把前面所有取消状态的节点都从链表中删除
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 如果前一个节点的状态小于等于0,则把其状态设置为等待唤醒
// 这里可以简单地理解为把初始状态0设置为SIGNAL
// CONDITION是条件锁的时候使用的
// PROPAGATE是共享锁使用的
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
// AbstractQueuedSynchronizer.parkAndCheckInterrupt()
private final boolean parkAndCheckInterrupt() {
// 阻塞当前线程
// 底层调用的是Unsafe的park()方法
LockSupport.park(this);
// 返回是否已中断
return Thread.interrupted();
}
下面我们看一下主要方法的调用关系,可以跟着我的 → 层级在脑海中大概过一遍每个方法的主要代码:
ReentrantLock#lock()
->ReentrantLock.FairSync#lock() // 公平模式获取锁
->AbstractQueuedSynchronizer#acquire() // AQS的获取锁方法
->ReentrantLock.FairSync#tryAcquire() // 尝试获取锁
->AbstractQueuedSynchronizer#addWaiter() // 添加到队列
->AbstractQueuedSynchronizer#enq() // 入队
->AbstractQueuedSynchronizer#acquireQueued() // 里面有个for()循环,唤醒后再次尝试获取锁
->AbstractQueuedSynchronizer#shouldParkAfterFailedAcquire() // 检查是否要阻塞
->AbstractQueuedSynchronizer#parkAndCheckInterrupt() // 真正阻塞的地方
获取锁的主要过程大致如下:
(1)尝试获取锁,如果获取到了就直接返回了;
(2)尝试获取锁失败,再调用addWaiter()构建新节点并把新节点入队;
(3)然后调用acquireQueued()再次尝试获取锁,如果成功了,直接返回;
(4)如果再次失败,再调用shouldParkAfterFailedAcquire()将节点的等待状态置为等待唤醒(SIGNAL);
(5)调用parkAndCheckInterrupt()阻塞当前线程;
(6)如果被唤醒了,会继续在acquireQueued()的for()循环再次尝试获取锁,如果成功了就返回;
(7)如果不成功,再次阻塞,重复(3)(4)(5)直到成功获取到锁。
以上就是整个公平锁获取锁的过程,下面我们看看非公平锁是怎么获取锁的。
2.非公平锁
// ReentrantLock.lock()
public void lock() {
sync.lock();
}
// ReentrantLock.NonfairSync.lock()
// 这个方法在公平锁模式下是直接调用的acquire(1);
final void lock() {
// 直接尝试CAS更新状态变量
if (compareAndSetState(0, 1))
// 如果更新成功,说明获取到锁,把当前线程设为独占线程
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
// ReentrantLock.NonfairSync.tryAcquire()
protected final boolean tryAcquire(int acquires) {
// 调用父类的方法
return nonfairTryAcquire(acquires);
}
// ReentrantLock.Sync.nonfairTryAcquire()
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
// 如果状态变量的值为0,再次尝试CAS更新状态变量的值
// 相对于公平锁模式少了!hasQueuedPredecessors()条件
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
相对于公平锁,非公平锁加锁的过程主要有两点不同:
(1)一开始就尝试CAS更新状态变量state的值,如果成功了就获取到锁了;
(2)在tryAcquire()的时候没有检查是否前面有排队的线程,直接上去获取锁才不管别人有没有排队呢;
总的来说,相对于公平锁,非公平锁在一开始就多了两次直接尝试获取锁的过程。
彩蛋
为什么非公平模式效率比较高?
答:因为非公平模式会在一开始就尝试两次获取锁,如果当时正好state的值为0,它就会成功获取到锁,少了排队导致的阻塞/唤醒过程,并且减少了线程频繁的切换带来的性能损耗。
线程池几个重要的参数,底层怎么实现的。
9.常见的分布式锁的实现方案有哪些
解:
redis的方案
- setnx:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
- expire:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
- delete:删除key
zookeeper方案
ZooKeeper内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。
- 创建一个目录mylock
- 线程A想获取锁就在mylock目录下创建临时顺序节点
- 获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁
- 线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点
- 线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁
使用reddisson框架
10.学校有参加过什么比赛?有没有发论文。
有主动学习或研究过什么技术吗(说到了看netty源码,RPC底层基本上都用netty,微服务)
netty现在有什么心得?如何这么高效的实现传输。
11.反问
1.你觉得你的优势是什么,项目中有哪些压力,碰到那些技术难题(一开始还以为是hr面)
2.netty看过netty细节原理么?BIO,NIO,AIO区别,100个连接创建有多少个线程?基于Nio呢?
解:BIO:同步并阻塞。NIO:同步非阻塞。AIO:异步非阻塞。
3.tcp拆包粘包
4.netty为什么高效
5.链表的二分查找
6.一个很长的数组,比如长度几个亿,堆排快排肯定有问题,怎么更快的排序
解:归并排序
7.找出一棵树两个节点的第一个公共祖先
8.一个递增数组,一个整数N,如何找出一个二元组,这二元组的两个值相加等于N,三元组呢?
9.mysql索引为什么不用红黑树而用b+树
10.计算机网络TIME_WAIT和CLOSE_WAIT,为什么是2MSL
11.操作系统页和段
解:背景:连续分配方式会形成许多“碎片”,虽然可通过“紧凑”方法将许多碎片拼接成可用的大块空间,但须为之付出很大的开销,如果允许将一个进程直接分散地装入到许多不相领接的分区中,便可充分地利用内存空间。基于这种思想而产生一下三种内存分配方式:
(1)分页机制:逻辑地址和物理地址分离的内存分配管理方案程序的逻辑地址划分为固定大小的页(Page)物理地址划分为同样大小的帧(Frame)通过页表对应逻辑地址和物理地址。
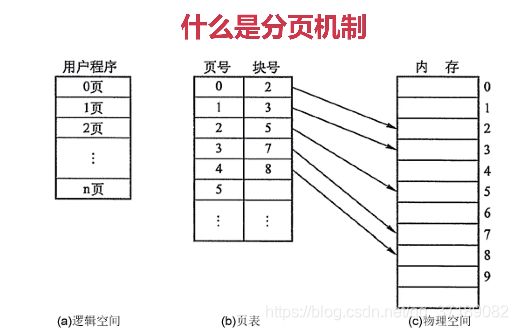
图解:左边是用户程序,对于用户程序关心的是逻辑地址,通过页表来获取物理地址。页表里面映射了逻辑地址和物理地址的对应关系,通过中间和右边图,可以看出逻辑地址对应的物理地址不一定是连续的。
(2)分段机制:分段是为了满足代码的一些逻辑需求数据共享,数据保护,动态链接等通过段表实现逻辑地址和物理地址的映射关系每个段内部是连续内存分配,段和段之间是离散分配的。
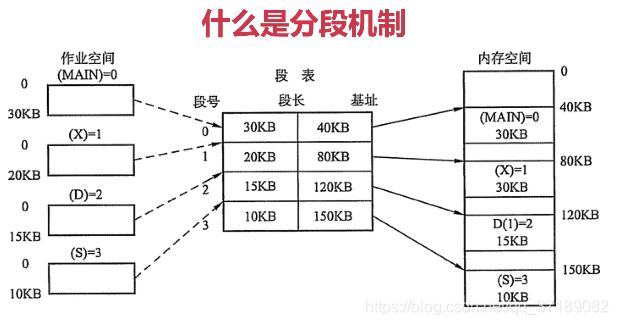
图解:段表里面主要保存的是段号、段长和起始地址(基址),通过这三个就可以确定每个段,它从那个地方开始并且它的长度是多少,段表可以把段号跟内存空间真实的物理地址对应起来。
注意:分页和分段的区别
分页 vs 分段
页是出于内存利用率的角度提出的离散分配机制
段是出于用户角度,用于数据保护,数据隔离等用途的管理机制
页的大小是固定的,操作系统决定;段大小不确定,用户程序决定
(3)段页管理:程序的地址空间划分为多个拥有独立地址空间的段,每个段上的地址空间划分为大小相同的页。这样既拥有分段系统的共享保护,又拥有分页系统的虚拟内存功能。它兼具两者的优点,是目前应用较为广泛的一种储存管理方式
第四天
阿里巴巴-蚂蚁金服-java 一面面经(已过)
1、自我介绍
2、介绍简历上项目
3、讲讲数学建模比赛收获
4、问问学校成绩
5、StringBuilder StringBuffer区别
6、Synchronized修饰类里面方法a一个线程访问了a别的线程还能访问另一个方法b吗?
解:能,可重用锁。
7、Synchronized和lock区别
解:上天的帖子里。
8、聊聊线程池关键参数(这个没仔细看过不会)
9、jvm内存模型
9、垃圾回收算法
10、了解jvm调优吗(不会)
11、类加载机制 双亲委派
12、数据库调优了解(就说了一点点索引调优,讲了b+树)
13、acid
14、事务四个隔离级别(不了解)
15、tcp四次挥手(还没有复习计网就没问了)
16、进程线程区别
17、聊聊高可用
18、还有什么要问吗
最后跟我说给我过了不可思议,20天前我连java八个基本类型都说不上来,看了很多牛客面经,自己多看看网课,现在能过一面已经很满足了。祝大家都能收获好的offer。
第五天
写在前面:蘑菇街的面试真的很硬核,凉凉
1.Map接口有哪些实现
解:hashmap、linkedhashmap、treemap
hashmap线程安全吗,会有什么问题。怎么实现一个线程安全的map
不安全,jdk1.8以前因为头插法可能导致循环链表,jdk1.8之后虽然没有循环链表了但是仍然会导致修改丢失等问题。
hashtable、concurrenthashmap、collections.synchronizedMap是安全的
linkedhashmap的应用场景
LRU
线程池的参数,他的流程是怎么样的
核心线程、最大线程、等待队列、拒绝策略、非核心线程存活时间
先请求过来创建核心线程,等核心线程创建达到指定值将请求放入等待队列,如果等待队列满了就创建非核心线程,等线程数达到最大线程就执行拒绝策略,等线程执行完毕,非核心线程空闲到指定时间就删除非核心线程
synchronized和reentranklock的实现和区别
synchronized是JVM层面的实现,锁类的话是monitorenter,monitorexit两个指令,锁方法的话是用ACC_synchronized标识来实现,在JDK1.6对synchronized进行了优化,有锁消除、锁粗化、轻量级锁、偏向锁、重量级锁等实现。
偏向锁的话就是在MarkWord上有一个当前持有线程的id和锁标识位,先检查锁标识位是不是偏向锁,然后是否指向自己线程,这样就少去了加锁步骤的开销,不是的话等持有线程运行到安全点会进行锁的膨胀,在MarkWord中会有一个指针指向持有线程栈帧中的对象,虽然有此时再有第三个线程过来或者自旋一定次数仍未获得轻量级锁,此时就要膨胀为重量级锁了,此时指针会指向monitor对象,其他线程想获得这个锁会阻塞。
reentranklock的底层是AQS,而AQS是CLH队列的增强,CLH底层实现了一个虚拟节点的双向链表,每个节点会自旋查询前面一个节点的情况。AQS在此基础上做了增强,支持可重入、可中断、不是一直自旋支持阻塞、支持非公平、支持独占和共享。reentranklock默认是非公平可重入锁。
(这里我面试的时候直接就奔原理去了,上来就说了synchronized的原理,等说到reentranklock还没开始面试官就让我停了,我后来复盘才意识到,他仅仅是让我说区别罢了,那么补充下区别)
synchronized是JVM的实现,是非公平可重入锁,代码执行完毕会在自动 放弃锁。
reentranklock是java类的实现,默认是非公平可重入锁,但是可以实现公平锁,选择性通知。需要在finally去unlock
怎么实现一个不可重入的锁
在reentranklock里面获取锁state会+1,,并判断是否是当前线程拿到的锁,那么直接把这个判断去了就行,如果state>0,就不能再获取锁。
mybatis的缓存实现,如果数据库进行修改了缓存怎么办
sqlsession一级缓存和二级缓存。
就一级缓存而言,数据库进行修改会导致一级缓存失效,
就二级缓存而言,因为他的作用域是namespace,如果有连表查询,而这个连表查询是写在某一个namespace里的,会导致脏数据的产生。
数据库和redis的一致性问题怎么解决的,如何保证强一致性
先更新数据库,再删除缓存。
那会出现一致性问题,
(1)缓存刚好失效
(2)请求A查询数据库,得一个旧值
(3)请求B将新值写入数据库
(4)请求B删除缓存
(5)请求A将查到的旧值写入缓存
怎么解决? 答:异步双删,在请求B写入数据库后,开启一个异步线程,此线程等待一会后,再去删除缓存。这个等待时间 一般是查请求的执行时间加上一定的数值。
再问:仍然会有一致性问题,在B写入而缓存还没删除的时候。再答:用分布式锁,将写操作和缓存失效的操作变为原子操作。写数据时,首先尝试加锁。此锁锁定1秒时间。如果加锁成功,开始更新数据库。无论更新失败或者成功都解锁。如果成功,同时使缓存过期。
你项目中是怎么用redis的,为什么这么用,解决了什么问题,
发布/订阅来实现消息的发送
在访问主页的时候从数据库加载值时放到缓存中并设置失效时间,用作缓存,并且再将这个数据放到布隆过滤器里来解决缓存穿透的问题。
缓存击穿是怎么实现的?
分布式锁、我项目里的话只是简单的对查询加了一个排它锁。
秒杀系统怎么解决超卖问题,还有其他实现方式吗
我项目里的话只是用了Spring的声明式事务,相当于在数据库层面加排它锁来实现。
其他实现方式的话比如乐观锁,但是冲突会比较大。
还有就是引入redis的String,借助redis串行化的特点,比如有100件商品,设置值为100,每次请求进来判断是否大于0,如果大于0把这个值-1,去访问数据库减库存。
可以把剩下一部分请求(比如50个)加入到消息队列中,剩下一部分全部拒绝掉。消息队列中的这部分请求用来处理可能出现的问题(因为你秒杀肯定是一个订单支付的操作,然后再去扣库存嘛,先是订单支付,你去操作数据库了,这个时候哪100个里有有一个人钱不够了,导致订单支付失败,然后后续操作都没法进行,这个时候我们消息队列里的50个请求就有用了。我是这么理解的,不知道具体情况怎么样。。)
redis的分布式锁有了解过吗,怎么实现的
redission就可以实现,原理的话就是用setnx来创建锁并设置锁的过期时间,然后有一个watchdog来对锁进行加时,方式锁到期请求还没处理完的情况,最后使用lua脚本将判断锁和删除锁写一起使其变成一个原子操作来完成锁的释放。
redission是可重入的吗?如果要实现分布式锁的可重入怎么实现
是可重入的、可以通过请求带来一个UUID,然后保存起来,下次再来请求先判断是不是这个UUID,如果是话就重入。
dubbo的流程,默认用的什么序列化方法,为什么这么用
服务提供方在容器中启动,将服务暴露到注册中心,消费者向注册中心订阅自己所需的服务,注册中心会提供消费者的地址列表,如果有变更,以zookeeper为例,也会较快收到变更的信息,从地址列表中,基于负载均衡算法,选一个提供者。消费者和提供者都会定时向监控中心返回方法的调用次数和调用时间。
默认序列化方法:hession2,为什么?不知道
数据库的隔离级别,用的什么引擎,他的ACID,这四个特性每一个MySQL是怎么保证的
readuncommited
readcommited
repeatedtable
seriazable
用的Innodb,持久性由redolog保证,就算断电也可以根据redolog进行未完成的事务,原子性由undolog保证,等undolog提供了回滚的特性,隔离性由MVCC机制保证,通过对每行数据加一个当前版本号和删除版本号的隐藏字段来保证事务间的隔离,一致性由前面三者保证,C是目的,AID是手段。
权限的实现,你自己的实现和shiro,springsecurity有什么区别,你会怎么优化
没了解过shiro和springsecurity
遇到过最难的事情是什么
还有什么想问我的
了解到蘑菇街会有一个缓存中台,然后数据库都是单表查询,查出来之后再去拼接?是自己实现的嘛还是有现成的框架。
看业务,有些是这么实现的,是公司自己实现的。
这是跟我一起面试的同学的面经,我三点钟他五点钟。
1.上来就手撕,链表快排(不能把链表转为数组)
[快速排序——链表快排](https://blog.csdn.net/u012114090/article/details/81751259)
2.java对象创建过程,引用和对象分别是什么时候被gc的
说一说类的加载机制?
虚拟机把描述类的Class文件加载到内存中,并对其验证、准备、解析、初始化,最终形成可以被虚拟机直接使用的Java类型。
类加载检查-->分配内存-->初始化零值-->设置对象头-->执行init方法
强引用:不会被gc
软引用:内存不足时候gc
弱引用:每次垃圾回收时
虚引用:gc时间未知,它的作用在于跟踪垃圾回收过程,在对象被收集器回收时收到一个系统通知。 当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在垃圾回收后,将这个虚引用加入引用队列,在其关联的虚引用出队前,不会彻底销毁该对象。 所以可以通过检查引用队列中是否有相应的虚引用来判断对象是否已经被回收了。
对象是什么时候被gc的?
由引用计数法或者可达性分析来判断对象是否可以被gc
3.半初始化过程
emm? 这是啥 我不知道
4.说说volatile关键字吧,有哪几种屏障?
volatile主要保证的是可见性和防止指令重排。
一般可见性方面,volatile可以使得本线程内的缓存失效,也就是读volatile变量的时候直接从内存中读,而写volatile变量的时候直接写入内存
volatile提供了四个内存屏障,loadstore读写、loadload读读、storestore写写、storeload写读
来保证指令不会重排序
来看下重排序可能导致的危害:
线程A:
context = loadContext();
inited = true;
线程B:
while(!inited ){ //根据线程A中对inited变量的修改决定是否使用context变量
sleep(100);
}
doSomethingwithconfig(context);
假设线程A中发生了指令重排序:
inited = true;
context = loadContext();
那么B中很可能就会拿到一个尚未初始化或尚未初始化完成的context,从而引发程序错误。
还有可能比如不安全发布的问题(比如单例模式中不写volatile的话可能会拿到由于重排序导致的”半个单例“,比如以下情况导致的尚未初始化的对象。
memory = allocate(); //1:分配对象的内存空间
instance = memory; //3:设置instance指向刚分配的内存地址(此时对象还未初始化)
ctorInstance(memory); //2:初始化对象
)
5.gc过程,为什么要分代
为什么分代:对于年轻代的对象,由于对象来的快去得快,垃圾收***比较频繁,因此执行时间一定要短,效率要高,因此要采用执行时间短,执行时间的长短只取决于对象个数的垃圾回收算法。但是这类回收器往往会比较浪费内存,比如Copying GC,会浪费一半的内存,以空间换取了时间。
对于老年代的对象,由于本身对象的个数不多,垃圾收集的次数不多,因此可以采用对内存使用比较高效的算法。
gc过程:
这里就简单说说CMS和G1的区别吧
CMS:
一开始先标记GC Roots能直接标记到的对象(会停顿)
然后开始延伸(不会停顿)
再之后修正并发标记期间,因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录(会停顿)
最后就是清理啦,因为不需要移动存活对象,所以这个阶段也是可以与用户线程同时并发的。(不会停顿,浮动垃圾也是这步产生的,cms用的是标记清除)
G1:先是标记GC Roots能直接关联到的对象(会停顿)
扫描整个堆里的对象图(并发标记,不停顿)
对用户线程进行暂停,处理并发标记的时候变动的对象(开始停顿)
筛选回收垃圾(根据设置的数值来控制回收的内存中垃圾大小)
可以看到最后一步G1是停顿的而CMS不会停顿,这也是CMS会产生浮动垃圾的原因
6.synchronized和lock哪个效率高,为什么,底层实现
1.6之后差不多,为什么?因为1.6之后也可以用cas来实现啦(如果没有膨胀到重量级锁的话)。我的面经已经讲过啦
7.hashmap为什么在链表长度为8时转化为红黑树。(泊松分布)
红黑树的平均查找长度是log(n),长度为8,查找长度为log(8)=3,链表的平均查找长度为n/2,当长度为8时,平均查找长度为8/2=4,这才有转换成树的必要;链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。