JVM内存区域划分_JVM类加载机制_双亲委派模型_垃圾回收策略GC(JVM)
目录
- 本章要点
- JVM执行流程
- 内存区域划分
-
- 程序计数器
- 栈
- 堆(线程共享)
- 方法区
- 类加载过程
-
- 经典面试代码题
- 双亲委派模型
- 垃圾回收策略(GC)
-
- 基于引用计数
- 基于可达性分析
- 标记清除
- 复制算法
- 标记整理
- 分代回收
- 垃圾收集器
本章要点
- JVM内存区域组成和内存区域划分后不同区域的功能
- JVM类加载机制和类加载流程
- 双亲委派模型
- JVM中的垃圾回收机制(GC)
JVM执行流程
我们知道JVM就我们的java虚拟机(Java Virtual Machine)的简称!
java执行一个java文件的流程:
程序在执行之前先要把java代码转换成字节码(class文件),JVM 首先需要把字节码通过一定的方式类加载器(ClassLoader) 把文件加载到内存中 运行时数据区(Runtime Data Area) ,而字节码文件是 JVM 的一套指令集规范,并不能直接交个底层操作系统去执行,因此需要特定的命令解析器 执
行引擎(Execution Engine)将字节码翻译成底层系统指令再交由CPU去执行,而这个过程中需要调用其他语言的接口 本地库接口(Native Interface) 来实现整个程序的功能,这就是这4个主要组成部分的职责与功能。

JVM大致通过4个部分来执行我们的java程序:
- 类加载器
- 运行时数据区
- 执行引擎
- 本地库接口
而上述4个部分中我们的java运行时数据区也叫内存布局,我们重点了解一些这块空间的内存是如何布局的即可!
内存区域划分
为啥要将内存区域进行划分呢?
对内存区域进行划分,就让不同的内存空间具有不同的功能,就好比我们的学校不同区域具有不同的功能,教学楼是用来学习的,寝室是用来睡觉的,食堂是用来吃饭的!
而我们的JVM中的内存区域也是按照不同区域行使的功能进行了划分!
java运行时数据区(内存布局划分如下)

主要分为4个重要的区域
- 程序计数器
- 栈
- 堆
- 方法区
我们下面来分别介绍这个4个不同区域的功能
程序计数器
程序计数器这块空间保存了下一条要执行指令的地址,我们通过这个地址空间,就可以让程序顺利执行下去!
这里的程序计数器每个线程都有一个,我们知道线程是程序调度的基本单位嘛!
而我们的CUP是需要并发执行的,并不能保证某一时刻连贯的就把某一进程执行结束,我们的CPU需要服务于多个线程,所有程序计数器很好的对程序的执行的位置进行了存档,当我们的该线程再次被CPU调用时根据程序计数器中记录的指令就可以找到上次执行的位置继续执行程序!
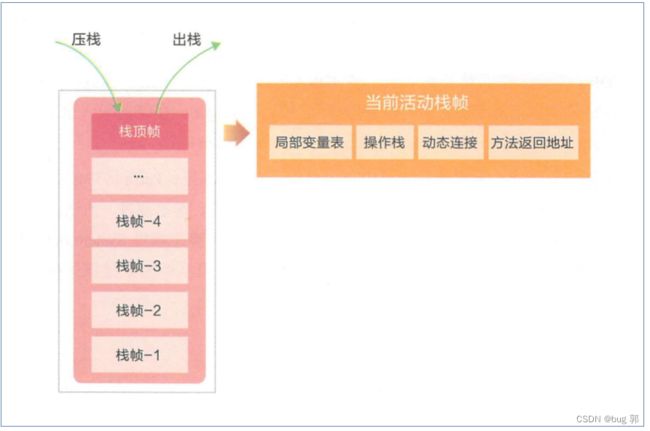
栈
这里的栈和我们数据结构中的栈结构类似,不过这里的栈保存的信息是
栈帧
栈中主要保存2种信息
- 方法调用信息
- 局部变量
栈帧(方法调用信息):
方法的实参
局部变量
方法调用的位置
方法执行结束的位置
我们通过下面代码进一步了解:
public class Main {
static void fun1(){
fun2();
}
static void fun2(){
fun3();
}
static void fun3(){
fun4();
}
static void fun4(){
System.out.println("fun4");
}
public static void main(String[] args) {
fun1();
}
}
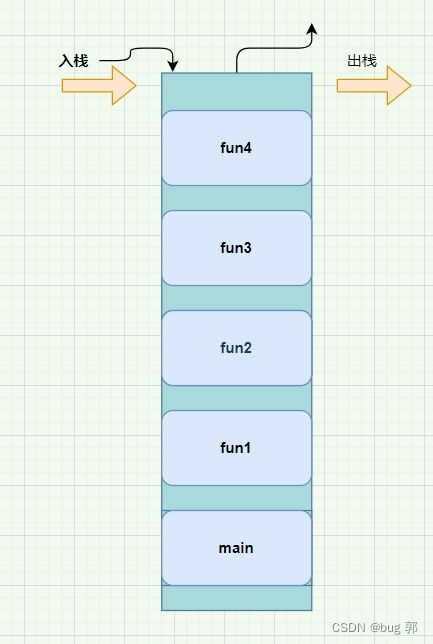
当我们需要执行
fun1方法,首先我们需要将main栈帧入栈,通过main栈帧中的信息,我们可以知道此时我们需要调用fun1,然后就将fun1栈帧入栈,紧接着fun3入栈,最后调用fun4然后进行打印,当我们的fun4方法调用结束,此时fun4栈帧就会出栈,然后回到fun3调用位置,fun3结束,fun3出栈,回到fun2,fun2出栈,fun1,main栈帧出栈,整个程序就执行结束了!
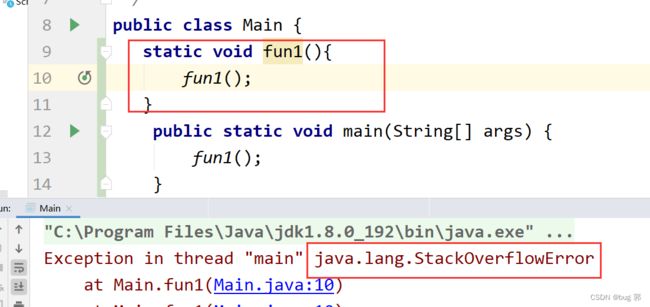
这里就需要注意的是我们的栈空间有限,一般只有几M到十几M大小,虽然可以自行设置,但是当我们递归时如果递归次数过多,或者递归出口没有设置很有可能导致栈溢出StackOverflow
堆(线程共享)
- 成员变量
new出来的对象
class A{
public String name1 = "张三";
public void fun(){
String name2 = new("李四");
System.out.println(name2);
}
}
我们的上述代码中成员变量 name1保存在堆中,fun方法中的name2引用属于局部变量保存在栈中,而其引用指向的本体new("李四")对象本体保存在堆!
注意:
这里的堆空间是线程共享空间,一个进程只要一个堆空间,所有这里的堆空间大小最大!
方法区
方法区存放的是类对象
啥是类对象呢?
我们
JVM执行一个.java程序,第一步要先将这个通过javac指令将该文件转成二进制字节码文件.class,而.class文件就会来到内存中,通过JVM加载将其构造成类对象,这里的加载过程就叫做类加载!
类对象都有些啥呢?
类对象就是描述这个类长啥样!
类名,有哪些成员,成员名,成员类型,public/private,方法,方法名,方法中的指令…
类对象中还有一个重要东西,静态成员~
就是static修饰的成员雷属性,而普通的成员叫做实例属性!
上面就是对内存区域划分及其功能的大致介绍,指的注意的是不同版本的JVM可能有不同的划分方式,但是大致都是一样的!
类加载过程
我们刚刚了解到我们的
JVM执行流程,就是将一个.class文件加载到内存中,然后根据.class文件构造一个类对象,当类对象结束使用后,一个类的生命周期也就结束!

而我们的类加载过程一共分为3个步骤!
- 加载(Loading)
加载过程主要做的,就是先找到对应的
.class文件,然后打开并读取.class文件,同时初步生成一个类对象!
Loading阶段最关键就是找到对应的.class文件,并且将其解析成类对象,那么如何去找到一个.class文件呢?
1)通过一个类的全限定名来获取定义此类的二进制字节流。
2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口

我们的JVM通过上述格式,就可以将一个.class文件找到,然后通过这个格式进行加载初步构造一个类对象!
-
连接(Linking)

连接又分为3个步骤:- 验证(Verification)
这里验证就是通过
.class文件中的内容对照JVM中提供的class文件标准格式信息进行对照,如果不符合格式,就会类加载失败,然后抛出异常- 准备(Preparation)
准备阶段就是给静态变量(类变量)分配内存,并且统一初始化置为0
- 解析(Resolution)
解析阶段是JVM将常量池内的符号引用替换成直接引用的过程,也就是初始化常量的过程
我们的.class文件中的常量是集中放置的.然后每个常量都会对应一个标号引用,而我们的class文件结构体初始只是记录了标号引用,所以我们要根据标号引用拿到对应常量,对常量进行初始化,填充到类对象中! -
初始化(Initialization)
这里才是真正对类进行初始化,尤其是静态变量!
初始化阶段,Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程。
经典面试代码题
class A {
public A(){
System.out.println("A构造方法");
}
{
System.out.println("A构造代码块");
}
static {
System.out.println("A静态代码块");
}
}
class B extends A{
public B(){
System.out.println("B构造方法");
}
{
System.out.println("B构造代码块");
}
static {
System.out.println("B静态代码块");
}
}
public class Main extends B{
public static void main(String[] args) {
new B();
new B();
}
}
输出上述代码的打印结果:

上述类型题目抓住3个要点即可攻破!
- 类加载要优先加载类属性(所以这里的静态代码块优先加载),而创建实例之前需要执行类加载过程,并且类加载自进行一次!
- 构造方法在构造代码块前,并且每次实例化都会调用对应的构造方法!
- 父类执行完再子类!
双亲委派模型
提到类加载机制,不得不提的一个概念就是“双亲委派模型”!
我们通过对类加载机制的学习了解了类的一个生命周期!
在第一个Loading加载环节!我们需要通过类名去找到对应的类,而双亲委派模型就是JVM使用的找到一个类的机制!
我们的JVM对类加载目录扫描进行了分工!
通过不同的加载器扫描不同的目录,主要有3个类加载器!
- 启动类加载器(Bootstrap ClassLoader)
类启动加载器,就是负责加载JDK中标准库中的类(scanner,String,ArrayList…)
- 扩展类加载器(Extension ClassLoader)
负责加载JDK中扩展的类!
- 应用程序类加载器(Application ClassLoader)
应用程序类加载器负责加载我们开发人员自己构造的类!
我们的JVM如何通过上述类加载器找到对应的类呢?
- 实例一:找到
java.lang.String类!
首先第一步来到应用程序类加载器,然后应用程序类加载器会首先检查他的父类加载器是否加载过,如果没有就就调用父类,也就是扩展类加载器,扩展类加载器,也是先检查父类是否加载过,没有就调用父类加载器,启动类加载器,然后检查父类是否加载过,显然他没有父类,就对其下的目录进行扫描,然后在标准库目录找到了该类,也就加载结束!
实例二: 找到加载一个 Test类
也是和实例一的步骤一样,逐层向上调用加载,到达启动类加载器后扫描后并没有找到,就再次回到扩展类加载器,扫描结束,回到程序类加载器,扫描后在其目录,将其类加载!

JVM为啥这样设计呢?
- 安全性: 我们通过这样父类优先类加载的过程,就保证了一个如果我们开发人员写的一个类名和标志库中类一样时,优先加载标志库中的类,也能顺利加载到标志库中的类!
- 避免重复加载类:如果A类和B类都有一个相同的父类C的话,当A启动后,就会将C类加载起来,那么B类启动会无需重复加载C类了!
垃圾回收策略(GC)
我们知道内存的申请是由我们程序员控制的,当我们创建了一个变量,就是申请了一块内存空间,而当我们这个变量不用时,应该将这块空间释放!这里释放归还的过程就会用到垃圾回收策略
garbage collection简称GC!
而有的编程语言像C/C++内存的释放还是通过程序员自己释放,但是这样通过程序员自己释放就会降低开发效率!我们程序员有时候很难控制释放的时间,如果释放的早,就会导致申请释放内存的开销,如果释放的晚,或者没有进行释放,就会导致内存泄漏问题!
大部分主流语言还是通过一个专门的进程,对内存空间进行释放,也就是我们这里说的垃圾回收!像Python/java/go/PHP等都是如此,不过不同语言的垃圾回收策略会有不同,我们主要学习java中的JVM是如何进行GC的!
垃圾回收策略的缺点:
1).消化额外的开销(我们在JVM下搞一个需要一个专门进程,这样消化的资源就多了)
2).可能影响程序运行的流畅度(垃圾回收会导致STW(Stop The World)问题,就是程序中断,注意这里说的中断并不是我们多线程学的中断,这里指的是GC要对垃圾进行回收,使得我们的业务程序不得不停止!)
我们知道了内存区域是如何划分的,而我们划分的空间如果不用了,就需要回收!
我们JVM的内存空间是想操作系统申请的!当我们不使用时,就需要将其归还,有借有还再借不难!
我们的JVM是如何判断一块空间是不用的,又是如何进行回收的呢?
垃圾回收都回收啥内存?
我们将
JVM的内存空间进行了划分,GC主要回收的内存空间就是堆上的空间,因为这块空间最大,也是我们需要回收的空间,不像栈会根据程序的执行,自己释放!程序计数器的空间大小是固定了也不需要释放,方法区存放的是类对象,而类对象只在类加载时加载一次创建一次,最后该类结束后,进行类卸载,需要释放内存,这里是比较低频的操作!我们GC的关键就是针对堆上的空间进行回收,因为我们代码中大量的内存空间都是在堆上的!
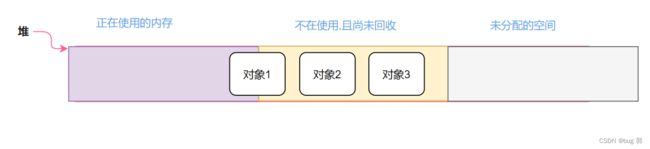
上图就是大致我们堆上的内存的使用分布!
我们可以知道我们这里的CG基本单位是对象,并不是字节,就好比对象1,有些变量还在使用,有一些不在使用,我们就要保留这块内存空间,自制所有的内存都不在使用,就将其回收!我们主要针对一整个对象回收!
如何定位垃圾?
当下垃圾回收机制有2个主流的定位垃圾的机制
- 基于引用计数
- 基于可达性分析
基于引用计数
我们堆上主要的保存的就是我们
new的对象和成员变量,我们可以根据一块空间记录指向一个对象的引用个数,然后根据记录的引用数决定是否需要将这块空间回收,如果引用为0说明这个对象已不再使用,就可以进行垃圾回收,这就是引用计数的方式!
t1 = new A();//new A()对象的引用加一!
t2 = new B();//new B()对象的引用加一!

我们的A对象只有有t1引用指向,所以引用数为1,B对象也是如此!
当某一时刻,该引用变量释放,对应的对象引用计数也会减1,然后为0时就会将这块内存空间视为垃圾,将其回收!
循环引用问题:
t1 = new A();
t1.t = new B();
t2 = new B();
t2.t = new A();
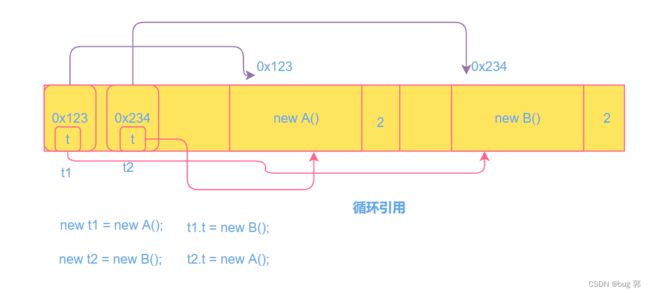
循环引用就是某一引用变量t1下面的属性也有引用t指向一个对象,当外面的引用变量t1释放后,new A()对象的引用计数是减1了,但是new B()对象的引用计数不会减少,t2也是如此,最后虽然t1和t2引用已经不存在,但是对象A和对象B的引用数还是1,这就尴尬了,虽然没人能拿到这两个对象,但是引用计数还是1,不能释放…
引用计数的缺点
- 要消耗额外空间,我们需要一块特点的空间记录引用数!当我们的对象本身空间就不大时,引用计数空间就很费资源!
- 循环引用问题,不能进准定位到垃圾!
基于可达性分析
我们上述的引用计数是其他语言(
PHP/Python)使用的定位垃圾的手段,而我们的java使用的定位垃圾的策略是可达性分析!
可达性分析: 就是通过额外的线程,对内存进行扫描,然后可以扫描到的对象就将其标记,这里就需要规定扫描的起始位置
GCRoots,通过起始位置,类似于二叉树的深度优先遍历一样,将能够访问到的对象都标记一遍,访问不到的就是是不在使用的内存空间,也就是垃圾了!
GCRoots:
1).栈上的局部变量!
2).常量池中引用指向的对象
3).方法区中静态变量指向的对象
我们用二叉树遍历来模拟GC可达性分析:
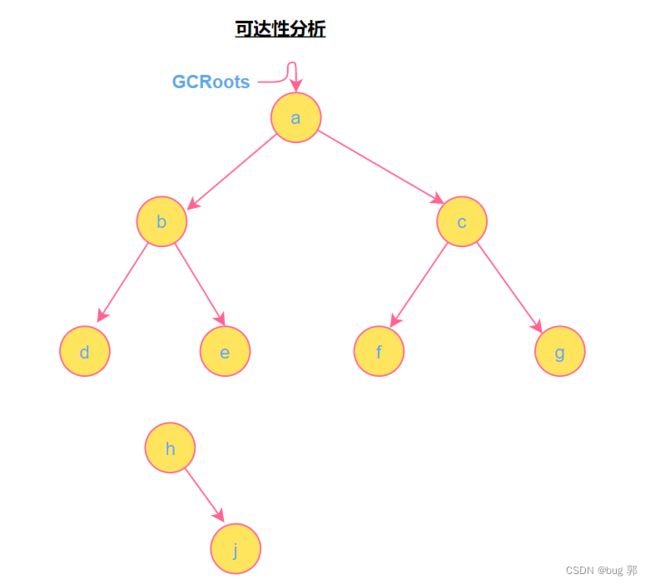
我们通过GCRoots起始位置对内存空间进行深度优先扫描,我们可以扫描到的节点对象就是真正使用内存的对象(a,b,d,e,f,g),我们将其标记,而没有扫描到的对象(h,j)也就是垃圾,我们将其空间回收即可!
我们通过引用计数和可达性分析可以将垃圾定位,那应该如何对垃圾进行处理呢也就是回收内存?
我们通过3种算法机制对垃圾进行回收:
- 标记清楚
- 复制算法
- 标记整理
标记清除
标记清楚就是对垃圾进行标记,然后将该标记的空间进行清楚回收即可!
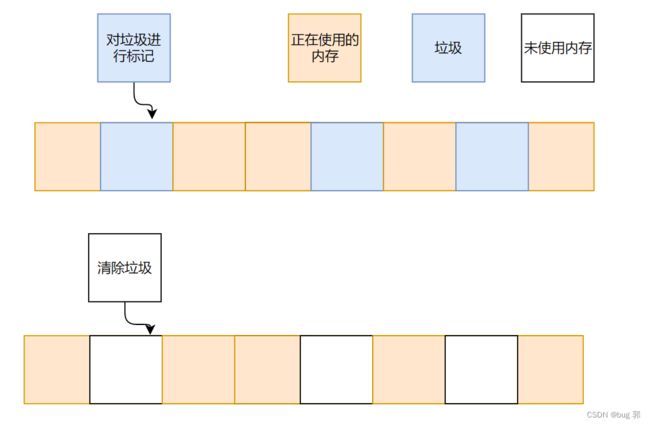
可以看到这种清除垃圾的算法,将内存空间回收后,会造成大量内存碎片,造成空间浪费!
复制算法
复制算法就是空间分成2分,一份用于对象使用,一份用于复制!
当标记到了垃圾,我们需要对这一半空间中的对象复制到另外一半空间,然后整体回收这一半的空间!
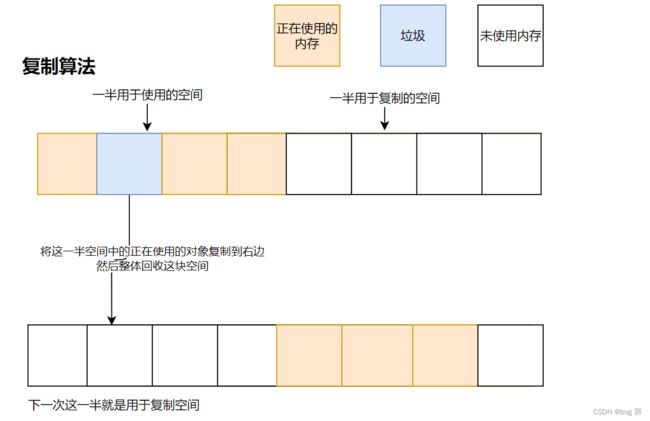
虽然这个算法解决了标记清楚的内存碎片问题,但是空间利用率低!有一半的空间未被使用到!
标记整理
标记整理,就类似数组中删除 某一元素,需要将数组元素进行整理!
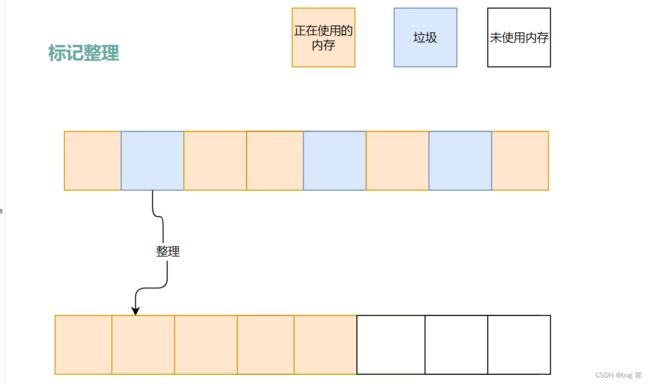
显然这种算法解决了上述2个算法的缺点,但是效率比较低,每次整理都要耗费大量时间开销!
我们GC在进行垃圾回收时会根据不同的情况,使用不同的算法进行回收垃圾!
分代回收
我们
JVM下的垃圾回收,将多种方案进行了结合, 一起使用,叫做分代回收!
这里的分代是根据"年龄"进行划分的,这里的年龄并不是传统意义上的年龄,是指经过一轮GC扫描后,如果对象还在,那这个对象就长一岁!根据不同岁数的对象进行了划分!

我们将堆空间进行分区,首先2个大类,新生代和老年代,然后新生代下又进行了划分,伊甸区和2个幸存区!
-
新生代
- 伊甸区
我们的创建好的对象直接放入到新生代中的伊甸区下!并且伊甸区大部分对象经过一轮
GC扫描后就会进行回收,只有少部分还存在!- 幸存区
当伊甸区经过一轮
GC扫描后,幸存的对象,就来到辛存区!辛存区的对象也会经过多轮GC扫描,这里的垃圾回收算法采用的是复制算法!然后经过多轮的GC扫描后没有被淘汰的对象就来到了老年代! -
老年代
老年代下的对象,
GC扫描的频率会大大减低,并且这里垃圾回收的算法采用的是标记整理算法!这里的GC扫描会经过很长的时间进行扫描,因为一般能来到老年代下的对象,命都比较硬!
注意:这里老年代下的对象除了是辛存区下来的,还有就是所占空间比较大的对象,直接就来到老年代,因为大对象,不适合复制算法进行回收,并且大对象一般存活的时间也比较长!
我们类比我们找工作的过程来理解分代回收机制:
首先投简历直接来到伊甸区,啪的一下,面试官进行一轮简历筛选,大部分简历直接就丢了,然后剩下的人就来到了辛存区,好比我们通过简历后要经过很多轮的笔试和面试,最后才能拿到offer,拿到offer后,我们就来到了老年代,虽然已经进公司了,但也不是就稳定了,如果干的不好,就会将其淘汰!而这里有一些牛逼大大佬,直接就免了笔试和面试,直接就进公司了,就好比大对象一样!
垃圾收集器
我们上述介绍的回收机制只是思想,如果要具体落地实现,要通过JVM中的垃圾收集器具体进行回收,因为随着JVM版本的更迭,收集器也不断的更新!所以我们就大致了解一下即可!
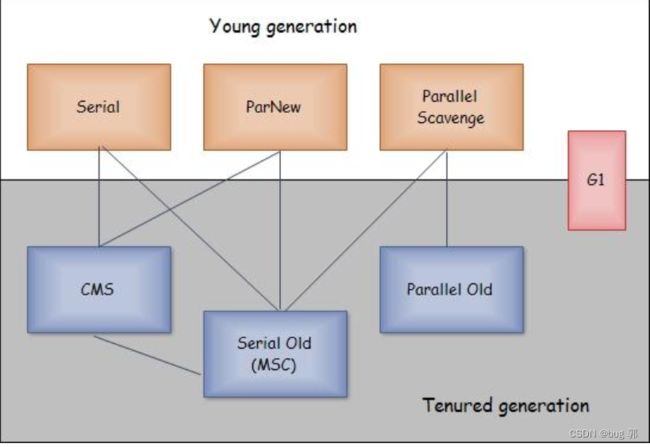
- 串行收集
Serial针对新生代
Serial Old针对老年代
在进行垃圾回收时,我们的业务线程需要停止工作,这种方式扫描的慢释放的页慢,产生了严重的STW!
- 并发收集
ParNew
Parallel Scavenge上面2个都是针对新生代
Parallel Old:针对老年代
并发收集,引入了多线程,但是也是比较低效的收集方式!
CMS收集器
设计比较巧妙,尽可能减少
STW
- 可达性分析
1).初始标记,速度很快,会引起短时间的STW,这里的标记只是为了找到Roots
2).并发标记,比较慢,但是这是和业务线程并发的,不会产生STW
3).重新标记,在并发标记时,并发的业务代码可能会影响标记结果,所以对标记进行微调,速度较快,会引起短时间的STW- 标记整理
4).回收内存,和业务线程并发!
-G1收集器
把整个内存分成很多个小的区域
Region,给这些Region进行标记,然后根据年龄放入不同的分代区域,扫描的时候一次扫描若干个Region,分多次扫描,所以影响业务代码最小,可以使STW减小到1ms