小目标检测综述
1.小目标检测算法的一般流程
| 传统小目标检测算法流程 |
现有的小目标检测算法流程 |
| 1.输入待检测图片对象,首先对待检测图片进行候选框提取。 |
1.输入图像,开始训练,首先进行数据预处理(可采用图片翻转、图片缩放,CutOut、CutMix、MixUp、Moasaic等处理手段) |
| 2.采用一些经典的模式识别中的算法(基于颜色、基于纹理、基于形状等语义特征的方法)进行特征提取 |
2.检测网络。包含基础骨干(卷积网络、转换器网络)、特征融合(金字塔结构、编解码结构)、初始化(锚点、角点、查询)、预测( 分类、回归、中心度)等四个过程。 |
| 3.对特征提取中得到的特征进行分类判定。 (1) 对于单类别的目标检测只需要区分当前的窗口所覆盖的对象是背景还是目标。 (2)对于多类别的目标检测还需要进一步确定当前窗口覆盖的对象的类别。 |
3.进行标签匹配与损失计算。其中标签匹配包含交并比匹配、距离匹配、似然估计匹配、二分匹配;损失计算包含交叉熵损失、Focal损失等。 上述是训练过程,检测过程在训练过程的下一页。 |
| 4.采取NMS(非极大值抑郁,局部最大搜索)对候选框进行合并,处理掉候选框可能重叠的状况。(如果是多类别的目标检测则需要进行这一步。) |
传统小目标检测的一般流程图:

现有小目标检测算法的训练流程图:

现有小目标算法的测试流程图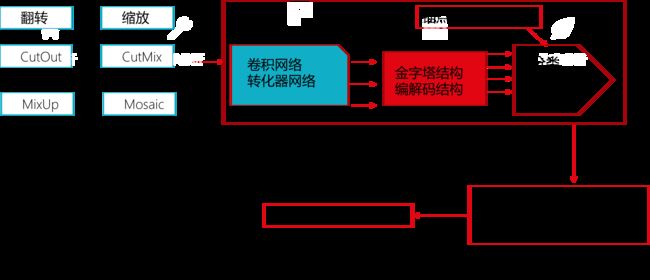
2.常用目标检测数据集
| 数据集名称 |
数据集描述 |
参与过的实验 |
| PASCALOVOC |
VOC数据集时目标检测常用数据集,包含了约10000张带有边界框的图片用于训练和验证,包含了20个类别,由于类别仅20个,因此被视为目标检测的一个基准数据集 |
Decetion Person Layout Classifiction等 |
| MSCOCO |
大型的、丰富的物体检测,分割和字幕数据集,对于目标检测任务,每年大赛的训练和验证集柏寒120000张图片,超过40000张测试图片,覆盖91类目标。 |
YoloV3 YoloV5 实例分割算法性能验证等 |
| ImageNet数据集 |
目前世界上图像识别最大的数据库,大约1500万张图片,2.2万类,每一周都经过严格的人工筛选和标记。ImageNet类似于图片所有引擎。 |
计算机视觉系统识别项目、YOLOV3等、SSD等 |
| AL-TOD航空图像数据集 |
AL-TOD在28036张航拍图像中包含8个类别的700621个对象实例。包含8个类别的700621个对象实例,AL-TOD中目标的平均大小为12.8像素,远小于其他数据集。 |
Fster-RCNN `YOLOV3 M-CenterNet等 |
| TinyPerson数据集 |
在TinyPerson有1610个标记图像和759个未标记图像,本数据集是第一个远距离和大背景下进行人员检测的基准,为极小目标检测开辟了一个新的前景方向。 |
RetinaNet、FCOS以及二阶段目标检测等算法。 |
| Deepscores数据集 |
DeepScores数据集的目标是推进小物体识别的最新技术,并将物体识别问题置于场景理解的背景下。 |
道路车辆异常检测,检测视频流中的异常。 |
| ALTEX数据集 |
该数据库由七个不同织物结构的245张4096*256像素图像组成。主要用于工业生产和质量检测,偏向于工业领域使用。 |
工业纺织生产检测 RCNN等 |
| Labelme图像数据集 |
Labelme Dataset是用于目标识别的图像数据集,涵盖1000多个完全注释和2000个部分注释的图像,测试集拥有来自世界不同地方拍摄的图像,可以保证图片在续联和测试之间会有较大的差异 |
深度学习图像分割应用、制作图像语义分析数据集等 |
| EuroCity Persons数据集 |
该数据集主要为城市交通场景,包含大量种类繁多,准确且详细的目标,该数据集比以前用于基准测试的数据集几乎大了一个数量级,其覆盖种类多,细节香精,将城市交通中的人员注释提升到了一个新的水平。 |
YOLOV3,交通路口车辆车牌识别、YOLOV4等 |
| Penn-Fudan行人检测与分割数据集 |
该数据集由Wang等提出的一个图像数据库,由用于行人检测的图像组成。该图像数据库中包含170张取自校园周围和城市街道场景的图片,其中图片来源于几个大学,且每张图片至少有一个行人。 |
行人检测、图像分割等。 |
| DOTA数据集 |
该数据集用于航空图像中目标检测的大型数据集,包含了各种尺度、方向、形状的对象,完全注释的DOTA图像包含188282个实例。 |
RCNN、SSD、CVPR21小目标检测。 |
3.小目标检测算法的历史流程

| 算法名称 |
出现时间 |
相关论文及链接 |
| VJ(Viola-Jones) |
2001 |
Viola-Jones Face Detector - University of California, Irvine [13-ViolaJones (usc.edu)] 论文链接: 13-ViolaJones (usc.edu) |
| HOG DET |
2006 |
Histograms of Oriented Gradients for Human Detection [CVPR05_DalalTriggs.pdf (stanford.edu)] 论文链接: CVPR05_DalalTriggs.pdf (stanford.edu) |
| DPM |
2008 |
Histograms of Oriented Gradients for Human Detection [CVPR05_DalalTriggs.pdf (stanford.edu)] 论文链接: CVPR05_DalalTriggs.pdf (stanford.edu) |
| Overfeat |
2013 |
OverFeat:Integrated Recognition, Localization and Detection using Convolutional Network [1312.6229.pdf (arxiv.org)] 论文链接:1312.6229.pdf (arxiv.org) |
| RCNN |
2014 |
Rich feature hierarchies for accurate object detection and semantic segmentation [https://arxiv.org/pdf/1311.2524v3.pdf] 论文链接:https://arxiv.org/pdf/1311.2524v3.pdf |
| SPPNet |
2014 |
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition [Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition | IEEE Journals & Magazine | IEEE Xplore] 论文链接:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition | IEEE Journals & Magazine | IEEE Xplore |
| Fast-RCNN |
2015 |
Fast R-CNN [1504.08083.pdf (arxiv.org)] 论文链接:1504.08083.pdf (arxiv.org) |
| Faster-RCNN |
2015 |
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [https://arxiv.org/pdf/1506.01497.pdf] 论文链接:https://arxiv.org/pdf/1506.01497.pdf |
| YOLO |
2016 |
You Only Look Once: Unified, Real-Time Object Detection [1506.02640] You Only Look Once: Unified, Real-Time Object Detection (arxiv.org)] 论文链接: [1506.02640] You Only Look Once: Unified, Real-Time Object Detection (arxiv.org) |
| SSD |
2016 |
SSD: Single Shot MultiBox Detector [[1512.02325v5] SSD: Single Shot MultiBox Detector (arxiv.org)] 论文链接:[1512.02325v5] SSD: Single Shot MultiBox Detector (arxiv.org) |
| 算法名称 |
出现时间 |
相关论文及链接 |
| YOLOv2 |
2017 |
YOLO9000: Better, Faster, Stronger [https://arxiv.org/abs/1612.08242] 论文链接: https://arxiv.org/abs/1612.08242 |
| MASKRCNN |
2017 |
Mask R-CNN 论文链接: https://arxiv.org/pdf/1703.06870.pdf |
| FPN |
2017 |
Feature Pyramid Networks for Object Detection 论文链接: [1612.03144] Feature Pyramid Networks for Object Detection (arxiv.org) |
| Retina Net |
2017 |
Focal Loss for Dense Object Detection 论文链接: https://arxiv.org/pdf/1708.02002.pdf |
| YoloV3 |
2018 |
YOLOv3: An Incremental Improvement 论文链接: [1804.02767] YOLOv3: An Incremental Improvement (arxiv.org) |
| Cascade RCNN |
2018 |
Cascade R-CNN: Delving into High Quality Object Detection 论文链接: [1712.00726] Cascade R-CNN: Delving into High Quality Object Detection (arxiv.org) |
| Libra RCNN |
2019 |
Libra R-CNN: Towards Balanced Learning for Object Detection 论文链接: https://arxiv.org/pdf/1904.02701.pdf |
| Grid RCNN |
2019 |
Grid R-CNN 论文链接: [1811.12030] Grid R-CNN (arxiv.org) |
| YoloV4 |
2020 |
YOLOv4: Optimal Speed and Accuracy of Object Detection 论文链接: [2004.10934] YOLOv4: Optimal Speed and Accuracy of Object Detection (arxiv.org) |
| YoloV5 |
2020 |
TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios 论文链接: TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios (thecvf.com) |
4.小目标检测算法实验
| 实验方法 |
实验描述 |
应用案例 |
| 消融实验 |
控制一个条件/参数不变,分析出哪个条件/参数对结果的影响。 |
[1] Peng S , Jiang W , Pi H , et al. Deep Snake for Real-Time Instance Segmentation[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020. Girshick, R., Donahue, J., Darrell, T. and Malik, J., 2014. 《Rich feature hierarchies for accurate object detection and semantic segmentation》. In Proceedings of the IEEE conference on computer vision and pattern recognition |
| 定性分析实验 |
运用演绎和归纳,以信息来研究小目标检测,从而获取资料。 在自然条件下通过类比推理,通过模型来间接研究原型的一种形容方法,以实现新的小目标研究。 |
[1]刘洪江, 王懋, 刘丽华,等. 基于深度学习的小目标检测综述[J]. 计算机工程与科学, 2021. |
| 定量分析实验 |
依据统计数据,建立相应的数学模型,并用数学模型计算出研究对象的各项指标及数值,为结论的总结和推理提供了帮助。 |
[1]高宗, 李少波, 陈济楠,等. 基于YOLO网络的行人检测方法[J]. 计算机工程, 2018, 44(5):6. |
| 经典算法对比 |
将一个算法得到的实验结果和其他经典算法实验得到的结果相比较得出结论 |
[1] Redmon J , Farhadi A . YOLOv3: An Incremental Improvement[J]. arXiv e-prints, 2018. |
| 文献研究 |
根据一定的研究目的或课题,通过调查文献来获取资料,从而全面地、正确地了解掌握掌握所要研究问题的一种方法。 |
[1]梁鸿,王庆玮,张千,李传秀. "小目标检测技术研究综述." 计算机工程与应用 17-28(2021). |
| 跨学科研究 |
运用数学、自然科学等理论、方法和成果从整体上来进行综合研究小目标检测。 |
[1]李红艳, 吴成柯. 一种基于小波与遗传算法的小目标检测算法[J]. 电子学报, 2001, 29(004):439-442. |
| 数据可视化 |
通过对部分数据进行可视化,运用观察法,通过自己的感官和辅助工具直接观察被研究对象,从而获取相关结论,这在现有的研究中被经常大量使用。 |
[1] Wang X , Shrivastava A , Gupta A . A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017. |
| 思维方法 |
在小目标检测领域中,这一领域内专家运用思维方法来提出了准确的思想表达。它对于一切科学研究都有普遍的指导意义。 |
[1] Ren S , He K , Girshick R , et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149. |
| 在多个数据集上实验。 |
通过一个算法在多个数据集上进行实验来综合评估该算法的性能和缺点等属性。 |
[1] Purkait P , Zhao C , Zach C . SPP-Net: Deep Absolute Pose Regression with Synthetic Views[J]. 2017. |
| 研究对象所耗费的代价统计 |
对研究对象进行的实验中的代价比较,对研究对象进行可行性与有效性等属性进行评估和归纳。 |
[1] Purkait P , Zhao C , Zach C . SPP-Net: Deep Absolute Pose Regression with Synthetic Views[J]. 2017. |
| 实验方法 |
实验描述 |
应用案例 |
| 数据集的5%、10%、15%、20%、30%的选择 |
通过对数据集的不同划分,基于数据集的不同划分可以测得算法的鲁棒性和更加可靠的准确率,对算法具有非常大多评估价值。 |
[1] Girshick, R. . "Fast R-CNN." Computer Science (2015). [1] Redmon, J. , and A. Farhadi . "YOLOv3: An Incremental Improvement." arXiv e-prints (2018). |
5.经典算法的比较
| 算法名称 |
算法优点 |
算法缺陷 |
| SPP-Net |
1.提出了SPP层(空间金字塔池化层),使得输入的候选框可大可小,解决了R-CNN区域候选时vrop/warp带来的偏差问题。 2.达到了CNN层的共享计算,减少了运算时间. |
1.训练速度慢,效率低,特征需要写入磁盘. 2.分阶段训练网络:选取候选区域训练CNN、训练SVM、训练BBOX回归器。 |
| RCNN |
1.从DPM HSC的34.3%直接提升到66%(mAP) 2.引入了RP+CNN |
1.训练步骤繁琐(微调网络+训练SVM+训练bbox) 2.训练、测试均速度慢 3.训练占空间 |
| SSD |
1.相比于Fast RCNN系列,删除了bounding box proposal这一步,及后续的重采样步骤,速度较快,达到了59FPS 2.SSD提取不同尺度的特征图来做检测,前面的大尺度用于检测小目标,后面的小尺度特征图用于检测大目标,采取VGG16作为基础模型。 |
对小尺度的目标识别仍比较差,还达不到Faster R-CNN的水准。 |
| YOLOV3 |
1.推理速度快 2.性价比高 3.通用性强 |
1.召回率高,定位精度较差 2.对于靠近或者遮挡的群体、小物体的检测能力相对较弱。 |
| FAST-RCNN |
1.准确率提高到了70% 2.每张图片耗时约3s |
1.依旧用SS提取RP(耗时2-3s,特征提取约0.32s) 2.无法满足实时应用,没有真正实现端到端训练测试 3.利用GPU,但是候选区域提取方法是在CPU上实现。 |
| FASTER-RCNN |
1.提取了检测精度和速度 2.真正实现端到端的目标检测框架 3.生成建议框仅需10ms |
1.无法达到实现实时检测目标 2.获取regio proposal,再对每个proposal分类计算量比较大 |
| YOLOV4 |
1.YOLO V4使用了多种数据增强技术的组合,作者混合CUTMix与Mosaic技术,同时使用了Self-Adversariar Training(SAT)来进行数据增强。 2.采用了CSPNet网络结构,用Concat代替Add,提取到了更加丰富的特征。 3.提出了高效而强大的目标检测模型.在训练期间,验证了SOTA的Bag-of Freebies和Bag-of-Specials的影响。 |
缺少自适应锚框。 |
| YOLOV5 |
1.采用了Anchor采样策略,增加了正样本数量、加速网络收敛、减小边框wh参数回归的难度,充分挖掘了质量较低的回归潜力。 2.基于缩放、色彩空间调整和马赛克增强进行了数据增强。 |
一部分正样本质量不高,置信度预测偏低,对宽高比极端的物体效果极差。 |
6.小目标检测面临的挑战
| 存在的挑战 |
困难描述 |
| 小目标就利用特征少 |
从基于绝对尺度和相对尺度来说,小目标相当于大/中尺度尺寸目标都存在分辨率低,而低分辨率的小目标可视化信息少,难以提取到具有鉴别力的特征,且再加上小目标极易受到环境因素的干扰,导致了训练出来的检测模型难以精准定位和识·识别小目标。 |
| 小目标定位精度要求高 |
在图像中小目标所占面积小,其边界框的定位相对于大、中尺度尺寸目标i具有更大的挑战性。在预测过程中,只要预测边界框偏移一个像素点,对小目标的误差影响远高于大/中尺度目标。目前,基于锚框的检测器占据了绝大多数,在训练过程中,匹配小目标的锚框数量远低于大/中尺度目标。 |
| 目前存在的数据集中小目标占比少 |
在目前的目标检测领域中,现有的数据集大多针对于大、中尺度尺寸目标。较少关注小目标。小目标不易标注,标全难度大。小目标对于标注误差更为敏感,而现有的大规模的通用小目标数据集处于缺乏状态,现有的算法因为没有足够的先验信息学习,导致了小目标检测性能不足。 |
| 样本不均衡 |
由于现有的定位方法中大多是预先在图片的每一个位置生成一系列的锚框。而在训练过程中,通过设置固定的阈值判断锚框属于正样本还是负样本,导致了模型训练过程中不同尺寸目标的正样本不均衡问题。当人工设定的锚框与小目标的真实边界框差异较大时,小目标的训练正样本将远远小于大/中尺度目标的正样本,导致了训练模型更加关注于大/中尺度目标的检测,从而忽略了小目标的检测。 |
| 小目标容易聚集 |
相对于大/中尺度目标,小目标有更大概率产生聚集现象。当小目标聚集出现时,聚集区域相邻的小目标经过多次采样后,反应到深层特征图上将聚合成一个点,导致模型无法区分。聚集区域的小目标之间边界距离过近,还将导致边界框难以回归,模型难以收敛。如果存在同类的小目标密集出现时,预测的边界框还可能会因后处理的非极大值抑制操作将大量正确预测的边界框过滤,从而造成漏检情况。 |
| 网络结构问题 |
现有的网络依旧是基于锚框的检测器占据主要位置,而锚框对小目标极不友好,在现有的网络训练过程中,小目标由于训练样本比较少,对损失函数的贡献少,进一步减弱了网络对于小目标的学习能力。 |
7.小目标检测算法评价指标
| 评价指标 |
计算方法 |
功能 |
| 交互比-IOU |
IOU=(area of overlap)/ (area of union) |
IOU是计算不同图像相互重叠比例的算法,在目标检测中,一次性生成大量的候选框,再根据每一个候选框的置信度进行排序,计算框与框之间的IoU,最后根据非极大值预测来寻找真正感兴趣的目标。 |
| 准确率、精度、召回率/FPR、f1指标 |
Tp:被正确分类的对象的数量 FP:对不存在的东西做了错的预测 或者 预测的IOU小于预设阈值 FN:漏检测 TN:由于TN有无数个,所以TN不考虑。 p=TP/(TP+FP)=TP/all detections (p为精度) recall=TP/(TP+FN)=TP/all ground truths (recall为召回率) FPR=FP/(FP+FN)(FPR即为召回率) F1=2*TP/(2*TP+FP+FN) |
在目标检测算法中,要评估算法的准确率和鲁棒性、查全率等,算法的准确率、精度、召回率以及FPR都是需要计算出来作为重要参考的,f1指标更是基于TP、FP、FN三者的综合考虑指标。 |
| PR曲线-AP值 |
PR曲线是以precision为纵坐标,recall为横坐标的曲线,AP是曲线所围成的面积,综合考量了recall和precision的影响。 |
PR曲线综合考量了recall和precision的影响,而AP则是PR围成的面积,在算法检测过程中,需要综合考虑recall和precision两者的影响,所以PR可以作为评价指标。 |
| mAP-平均精度均值 |
如果是多类别目标检测任务,则需要使用mean AP,定义公式如下: mAP=(1/N)*=1i∑_(i=1)^N▒APi |
mAP指不同召回率下最大精度的平均值,具有可靠的参考性,能够较好地反映算法的性能。 |
| FPS |
每秒内可以处理的图片数量,这是一个速度指标。 |
在算法历程中,算法的时间复杂度不可忽略,FPS是一个速度指标,通过计算每秒内可以处理的图片数量,反应出算法十的时间性能 |
| 非极大值抑制(NMS) |
单个预测目标的NMS计算: 1.计算出每一个bounding box的面积,然后根据置信度进行排序,把置信度最大的bounding box作为队列中首个比较的对象。 2.计算其余bounding box与当前最大的score的IoU,,去除IoU大于设定阈值的bounding box,保留小的IoU预测框。 3.再重复上面的过程,直到候选bounding box为空。 多个预测目标的NMS计算: 当存在多目标预测时,先选取置信度最大的候选框B1,然后根据IoU阈值来去除B1候选框周围的框,再选取置信度第二大的候选框B2,再根据IOU阈值去除B2候选框周围的框。 |
非极大值抑制是不可缺少的评价指标,它是用来找到预测目标,由于目标检测存在多个框,而准确的锚框很少,通过NMS后,可以减少重复的锚框,提高小目标算法的速度性能和锚框的准确性。所以该指标在小目标检测算法中十分重要。 |
| F1-measure |
F1=2*PR/(P+R) |
综合了P和R的影响,F1越大,实验方法比较理想。 |
| ROC和AUC |
ROC的横坐标是FPR,而纵坐标是TRP,AUC是ROC曲线下的面积 |
ROC指标综合了FPR和TPR二者的影响,AUC可以侧面反映该模型的性能,AUC越大模型越好。二者可作为评价指标综合评价。 |
上述内容来自于个人PPT,需要可在作者的资源中下载或者私聊获取,小可爱可以点个赞吗。