重点!11个重要的机器学习模型评估指标
全文共8139字,预计学习时长16分钟
构建机器学习模型的想法应基于建设性的反馈原则。你可以构建模型,从指标得到反馈,不断改进,直到达到理想的准确度。评估指标能体现模型的运转情况。评估指标的一个重要作用在于能够区分众多模型的结果。
很多分析师和数据科学家甚至都不愿意去检查其模型的鲁棒性。一旦完成了模型的构建,他们就会急忙将预测值应用到不可见的数据上。这种方法不正确。
我们的目的不能是简单地构建一个预测模型。目的是关于创建和选择一个对样本以外数据也能做到高精度的模型。因此,在计算预测值之前,检查模型的准确性至关重要。

在这个行业中,大家会考虑用不同类型的指标来评估模型。指标的选择完全取决于模型的类型和执行模型的计划。
模型构建完成后,这11个指标将帮助评估模型的准确性。考虑到交叉验证的日益普及和重要性,本文中也提到了它的一些原理。

预测模型的类型
说到预测模型,大家谈论的要么是回归模型(连续输出),要么是分类模型(离散输出或二进制输出)。每种模型中使用的评估指标都不同。
在分类问题中,一般使用两种类型的算法(取决于其创建的输出类型):
1.类输出:SVM和KNN等算法创建类输出。例如,在二进制分类问题中,输出值将为0或1。但如今,有算法可以将这些类输出转换为概率输出。但是,统计圈并不是很乐意接受这些算法。
2.概率输出:逻辑回归( Logistic Regression ),随机森林( Random Forest ),梯度递增( Gradient Boosting ),Adaboost等算法会产生概率输出。将概率输出转换为类输出只是创建一个阈值概率的问题。
在回归问题中,输出时不会出现这种不一致性。输出本来就是一直连续的,不需要进一步处理。
例证
关于分类模型评估指标的讨论,笔者已在Kaggle平台上对BCI挑战做了预测。问题的解决方案超出了此处讨论的范围。但是,本文引用了训练集的最终预测。通过概率输出预测该问题,假设阈值为0.5的情况下,将概率输出转换为类输出。

1. 混淆矩阵
混淆矩阵是一个N×N矩阵,N是预测的类的数量。针对目前的问题,有N = 2,因此得到一个2×2的矩阵。你需要记住以下这些关于混淆矩阵的定义:
· 准确性:正确预测的结果占总预测值的比重
· 阳性预测值或查准率:预测结果是正例的所有结果中,正确模型预测的比例
· 阴性预测值:预测结果是负例的所有结果中,错误模型预测的比例。
· 敏感度或查全率 :在真实值是正例的结果中,正确模型预测的比重。
· 特异度:在真实值是负例的所有结果中,正确模型预测的比重。
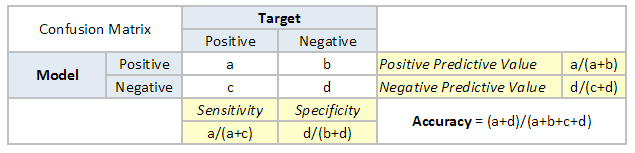

目前案例的准确率达到88%。从以上两个表中可以看出,阳性预测值很高,但阴性预测值很低,而敏感度和特异度一样。这主要由选择的阈值所造成,如果降低阈值,两对截然不同的数字将更接近。
通常,大家关注上面定义的指标中的一项。例如,一家制药公司,更关心的是最小错误阳性诊断。因此,他们会更关注高特异度。另一方面,消耗模型会更注重敏感度。混淆矩阵通常仅用于类输出模型。

2. F1分数
在上一节中,讨论了分类问题的查准率和查全率,也强调了在用例中选择查准率和查全率的重要性。如果对于一个用例,想要试图同时获得最佳查准率和查全率呢?F1-Score是分类问题查准率和查全率的调和平均值。其公式如下:

现在,一个显而易见的问题是,为什么采用调和平均值而不是算术平均值呢?这是因为调和平均值可以解决更多极值。通过一个例子来理解这一点。有一个二进制分类模型的结果如下:
查准率:0,查全率:1
这里,如果采用算术平均值,得到的结果是0.5。很明显,上面的结果是一个“傻子”分类器处理的,忽略了输入,仅将其预测的其中一个类作为输出。现在,如果要取调和平均值,得到的结果就会是0,这是准确的,因为这个模型对于所有的目的来说都是无用的。
这看似很简单。然而在有些情况下,数据科学家更关心查准率和查全率的问题。稍稍改变上面的表达式,包含一个可调参数β来实现该目的,得出:

Fbeta衡量模型对用户的有效性,用户对查全率的重视程度是查准率的β倍。

3. 增益图和提升图
增益图和提升图主要用于检查概率的顺序。以下是构建提升图/增益图的步骤:
步骤1:计算每个样本的概率。
步骤2:按降序排列这些概率。
步骤3:每组构建十分位数时都有近10%的样本。
步骤4:计算每个十分位数的响应率,分为Good( Responders )、Bad( Non-responders )和总数。
你会获得下表,需要据此绘制增增益图或提升图:

表格提供了大量信息。累积增益图介于累计 %Right和累计 %Population图之间。下面是对应的案例图:

该图会告诉你的模型responders与non-responders的分离程度。例如,第一个十分位数有10%的数量,和14%的responders。这意味着在第一个十分位数时有140%的升力。
在第一个十分位数可以达到的最大升力是多少?从第一个表中可以知道responders的总数是3,850人,第一个十分位数也包含543个样本。因此,第一个十分位数的最大升力值可能是543/3850约为14.1%。所以该模型近乎完美。
现在绘制升力曲线。升力曲线是总升力和 %population之间的关系曲线。注意:对于随机模型,此值始终稳定在100%处。这是目前案例对应的提升图:

也可以使用十分位数绘制十分位升力:
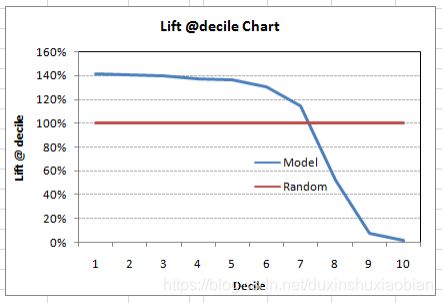
这个图说明什么?这表示模型运行到第7个十分位数都挺好。每个十分位数都会倾向non-responders。在3分位数和7分位数之间,任何升力在100%以上的模型(@十分位数)都是好模型。否则可能要先考虑采样。
提升图或增益图表广泛应用于目标定位问题。这告诉我们,在特定的活动中,可以锁定客户在哪个十分位数上。此外,它会告诉你对新目标数据期望的响应量。
 4. K-S图
4. K-S图
K-S或Kolmogorov-Smirnov图表衡量分类模型的性能。更准确地说,K-S是衡量正负例分布分离程度的指标。如果分数将人数划分为单独两组,其中一组含所有正例,另一组含所有负例,则K-S值为100。
另一方面,如果模型不能区分正例和负例,那么就如同模型从总体中随机选择案例一样,K-S为0。在大多数分类模型中,K-S值将从0和100之间产生,并且值越高,模型对正例和负例的区分越好。
对于以上案例,请看表格:

还可以绘制 %Cumulative Good和Bad来查看最大分离。下面是示例图:

到目前为止,所涵盖的指标主要用于分类问题。直到这里,已经了解了混淆矩阵、增益图和提升图以及kolmogorov-smirnov图。接下来继续学习一些更重要的指标。

5. AUC曲线( AUC-ROC )
这又是业内常用的指标之一。使用ROC曲线的最大优点是不受responders比例变化的影响。下文会讲得更清楚。
首先试着去理解什么是ROC(接收器操作特性)曲线。如果看下面的混淆矩阵,就会观察到对于概率模型,每个指标的值不同。

因此,对于每种敏感度,都会有不同的特异度。两者差异如下:

ROC曲线是敏感度和(1-特异度)之间的曲线。(1-特异性)也称为假正率,敏感度也称为真正率。下图本案例的ROC曲线。

以阈值为0.5为例(参考混淆矩阵)。这是混淆矩阵:

如你所见,此时敏感度为99.6%,(1-特异性)大约为60%。该坐标在ROC曲线中成为点。为了将该曲线表达成数值,就要计算该曲线下的面积( AUC )。
注意,整个正方形的面积是1 * 1 = 1。因此,AUC本身就是曲线下的比值和总面积。对于那个案例,得到AUC ROC的值为96.4%。以下是一些拇指规则( thumb rules ):
· 0.90-1=优秀(A)
· 0.80-0.90 =良好(B)
· 0.70-0.80 =一般(C)
· 0.60-0.70 =差(D)
· 0.50-0.60 =失败(F)
可以看出,目前的模型属于优秀范围。但也可能只是过度拟合。这种情况下,验证显得迫在眉睫了。
以下几点需注意:
1.对于作为类输出的模型,将在ROC图中用单个点表示。
2.这些模型无法相互比较,因为需要在单个指标基础上进行判断而不是多个指标。例如,具有参数(0.2,0.8)的模型和具有参数(0.8,0.2)的模型可以来自相同的模型,因此不应直接比较这些指标。
3.在概率模型的情况下,有幸能得到一个AUC-ROC的单个数字。但是,仍然需要查看整个曲线去做最终决定。又可能是一个模型在某些范围中性能更好,其他的在别的范围中更好。
使用ROC的优点
为什么要使用ROC而不是升力曲线等指标?
升力取决于人口的总响应率。因此,如果人口的响应率发生变化,同一模型将带来不同的升力图。解决这种问题的方案可以是真正的升力图(在每个十分位数处找到升力值和完美模型升力值的比率)。但这种比例很少对企业有价值。
另一方面,ROC曲线几乎与响应率无关。这是因为它有两个来自混淆矩阵柱状计算中的轴。在响应率变化的情况下,x轴和y轴的分子和分母也会有相应的改变。

6. 对数损失
确定模型性能时AUC-ROC会考虑预测概率。然而,AUC ROC存在一个问题,就是只考虑概率的顺序,因此忽略了模型对更可能是正样本预测更高概率的能力。这种情况下,可以采取对数损失,它只是每个案例修正预测概率的对数的负平均值。

· p( yi )是正类预测概率
· 1-p( yi )是负类预测概率
· yi = 1表示正类,0表示负类(实际值)
随机计算几个值的对数损失,得出上述数学函数的要点:
Logloss(1,0.1)= 2.303
Logloss(1,0.5)= 0.693
Logloss(1,0.9)= 0.105
如果绘制这种关系,曲线图如下:

从斜率向右下方逐渐平缓可以明显看出,随着预测概率的提高,对数损失值逐渐下降。不过反方向移动时,对数损失快速增加而预测概率趋近于0。
因此,降低对数损失,对模型更好。但是,对于好的对数损失没有绝对的衡量标准,它取决于用例或者应用程序。
虽然AUC是根据具有不同决策阈值的二进制分类计算的,但对数损失实际上考虑了分类的“确定性”。

7. 基尼系数
基尼系数有时用于分类问题。基尼系数可由AUC ROC数直接导出。基尼只是ROC曲线和diagnol线之间的面积与上述三角形的面积之比。下面是使用公式:
Gini = 2*AUC – 1
基尼系数高于60%,模型就很好。对于目前的情况而言,基尼系数的值为92.7%。

8. Concordant – Discordant ratio
对于任何分类预测问题,这也是最重要的指标之一。想要理解这个,先假设有3名学生今年有可能通过。以下是预测:
A – 0.9
B – 0.5
C – 0.3
现在想象一下。如果从这三个学生中挑两对,会有多少对?将有3种组合:AB、BC和CA。现在,年底结束后,A和C通过了,而B没有。不行,选择所有配对,找到一个responder和其他non-responder。这样的配对有多少?
有两对:AB和BC。现在对于2对中的每一对,一致对( concordant pair )是responder的概率高于non-responder的。而不一致的对( discordant pair )虽情况相反但也是如此。如果两个概率相等,就称之为相当的。现在来看看案例中发生了什么:
AB – Concordant
BC – Discordant
因此,在这个例子中50%的一致案例。一致率超过60%会被视为好模型。在决定锁定客户数量时,通常不使用此指标标准。它主要用于测试模型的预测能力。像锁定客户数量的话,就再次采用KS图或者提升图。

9. 均方根误差
RMSE是回归问题中最常用的评估指标。它遵循一个假设,即误差无偏,遵循正态分布。以下是RMSE需要注意的要点:
1.“平方根”使该指标能够显示很多偏差。
2.此指标的“平方”特性有助于提供更强大的结果,从而防止取消正负误差值。换句话说,该指标恰当地显示了错误术语的合理幅度。
3.它避免使用绝对误差值,这在数学计算中是极不希望看到的。
4.有更多样本时,使用RMSE重建误差分布被认为更可靠。
5.RMSE受异常值的影响很大。因此,请确保在使用此指标之前已从数据集中删除了异常值。
6.与平均绝对误差相比,RMSE提供更高的权重并惩罚大错误。
RMSE指标由以下公式给出:

其中,N是样本总数。

10. 均方根对数误差
在均方根对数误差的情况下,采用预测和实际值的对数。基本上,正在测量的方差就是变化。预测值和真值都很庞大时不希望处理预测值和实际值存在的巨大差异话通常采用RMSLE。
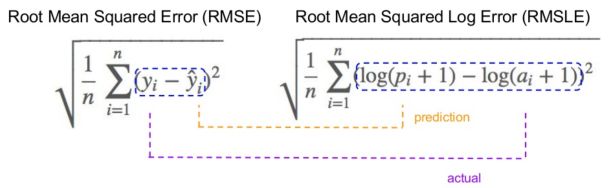
1.如果预测值和实际值都很小:RMSE和RMSLE相同。
2.如果预测值或实际值很大:RMSE> RMSLE
3.如果预测值和实际值都很大:RMSE> RMSLE(RMSLE几乎可以忽略不计)

11. R-Squared/Adjusted R-Squared
已经知道RMSE降低时,模型的性能将会提高。但仅凭这些值并不直观。
在分类问题的情况下,如果模型的准确度为0.8,可以衡量模型对随机模型的有效性,哪个准确度为0.5。因此,随机模型可以作为基准。但是在谈论RMSE指标时,却没有比较基准。
这里可以使用R-Squared指标。R-Squared的公式如下:


MSE(模型):预测值与实际值的平均误差
MSE(基线):平均预测值与实际值的平均误差
换言之,与一个非常简单的模型相比,回归模型可以说很不错了,一个简单的模型只能预测训练集中目标的平均值作为预测。
Adjusted R-Squared调整后的可决系数(参考)
模型表现与baseline相同时,R-Squared为0。模型越好,R2值越高。最佳模型含所有正确预测值时,R-Squared为1。但是,向模型添加新功能时,R-Squared值会增加或保持不变。R-Squared不会因添加了对模型无任何价值的功能而被判“处罚”。因此,R-Squared的改进版本是经过调整的R-Squared。调整后的R-Squared的公式如下:

k:特征数量
n:样本数量
如你所见,此指标会考虑特征的数量。添加更多特征时,分母项n-(k +1)减小,因此整个表达式在增大。
如果R-Squared没有增大,那意味着添加的功能对模型没有价值。因此总的来说,在1上减去一个更大的值,调整的r2,反而会减少。
除了这11个指标之外,还有另一种检验模型性能。这7种方法在数据科学中具有统计学意义。但是,随着机器学习的到来,我们现在拥有更强大的模型选择方法。没错!现在来谈论一下交叉验证。
虽然交叉验证不是真正的评估指标,会公开用于传达模型的准确性。但交叉验证提供了足够直观的数据来概括模型的性能。
现在来详细了解交叉验证。

12.交叉验证(虽然不是指标!)
首先来了解交叉验证的重要性。由于日程紧张,这些天笔者没有太多时间去参加数据科学竞赛。很久以前,笔者参加了Kaggle的TFI比赛。这里就不相信介绍笔者竞赛情况了,我想向大家展示个人的公共和私人排行榜得分之间的差异。
以下是Kaggle得分的一个例子!
对于TFI比赛,以下是个人的三个解决方案和分数(越小越好):
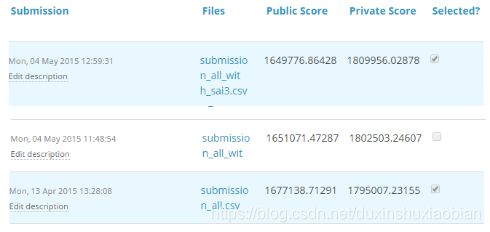
可以注意到,公共分数最差的第三个条目成为了私人排行榜上的最佳模型。“submission_all.csv”之前有20多个模型,但笔者仍然选择“submission_all.csv”作为最终条目(实践证明确实很有效)。是什么导致了这种现象?笔者的公共和私人排行榜的差异是过度拟合造成的。
模型变得高度复杂时,过度拟合也会开始捕捉噪音。这种“噪音”对模型没有任何价值,只会让其准确度降低。
下一节中,笔者将讨论在真正了解测试结果之前,如何判断解决方案是否过度拟合。
概念:交叉验证
交叉验证是任何类型数据建模中最重要的概念之一。就是说,试着留下一个样本集,但并不在这个样本集上训练模型,在最终确定模型之前测试依据该样本集建立的模型。

上图显示了如何使用及时样本集验证模型。简单地将人口分成2个样本,在一个样本上建立模型。其余人口用于及时验证。
上述方法会有不好的一面吗?
这种方法一个消极面就是在训练模型时丢失了大量数据。因此,模型的偏差会很大。这不会给系数做出最佳估测。那么下一个最佳选择是什么?
如果,将训练人口按50:50的比例分开,前50用于训练,后50用于验证。然后两组颠倒过来进行实验。通过这种方式,在整个人口基础上训练模型,但一次只借用50%。这样可以减少偏差,因为样品选择在一定程度上可以提供较小的样本来训练模型。这种方法称为2折交叉验证。
k折交叉验证
最后一个例子是从2折交叉验证推断到k折交叉验证。现在,尝试将k折交叉验证的过程可视化。
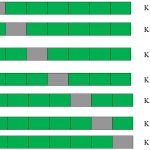
这是一个7折交叉验证。
真实情况是这样:将整个人口划分为7个相同的样本集。现在在6个样本集(绿色框)上训练模型,在1个样本集(灰色框)上进行验证。然后,在第二次迭代中,使用不同的样本集训练模型作为验证。在7次迭代中,基本上在每个样本集上都构建了模型,同时作为验证。这是一种降低选择偏差、减少预测方差的方法。一旦拥有所有这7个模型,就可以利用平均误差项找到最好的模型。
这是如何帮助找到最佳(非过度拟合)模型的?
k折交叉验证广泛用于检查模型是否是过度拟合。如果k次建模中的每一次的性能指标彼此接近,那么指标的均值最高。在Kaggle比赛中,你可能更多地依赖交叉验证分数而不是Kaggle公共分数。这样就能确保公共分数不单单是偶然出现。
如何使用任何型号实现k折?
R和Python中的k折编码非常相似。以下是在Python中编码k-fold的方法:
from sklearn import cross_validation model = RandomForestClassifier(n_estimators=100) #Simple K-Fold cross validation. 5 folds. #(Note: in older scikit-learn versions the "n_folds" argument is named "k".) cv = cross_validation.KFold(len(train), n_folds=5, indices=False) results = [] # "model" can be replaced by your model object # "Error_function" can be replaced by the error function of your analysis for traincv, testcv in cv: probas = model.fit(train[traincv], target[traincv]).predict_proba(train[testcv]) results.append( Error_function ) #print out the mean of the cross-validated results print "Results: " + str( np.array(results).mean() )
但是如何选择k呢?
这是棘手的部分。需要权衡来选择k。
对于小k,有更高的选择偏差但性能差异很小。
对于大k,有小的选择偏差但性能差异很大。
想想极端情况:
k = 2:只有2个样本,类似于50-50个例子。在这里,每次仅在50%的人口中构建模型。但由于验证会有很多人,所以 验证性能的差异是最小的。
k =样本数( n ):这也称为“留一法”。有n次样本,建模重复n次,只留下一个样本集进行交叉验证。因此,选择偏差很小,但验证性能的差异非常大。
通常,针对大多数情况,建议使用k = 10的值。

结语
在训练样本上评估模型毫无意义。留出大量的样本来验证模型也是在浪费数据。k折交叉验证为我们提供了一种使用单个数据点的方法,可以在很大程度上减少选择偏差。同时,K折交叉验证可以与任何建模技术一起使用。
此外,本文中介绍的指标标准是分类和回归问题中评估最常用的指标标准。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)