【2022 MS MARCO】【阿里】HLATR:基于混合列表感知Transformer重排的多阶段文本检索增强 ( .feat PRM:个性化的推荐重排)
论文: 《HLATR: Enhance Multi-stage Text Retrieval with Hybrid List Aware Transformer Reranking》
1. 背景
由于数据规模和计算资源的限制,当前文本检索系统通常遵循召回-排序范式,召回和精排模型通常被实例化为我们在《【NAACL 2021】AugSBERT:用于改进成对句子评分任务的 Bi-encoder 数据增强方法》中介绍到的 Bi-Encoder 和 Cross-Encoder。
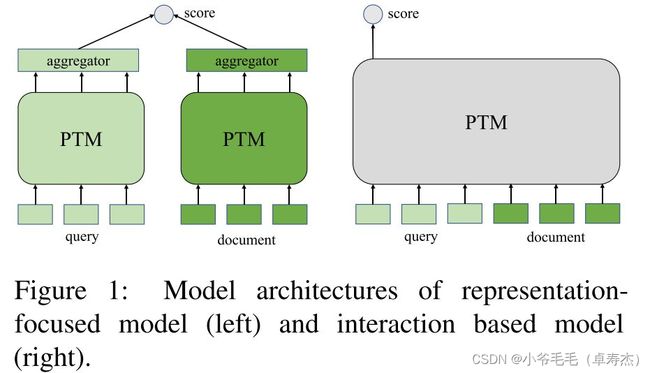
- Bi-Encoder:

- Cross-Encoder:

虽然在检索系统中,召回和排序模型是紧密关联的,但是目前已发表的工作大多仅致力于优化整个检索系统的单个模块。也就是说,面向召回模型的优化工作大多不会考虑排序模型的性能,反之亦然。虽然最近也出现了一些联合优化召回模型和排序模型的工作,比如以前介绍过的:
《【NAACL 2021】AugSBERT:用于改进成对句子评分任务的 Bi-encoder 数据增强方法》
《【NAACL 2022】GPL:用于密集检索的无监督域自适应的生成伪标记》
《【ICLR 2022】Trans-Encoder:通过自蒸馏和相互蒸馏的无监督句对建模》
但是这些工作的出发点都是利用表达能力更强的排序模型来提升召回模型的性能(AugSBERT、GPL),或是尝试蒸馏进行相互的提升(Trans-Encoder)。
由于训练过程中负样本规模和特征的差异,召回模型更偏向于学习粗粒度相关性,而排序模型更偏向于学习细粒度相关性。 这里需要注意的一点是,细粒度相关性和粗粒度相关性并无优劣之分,它们的关系实际上有点像模型鲁棒性和模型泛化性的关系。基于上述分析,我们可以猜想召回和排序的特征实际上是有一定的互补性的,如果我们可以有效地融合召回和排序的特征并用来对候选文档集合做进一步的重排序,是不是能够进一步提升整个系统的排序性能呢?
2. HLATR
基于此,本文作者在传统的召回-排序两阶段检索系统的基础上,提出了第三个重排阶段,该阶段融合了粗粒度召回特征和细粒度排序特征,进一步改善query和候选document的相关性打分,从而提升整个系统的检索性能。本文作者将该三阶段重排序的模型命名为混合列表感知排序模型HLATR ,如下图所示:

-
HLATR采用Transformer Encoder作为特征融合结构,整体结构如下图所示:
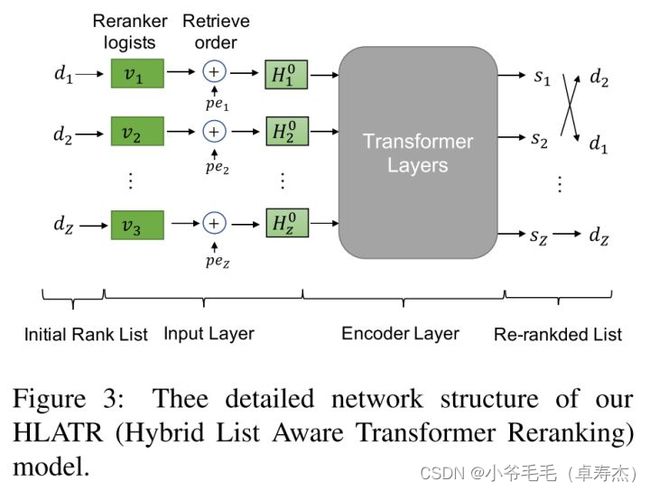
-
作者将排序模型顶层输出的文档表示向量作为HLATR输入的token embedding:

其中 W v W_v Wv为要学习的参数。 -
将召回模型输出的排序序号作为对应文档的position embedding:

其中 p p p为要学习的参数。 -
Transformer Encoder 的底层输入为 :
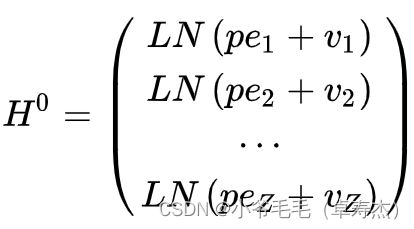
其中 Z Z Z为候选文档集合的大小。 -
每个位置的输出为 q q q和 d i d_i di的打分:

-
采用listwise的对比损失优化模型:

3. 实验结果
实验结果如下表所示:
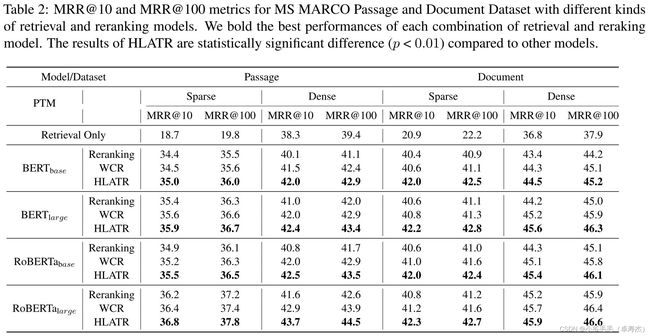
我们可以发现在不同的实验设置下,HLATR的性能均超越了两阶段排序结构和WCR策略。WCR策略是一个简单的基线策略——将召回打分和排序打分做一个线性加权融合:

说明HLATR带来的性能提升对模型类型和模型大小来说均是鲁棒的。另外,WCR策略实际上也能够带来小幅度的稳定提升,这也说明混合召回排序粗细粒度能增强文本检索的猜想是正确的。
4. 思考
4.1 对比排序阶段
HLATR 做的是 listwise 级别的相关性建模,而第二阶段排序的相关性建模大多只能做到对输出的相关性打分进行 pointwise 或 pairwise 建模。HLATR 有着更大的负样本规模,输入的每个位置都表示着一个文档,在训练过程中我们可以考虑输入召回模型返回的整个文档集合,而不是像第二阶段排序那样还需要随机抽样负样本来构造训练集。
4.2 对比 PRM:个性化的推荐重排
发现阿里出的HLATR搜索重排模型,和同样是阿里的推荐重排模型PRM结构非常相似:
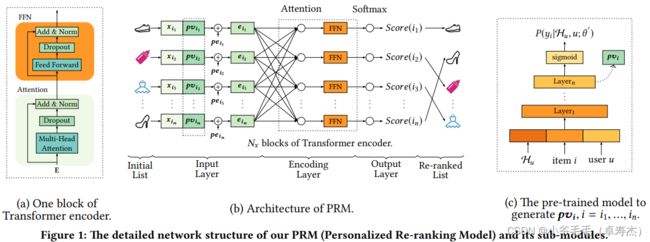
可以参阅 paper《Personalized Re-ranking for Recommendation》
对于在排序阶段得到的items,我们可以得到它们对应的原始特征向量 x i 1 , x i 2 , . . . , x i n {x_{i_1}, x_{i_2}, ..., x_{i_n}} xi1,xi2,...,xin,组合成了初始的特征矩阵。然后将这个矩阵和一个PV的个性化矩阵concat起来,组成一个embedding矩阵。PRM的x部分,类似对应HLATR中召回模型输出的向量。
个性化矩阵PV,那么它是怎么得到的呢?如下图所示:

PRM的PV部分,类似对应HLATR中排序模型输出的向量。
PRM的 position embedding(PE) 是排序结果位置embedding,而HLATR的PE是召回结果位置embedding。
对比PRM,引发了我对于HLATR架构的一个困惑:
HLATR并没有类似于PRM引入items原始特征那样,很好的引入document的特征。 HLATR中的向量 v v v是基于排序模型向量的输入,但是排序模型中该向量是接着point-wise 二分类任务,所以该向量应该是不能很好的表达document,这样一来可能就会影响 Transformer Encoder 对句子间进行特征交互的效果。
借鉴PRM,我认为HLATR 的 Transformer Encoder输出可以尝试改为以下方案:
[bi-encoder emb;cross-encoder emb] + [recall position emb;rank position emb]
猜想这可能会有更好的效果,当然这需要实验验证 ~~