可能是史上最适合入门SQL语句的教程——自学SQL网学习笔记
自学SQL网Note
学习网址:http://xuesql.cn/
表格、题目和知识点采集于自学SQL网,这个网站提供直接练习SQL的页面,免去了安装MySQL和导入表格的繁琐步骤,非常推荐初学者学习!
部分答案参考:https://blog.csdn.net/Xemacil/article/details/107086456
因为现在网站删掉了部分题目,我根据上面的博客补充了之前的题目,但是否准确就无法验证了。
本文除了整理提供了网站的答案外,还写入了部分从的题目中得到的思考和总结,适合需要初步学习SQL的朋友。
SQL Lesson 1: SELECT 查询 101
| Id | Title | Director | Year | Length_minutes |
|---|---|---|---|---|
| 1 | Toy Story | John Lasseter | 1995 | 81 |
| 2 | A Bug’s Life | John Lasseter | 1998 | 95 |
| 3 | Toy Story 2 | John Lasseter | 1999 | 93 |
| 4 | Monsters, Inc. | Pete Docter | 2001 | 92 |
| 5 | Finding Nemo | Finding Nemo | 2003 | 107 |
| 6 | The Incredibles | Brad Bird | 2004 | 116 |
| 7 | Cars | John Lasseter | 2006 | 117 |
| 8 | Ratatouille | Brad Bird | 2007 | 115 |
| 9 | WALL-E | Andrew Stanton | 2008 | 104 |
| 10 | Up | Pete Docter | 2009 | 101 |
| 11 | Toy Story 3 | Lee Unkrich | 2010 | 103 |
| 12 | Cars 2 | John Lasseter | 2011 | 120 |
| 13 | Brave | Brenda Chapman | 2012 | 102 |
| 14 | Monsters University | Dan Scanlon | 2013 | 110 |
-
找到所有电影的名称Title
SELECT Title FROM Movies; -
找到所有电影的导演
SELECT Director FROM Movies; -
找到所有电影的名称和导演
SELECT Title,Director FROM Movies; -
找到所有电影的名称和上映年份
SELECT Title,Year FROM Movies; -
找到所有电影的所有信息
SELECT * FROM Movies; -
找到所有电影的名称,Id和播放时长
SELECT Title,Id,Length_minutes FROM Movies; -
请列出所有电影的Id,名称和出版国(即美国)
SELECT Id,Title,“美国” as Country FROM Movies;note:这里再Country列加入“美国”这个条件,从而简化了后续增加WHERE的语法量
总结:
主要是
SELECT * from 表名的应用
SQL Lesson 2: 条件查询 (constraints) (Pt. 1)
| Id | Title | Director | Year | Length_minutes |
|---|---|---|---|---|
| 1 | Toy Story | John Lasseter | 1995 | 81 |
| 2 | A Bug’s Life | John Lasseter | 1998 | 95 |
| 3 | Toy Story 2 | John Lasseter | 1999 | 93 |
| 4 | Monsters, Inc. | Pete Docter | 2001 | 92 |
| 5 | Finding Nemo | Finding Nemo | 2003 | 107 |
| 6 | The Incredibles | Brad Bird | 2004 | 116 |
| 7 | Cars | John Lasseter | 2006 | 117 |
| 8 | Ratatouille | Brad Bird | 2007 | 115 |
| 9 | WALL-E | Andrew Stanton | 2008 | 104 |
| 10 | Up | Pete Docter | 2009 | 101 |
| 11 | Toy Story 3 | Lee Unkrich | 2010 | 103 |
| 12 | Cars 2 | John Lasseter | 2011 | 120 |
| 13 | Brave | Brenda Chapman | 2012 | 102 |
| 14 | Monsters University | Dan Scanlon | 2013 | 110 |
-
找到Id为6的电影
SELECT * FROM Movies WHERE Id = 6; -
找到在2000-2010年间Year上映的电影
SELECT * FROM Movies WHERE Year BETWEEN 2000 AND 2010; -
找到不是在2000-2010年间Year上映的电影
SELECT * FROM Movies WHERE Year not BETWEEN 2000 AND 2010; -
找到头5部电影
SELECT * FROM Movies LIMIT 5;note: 详见LIMIT方法
-
找到2010(含)年之后的电影里片长小于两个小时的片子
SELECT * FROM Movies WHERE Year >=2010 AND Length_minutes < 120; -
找到99年和09年的电影,只要列出年份和片长看下
SELECT Year,Length_minutes FROM Movies WHERE Year =1999 or Year =2009;
补充:
LIMIT方法
LIMIT语句用于限制select语句返回的行数
主要有两个参数:LIMIT 和 offset
SELECT
column_list
FROM
table1
ORDER BY column_list
LIMIT row_count OFFSET offset;
SQL
在这个语法中,
row_count确定将返回的行数。OFFSET子句在开始返回行之前跳过偏移行。OFFSET子句是可选的。 如果同时使用LIMIT和OFFSET子句,OFFSET会在LIMIT约束行数之前先跳过偏移行。
row_count是限制一共返回多少行
offset是从上到下跳过多少行开始
LIMIT 1 offset 1
就是取第二行
LIMIT 5 offset 3
就是从第四行开始取五行
总结:
这里讲了几种简单的条件查询方法
| Operator(关键字) | Condition(意思) | SQL Example(例子) |
|---|---|---|
| =, !=, < <=, >, >= | Standard numerical operators 基础的 大于,等于等比较 | col_name != 4 |
| BETWEEN … AND … | Number is within range of two values (inclusive) 在两个数之间 | col_name BETWEEN 1.5 AND 10.5 |
| NOT BETWEEN … AND … | Number is not within range of two values (inclusive) 不在两个数之间 | col_name NOT BETWEEN 1 AND 10 |
| IN (…) | Number exists in a list 在一个列表 | col_name IN (2, 4, 6) |
| NOT IN (…) | Number does not exist in a list 不在一个列表 | col_name NOT IN (1, 3, 5) |
可以用 AND or OR 这两个关键字来组装多个条件(表示并且,或者)
(ie. num_wheels >= 4 AND doors <= 2 这个组合表示 num_wheels属性 大于等于 4 并且 doors 属性小于等于 2)
SQL Lesson 3: 条件查询(constraints) (Pt. 2)
| Id | Title | Director | Year | Length_minutes |
|---|---|---|---|---|
| 1 | Toy Story | John Lasseter | 1995 | 81 |
| 2 | A Bug’s Life | John Lasseter | 1998 | 95 |
| 3 | Toy Story 2 | John Lasseter | 1999 | 93 |
| 4 | Monsters, Inc. | Pete Docter | 2001 | 92 |
| 5 | Finding Nemo | Finding Nemo | 2003 | 107 |
| 6 | The Incredibles | Brad Bird | 2004 | 116 |
| 7 | Cars | John Lasseter | 2006 | 117 |
| 8 | Ratatouille | Brad Bird | 2007 | 115 |
| 9 | WALL-E | Andrew Stanton | 2008 | 104 |
| 10 | Up | Pete Docter | 2009 | 101 |
| 11 | Toy Story 3 | Lee Unkrich | 2010 | 103 |
| 12 | Cars 2 | John Lasseter | 2011 | 120 |
| 13 | Brave | Brenda Chapman | 2012 | 102 |
| 14 | Monsters University | Dan Scanlon | 2013 | 110 |
- 找到所有
Toy Story系列电影
SELECT * FROM Movies WHERE Title LIKE “%Toy Story%”; - 找到所有John Lasseter导演的电影
SELECT * FROM Movies WHERE Director LIKE “John Lasseter%”; - 找到所有不是John Lasseter导演的电影
SELECT * FROM Movies WHERE Director not LIKE “John Lasseter%”; - 找到所有电影名为 “WALL-” 开头的电影
SELECT * FROM Movies WHERE Title LIKE “%Wall%”; - 有一部98年电影中文名《虫虫危机》请给我找出来
SELECT * FROM Movies WHERE Year =1998; - 找出所有Pete导演的电影,只要列出电影名,导演名和年份就可以
SELECT Title,Director,Year FROM Movies WHERE Director LIKE “%Pete%” - John Lasseter导演了两个系列,一个Car系列一个Toy Story系列,请帮我列出这John Lasseter导演两个系列千禧年之后(含千禧年)的电影
SELECT * FROM Movies WHERE Director="John Lasseter"AND Year>= 2000
总结:
| Operator(操作符) | Condition(解释) | Example(例子) |
|---|---|---|
| = | Case sensitive exact string comparison (notice the single equals)完全等于 | col_name = “abc” |
| != or <> | Case sensitive exact string inequality comparison 不等于 | col_name != “abcd” |
| LIKE | Case insensitive exact string comparison 没有用通配符等价于 = | col_name LIKE “ABC” |
| NOT LIKE | Case insensitive exact string inequality comparison 没有用通配符等价于 != | col_name NOT LIKE “ABCD” |
| % | Used anywhere in a string to match a sequence of zero or more characters (only with LIKE or NOT LIKE) 通配符,代表匹配0个以上的字符 | col_name LIKE “%AT%” (matches “AT”, “ATTIC”, “CAT” or even “BATS”) “%AT%” 代表AT 前后可以有任意字符 |
| _ | Used anywhere in a string to match a single character (only with LIKE or NOT LIKE) 和% 相似,代表1个字符 | col_name LIKE “AN_” (matches “AND”, but not “AN”) |
| IN (…) | String exists in a list 在列表 | col_name IN (“A”, “B”, “C”) |
| NOT IN (…) | String does not exist in a list 不在列表 | col_name NOT IN (“D”, “E”, “F”) |
LIKE + 通配符对条件进行模糊匹配
=是对条件进行精准匹配,用LIKE可以模糊匹配
通配符%代表匹配0个以上的任意字符
通配符_代表1个任意字符
SQL Lesson 4: 查询结果Filtering过滤 和 sorting排序
Table: Movies (Read-Only)
| Id | Title | Director | Year | Length_minutes |
|---|---|---|---|---|
| 1 | Toy Story | John Lasseter | 1995 | 81 |
| 2 | A Bug’s Life | John Lasseter | 1998 | 95 |
| 3 | Toy Story 2 | John Lasseter | 1999 | 93 |
| 4 | Monsters, Inc. | Pete Docter | 2001 | 92 |
| 5 | Finding Nemo | Finding Nemo | 2003 | 107 |
| 6 | The Incredibles | Brad Bird | 2004 | 116 |
| 7 | Cars | John Lasseter | 2006 | 117 |
| 8 | Ratatouille | Brad Bird | 2007 | 115 |
| 9 | WALL-E | Andrew Stanton | 2008 | 104 |
| 10 | Up | Pete Docter | 2009 | 101 |
| 11 | Toy Story 3 | Lee Unkrich | 2010 | 103 |
| 12 | Cars 2 | John Lasseter | 2011 | 120 |
| 13 | Brave | Brenda Chapman | 2012 | 102 |
| 14 | Monsters University | Dan Scanlon | 2013 | 110 |
- 按导演名
排重列出所有电影(只显示导演),并按导演名正序排列
SELECT DISTINCT Director FROM Movies ORDER BY Director; - 列出按上映年份最新上线的4部电影
SELECT * FROM Movies ORDER BY Year DESC LIMIT 4; - 按电影名字母序升序排列,列出前5部电影
SELECT * FROM Movies ORDER BY Title ASC LIMIT 5; - 按电影名字母序升序排列,列出上一题
之后的5部电影
SELECT * FROM Movies ORDER BY Title ASC LIMIT 5 offset 5; - 如果按片长排列,John Lasseter导演导过片长第3长的电影是哪部,列出名字即可
SELECT Title FROM Movies WHERE Director=“John Lasseter” ORDER BY Length_minutes DESC LIMIT 1 offset 2 - 按导演名字母升序,如果导演名相同按年份降序,取前10部电影给我
SELECT * FROM Movies ORDER BY Director ASC,Year DESC LIMIT 10;
总结:
1、WHERE/ORDER BY/LIMIT OFFSET要按这个顺序来写
2、ORDER BY的降序是DESC
3、DISTINCT是将该列去重
SQL Review: 复习 SELECT 查询
Table: North_american_cities (Read-Only)
| City | Country | Population | Latitude | Longitude |
|---|---|---|---|---|
| Guadalajara | Mexico | 1500800 | 20.659699 | -103.349609 |
| Toronto | Canada | 2795060 | 43.653226 | -79.383184 |
| Houston | United States | 2195914 | 29.760427 | -95.369803 |
| New York | United States | 8405837 | 40.712784 | -74.005941 |
| Philadelphia | United States | 1553165 | 39.952584 | -75.165222 |
| Havana | Cuba | 2106146 | 23.05407 | -82.345189 |
| Mexico City | Mexico | 8555500 | 19.432608 | -99.133208 |
| Phoenix | United States | 1513367 | 33.448377 | -112.074037 |
| Los Angeles | United States | 3884307 | 34.052234 | -118.243685 |
| Ecatepec de Morelos | Mexico | 1742000 | 19.601841 | -99.050674 |
| Montreal | Canada | 1717767 | 45.501689 | -73.567256 |
| Chicago | United States | 2718782 | 41.878114 | -87.629798 |
1.列出所有加拿大人的Canadian信息(包括所有字段)
SELECT * FROM North_american_cities WHERE Country=“Canada”;
2.列出所有美国United States的城市按纬度从北到南排序(包括所有字段)
SELECT * FROM North_american_cities WHERE Longitude < ‘-87.629798’ ORDER BY Longitude ASC;
--SELECT * FROM North_american_cities WHERE Longitude < (SELECT Longitude FROM North_american_cities WHERE City = ‘Chicago’) ORDER BY Longitude;
3.列出所有在Chicago西部的城市,从西到东排序(包括所有字段)
SELECT * FROM North_american_cities WHERE Longitude<-87.629798 ORDER BY Longitude ASC;
4.用人口数Population排序,列出墨西哥Mexico最大的2个城市(包括所有字段)
SELECT * FROM North_american_cities WHERE Country = ‘Mexico’ ORDER BY Population DESC LIMIT 2;
5.列出美国United States人口3-4位的两个城市和他们的人口(包括所有字段)
SELECT * FROM North_american_cities WHERE Country=‘United States’ ORDER BY Population DESC LIMIT 2 offset 2;
6.北美所有城市,请按国家名字母序从A-Z再按人口从多到少排列看下前10位的城市(包括所有字段)
SELECT * FROM North_american_cities ORDER BY Country ASC,Population DESC LIMIT 10;
总结:
这节没啥好总结的,单表查询的基本操作看之前的就可以。
SQL Lesson 6: 用JOINs进行多表联合查询
Table: Movies (Read-Only)
| Id | Title | Director | Year | Length_minutes |
|---|---|---|---|---|
| 1 | Toy Story | John Lasseter | 1995 | 81 |
| 2 | A Bug’s Life | John Lasseter | 1998 | 95 |
| 3 | Toy Story 2 | John Lasseter | 1999 | 93 |
| 4 | Monsters, Inc. | Pete Docter | 2001 | 92 |
| 5 | Finding Nemo | Finding Nemo | 2003 | 107 |
| 6 | The Incredibles | Brad Bird | 2004 | 116 |
| 7 | Cars | John Lasseter | 2006 | 117 |
| 8 | Ratatouille | Brad Bird | 2007 | 115 |
| 9 | WALL-E | Andrew Stanton | 2008 | 104 |
| 10 | Up | Pete Docter | 2009 | 101 |
| 11 | Toy Story 3 | Lee Unkrich | 2010 | 103 |
| 12 | Cars 2 | John Lasseter | 2011 | 120 |
| 13 | Brave | Brenda Chapman | 2012 | 102 |
| 14 | Monsters University | Dan Scanlon | 2013 | 110 |
Table: Boxoffice (Read-Only)
| Movie_id | Rating | Domestic_sales | International_sales |
|---|---|---|---|
| 5 | 8.2 | 380843261 | 555900000 |
| 14 | 7.4 | 268492764 | 475066843 |
| 8 | 8 | 206445654 | 417277164 |
| 12 | 6.4 | 191452396 | 368400000 |
| 3 | 7.9 | 245852179 | 239163000 |
| 6 | 8 | 261441092 | 370001000 |
| 9 | 8.5 | 223808164 | 297503696 |
| 11 | 8.4 | 415004880 | 648167031 |
| 1 | 8.3 | 191796233 | 170162503 |
| 7 | 7.2 | 244082982 | 217900167 |
| 10 | 8.3 | 293004164 | 438338580 |
| 4 | 8.1 | 289916256 | 272900000 |
| 2 | 7.2 | 162798565 | 200600000 |
| 13 | 7.2 | 237283207 | 301700000 |
-
找到所有电影的国内Domestic_sales和国际销售额
SELECT * FROM Movies LEFT JOIN Boxoffice on Movies.Id = Boxoffice.Movie_id; -
找到所有国际销售额比国内销售大的电影
SELECT * FROM Movies LEFT JOIN Boxoffice on Movies.Id = Boxoffice.Movie_id WHERE demostic_sales < International_sales; -
找出所有电影按市场占有率Rating倒序排列
SELECT * FROM Movies LEFT JOIN Boxoffice on Movies.Id = Boxoffice.Movie_id ORDER BY Rating ASC; -
每部电影按国际销售额比较,排名最靠前的导演是谁,国际销量多少
SELECT Director,International_sales FROM Movies LEFT JOIN Boxoffice on Movies.Id = Boxoffice.Movie_id ORDER BY International_sales LIMIT 1;这个答案不对!
自己写的:SELECT Director, International_sales FROM Movies INNER JOIN Boxoffice On Movies.Id = Boxoffice.Movie_id GROUP BY Director ORDER BY International_sales DESC LIMIT 1;
要先GROUP BY一下把International_sales加起来然后再排序
总结:
用JOINs进行多表联合查询
主键(primary key), 一般关系数据表中,都会有一个属性列设置为 主键(primary key)。主键是唯一标识一条数据的,不会重复复(想象你的身份证号码)。一个最常见的主键就是auto-incrementing integer(自增Id,每写入一行数据Id+1, 当然字符串,hash值等只要是每条数据是唯一的也可以设为主键.
借助主键(primary key)(当然其他唯一性的属性也可以),我们可以把两个表中具有相同 主键Id的数据连接起来(因为一个Id可以简要的识别一条数据,所以连接之后还是表达的同一条数据)(你可以想象一个左右连线游戏)。具体我们用到 JOIN 关键字。我们先来学习 INNER JOIN.
用INNER JOIN 连接表的语法
SELECT column, another_table_column, … FROM mytable (主表)
INNER JOIN another_table (要连接的表)
ON mytable.Id = another_table.Id (想象一下刚才讲的主键连接,两个相同的连成1条)
WHERE condition(s) ORDER BY column, … ASC/DESC LIMIT num_limit OFFSET num_offset;
通过ON条件描述的关联关系;INNER JOIN 先将两个表数据连接到一起. 两个表中如果通过Id互相找不到的数据将会舍弃。此时,你可以将连表后的数据看作两个表的合并,SQL中的其他语句会在这个合并基础上 继续执行(想一下和之前的单表操作就一样了).
还有一个理解INNER JOIN的方式,就是把 INNER JOIN 想成两个集合的交集。

SQL Lesson 7: 外连接(OUTER JOINs)
Table: Employees (Read-Only)
| Role | Name | Building | Years_employed |
|---|---|---|---|
| Engineer | Becky A. | 1e | 4 |
| Engineer | Dan B. | 1e | 2 |
| Engineer | Sharon F. | 1e | 6 |
| Engineer | Dan M. | 1e | 4 |
| Engineer | Malcom S. | 1e | 1 |
| Artist | Tylar S. | 2w | 2 |
| Artist | Sherman D. | 2w | 8 |
| Artist | Jakob J. | 2w | 6 |
| Artist | Lillia A. | 2w | 7 |
| Artist | Brandon J. | 2w | 7 |
| Manager | Scott K. | 1e | 9 |
| Manager | Shirlee M. | 1e | 3 |
| Manager | Daria O. | 2w | 6 |
| Engineer | Yancy I. | null | 0 |
| Artist | Oliver P. | null | 0 |
Table: Buildings (Read-Only)
| Building_name | Capacity |
|---|---|
| 1e | 24 |
| 1w | 32 |
| 2e | 16 |
| 2w | 20 |
-
找到所有有雇员的办公室(buildings)名字
SELECT DISTINCT Building FROM Employees WHERE Building is not null; -
找到所有办公室和他们的最大容量
SELECT * FROM buildings; -
找到所有办公室里的所有角色(包含没有雇员的),并做唯一输出(DISTINCT)
SELECT DISTINCT buildings.Building_name,Employees.Role FROM buildings LEFT JOIN Employees on Employees.Building=buildings.Building_name;自己写的:SELECT DISTINCT Building_name, Role FROM Buildings LEFT JOIN Employees On Buildings.Building_name = Employees.Building;
-
找到所有有雇员的办公室(buildings)和对应的容量
SELECT DISTINCT Building,capacity FROM Employees LEFT JOIN buildings on Employees.Building=buildings.Building_name WHERE Employees.Building is not null;
总结:
INNER JOIN 只会保留两个表都存在的数据(还记得之前的交集吗),这看起来意味着一些数据的丢失,在某些场景下会有问题.
真实世界中两个表存在差异很正常,所以我们需要更多的连表方式,也就是本节要介绍的左连接LEFT JOIN,右连接RIGHT JOIN 和 全连接FULL JOIN. 这几个 连接方式都会保留不能匹配的行。
用LEFT/RIGHT/FULL JOINs 做多表查询
SELECT column, another_column, … FROM mytable
INNER/LEFT/RIGHT/FULL JOIN another_table
ON mytable.Id = another_table.matching_id
WHERE condition(s) ORDER BY column, … ASC/DESC LIMIT num_limit OFFSET num_offset;
和INNER JOIN 语法几乎是一样的. 我们看看这三个连接方法的工作原理:
在表A 连接 B, LEFT JOIN保留A的所有行,不管有没有能匹配上B 反过来 RIGHT JOIN则保留所有B里的行。最后FULL JOIN 不管有没有匹配上,同时保留A和B里的所有行
!也就是说只要On 后面的条件两边都能完全对应,那么JOIN/LEFT JOIN/RIGHT JOIN都是一样的
我们还是可以用集合的图示来描述:
LEFT JOIN 
RIGHT JOIN 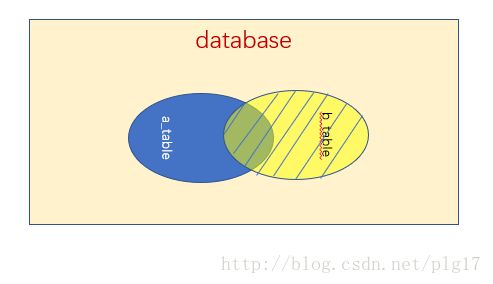
FULL JOIN 
将两个表数据1-1连接,保留A或B的原有行,如果某一行在另一个表不存在,会用 NULL来填充结果数据。所有在用这三个JOIN时,你需要单独处理 NULL. 关于 NULL 下一节会做更详细的说明
哪一列是唯一且不重复的就以它为左连的第一个表
SQL Lesson 8: 关于特殊关键字 NULLs
Table: Employees (Read-Only)
| Role | Name | Building | Years_employed |
|---|---|---|---|
| Engineer | Becky A. | 1e | 4 |
| Engineer | Dan B. | 1e | 2 |
| Engineer | Sharon F. | 1e | 6 |
| Engineer | Dan M. | 1e | 4 |
| Engineer | Malcom S. | 1e | 1 |
| Artist | Tylar S. | 2w | 2 |
| Artist | Sherman D. | 2w | 8 |
| Artist | Jakob J. | 2w | 6 |
| Artist | Lillia A. | 2w | 7 |
| Artist | Brandon J. | 2w | 7 |
| Manager | Scott K. | 1e | 9 |
| Manager | Shirlee M. | 1e | 3 |
| Manager | Daria O. | 2w | 6 |
| Engineer | Yancy I. | null | 0 |
| Artist | Oliver P. | null | 0 |
Table: Buildings (Read-Only)
| Building_name | Capacity |
|---|---|
| 1e | 24 |
| 1w | 32 |
| 2e | 16 |
| 2w | 20 |
-
找到雇员里还没有分配办公室的(列出名字和角色就可以)
SELECT Name,Role FROM Employees WHERE Building is null;自己的:SELECT Name, Role FROM Employees WHERE Building is null;
-
找到还没有雇员的办公室
SELECT Building_name FROM Buildings LEFT JOIN Employees on Buildings.Building_name = Employees.Building WHERE Name is null;自己的:SELECT Building_name FROM Buildings LEFT JOIN Employees On Buildings.Building_name = Employees.Building WHERE Building is null;
总结:
先不要想着一步到位,SELECT的部分可以先用*,等结果出来之后再去选列
SQL Lesson 9: 在查询中使用表达式
Table: Movies (Read-Only)
| Id | Title | Director | Year | Length_minutes |
|---|---|---|---|---|
| 1 | Toy Story | John Lasseter | 1995 | 81 |
| 2 | A Bug’s Life | John Lasseter | 1998 | 95 |
| 3 | Toy Story 2 | John Lasseter | 1999 | 93 |
| 4 | Monsters, Inc. | Pete Docter | 2001 | 92 |
| 5 | Finding Nemo | Finding Nemo | 2003 | 107 |
| 6 | The Incredibles | Brad Bird | 2004 | 116 |
| 7 | Cars | John Lasseter | 2006 | 117 |
| 8 | Ratatouille | Brad Bird | 2007 | 115 |
| 9 | WALL-E | Andrew Stanton | 2008 | 104 |
| 10 | Up | Pete Docter | 2009 | 101 |
| 11 | Toy Story 3 | Lee Unkrich | 2010 | 103 |
| 12 | Cars 2 | John Lasseter | 2011 | 120 |
| 13 | Brave | Brenda Chapman | 2012 | 102 |
| 14 | Monsters University | Dan Scanlon | 2013 | 110 |
Table: Boxoffice (Read-Only)
| Movie_id | Rating | Domestic_sales | International_sales |
|---|---|---|---|
| 5 | 8.2 | 380843261 | 555900000 |
| 14 | 7.4 | 268492764 | 475066843 |
| 8 | 8 | 206445654 | 417277164 |
| 12 | 6.4 | 191452396 | 368400000 |
| 3 | 7.9 | 245852179 | 239163000 |
| 6 | 8 | 261441092 | 370001000 |
| 9 | 8.5 | 223808164 | 297503696 |
| 11 | 8.4 | 415004880 | 648167031 |
| 1 | 8.3 | 191796233 | 170162503 |
| 7 | 7.2 | 244082982 | 217900167 |
| 10 | 8.3 | 293004164 | 438338580 |
| 4 | 8.1 | 289916256 | 272900000 |
| 2 | 7.2 | 162798565 | 200600000 |
| 13 | 7.2 | 237283207 | 301700000 |
- 列出所有的电影Id,名字和销售总额(以百万美元为单位计算)
SELECT Id,Title,(Domestic_sales+International_sales)/1000000 as “销售总额” FROM Movies LEFT JOIN Boxoffice on Movies.Id = Boxoffice.Movie_id; - 列出所有的电影Id,名字和市场指数(Rating的10倍为市场指数)
SELECT Id,Title,Rating*10 as “市场指数” FROM Movies LEFT JOIN Boxoffice on Movies.Id = Boxoffice.Movie_id; - 列出所有偶数年份的电影,需要电影Id,名字和年份
SELECT Id,Title,Year from Movies LEFT JOIN Boxoffice on Movies.Id = Boxoffice.Movie_id WHERE Year%2=0; - John Lasseter导演的每部电影每分钟值多少钱,告诉我最高的3个电影名和价值就可以
SELECT Title,(Domestic_sales+International_sales)/Length_minutes as “价值” from Movies LEFT JOIN Boxoffice on Movies.Id = Boxoffice.Movie_id WHERE Director = “Jhon Lasseter” ORDER BY “价值” LIMIT 3; - 电影名最长的3部电影和他们的总销量是多少
SELECT,length(Title) as title_len,Title,(Domestic_sales + International_sales) as “总销量” from Movies LEFT JOIN Boxoffice on Movies.Id = Boxoffice.Movie_id ORDER BY title_len DESC LIMIT 3;
自己的答案:
- SELECT Id, Title, (Domestic_sales + International_sales)/1000000 as ‘销售总额’ FROM Movies LEFT JOIN Boxoffice On Movies.Id = Boxoffice.movie_id;
- SELECT Id, Title,(Rating * 10) AS ‘市场指数’ FROM Movies LEFT JOIN Boxoffice On Movies.Id = Boxoffice.Movie_id;
- SELECT Id, Title, Year FROM Movies WHERE Year&1 = 0;
- SELECT Title, (Domestic_sales + International_sales)/Length_minutes AS ‘价值’ FROM Movies LEFT JOIN Boxoffice On Movies.Id = Boxoffice.Movie_id WHERE Director = ‘John Lasseter’ ORDER BY 价值 DESC LIMIT 3;
总结:
mysql判断奇数偶数,效率按顺序
– 按位与
select * from cinema WHERE Id&1;
– Id先除以2然后乘2 如果与原来的相等就是偶数
select * from cinema WHERE Id=(Id>>1)<<1;
– Id计算
select * from cinema WHERE Id%2 = 1;
select * from cinema WHERE Id%2 = 0;
– 与上面的一样
select * from cinema WHERE mod(Id, 2) = 1;
select * from cinema WHERE mod(Id, 2) = 0;
– -1的奇数次方和偶数次方
select * from cinema WHERE POWER(-1, Id) = -1;
select * from cinema WHERE POWER(-1, Id) = 1;
– 正则匹配最后一位
select * from cinema WHERE Id regexp '[13579]$';
select * from cinema WHERE Id regexp '[02468]$';
SQL Lesson 10: 在查询中进行统计I (Pt. 1)
Table(表): Employees
| Role | Name | Building | Years_employed |
|---|---|---|---|
| Engineer | Becky A. | 1e | 4 |
| Engineer | Dan B. | 1e | 2 |
| Engineer | Sharon F. | 1e | 6 |
| Engineer | Dan M. | 1e | 4 |
| Engineer | Malcom S. | 1e | 1 |
| Artist | Tylar S. | 2w | 2 |
| Artist | Sherman D. | 2w | 8 |
| Artist | Jakob J. | 2w | 6 |
| Artist | Lillia A. | 2w | 7 |
| Artist | Brandon J. | 2w | 7 |
| Manager | Scott K. | 1e | 9 |
| Manager | Shirlee M. | 1e | 3 |
| Manager | Daria O. | 2w | 6 |
| Engineer | Yancy I. | null | 0 |
| Artist | Oliver P. | null | 0 |
-
找出就职年份最高的雇员(列出雇员名字+年份)
SELECT Name,MAX(Years_employed) FROM Employees;自己写的:
SELECT Name, Years_employed FROM Employees ORDER BY Years_employed DESC LIMIT 1;
-
按角色(Role)统计一下每个角色的平均就职年份
SELECT Role, AVG(Years_employed) FROM Employees GROUP BY Role; -
按办公室名字总计一下就职年份总和
SELECT Building, SUM(Years_employed) FROM Employees GROUP BY Building; -
每栋办公室按人数排名,不要统计无办公室的雇员
SELECT Building, Count(Name) FROM Employees WHERE Building is not NULL GROUP BY Building;SELECT Building, Count(Name) FROM Employees GROUP BY Building HAVING Building is not NULL;
Note:Count(Name)换成Count(*)也可以
-
就职1,3,5,7年的人分别占总人数的百分比率是多少(给出年份和比率"50%" 记为 50)
SELECT Years_employed, Count() * 100/(select count() FROM Employees) AS Rating FROM Employees WHERE Years_employed in (1,3,5,7) GROUP BY Years_employed;
总结:
对全部结果数据做统计的SQL格式
SELECT AGG_FUNC(\column_or_expression\) AS aggregate_description, …
FROM mytable
WHERE constraint_expression;
下面介绍几个常用统计函数:
| Function | Description |
|---|---|
| COUNT(*), COUNT(column) | 计数!COUNT(*) 统计数据行数,COUNT(column) 统计column非NULL的行数. |
| MIN(column) | 找column最小的一行. |
| **MAX(**column) | 找column最大的一行. |
| **AVG(**column) | 对column所有行取平均值. |
| SUM(column) | 对column所有行求和. |
注意:
GROUP BY 之后在SELECT 后使用统计函数是对分组后的每组做这些统计运算
SQL Lesson 11: 在查询中进行统计II (Pt. 2)
Table(表): Employees
| Role | Name | Building | Years_employed |
|---|---|---|---|
| Engineer | Becky A. | 1e | 4 |
| Engineer | Dan B. | 1e | 2 |
| Engineer | Sharon F. | 1e | 6 |
| Engineer | Dan M. | 1e | 4 |
| Engineer | Malcom S. | 1e | 1 |
| Artist | Tylar S. | 2w | 2 |
| Artist | Sherman D. | 2w | 8 |
| Artist | Jakob J. | 2w | 6 |
| Artist | Lillia A. | 2w | 7 |
| Artist | Brandon J. | 2w | 7 |
| Manager | Scott K. | 1e | 9 |
| Manager | Shirlee M. | 1e | 3 |
| Manager | Daria O. | 2w | 6 |
| Engineer | Yancy I. | null | 0 |
| Artist | Oliver P. | null | 0 |
-
统计一下Artist角色的雇员数量
SELECT Count(*) FROM Employees WHERE Role = ‘Artist’; -
按角色统计一下每个角色的雇员数量
SELECT Role, Count(*) FROM Employees GROUP BY Role; -
算出Engineer角色的就职年份总计
SELECT SUM(Years_employed) FROM Employees WHERE Role = ‘Engineer’;题目要求用分组,但我觉得速度应该会变慢
SELECT SUM(Years_employed) FROM Employees GROUP BY Role HAVING Role = ‘Engineer’;
-
每栋办公室按人数排名,不要统计无办公室的雇员
SELECT count(*) as count,Role,building is not null as bn FROM employees group by Role,bn; -
就职1,3,5,7年的人分别占总人数的百分比率是多少(给出年份和比率"50%" 记为 50)
SELECT Role,Years_employed/3 as year_3,count(*) as count FROM employees group by Role,year_3 order by count desc;
总结:
GROUP BY其实是可以group by 多列的,相当于对遍历这些列的所有情况
比如说col1有0,1两种情况,col2有0,1两种情况
那如果group by col1,col2,那就是按(0,0),(0,1),(1,0),(1,1)四种情况来分
| col1 | col2 | result |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
SQL Lesson 12: 查询执行顺序
Table: Movies (Read-Only)
| Id | Title | Director | Year | Length_minutes |
|---|---|---|---|---|
| 1 | Toy Story | John Lasseter | 1995 | 81 |
| 2 | A Bug’s Life | John Lasseter | 1998 | 95 |
| 3 | Toy Story 2 | John Lasseter | 1999 | 93 |
| 4 | Monsters, Inc. | Pete Docter | 2001 | 92 |
| 5 | Finding Nemo | Finding Nemo | 2003 | 107 |
| 6 | The Incredibles | Brad Bird | 2004 | 116 |
| 7 | Cars | John Lasseter | 2006 | 117 |
| 8 | Ratatouille | Brad Bird | 2007 | 115 |
| 9 | WALL-E | Andrew Stanton | 2008 | 104 |
| 10 | Up | Pete Docter | 2009 | 101 |
| 11 | Toy Story 3 | Lee Unkrich | 2010 | 103 |
| 12 | Cars 2 | John Lasseter | 2011 | 120 |
| 13 | Brave | Brenda Chapman | 2012 | 102 |
| 14 | Monsters University | Dan Scanlon | 2013 | 110 |
Table: Boxoffice (Read-Only)
| Movie_id | Rating | Domestic_sales | International_sales |
|---|---|---|---|
| 5 | 8.2 | 380843261 | 555900000 |
| 14 | 7.4 | 268492764 | 475066843 |
| 8 | 8 | 206445654 | 417277164 |
| 12 | 6.4 | 191452396 | 368400000 |
| 3 | 7.9 | 245852179 | 239163000 |
| 6 | 8 | 261441092 | 370001000 |
| 9 | 8.5 | 223808164 | 297503696 |
| 11 | 8.4 | 415004880 | 648167031 |
| 1 | 8.3 | 191796233 | 170162503 |
| 7 | 7.2 | 244082982 | 217900167 |
| 10 | 8.3 | 293004164 | 438338580 |
| 4 | 8.1 | 289916256 | 272900000 |
| 2 | 7.2 | 162798565 | 200600000 |
| 13 | 7.2 | 237283207 | 301700000 |
-
统计出每一个导演的电影数量(列出导演名字和数量)
SELECT Director,Count(*) FROM Movies Group by Director; -
统计一下每个导演的销售总额(列出导演名字和销售总额)
SELECT Director, SUM(Domestic_sales+International_sales) AS ‘销售总额’ FROM Movies Left Join Boxoffice On Movies.Id = Boxoffice.Movie_id GROUP BY Director; -
按导演分组计算销售总额,求出平均销售额冠军(统计结果过滤掉只有单部电影的导演,列出导演名,总销量,电影数量,平均销量)
SELECT director,sum(Domestic_sales + International_sales) AS sum_sales,count(director),sum(Domestic_sales + International_sales)/count(director) AS avg_sales FROM movies LEFT JOIN boxoffice ON movies.id = boxoffice.movie_id group by director having count(director) > 1 ORDER BY avg_sales DESC LIMIT 1–SELECT Director, SUM(Domestic_sales+International_sales) AS ‘总销量’, Count() AS ‘电影数量’, SUM(Domestic_sales+International_sales)/Count() AS ‘平均销量’ FROM Movies Left Join Boxoffice On Movies.Id = Boxoffice.Movie_id GROUP BY Director HAVING Count() > 1 ORDER BY SUM(Domestic_sales+International_sales)/Count() DESC LIMIT 1;
note:用中文名的话不可以直接用AS的列名来操作
-
找出每部电影和单部电影销售冠军之间的销售差,列出电影名,销售额差额
select title ,(select max(international_sales+domestic_sales) from boxoffice)-(international_sales+domestic_sales) AS Margin from movies left join boxoffice on movies.id=boxoffice.movie_id;SELECT Title, ((SELECT (Domestic_sales + International_sales) FROM Movies Left Join Boxoffice On Movies.Id = Boxoffice.Movie_id ORDER BY (Domestic_sales + International_sales) DESC LIMIT 1 ) - (Domestic_sales + International_sales))AS Rest FROM movies LEFT JOIN boxoffice ON movies.id = boxoffice.movie_id;
总结:
按这个顺序来写,注意顺序不能颠倒,否则会报错!
SELECT DISTINCT column, AGG_FUNC(*column_or_expression*),
… FROM mytable
JOIN another_table ON mytable.column = another_table.column
WHERE constraint_expression
GROUP BY column
AVING constraint_expression
ORDER BY *column* ASC/DESC
LIMIT count OFFSET COUNT;