Kube-prometheus(k8s-1.14版本,离线安装)-prometheus和grafana挂载nfs-mysql监控
前提:部署kube-prometheus之前单独在k8s集群上部署过prometheus和grafana,不过因为监测指标过多,导致prometheus总是被oomkill掉,调大使用cpu和内存也不行,而kube-prometheus本身就是高可用prometheus。两者的不同之处还在于添加检测对象上,prometheus需要修改配置文件,然后重启,kube-prometheus需要根据监测服务创建servicemonitor之后自动检测到并添加。
kub-prometheus介绍
kube-prometheus 是一整套监控解决方案,它使用 Prometheus 采集集群指标,Grafana 做展示,包含如下组件:
| 组件 | 功能 |
|---|---|
| The Prometheus Operator | 以非常简单的在kubernetes集群中部署Prometheus服务,并且提供对kubernetes集群的监控,并且可以配置和管理prometheus |
| Highly available Prometheus | 高可用监控工具 |
| Highly available Alertmanager | 高可用告警工具,用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组等,是一款前卫的告警通知系统。 |
| node-exporter | 用于采集服务器层面的运行指标,包括机器的loadavg、filesystem、meminfo等基础监控,类似于传统主机监控维度的zabbix-agent |
| grafana | 用于大规模指标数据的可视化展现,是网络架构和应用分析中最流行的时序数据展示工具 |
| kube-state-metrics | 收集kubernetes集群内资源对象数据,制定告警规则。 |
| Prometheus Adapter for /Kubernetes Metrics APIs | 轮询Kubernetes API,并将Kubernetes的结构化信息转换为metrics |
其中 k8s-prometheus-adapter 使用 Prometheus 实现了 metrics.k8s.io 和 custom.metrics.k8s.io API,
所以不需要再部署 metrics-server( metrics-server 通过 kube-apiserver 发现所有节点,然后调用 kubelet APIs(通过 https 接口)获得各节点(Node)和 Pod 的 CPU、Memory 等资源使用情况。)
部署之后可以直接使用kubectl top命令


kube-prometheus安装准备
Kube-Prometheus项目地址:
https://github.com/coreos/kube-prometheus
根据k8s版本下载kube-prometheus版本

使用k8s为1.14版本,所以使用release-0.3
下载本地进入目录kube-prometheus/manifests,执行以下命令查看镜像版本:
grep -riE 'quay.io|k8s.gcr|grafana/' *
prometheus和alertmanager可以cat yaml文件查看具体版本
然后可以写个脚本下载所有镜像以及打包镜像
kube-prometheus离线安装
将kube-prometheus-release-0.3zip文件和镜像压缩包以及传到k8s服务器主节点上,可以将镜像上传到内网镜像仓库或者用ansible或者手动将镜像传到k8s各个机器上解压,
此处注意服务器的架构和下载镜像的架构是否一致,amd和ard架构的镜像是不通用的,否则pod启动会报错
上传之后就可以执行yaml文件
首先我们修改一下alertmanager、grafana、和kube-prometheus的service可以通过集群ip加端口访问
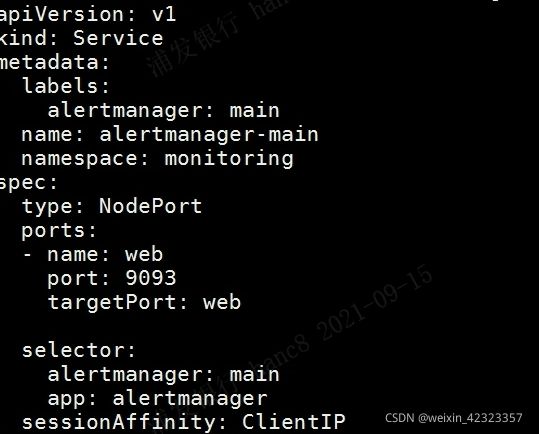
同理。修改prometheus-service.yaml,grafana-service.yaml
可以指定nodePort,也可以不指定。
然后cd kube-prometheus-release-0.3依次执行
kubectl apply -f ./manifests/setup
kubectl apply -f ./manafests
查看暴露的端口

访问grafana
初始账号密码admin/admin
自带一些k8s指标的面板

访问prometheus
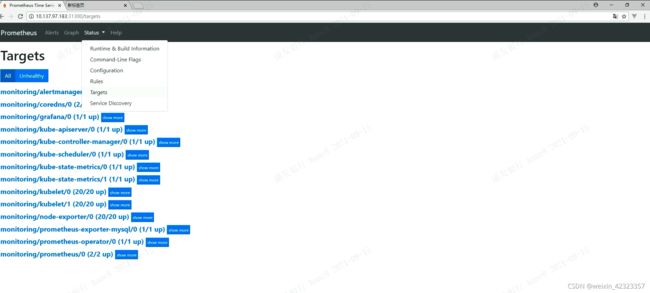
创建之后可能会发现kube-scheduler和kube-controller-manager没有监控,是因为这两者没有暴露service,所以prometheus监控不到
修改步骤
1.cd /etc/kubernetes/manifests
分别修改kube-controller-manager.yaml和Kube-scheduler.yaml,修改之后不用手动更新,k8s会自动更新配置
bind-address删掉
address值为0.0.0.0
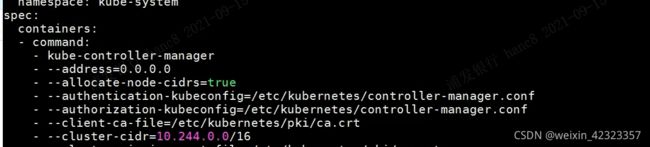
然后创建两者的service,endpoint yaml,apply之后,等待prometheus自动监测就行


然后就可以监测到scheduler和controller
prometheus和grafana挂载nfs
peometheus和grafana默认是使用emptydir存储数据,每次pod重启之后数据会丢失
grafana类型为deployment,所以可以直接创建pv和pvc
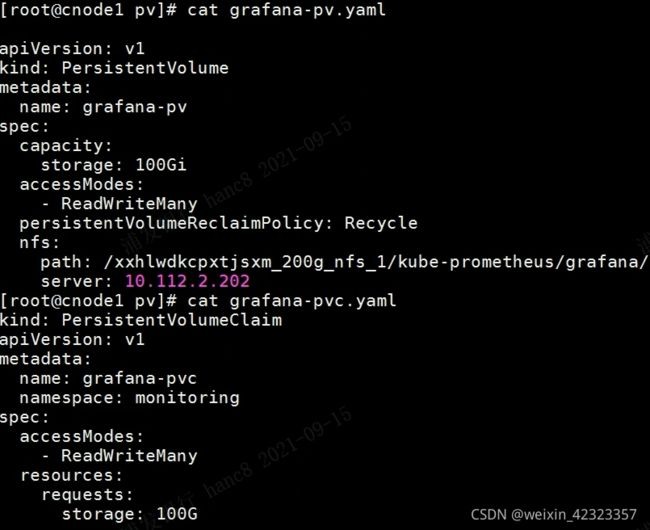
vim grafana-deployment.yaml
修改name为grafana-storage的volume
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
prometheus类型为statefulset,所有需要用模板创建pvc,这里不详细贴出storageclass的创建。
直接修改prometheus-peometheus.yaml文件
在最后加上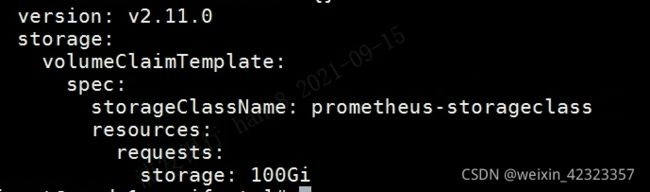
修改之后重新apply prometheus和grafana的yaml文件即可
grafana修改邮件配置以及mysql纳入prometheus监控
grafana配置
进入grafanapod查看,grafana配置文件grafana.ini在/etc/grafana目录下,只需要将配置文件挂载进入即可。
首先在任意目录下copy一份原始grafana.ini文件
修改部分信息
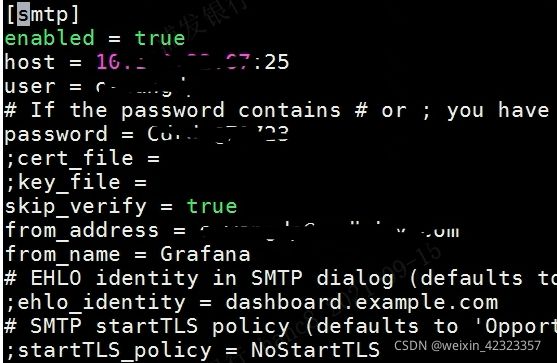
修改之后,根据此文件创建configmap
kubectl create configmap grafana-ini --from-file=./grafana.ini
vi grafana-deployment.yaml
volumeMounts:
- mountPath: /etc/grafana. #容器内目录
name: grafana-ini
volumes:
- name: grafana-ini
configMap:
name: grafana-ini #将configmp中的grafana.ini挂载到该目录
重启grafana-deployment.yaml
mysql监控
mysql是在k8s集群之外的服务器上搭建,需要安装mysql-exporter,安装过程省略,只记录在prometheus上的操作
首先需要创建一个mysql的service和endpoint,endpoint指向mysql所在的服务器

然后创建一个servicemonitor供prometheus探测到该service
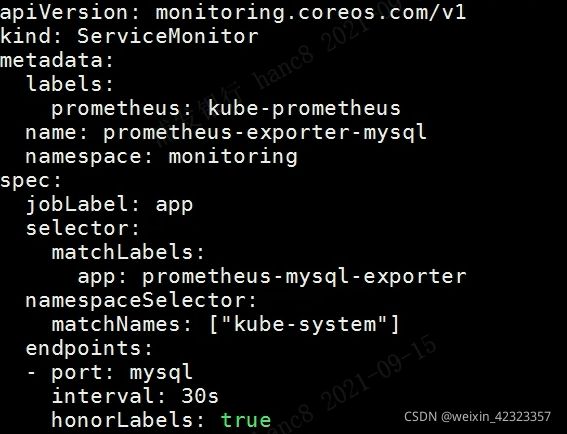
namespqceSelector 需要保证与service所在namespace一致,interval为探测时间,
参考博客:
https://www.cnblogs.com/zhanglianghhh/p/14294615.html
https://soulchild.cn/2623.html