Python基于深度学习yolov5的扑克牌识别
Python基于深度学习yolov5的扑克牌识别(附带源码)

源程序来源于本人参与开发的一个网络扑克牌小游戏的图像识别、AI分析,AI出牌的小项目,做完后和大家分享一下扑克牌自动识别模块制作的过程。
网上有很多识别扑克牌的教程,要么是卖程序的,要么就是只能识别垂直拍摄的牌。我们在实际应用中都需要很准确的识别出扑克牌,不能很大的差错。类似于
https://blog.csdn.net/mao_hui_fei/article/details/119389189
做的我加他的闲鱼号问了下技术细节发现他采用的数据集只有90°垂直拍摄标注的数据集
https://blog.csdn.net/weixin_41082095/article/details/120307644
同类型的博主做的也是针对垂直拍摄的虚拟扑克进行识别,具有很大程度的局限性
1.虚拟环境的搭建
首先第一步是搭建起Python和其他所需的虚拟环境,具体可细分为以下几个步骤:
1.Anaconda的安装,虚拟环境创建及配置
以前作为萌新的时候曾傻乎乎的直接百度装Python、OpenCV,不仅不好安装相关依赖,以后的库也不好装,所以建议参考下面的教程装
https://zhuanlan.zhihu.com/p/423809879
2.下载安装IDE:Pycharm
PyCharm是一款Python IDE,其带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如, 调试、语法高亮、Project管理、代码跳转、智能提示
https://blog.csdn.net/qq_44809707/article/details/122501118
3.搭建yolov5所需的虚拟环境以及硬件支持
https://blog.csdn.net/qq_44697805/article/details/107702939
按照上面的链接搭建就可以,需要注意的几点是:
一.如果没有独立显卡的朋友建议安装CPU版本的Pytorch、如果是nvdia显卡的朋友又要细分一下:
1)如果是30系或者是A100的N卡,因为是最新的安培架构,所以CUDA只能装11.0以上的版本,建议和作者选择一样的CUDA11.1。
2)如果是其他系列的N卡,建议装CUDA10.2版本。
二.Pytorch版本的问题,这里我直接放两个安装链接,涵盖了绝大部分情况的需求,对号入座输入指令下载安装即可
1)CPU版本的Pytorch:
pip install -f https://download.pytorch.org/whl/cu110/torch_stable.html torch==1.7.0 torchvision==0.8.0如果安装速度奇慢无比,或者中途断掉,可以换用以下国内的清华源:
pip install torch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 -i https://pypi.tuna.tsinghua.edu.cn/simple2)CUDA10.2版本GPU的Pytorch:
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=10.2 -c pytorch2)CUDA11.1版本GPU的Pytorch:
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.1 -c pytorch2.数据集的采集
因此如何收集一个鲁棒性强,包含各种复杂情况的数据集成为一个很棘手的问题,我曾经尝试过闲鱼号的博主,发现他的数据集售价高昂(流下了贫困的泪水┭┮﹏┭┮),没事,咱们自己收集数据集,那么首要的一步就是编写一个爬虫demo,废话不多说,直接贴代码,run运行就能用(ヾ(✿゚▽゚)ノ)
# -*- coding: utf-8 -*-
import re
import requests
from urllib import error
from bs4 import BeautifulSoup
import os
num = 0
numPicture = 0
file = ''
List = []
def Find(url, A):
global List
print('正在检测图片总数,请稍等.....')
t = 0
i = 1
s = 0
while t < 1000:
Url = url + str(t)
try:
# 这里搞了下
Result = A.get(Url, timeout=7, allow_redirects=False)
except BaseException:
t = t + 60
continue
else:
result = Result.text
pic_url = re.findall('"objURL":"(.*?)",', result, re.S) # 先利用正则表达式找到图片url
s += len(pic_url)
if len(pic_url) == 0:
break
else:
List.append(pic_url)
t = t + 60
return s
def recommend(url):
Re = []
try:
html = requests.get(url, allow_redirects=False)
except error.HTTPError as e:
return
else:
html.encoding = 'utf-8'
bsObj = BeautifulSoup(html.text, 'html.parser')
div = bsObj.find('div', id='topRS')
if div is not None:
listA = div.findAll('a')
for i in listA:
if i is not None:
Re.append(i.get_text())
return Re
def dowmloadPicture(html, keyword):
global num
# t =0
pic_url = re.findall('"objURL":"(.*?)",', html, re.S) # 先利用正则表达式找到图片url
print('找到关键词:' + keyword + '的图片,即将开始下载图片...')
for each in pic_url:
print('正在下载第' + str(num + 1) + '张图片,图片地址:' + str(each))
try:
if each is not None:
pic = requests.get(each, timeout=7)
else:
continue
except BaseException:
print('错误,当前图片无法下载')
continue
else:
string = file + r'\\' + keyword + '_' + str(num) + '.jpg'
fp = open(string, 'wb')
fp.write(pic.content)
fp.close()
num += 1
if num >= numPicture:
return
if __name__ == '__main__': # 主函数入口
headers = {
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Upgrade-Insecure-Requests': '1'
}
A = requests.Session()
A.headers = headers
###############################
tm = int(input('请输入每类图片的下载数量 '))
numPicture = tm
line_list = []
with open('./name.txt', encoding='utf-8') as file:
line_list = [k.strip() for k in file.readlines()] # 用 strip()移除末尾的空格
for word in line_list:
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&pn='
tot = Find(url, A)
Recommend = recommend(url) # 记录相关推荐
print('经过检测%s类图片共有%d张' % (word, tot))
file = word + '文件'
y = os.path.exists(file)
if y == 1:
print('该文件已存在,请重新输入')
file = word + '文件夹2'
os.mkdir(file)
else:
os.mkdir(file)
t = 0
tmp = url
while t < numPicture:
try:
url = tmp + str(t)
# result = requests.get(url, timeout=10)
# 这里搞了下
result = A.get(url, timeout=10, allow_redirects=False)
print(url)
except error.HTTPError as e:
print('网络错误,请调整网络后重试')
t = t + 60
else:
dowmloadPicture(result.text, word)
t = t + 60
numPicture = numPicture + tm
print('爬图完毕')
因为是百度图片的url爬取的,所以良莠不齐,咱们挑选效果好的进入下一步标注环节
3.数据集的标注
我们下载一个通用的图像标注工具labelimg,具体的安装使用教程可以参考
https://blog.csdn.net/knighthood2001/article/details/125883343
需要注意的一点就是,因为我们选择的目标检测算法为yolov5,所以在标注前记得将labelimg标注的格式改为YOLO,不然标注完了要么得找格式转换代码,要么得用labelimg每张图切换一下模式(手点断o(╥﹏╥)o)
最终标注好的数据集如下图的样子,标注好的数据集直接文章底部获取,请叫我活雷锋!
4.数据集格式的处理
由于我们标注的时候并不是每张图都标注,只挑选认为效果较好的图像进行标注,所以并非每张图都会生成对应的label(txt),而最终yolo训练所需要的数据集必须是严格的图像——同名的label,一一对应,这就给我们后期处理标注的数据集带来了很大的工作量,稍有出错都会报错,所以我们编写了一个简单的demo来处理labelimg标注完的文件夹,将其中存在一一对应关系的图片挑选出来,并且自动划分为所需比例的训练集和验证集,直接生成yolov5所需格式的训练数据集,废话不多说,直接贴代码
# -*- coding: utf-8 -*-
import os
import shutil
############################designed for yolov5 train#############################
path = './data_input' #存放数据集文件夹,包含images(jpg&png)labels(txt&xml)
result = os.listdir(path)
train_file = './data_output' #更改为你的数据集名称
ratio = 2/3 #训练集占数据集的比例
if not os.path.exists(train_file):
os.mkdir(train_file)
if not os.path.exists(train_file + '/train'):
os.mkdir(train_file + '/train')
if not os.path.exists(train_file + '/train/images'):
os.mkdir(train_file + '/train/images')
if not os.path.exists(train_file + '/train/labels'):
os.mkdir(train_file + '/train/labels')
if not os.path.exists(train_file + '/valid'):
os.mkdir(train_file + '/valid')
if not os.path.exists(train_file + '/valid/images'):
os.mkdir(train_file + '/valid/images')
if not os.path.exists(train_file + '/valid/labels'):
os.mkdir(train_file + '/valid/labels')
if not os.path.exists(train_file + '/test'):
os.mkdir(train_file + '/test')
if not os.path.exists(train_file + '/test/images'):
os.mkdir(train_file + '/test/images')
if not os.path.exists(train_file + '/test/labels'):
os.mkdir(train_file + '/test/labels')
jpg,png,txt,xml =[],[],[],[]
try:
for i in result:
if i[-3:] == 'jpg':
jpg.append(i[:-4])
if i[-3:] == 'png':
png.append(i[:-4])
if i[-3:] == 'txt':
txt.append(i[:-4])
if i[-3:] == 'xml':
xml.append(i[:-4])
if len(txt) >= len(xml):
xml = []
else:
txt = []
if len(jpg) >= len(png):
png = []
else:
jpg = []
except:
print(path + '是个空文件夹')
if jpg != []:
train_num = 0
for i in jpg:
train_num += 1
if (i in txt or i in xml) and train_num <= int(len(jpg)*ratio):
shutil.copyfile(path + '/' + i + '.jpg', train_file + '/train/images/' + i + '.jpg')
try:
shutil.copyfile(path + '/' + i + '.txt', train_file + '/train/labels/' + i + '.txt')
except:
pass
try:
shutil.copyfile(path + '/' + i + '.xml', train_file + '/train/labels/' + i + '.xml')
except:
pass
if (i in txt or i in xml) and train_num > int(len(jpg)*ratio):
shutil.copyfile(path + '/' + i + '.jpg', train_file + '/valid/images/' + i + '.jpg')
try:
shutil.copyfile(path + '/' + i + '.txt', train_file + '/valid/labels/' + i + '.txt')
shutil.copyfile(path + '/' + i + '.txt', train_file + '/test/labels/' + i + '.txt')
except:
pass
try:
shutil.copyfile(path + '/' + i + '.xml', train_file + '/valid/labels/' + i + '.xml')
shutil.copyfile(path + '/' + i + '.xml', train_file + '/test/labels/' + i + '.xml')
except:
pass
if png != []:
train_num = 0
for i in png:
train_num += 1
if (i in txt or i in xml) and train_num <= int(len(png)*ratio):
shutil.copyfile(path + '/' + i + '.png', train_file + '/train/images/' + i + '.png')
try:
shutil.copyfile(path + '/' + i + '.txt', train_file + '/train/labels/' + i + '.txt')
except:
pass
try:
shutil.copyfile(path + '/' + i + '.xml', train_file + '/train/labels/' + i + '.xml')
except:
pass
if (i in txt or i in xml) and train_num > int(len(png)*ratio):
shutil.copyfile(path + '/' + i + '.png', train_file + '/valid/images/' + i + '.png')
try:
shutil.copyfile(path + '/' + i + '.txt', train_file + '/valid/labels/' + i + '.txt')
shutil.copyfile(path + '/' + i + '.txt', train_file + '/test/labels/' + i + '.txt')
except:
pass
try:
shutil.copyfile(path + '/' + i + '.xml', train_file + '/valid/labels/' + i + '.xml')
shutil.copyfile(path + '/' + i + '.xml', train_file + '/test/labels/' + i + '.xml')
except:
pass
最终处理好的数据集如下图所示(终于完成啦!)

每个文件夹内这样格式

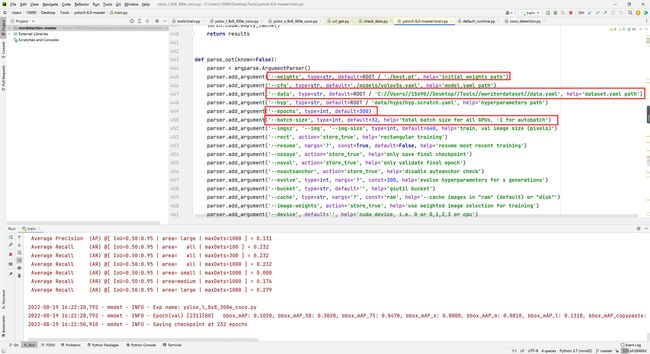
5.模型的训练
打开yolov5代码根目录的train.py,修改--data数据集的位置,--weights训练权重保存的位置,--epochs训练的轮次,--batch-size建议显存小的小伙伴设置为1。然后右键RUN就可以开始训练啦!
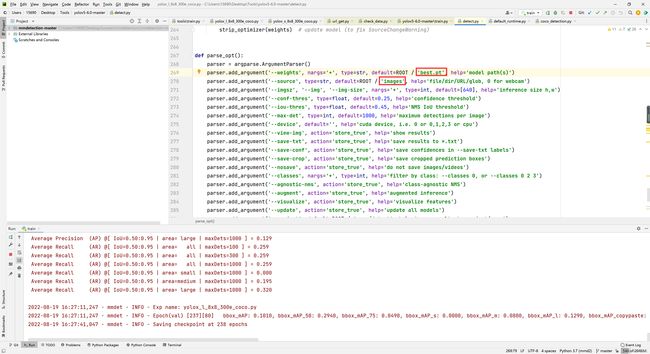
6.扑克牌图像/视频的预测
打开yolov5代码根目录的detect.py,修改--weights训练权重保存的位置,--source为你要检测的扑克牌图像或者视频的路径,注意如果不在根目录下记得去掉前面的ROOT,然后右键RUN就可以开始检测啦!
7.扑克牌检测效果展示



完美!\(^o^)/
附上数据集链接:https://download.csdn.net/download/cheng2333333/86405295
完整源码整理完后上传