YOLO_v1讲解
文章目录
- 一:YOLO_v1的出现
- 二:网络模型
- 三:训练阶段
-
- step1:训练数据的制作
- step2:损失函数
- 四:测试阶段
-
- step1:输入原图
- step2:计算每个bbox的类别得分
- 五:YOLO_v1的不足
一:YOLO_v1的出现
YOLO_v1的出现,打破了Faster R-CNN的一统图像检测江山的格局,首次提出了one-stage的图像检测模型,真正实现了end-to-end,其具体优势如下:
- 快,非常的快,基础版YOLO每秒可以处理45帧;快速版能达到155帧每秒,绝对是开挂的速度
- 准确率高,map达到63.4 map
- 易优化,整体上是一个单阶段网络,很容易进行端到端的优化
二:网络模型
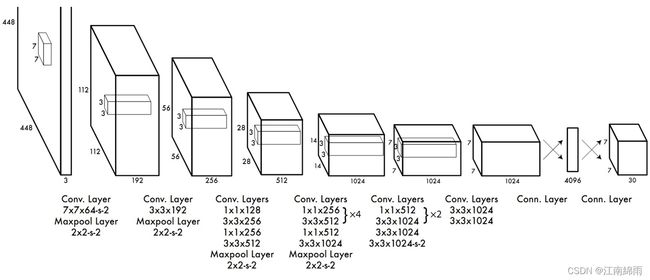
通过上面结构图,我们可以很直接的看出yolov1的网络结构,用了一系列的卷积层、最大池化下载样层以及全连接层,在这里说明一下全连接层。
通过第一个Conn.Layer时,需要进行三个处理:①transpose处理。不一定要进行②flateen。因为要和全连接层连接,所以要进行展平处理。③fc(4096)。通过一个节点个数为4096的全连接层进行连接。此时得到一个4096维的向量。
通过第二个Conn.Layer时,需要进行两个处理:①通过一个节点个数为1470的全连接层。因为要得到一个7×7×30的特征矩阵,所以需要1470。②进行reshape处理。把向量调整为7×7×30的矩阵。
可见,YOLOv1的网络结构还是比较简单的,因为它的关键部分在于它的逻辑,就是它的输入输出的映射和损失函数设计,下面我将从训练阶段和测试阶段进行剖析:
三:训练阶段
step1:训练数据的制作

标签为007732.jpg 341 217 487 375 8 114 209 183 298 8 237 110 320 176 19,其中8表示chair,19表示tvmonitor。
下面演示如何将这些坐标和类别信息转化为YOLO的target张量(7×7×30):
首先,7×7好理解,就是对一张图片,切成了49个cell,我们对其中一个cell的30个元素进行分析,如下图:

如果该cell中有物体(可能有多个物体),那么x1,y1,w1,h1=x2,y2,w2,h2=cell中程序遍历到的最后一个物体的坐标和长宽,confidence1=confidence2=1,类别就是独热编码。
如果该cell中没有物体,那么30个元素都是0。
def encode(self, boxes, labels):
""" Encode box coordinates and class labels as one target tensor.
Args:
boxes: (tensor) [[x1, y1, x2, y2]_obj1, ...], normalized from 0.0 to 1.0 w.r.t. image width/height.
labels: (tensor) [c_obj1, c_obj2, ...]
Returns:
An encoded tensor sized [S, S, 5 x B + C], 5=(x, y, w, h, conf)
"""
S, B, C = self.S, self.B, self.C
N = 5 * B + C
target = torch.zeros(S, S, N)
cell_size = 1.0 / float(S)
boxes_wh = boxes[:, 2:] - boxes[:, :2] # width and height for each box, [n, 2]
boxes_xy = (boxes[:, 2:] + boxes[:, :2]) / 2.0 # center x & y for each box, [n, 2]
for b in range(boxes.size(0)):
xy, wh, label = boxes_xy[b], boxes_wh[b], int(labels[b])
ij = (xy / cell_size).ceil() - 1.0
i, j = int(ij[0]), int(ij[1]) # y & x index which represents its location on the grid.
x0y0 = ij * cell_size # x & y of the cell left-top corner.
xy_normalized = (xy - x0y0) / cell_size # x & y of the box on the cell, normalized from 0.0 to 1.0.
# TBM, remove redundant dimensions from target tensor.
# To remove these, loss implementation also has to be modified.
for k in range(B):
s = 5 * k
target[j, i, s :s+2] = xy_normalized
target[j, i, s+2:s+4] = wh
target[j, i, s+4 ] = 1.0
target[j, i, 5*B + label] = 1.0
return target
target = torch.zeros(S, S, N) #就是YOLO的输出格式;其中S=7,N=5 * B + C=30
以前面的那张007732.jpg为例,其中右下角的白色椅子的编码结果(target[5, 5])为:
tensor([0.7960, 0.5253, 0.2920, 0.4213, 1.0000, 0.7960, 0.5253, 0.2920, 0.4213,
1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000])
其中黑色小椅子的编码结果(target[4, 2])为:
tensor([0.0790, 0.7320, 0.1380, 0.2373, 1.0000, 0.0790, 0.7320, 0.1380, 0.2373,
1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000])
其中tvmonitor的编码结果(target[2, 3])为:
tensor([0.8990, 0.6693, 0.1660, 0.1760, 1.0000, 0.8990, 0.6693, 0.1660, 0.1760,
1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 1.0000])

从这个for循环可以看出,两个x、y、w、h和置信度都是一样的,就是我们前面说的,即,如果训练图像的某个cell含有多个物体的中心点的话,只保留程序遍历到的最后一个物体。
到此,训练数据的已经处理成YOLO需要的格式(7×7×30)。
step2:损失函数
将原图resize成448×448后输入网络中,最后输出(7×7×30)的张量。下面来讲解如何根据标注好的训练样本,计算损失。
根据标签数据,计算出含有物体中心点的cell的掩码 coord_mask[0,:,:].numpy()

取反,得到不含有物体中心点的cell的掩码 noobj_mask[0,:,:].numpy()
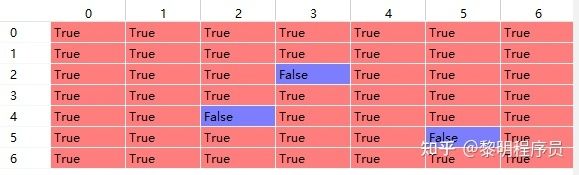
下面对损失函数的五个部分进行分析:
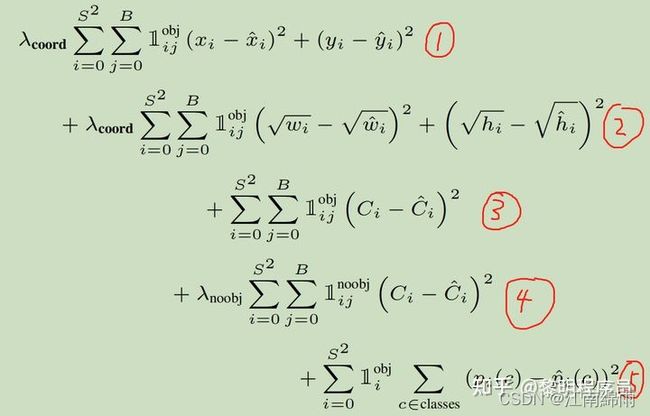
先简介一下这个五个部分:
①:含有物体中心点的cell里,负责预测的bounding box预测出的xy的MSE
②:含有物体中心点的cell里,负责预测的bounding box预测出的wh的MSE
③:含有物体中心点的cell里,负责预测的bounding box预测出的存在物体的置信度的误差。Ci是真实值,用预测出的框体与GT的IOU表示,Ci_hat是yolo的预测值,然后累加MSE。预测置信度对后续非极大值抑制有用。
④:不含有物体中心点的cell里,每一个bounding box都要参与到loss的计算,Ci一直=0;Ci_hat=bounding box的预测值,然后累加MSE。
⑤:含有物体中心点的cell里,预测出的物体类别向量和GT对应的向量的MSE。
先看④——所有不含物体中心点的cell的预测分数与全零向量的MSE:

A步骤:上面是Yolo对某张图像前向传播的输出张量,下面是该图的目标张量。
B步骤:乘以 不含物体中心点的cell的掩码。
C步骤:挖去了三个洞(去除了3个含有物体中心点的cell的数据)。
D步骤:一共49个格子,挖去3个=46,B=2,因此拉直的向量长度为92。
E步骤:计算MSE——对应论文中的④。
总结④:如果某个cell中不包含物体的中心点,那这个cell的bounding box预测出物体的置信度就要趋近于0。
再看①②③⑤:
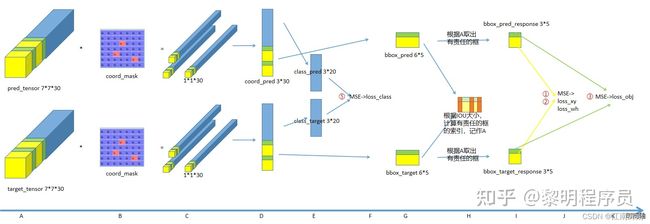
A步骤:上一行图是Yolo对某张图像前向传播的输出张量,下一行图是该图的目标张量。
B步骤:乘以含物体中心点的cell的掩码。
C步骤:只留下三个向量(3个含有物体中心点的cell的数据)。
D步骤:向量合并
E步骤:提取出类别的向量。
F步骤:计算MSE——对应论文中的⑤
总结⑤:如果有物体,预测正确类别误差就=0。
G步骤:提取出xywh和置信度的向量,向量合并
H步骤:每一个cell会有2个bounding box,每个bounding box与ground truth的IOU,然后,得到索引矩阵(可以用来确定哪个bounding box对于这个cell来说是responsible for that prediction的)
I步骤:提取出有责任的bounding box的向量。
J步骤:bounding box预测出的xy与GT算MSE——对应论文中的①;bounding box预测出的wh与GT算MSE——对应论文中的②;
总结①②:bounding box预测出的xywh和真实的越接近,误差越小。
K步骤:bounding box预测出的置信度与GT算MSE——对应论文中的③。
( 这里有个tips,就是计算置信度的时候使用了公式:
![]()
对于label计算这个公式,Pr(Object)=1,最终使用的是iou_predict_truth来作为置信度目标,这样有更深层的含义,就是希望学习到的是如何计算当前预测的box与ground_truth的iou来作为置信度,这个真的好厉害啊,但是也好复杂,他想要学习到这个信息,是不是最起码得对目标位置有个准确的认识,然后还要学习到iou计算公式,最终才会计算到这个iou。)
总结③:yolo预测出的置信度和真实的置信度(预测出来的框体和GT的IOU)越接近误差越小。
最后再将这些误差带权叠加,作为最终的损失函数。再讲一下损失函数前面的权重参数:
-
位置相关误差(坐标、IOU)与分类误差对网络loss的贡献值是不同的,因此YOLO在计算loss时,使用 λ c o o r d = 5 λ_{coord} = 5 λcoord=5 修正 c o o r d E r r o r coordError coordError。
-
在计算IOU误差时,包含物体的格子与不包含物体的格子,二者的IOU误差对网络loss的贡献值是不同的。若采用相同的权值,那么不包含物体的格子的confidence值近似为0,变相放大了不包含物体的格子的confidence误差在计算网络参数梯度时的影响。为解决这个问题,YOLO 使用 λ n o o b j = 0.5 λ_{noobj} = 0.5 λnoobj=0.5 修正 i o u E r r o r iouError iouError。(注此处的‘包含’是指存在一个物体,它的中心坐标落入到格子内)。
四:测试阶段
step1:输入原图
经过YOLO_v1网络后,输出7×7×(2×5+20)的张量
step2:计算每个bbox的类别得分
![]()
- 从每一个cell中找出20个类别score中最大的类别,作为cell中两box预测出的类别
- 针对每一个cell中的两个bbox,选择置信度大的box来代表这个cell,并按上面的公式计算出该box的类别得分
- 这样只剩下49个bbox,最后进行NMS
五:YOLO_v1的不足
首先,相比RCNN系列物体检测方法,YOLO具有以下缺点:
- 识别物体位置精准性差。
- 召回率低。
再者,针对于YOLO的v1系列的短板,也有以下几个缺陷:
- 由于感受野太大,只分了 7×7个cell,对一些群体性的小目标检测效果很差。
- 如果一个cell中有多个类别,也检测不出
- 定位不准确,毕竟没有RP,光想一步到位了
至此我对YOLO_v1的全部流程与细节,进行了深度讲解,希望对大家有所帮助,有不懂的地方或者建议,欢迎大家在下方留言评论。(码字不易,各位看官点个赞,手留余香~谢谢!)
我是努力在CV泥潭中摸爬滚打的江南咸鱼,我们一起努力,不留遗憾!