操作系统原理总结【含详解】——第一章《计算机系统概述》
文章导航
- 1.1 操作系统的基本构成
- 1.2 指令的执行
- 1.3 中断
-
- 1.3.1 中断和指令周期
- 1.3.2 中断处理
- 1.3.3 多个中断
- 1.4 直接内存存取
最近开始复习操作系统,之前学了一遍,算是对操作系统有了大致的了解。希望通过第二遍复习,能够将知识点再巩固一遍。在这次复习总结中,我会附带一些我自己的理解,可能会存在一些错误,希望大家能够及时在评论区里指出,大家相互学习,相互进步!我会持续更新,直到我将操作系统复习完成,希望我的总结能够给小伙伴们带来帮助,大家的点赞、收藏和评论都是对我最大的支持!
参考书籍:操作系统——精髓与设计原理(第八版)
1.1 操作系统的基本构成
计算机由处理器、存储器和输入/输出部件组成,每类部件都由一个或多个模块。这些部件以某种方式互连,已实现计算机执行程序的主要功能。因此,计算机有4个主要的结构化部件:
- 处理器:控制计算机的操作,执行数据处理功能。只有一个处理器时,它通常指中央处理器(CPU)
- 内存:存储数据和程序。此类存储器通常是易失性的,即当计算机关机时,存储器的内容会丢失。相对于此的是磁盘存储器,当计算机关机时,它的内容不会丢失。内存通常也称为实存储器或主存储器。
- 输入/输出模块:在计算机中和外部环境之间移动数据。
- 系统总线:在处理器、内存和输入/输出模块间提供通信的设施。
图1.1显示了这些部件的顶视图。

处理器的一种功能是与存储器交换数据。为此,它通常使用两个内部寄存器:
- 存储器地址寄存器(MAR):用于确定下一次读/写的存储器地址。
- 存储器缓冲寄存器(MBR):存放要写入存储器的数据或从存储器中读取的数据。
同理:
- 输入/输出地址寄存器(I/O AR):用于确定一个特定的输入/输出设备。
- 输入/输出缓冲寄存器(I/0 BR):用于在输入/输出模块和处理器间交换数据。
内存(主存)模块由一组单元组成,这些单元由顺序编号的地址定义。每个单元包含一个二进制数,它可以解释为一个指令或数据。输入/输出模块在外部设备与处理器和存储器之间传送数据。输入/输出模块包含内存缓冲区,用于临时保存数据,直到它们被发送出去。
1.2 指令的执行
处理器执行的程序是由一组保存在存储器(内存)中的指令组成的。 最简单的指令处理包括两步:处理器从存储器中一次读取一条指令,然后执行每条指令。程序执行是由不断重复的读取指令和执行指令的过程组成的。其中,单个指令所需要的处理称为一个指令周期。
如图1.2所示,我们可以使用两个简单的步骤来描述指令周期。这两个步预分别称为取指阶段和执行阶段。仅当机器关机、发生某些未知错误或遇到与停机相关的程序指令时,程序执行才会停止。

在每个指令周期开始时,处理器从存储器中取一条指令。在典型的处理器中,程序计数器(简称PC)保存下一次要取得指令地址。除非出现其他情况,否则处理器在每次取指令后总是递增PC,以便能够取下一条指令(即位于下一个存储器地址的指令)。
举个例子:考虑一台简化的计算机,其中的每条指令占据存储器中的一个16位字,假设程序计数器(PC)被置为地址300,那么处理器下一次将在地址为300的存储单元处取指令,在随后的指令周期中,它将从地址为301、302、303等的存储单元处取指令。
取到的指令放在处理器的指令寄存器中。指令中包含确定处理器将要执行的操作的位,处理器解释指令并执行对应的操作。大体上,这些动作可以分为4类:
- 处理器-存储器:数据可在两者之间相互传送
- 处理器-I/O:通过处理器和I/O模块的数据传送,数据可以输出到外部设备,或从外部设备向处理器输入数据
- 数据处理:处理器可以执行很多与数据相关的算数操作或逻辑操作
- 控制:某些指令可以改变执行顺序。 例如,处理器从地址为149的存储单元中取出一条指令,该指令指定下一条应该从地址为182的存储单元中取,这样处理器就会把程序计数器置为182.因此在下一个取指阶段,将从地址为182的存储单元而非150得存储单元中取指令。
举个例子:假设一台机器具有图1.3中列出的所有特征,处理器包含一个称为累加器(AC)的数据寄存器,所有指令和长度均为16位,使用16位的单元或字来组织存储器。指定格式中有4位是操作码,因而最多有24=16种不同的操作码(用1位十六进制数字表示,即下图中(b)整数格式中的S)。操作码定义了处理器执行的操作。通过指令格式的余下12位,可直接访问的存储器尺寸最大为212=4096个字(用3位十六进制数字表示)。
图1.4描述了程序的部分执行过程,显示了存储器和处理器寄存器的相关部分。给出的程序片段把地址为940的存储单元中的内容与地址为941的存储单元中的内容相加,并将结果保存在后一个单元中。这需要三条指令,可用三个取指阶段和三个执行阶段来描述:

解读
步骤1:PC中包含第一条指令的地址为300,该指令内容(值为十六进制数1940)被送入到处理器中的指令寄存器IR中,PC增1。注意:该处理过程使用了存储地址寄存器(MAR)和存储器缓冲寄存器(MBR)。
步骤2:IR中最初的4位(十六进制数),即处理器从存储器中取出的第一条指令1940。1是操作码,为十六进制数,表示从内存中载入累加器(AC),剩下的12位(后三个十六进制数)表示地址为940,然后将地址940中的数据放入累加器(AC)中。
步骤3:由于步骤1中PC增1,所以第二次从地址为301的存储单元中取下一条指令(5941),PC再增1。
步骤4:原理同步骤2,将地址941中取出的数据与AC中的数据相加,并存放在AC中
步骤5:从地址为302的存储单元中取下一条指令(2941),PC增1。
步骤6:AC中的内容被存储在地址为941的存储单元中。
在该例中,为把地址为940的存储单元中的内容与地址为941的存储单元中的内容相加,一共需要三个指令周期,每个指令周期都包含一个取指阶段和一个执行阶段。
1.3 中断
事实上,所有计算机都提供允许其他模块(I/O、存储器)中断处理器正常处理过程的机制,表1.1列出了最常见的中断类别。
举个例子:假设有一台1GHz的CPU的PC,它每秒约可执行109条指令。典型的硬盘速度是7200转/秒,因此旋转半周的时间约为4ms,这要比处理器约慢400万倍。
补充:
1兆赫 = 1000,000赫兹。
1Hz = 1/s,即在单位时间内完成振动的次数,单位为赫兹(1赫兹=1次/秒)
图1.5(a)显示了这些事件的状态,用户程序在处理过程中交替执行一系列WRITE调用,竖实线表示程序中的代码段,代码段1、2和3表示不涉及I/O的指令序列。WRITE调用要执行一个I/O程序,该I/O程序是一个系统工具程序,由它执行真正的I/O操作。此I/O程序由三部分组成:
- 图中标记为4的指令序列,用于为实际的I/O操作做准备,包括复制将要输出到特定缓冲区的数据,为设备命令准备参数。
- 实际的I/O命令。如果不使用中断,则执行此命令时,程序必须等待I/O设备执行请求的函数。程序可以通过简单地重复执行一个测试操作的方式进行等待,以确定I/O操作是否完成
- 图中标记为5的指令序列,用于完成操作,包括设置一个表示操作成功或失败的标记。
虚线代表处理器执行的路径,即它显示了指令的执行顺序。遇到第一条WRITE指令,用户程序被中断,开始执行I/O程序。在I/O程序执行完成之后,WRITE指令之后的用户程序立即恢复执行。
由于完成I/O操作可能要花费较长时间,I/O程序需要挂起等待操作完成,因此用户程序会在WRITE调用处停留相当长一段时间。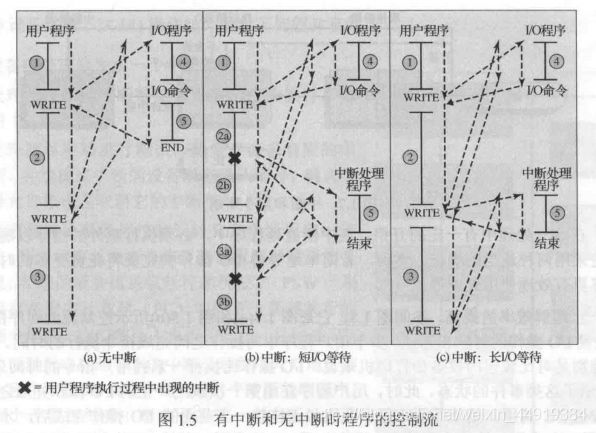
1.3.1 中断和指令周期
利用中断功能,处理器可以在I/O操作的执行过程中执行其他指令。
中断处理程序:外部设备做好服务的准备之后,即它准备好从处理器接收更多的数据时,外部设备的I/O模块给处理器发送一个中断请求信号。这时处理器会做出响应,暂停当前程序的处理,转去处理服务于特定I/O设备的程序。在对该设备的服务响应完成后,处理器恢复原先的执行。图1.5(b)中用“×”表示发生中断的点。注意:中断可在主程序中的任何位置而非仅在一条特定指令处发生。
为适应中断产生的情况,在指令周期中要增加一个中断阶段,如图1.7所示(与图1.2对照)。在中断阶段,处理器检查是否有中断发生,即检查是否出现中断信号,并进行相应的处理。

如图1.7所示,每次执行指令都需要检查是否有中断请求,显然增大了处理器的开销。为进一步理解效率的提高,参阅图1.8,它是图1.5(a)和图1.5(b)所示控制流的时序图。

解读:
图中全黑部分指的是在此过程,处理器需要等I/O做完所有的工作之后,才能进行下一步工作,可见效率很低。
而I/O操作与处理器执行并发的意思是,I/O和处理器同时工作。也就是处理器不需要等I/O做完所有的工作,这样效率明显得到提高。
同样的,长I/O等待如图1.9所示:
1.3.2 中断处理
中断激活了很多事件,包括处理器硬件中的事件和软件中的事件:
- 设备给处理器发出一个中断信号。
- 处理器在响应该中断之前,已经结束当前指令的执行,如图1.7所示。
- 处理器对该中断进行测试,确定存在未响应的中断,并给提交中断的设备发送确认信号,确定信号允许该设备取消它的中断信号。
- 处理器需要准备把控制权转交到中断程序。首先,需要保存从中断点恢复当前程序所需要的信息,要求的最少信息包括程序状态字(PSW)和保存在程序计数器(PC)中的下一条要执行的指令地址,它们被压入系统控制栈。
- 处理器把响应此中断的中断处理程序入口地址装入程序计数器。
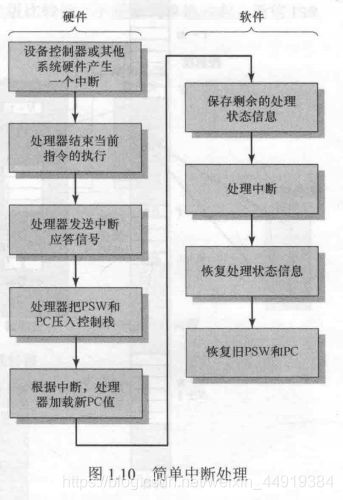
一旦装入程序计数器,处理器就继续下一个指令周期,该指令周期也从取指开始。 由于取指是由程序计数器的内容决定的,因此控制权被转交到中断处理程序,该程序的执行会引起以下操作:
-
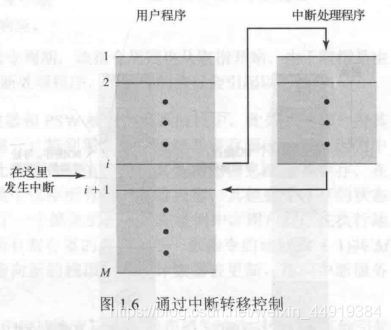
在这一点,与被中断程序相关的程序计数器和PSW被保存到系统栈中,此外,还有一些其他信息被当做正在执行程序的状态的一部分。特别需要保存处理器寄存器的内容,因为中断处理程序可能会用到这些寄存器,因此所有这些值和任何其他状态信息都需要保存。图1.11(a)给出了一个简单的例子。 在该例中,用户程序在执行地址为N的存储单元中的指令后被中断,所有寄存器的内容和下一条指令的地址(N+1)共M个字,被压入控制栈。栈指针被更新,指向新的栈顶;程序计数器被更新,指向中断服务程序的开始。

-
中断程序现在可以开始处理中断,其中包括检查与I/O操作相关的状态信息或其他引起中断的事件,还可能包括给I/O设备发送附加命令或应答。
-
中断处理结束后,被保存的寄存器值从栈中释放并恢复到寄存器中,如图1.11(b)所示。
-
最后的操作是从栈中恢复PSW和程序计数器的值,因此下一条要执行的指令来自前面被中断的程序。
这一段很重要,需要花时间去理解,讲的很详细。
1.3.3 多个中断
处理多个中断有两种方法。
方法一: 正在处理一个中断时,禁止再发生中断。禁止中断的意思是处理器将对任何新的中断请求信号不予理睬。如果在这期间发生了中断,通常中断保持挂起,当处理器再次允许中断时,再由处理器检查。因此,当用户程序正在执行时有一个中断发生,则立即禁止中断;当中断处理程序完成后,在恢复用户程序之前再允许中断,并且由处理器检查是否还有中断发生。【见图1.12(a)】
上述方法缺点是,未考虑相对优先级和时间限制的要求。例如,当来自通信线的输入到达时,可能需要快速接收,以便为更多的输入让出空间。如果在第二批输入到达时第一批输入还未处理完,就有可能由于I/O设备的缓冲区装满或溢出而丢失数据。
方法二: 定义中断优先级,允许高优先级中断打断低优先级中断的运行【见图1.12(b)】。例如,假设一个系统有3个I/O设备:打印机、磁盘和通信线,优先级以此为2、4和5,图1.13给出了可能的顺序。用户程序在t=0时开始,在t=10时,发生一个打印机中断;用户信息被放置到系统栈中并开始执行打印机中断服务例程(ISR);这个例程仍在执行时,在t=15时发生了一个中断,由于通信线的优先级高于打印机,因此必须处理这个中断,打印机ISR被打断,其状态被压入栈中,并开始执行通信ISR;当这个程序正在执行时,又发生了一个磁盘中断(t=20),由于这个终端的优先级比较低,于是被简单地挂起,通信ISR运行直到结束。
当通信ISR完成后(t=25),恢复以前关于执行打印机ISR的处理器状态。但是,在执行这个例程中的任何一条指令前,处理器必须完成高优先级的磁盘中断,这样控制权就转移给了磁盘ISR。只有当这个例程也完成(t=35)时,才恢复打印机ISR。当打印机ISR完成时(t=40),控制权最终返回到用户程序。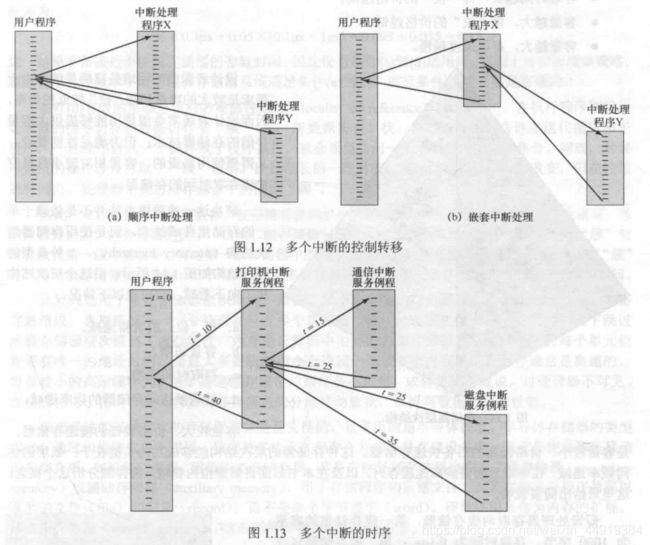
1.4 直接内存存取
执行I/O操作的技术有三种:可编程I/O、中断驱动I/O和直接内存存取(DMA)。
可编程I/O: 当处理器正在执行程序并遇到一个与I/O相关的指令时,它会通过给相应的I/O模块发命令来执行这个指令。使用可编程I/O操作时,I/O模块执行请求的动作并设置I/O状态寄存器中相应的位,但它并不会进一步通知处理器,尤其是它并不会中断处理器。因此处理器在执行I/O指令后,还要定期检查I/O模块的状态,以确定I/O操作是否已经完成。
可编程I/O的问题是,处理器通常必须等待很长的时间,以确定I/O模块是否做好了接收或发送更多数据的准备。处理器在等待期间必须不断的询问I/O模块的状态,因此会严重降低整个系统的性能。
中断驱动I/O: 由处理器给I/O模块发送I/O命令,然后处理器继续做其他一些有用的工作。当I/O模块准备好与处理器交换数据时,它将打断处理器的执行并请求服务。处理器和前面一样执行数据传送,然后恢复处理器以前的执行过程。
尽管中断驱动I/O比简单的可编程I/O更有效,但处理器仍然需要主动干预在存储器和I/O模块之间的数据传送,并且任何数据传送都必须完全通过处理器。因此这两种I/O形式都有两方面固有的缺陷:
- I/O传送速度受限于处理器测试设备和提供服务的速度
- 处理器忙于管理I/O传送的工作,必须执行很多指令已完成I/O传送
需要移动大量数据时,要是用一种更有效的技术:直接内存存取(DMA)。DMA功能可以由系统总线中的一个独立模块完成,也可以并入一个I/O模块中。无论采取何种形式,该技术的工作方式均是在处理器读或写一块数据时,给DMA模块产生一条命令,发送以下信息:
- 是否请求一次读或写
- 所涉I/O设备的地址
- 开始读或写的存储器单元
- 需要读或写的字数
之后处理器继续其他工作。处理器把这个操作委托给DMA模块负责处理。**DMA模块直接与存储器交互,传送整个数据块,每次传送一个字。这个过程不需要处理器参与。**传送完成之后,DMA模块像处理器发送一个中断信号。因此,只有开始传送和传送结束时处理器才会参与。
DMA模块需要控制总线来与存储器进行数据传送。由于在总线使用中存在竞争,当处理器需要使用总线时,要等待DMA模块。注意,这并不是一个中断,处理器没有保存上下文环境取做其他事情,而只是暂停一个总线周期(在总线上传输一个字的时间)。因此,在DMA传送过程中,当处理器需要访问总线时,处理器的执行速度会变慢。尽管如此,对多字I/O传送来说,DMA仍比中断驱动和程序控制I/O更有效。
都是一字一字敲上去的,对于部分难理解的地方都添加了说明,希望大家都能够看懂。大家的点赞、收藏和评论都是对我最大的支持呀!