Fast R-CNN
文章目录
-
-
- 论文信息
-
-
- 论文标题:
- 论文作者:
- 收录期刊/会议及年份:
-
- 论文学习
- 论文阅读
-
-
- 问题/背景:
- 主要贡献:
- 摘要:
- 介绍:
- Fast R-CNN 的结构和训练:
-
- Fast R-CNN 的具体步骤:
- RoI 池化层:
- 来自预训练网络的初始化:
- 微调:
- 多任务损失:
- 尺度不变性:
- Fast R-CNN 检测:
- 主要结果:
-
-
论文信息
论文标题:
Fast R-CNN
论文作者:
Ross Girshick
收录期刊/会议及年份:
ICCV,2015
论文获取地址
论文学习
改进: 提出了一个 RoI pooling;并将 CNN、RoI pooling、softmax 分类、bbox 回归整合到一起训练。
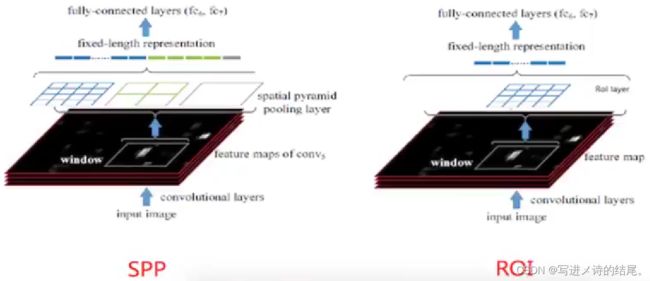
RoI pooling 实际上是一个特殊的 SPP 层,目的是减少计算时间并得到固定长度的特征向量。
端到端模型: 从输入端到输出端直接用一个神经网络相连,整体优化目标函数。
Fast R-CNN 实际上是一个伪端到端模型,它仍需要使用 SS 算法生成候选区域,需要将候选区域映射到特征图上。
CNN 的训练和 SVM 分类器的训练在时间上是先后的,两者的训练方式独立,因此 SVM 的训练 Loss 无法更新 SPP 层之前的卷积层参数。去掉 SVM 后,所有特征都存储在内存中,不再占用磁盘空间,形成了 End-to-End 模型(生成候选区域除外,End-to-End 在 Faster R-CNN 中得以完善)。
多任务损失: 对于分类损失,通过 softmax 输出 N+1 个值,使用交叉熵损失;
对于回归损失,输出 4 个边框值,使用 MAE 损失。


论文阅读
问题/背景:
R-CNN 与 SPPNet 的训练阶段过多,检测速度慢
主要贡献:
- 相比于 R-CNN 与 SPPNet,能得到更高的 mAP;
- 训练是单个阶段的(该方法不属于一阶段),使用多任务损失;
- 训练可以更新所有的网络层;
- 提取的特征不需要写入磁盘。
摘要:
对于非常深的 VGG16 网络,Fast R-CNN 的训练速度比 R-CNN 快 9 倍,测试速度快 213 倍,并在 PASCAL VOC 2012 上实现了更高的 mAP。
同样对于 VGG16 网络,Fast R-CNN 的训练速度比 SPPNet 快 3 倍,测试速度快 10 倍,而且更准确。
介绍:
R-CNN 有几个明显的缺点:
- 训练分多个阶段:微调 CNN,训练 SVM 分类器,训练边框回归器
- 训练非常耗费时间和空间:为了训练 SVM 分类器和边框回归器,从每幅图像中的每个候选区域提取的特征都需要写入磁盘
- 执行目标检测任务的速度很慢:在一个 GPU 上用 VGG16 来检测一张图像需要花费 47s
R-CNN 速度很慢,因为它为每个候选区域执行前向传递,而没有共享计算(即使重合度很高的候选区域也要输入 CNN 中进行卷积计算)。
SPPNet 通过共享计算(整个图像输入 CNN 中进行一次卷积计算)来提升速度。
SPPNet 的测试速度比 R-CNN 提高了 10-100 倍,由于更快的候选区域特征提取,训练时间也减少了 3 倍。
SPPNet 也有几个明显的缺点:
- 训练分多个阶段:特征提取,用损失函数微调网络,训练 SVM 分类器,训练边框回归器
- 训练比较耗费时间和空间:从候选区域提取的特征同样要写入磁盘
- 不能更新空间金字塔池化层之前的卷积层参数:这一点与 R-CNN 不同,这将限制更深网络的精度
Fast R-CNN 的结构和训练:
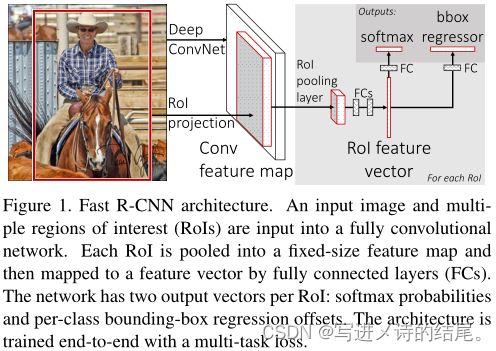
Fast R-CNN 的具体步骤:
- 使用 SS 算法生成候选区域,将整个图像输入 CNN 得到特征图;
- 将候选区域通过 RoI projection 映射到特征图上得到对应的特征块;
- 将特征块(特征矩阵)通过 RoI 池化层缩放至统一大小,再经过两个全连接层得到固定长度的特征向量;
- 将特征向量分别输入到两个全连接层,一个全连接层输出 K+1 个 softmax 概率值(K 为类别数量,1 为背景),另一个全连接层输出 4 个修正边框位置的值。
RoI 池化层:
RoI 池化层将特征图上每一个候选区域对应的特征矩阵缩放至固定大小(这里的固定大小指的是固定区域数量,如 7*7 表示有 49 个小区域),然后对每一个小区域执行最大池化操作,最后每一个特征矩阵都能得到固定大小的特征向量。
RoI 池化层是 SPPNet 中 SPP 层的一个特例(只使用一个金字塔级)。
一个感兴趣区域(RoI)是一个候选区域对应到特征图上的一个矩形窗口,每一个感兴趣区域(RoI)由 ( r , c , h , w ) (r, c, h, w) (r,c,h,w) 定义,其中 ( r , c ) (r, c) (r,c) 表示左上角点, ( h , w ) (h, w) (h,w) 表示高和宽。
RoI 池化层将 h*w 的 RoI 划分成 H*W 个网格,每个网格中执行最大池化操作。
来自预训练网络的初始化:
我们使用三个预训练的 ImageNet 网络进行实验,每个网络具有五个最大池化层和五到十三个卷积层。当用一个预训练网络初始化 Fast R-CNN 网络时会经历三次转换:
首先,最后一个最大池化层将被 RoI 池化层替换,并设置好 H 和 W(如 H=W=7);
其次,网络的最后一个全连接层和 softmax 会被两个分支替换(一个分支输出 softmax 概率值,另一个分支输出 4 个边框回归的值);
最后,网络被修改为接受两个数据的输入,一个是图像列表,另一个是 RoI 列表。
微调:
通过反向传播训练所有网络参数是 Fast R-CNN 中一个很重要的能力。
首先解释为什么 SPPNet 不能更新 SPP 层之前的卷积层参数:根本原因在于当训练样本(即 RoI)来自不同的图像时,通过 SPP 层的反向传播效率非常低。效率低是因为每个 RoI 都可能具有趋近整个图像的非常大的接受场,而前向传递必须处理整个接受场,因此训练输入很大(通常是整个图像)。
我们提出了一种更有效的训练方法,即在训练过程中利用特征共享。在 Fast R-CNN 的训练中,我们分层采样小批量,首先采样 N 个图像,然后每个图像采样 R/N 个 RoI。很关键的一点是,来自同一图像的 RoI 在向前和向后传递时共享计算和内存。
当 N=2 和 R=128 时,训练速度要比从 128 个不同图像上各采样一个 RoI 快 64 倍。
该方法的一个问题是,它可能会导致训练的收敛速度缓慢,因为来自同一图像的 RoI 是相关的。但这个问题似乎不是一个实际问题,在 N=2 和 R=128 的情况下使用比 R-CNN 更少的 SGD 迭代便获得了良好的结果。
除了分层采样,Fast R-CNN 还使用一个简化的训练过程和一个微调阶段,共同优化 softmax 分类器和边框回归器。
多任务损失:
Fast R-CNN 有两个输出分支,一个分支用于分类,另一个分支用于回归。
每一个用于训练的 RoI 都带有真实类别和真实边框的标签,我们使用一个多任务损失作用于每一个带标签的 RoI 上来联合训练分类和回归。
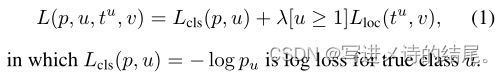

尺度不变性:
两个相同的目标,一个尺度比较大,一个尺度比较小,如果这两个不同尺度的目标都能被模型很好的识别出来,就说明该模型具有比较好的尺度不变性。
我们使用两种方法来实现目标检测的尺度不变性:(1)单尺度训练,每一张图片都被处理成预定义好的尺寸,其目的是让网络直接学习尺度不变性;(2)多尺度训练,对每一张图片随机进行金字塔级采样,该方式还能增强数据。
Fast R-CNN 检测:
对于图像分类任务来说,花费在全连接层中的计算时间要比花费在卷积层中的计算时间少;而对于检测任务,因为要处理的 RoI 数量很大,因此近一半的前向传递时间都要花费在全连接层的计算上。
通过截断的奇异值分解方法对全连接层进行压缩,可以很容易地实现加速。

假设有一个 u*v 大小的矩阵,可以通过奇异值分解把它分解成一个 u*n 大小的矩阵乘以一个 n*n 大小的对角矩阵再乘以一个 n*v 大小的矩阵。中间这个对角矩阵有一个性质,就是越靠近左上角的值越重要,越靠近右下角的值作用越小。利用这个性质,可以把部分右下角的值去掉,使其变成 t*t 的对角矩阵,左右两个矩阵也作出相应的变换分别得到 u*t 和 t*v 的矩阵,这就相当于对原始矩阵做了一个压缩。
主要结果:
- Fast R-CNN 在 VOC07,2010 和 2012 上的 mAP 达到了最高;
- 与 R-CNN 和 SPPNet 相比,训练和测试速度更快;
- 微调网络中的卷积层可以提高 mAP。


该实验结果证明了奇异值分解方法(SVD)可以加速训练。

该实验结果证明了微调网络中的卷积层参数可以提高 mAP。

该实验结果证明了多任务训练不仅有效,而且比多阶段训练效果更好。

该实验结果证明了多尺度训练比单尺度训练效果更好,mAP 更高,但速度方面有所下降。
在DPM 模型中增加训练数据到一定程度后,会出现精度饱和的情况,我们做了实验以证明 Fast R-CNN 是否也会出现精度饱和的现象。实验结果证明对于 Fast R-CNN,增加训练数据能够明显提高 mAP。
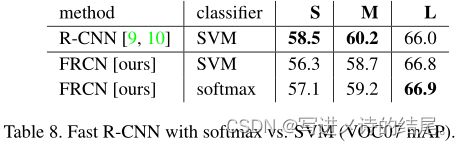
该实验结果证明 softmax 比 SVM 的分类效果更好。

该实验结果证明候选区域的数量并不是越多越好,随着候选区域数量的增加,mAP 值会呈现先增后减的现象。