一文带你深入了解 redis 复制技术及主从架构
主从架构可以说是互联网必备的架构了,第一是为了保证服务的高可用,第二是为了实现读写分离,你可能熟悉我们常用的 MySQL 数据库的主从架构,对于我们 redis 来说也不意外,redis 数据库也有各种各样的主从架构方式,在主从架构中会涉及到主节点与从节点之间的数据同步,这个数据同步的过程在 redis 中叫做复制,这在篇文章中,我们详细的聊一聊 redis 的复制技术和主从架构 ,本文主要有以下内容:
- 主从架构环境搭建
- 主从架构的建立方式
- 主从架构的断开
- 复制技术的原理
- 数据同步过程
- 心跳检测
- 主从拓扑架构
- 一主一从
- 一主多从
- 树状结构
主从环境搭建
redis 的实例在默认的情况下都是主节点,所以我们需要修改一些配置来搭建主从架构,redis 的主从架构搭建还是比较简单的,redis 提供了三种方式来搭建主从架构,在后面我们将就介绍,在介绍之前我们要先了解主从架构的特性:在主从架构中有一个主节点(master)和最少一个从节点(slave),并且数据复制是单向的,只能从主节点复制到从节点,不能由从节点到主节点。
主从架构的建立方式
主从架构的建立有以下三种方式:
- 在 Redis.conf 配置文件中加入 slaveof {masterHost} {masterPort} 命令,随 Redis 实例的启动生效
- 在 redis-server 启动命令后加入 --slaveof {masterHost} {masterPort} 参数
- 在 redis-cli 交互窗口下直接使用命令:slaveof {masterHost} {masterPort}
上面三种方式都可以搭建 Redis 主从架构,我们以第一种方式来演示,其他两种方式自行尝试,由于是演示,所以就在本地启动两个 Redis 实例,并不在多台机器上启动 redis 的实例了,我们准备一个端口 6379 的主节点实例,准备一个端口 6480 从节点的实例,端口 6480 的 redis 实例配置文件取名为 6480.conf 并且在里面添加 slaveof 语句,在配置文件最后加入如下一条语句
slaveof 127.0.0.1 6379
分别启动两个 redis 实例,启动之后他们会自动建立主从关系,关于这背后的原理,我们后面在详细的聊一聊,先来验证一下我们的主从架构是否搭建成功,我们先在 6379 master 节点上新增一条数据:

然后再 6480 slave 节点上获取该数据:

可以看出我们在 slave 节点上已经成功的获取到了在 master 节点新增的值,说明主从架构已经搭建成功了,我们使用 info replication 命令来查看两个节点的信息,先来看看主节点的信息

可以看出 6379 端口的实例 role 为 master,有一个正在连接的实例,还有其他运行的信息,我们再来看看 6480 端口的 redis 实例信息

可以看出两个节点之间相互记录着对象的信息,这些信息在数据复制时候将会用到。在这里有一点需要说明一下,默认情况下 slave 节点是只读的,并不支持写入,也不建议开启写入,我们可以验证一下,在 6480 实例上写入一条数据
127.0.0.1:6480> set x 3
(error) READONLY You can't write against a read only replica.
127.0.0.1:6480>
提示只读,并不支持写入操作,当然我们也可以修改该配置,在配置文件中 replica-read-only yes 配置项就是用来控制从服务器只读的,为什么只能只读?因为我们知道复制是单向的,数据只能由 master 到 slave 节点,如果在 salve 节点上开启写入的话,那么修改了 slave 节点的数据, master 节点是感知不到的,slave 节点的数据并不能复制到 master 节点上,这样就会造成数据不一致的情况,所以建议 slave 节点只读。
主从架构的断开
主从架构的断开同样是 slaveof 命令,在从节点上执行 slaveof no one 命令就可以与主节点断开追随关系,我们在 6480 节点上执行 slaveof no one 命令
127.0.0.1:6480> slaveof no one
OK
127.0.0.1:6480> info replication
# Replication
role:master
connected_slaves:0
master_replid:a54f3ba841c67762d6c1e33456c97b94c62f6ac0
master_replid2:e5c1ab2a68064690aebef4bd2bd4f3ddfba9cc27
master_repl_offset:4367
second_repl_offset:4368
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:4367
127.0.0.1:6480>
执行完 slaveof no one 命令之后,6480 节点的角色立马恢复成了 master ,我们再来看看时候还和 6379 实例连接在一起,我们在 6379 节点上新增一个 key-value
127.0.0.1:6379> set y 3
OK
在 6480 节点上 get y
127.0.0.1:6480> get y
(nil)
127.0.0.1:6480>
在 6480 节点上获取不到 y ,因为 6480 节点已经跟 6379 节点断开的联系,不存在主从关系了,slaveof 命令不仅能够断开连接,还能切换主服务器,使用命令为 slaveof {newMasterIp} {newMasterPort},我们让 6379 成为 6480 的从节点, 在 6379 节点上执行 slaveof 127.0.0.1 6480 命令,我们在来看看 6379 的 info replication
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6480
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:4367
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:99624d4b402b5091552b9cb3dd9a793a3005e2ea
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:4367
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:4368
repl_backlog_histlen:0
127.0.0.1:6379>
6379 节点的角色已经是 slave 了,并且主节点的是 6480 ,我们可以再看看 6480 节点的 info replication
127.0.0.1:6480> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6379,state=online,offset=4479,lag=1
master_replid:99624d4b402b5091552b9cb3dd9a793a3005e2ea
master_replid2:a54f3ba841c67762d6c1e33456c97b94c62f6ac0
master_repl_offset:4479
second_repl_offset:4368
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:4479
127.0.0.1:6480>
在 6480 节点上有 6379 从节点的信息,可以看出 slaveof 命令已经帮我们完成了主服务器的切换。
复制技术的原理
redis 的主从架构好像很简单一样,我们就执行了一条命令就成功搭建了主从架构,并且数据复制也没有问题,使用起来确实简单,但是这背后 redis 还是帮我们做了很多的事情,比如主从服务器之间的数据同步、主从服务器的状态检测等,这背后 redis 是如何实现的呢?接下来我们就一起看看
数据复制原理
我们执行完 slaveof 命令之后,我们的主从关系就建立好了,在这个过程中, master 服务器与 slave 服务器之间需要经历多个步骤,如下图所示:

slaveof 命令背后,主从服务器大致经历了七步,其中权限验证这一步不是必须的,为了能够更好的理解这些步骤,就以我们上面搭建的 redis 实例为例来详细聊一聊各步骤。
1、保存主节点信息
在 6480 的客户端向 6480 节点服务器发送 slaveof 127.0.0.1 6379 命令时,我们会立马得到一个 OK
127.0.0.1:6480> slaveof 127.0.0.1 6379
OK
127.0.0.1:6480>
这时候数据复制工作并没有开始,数据复制工作是在返回 OK 之后才开始执行的,这时候 6480 从节点做的事情是将给定的主服务器 IP 地址 127.0.0.1 以及端口 6379 保存到服务器状态的 masterhost 属性和 masterport 属性里面
2、建立 socket 连接
在 slaveof 命令执行完之后,从服务器会根据命令设置的 IP 地址和端口,跟主服务器创建套接字连接, 如果从服务器能够跟主服务器成功的建立 socket 连接,那么从服务器将会为这个 socket 关联一个专门用于处理复制工作的文件事件处理器,这个处理器将负责后续的复制工作,比如接受全量复制的 RDB 文件以及服务器传来的写命令。同样主服务器在接受从服务器的 socket 连接之后,将为该 socket 创建一个客户端状态,这时候的从服务器同时具有服务器和客户端两个身份,从服务器可以向主服务器发送命令请求而主服务器则会向从服务器返回命令回复。
3、发送 ping 命令
从服务器与主服务器连接成功后,做的第一件事情就是向主服务器发送一个 ping 命令,发送 ping 命令主要有以下目的:
- 检测主从之间网络套接字是否可用
- 检测主节点当前是否可接受处理命令
在发送 ping 命令之后,正常情况下主服务器会返回 pong 命令,接受到主服务器返回的 pong 回复之后就会进行下一步工作,如果没有收到主节点的 pong 回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从服务器会断开复制连接,等待下一次定时任务的调度。
4、身份验证
从服务器在接收到主服务器返回的 pong 回复之后,下一步要做的事情就是根据配置信息决定是否需要身份验证:
- 如果从服务器设置了 masterauth 参数,则进行身份验证
- 如果从服务器没有设置 masterauth 参数,则不进行身份验证
在需要身份验证的情况下,从服务器将就向主服务器发送一条 auth 命令,命令参数为从服务器 masterauth 选项的值,举个例子,如果从服务器的配置里将 masterauth 参数设置为:123456,那么从服务器将向主服务器发送 auth 123456 命令,身份验证的过程也不是一帆风顺的,可能会遇到以下几种情况:
- 从服务器通过 auth 命令发送的密码与主服务器的 requirepass 参数值一致,那么将继续进行后续操作,如果密码不一致,主服务将返回一个 invalid password 错误
- 如果主服务器没有设置 requirepass 参数,那么主服务器将返回一个 no password is set 错误
所有的错误情况都会令从服务器中止当前的复制工作,并且要从建立 socket 开始重新发起复制流程,直到身份验证通过或者从服务器放弃执行复制为止
5、发送端口信息
在身份验证通过后,从服务器将执行 REPLCONF listening 命令,向主服务器发送从服务器的监听端口号,例如在我们的例子中从服务器监听的端口为 6480,那么从服务器将向主服务器发送 REPLCONF listening 6480 命令,主服务器接收到这个命令之后,会将端口号记录在从服务器所对应的客户端状态的 slave_listening_port 属性了,也就是我们在 master 服务器的 info replication 里面看到的 port 值。
6、数据复制
数据复制是最复杂的一块了,由 psync 命令来完成,从服务器会向主服务器发送一个 psync 命令来进行数据同步,在 redis 2.8 版本以前使用的是 sync 命令,除了命令不同之外,在复制的方式上也有很大的不同,在 redis 2.8 版本以前使用的都是全量复制,这对主节点和网络会造成很大的开销,在 redis 2.8 版本以后,数据同步将分为全量同步和部分同步。
-
全量复制:一般用于初次复制场景,不管是新旧版本的 redis 在从服务器第一次与主服务连接时都将进行一次全量复制,它会把主节点的全部数据一次性发给从节点,当数据较大时,会对主节点和网络造成很大的开销,redis 的早期版本只支持全量复制,这不是一种高效的数据复制方式
-
部分复制:用于处理在主从复制中因网络闪断等原因造成的数据丢失 场景,当从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据 给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销,部分复制是对老版复制的重大优化,有效避免了不必要的全量复制操作
redis 之所以能够支持全量复制和部分复制,主要是对 sync 命令的优化,在 redis 2.8 版本以后使用的是一个全新的 psync 命令,命令格式为:psync {runId} {offset},这两个参数的意义:
- runId:主节点运行的id
- offset:当前从节点复制的数据偏移量
也许你对上面的 runid、offset 比较陌生,没关系,我们先来看看下面三个概念:
1、复制偏移量
参与复制的主从节点都会分别维护自身复制偏移量:主服务器每次向从服务器传播 N 个字节的数据时,就将自己的偏移量的值加上 N,从服务器每次接收到主服务器传播的 N个字节的数据时,将自己的偏移量值加上 N。通过对比主从服务器的复制偏移量,就可以知道主从服务器的数据是否一致,如果主从服务器的偏移量总是相同,那么主从数据一致,相反,如果主从服务器两个的偏移量并不相同,那么说明主从服务器并未处于数据一致的状态,比如在有多个从服务器时,在传输的过程中某一个服务器离线了,如下图所示:
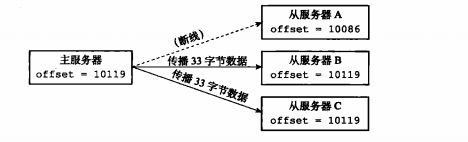
由于从服务器A 在数据传输时,由于网络原因掉线了,导致偏移量与主服务器不一致,那么当从服务器A 重启并且与主服务器连接成功后,重新向主服务器发送 psync 命令,这时候数据复制应该执行全量复制还是部分复制呢?如果执行部分复制,主服务器又如何补偿从服务器A 在断线期间丢失的那部分数据呢?这些问题的答案都在复制积压缓冲区里面
2、复制积压缓冲区
复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为 1MB,当主节点有连接的从节点(slave)时被创建,这时主节点(master) 响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区,如下图所示:
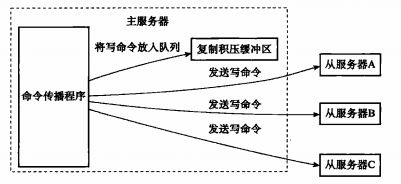
因此,主服务器的复制积压缓冲区里面会保存着一部分最近传播的写命令,并且复制积压缓冲区会为队列中的每个字节记录相应的复制偏移量。所以当从服务器重新连上主服务器时,从服务器通过 psync 命令将自己的复制偏移量 offset 发送给主服务器,主服务器会根据这个复制偏移量来决定对从服务器执行何种数据同步操作:
- 如果从服务器的复制偏移量之后的数据仍然存在于复制积压缓冲区里面,那么主服务器将对从服务器执行部分复制操作
- 如果从服务器的复制偏移量之后的数据不存在于复制积压缓冲区里面,那么主服务器将对从服务器执行全量复制操作
3、服务器运行ID
每个 Redis 节点启动后都会动态分配一个 40 位的十六进制字符串作为运行 ID,运行 ID 的主要作用是用来唯一识别 Redis 节点,我们可以使用 info server 命令来查看
127.0.0.1:6379> info server
# Server
redis_version:5.0.5
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:2ef1d58592147923
redis_mode:standalone
os:Linux 3.10.0-957.27.2.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:4.8.5
process_id:25214
run_id:7b987673dfb4dfc10dd8d65b9a198e239d20d2b1
tcp_port:6379
uptime_in_seconds:14382
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:14554933
executable:/usr/local/redis-5.0.5/src/./redis-server
config_file:/usr/local/redis-5.0.5/redis.conf
127.0.0.1:6379>
这里面有一个run_id 字段就是服务器运行的ID
了解这几个概念之后,我们一起来看看 psync 命令的运行流程,psync 命令运行流程如下图所示:

psync 命令的逻辑比较简单,整个流程分为两步:
1、从节点发送 psync 命令给主节点,参数 runId 是当前从节点保存的主节点运行ID,参数offset是当前从节点保存的复制偏移量,如果是第一次参与复制则默认值为 -1。
2、主节点接收到 psync 命令之后,会向从服务器返回以下三种回复中的一种:
- 回复 +FULLRESYNC {runId} {offset}:表示主服务器将与从服务器执行一次全量复制操作,其中 runid 是这个主服务器的运行 id,从服务器会保存这个id,在下一次发送 psync 命令时使用,而 offset 则是主服务器当前的复制偏移量,从服务器会将这个值作为自己的初始化偏移量
- 回复 +CONTINUE:那么表示主服务器与从服务器将执行部分复制操作,从服务器只要等着主服务器将自己缺少的那部分数据发送过来就可以了
- 回复 +ERR:那么表示主服务器的版本低于 redis 2.8,它识别不了 psync 命令,从服务器将向主服务器发送 sync 命令,并与主服务器执行全量复制
7、命令持续复制
当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。但是主从服务器并不会断开连接,因为接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
经过上面 7 步就完成了主从服务器之间的数据同步,由于这篇文章的篇幅比较长,关于全量复制和部分复制的细节就不介绍了,全量复制就是将主节点的当前的数据生产 RDB 文件,发送给从服务器,从服务器再从本地磁盘加载,这样当文件过大时就需要特别大的网络开销,不然由于数据传输比较慢会导致主从数据延时较大,部分复制就是主服务器将复制积压缓冲区的写命令直接发送给从服务器。
心跳检测
心跳检测是发生在主从节点在建立复制后,它们之间维护着长连接并彼此发送心跳命令,便以后续持续发送写命令,主从心跳检测如下图所示:
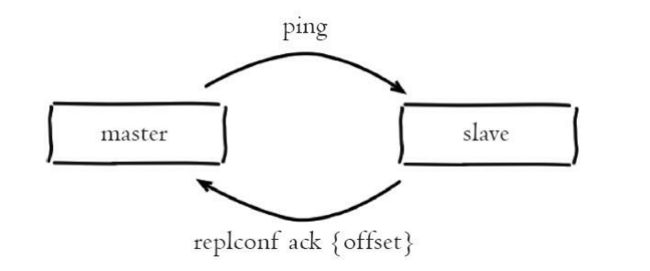
主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信,主从心跳检测的规则如下:
- 主节点默认每隔 10 秒对从节点发送 ping 命令,判断从节点的存活性和连接状态。可通过修改 redis.conf 配置文件里面的 repl-ping-replica-period 参数来控制发送频率
- 从节点在主线程中每隔 1 秒发送 replconf ack {offset} 命令,给主节点 上报自身当前的复制偏移量,这条命令除了检测主从节点网络之外,还通过发送复制偏移量来保证主从的数据一致
主节点根据 replconf 命令判断从节点超时时间,体现在 info replication 统 计中的 lag 信息中,我们在主服务器上执行 info replication 命令:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6480,state=online,offset=25774,lag=0
master_replid:c62b6621e3acac55d122556a94f92d8679d93ea0
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:25774
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:25774
127.0.0.1:6379>
可以看出 slave0 字段的值最后面有一个 lag,lag 表示与从节点最后一次通信延迟的秒数,正常延迟应该在 0 和 1 之间。如果超过 repl-timeout 配置的值(默认60秒),则判定从节点下线并断开复制客户端连接,如果从节点重新恢复,心跳检测会继续进行。
主从拓扑架构
Redis的主从拓扑结构可以支持单层或多层复制关系,根据拓扑复杂性可以分为以下三种:一主一从、一主多从、树状主从架构
一主一从结构
一主一从结构是最简单的复制拓扑结构,我们前面搭建的就是一主一从的架构,架构如图所示:

一主一从架构用于主节点出现宕机时从节点 提供故障转移支持,当应用写命令并发量较高且需要持久化时,可以只在从节点上开启 AOF,这样既保证数据安全性同时也避免了持久化对主节点的性能干扰。但是这里有一个坑,需要你注意,就是当主节点关闭持久化功能时, 如果主节点脱机要避免自动重启操作。因为主节点之前没有开启持久化功能自动重启后数据集为空,这时从节点如果继续复制主节点会导致从节点数据也被清空的情况,丧失了持久化的意义。安全的做法是在从节点上执行 slaveof no one 断开与主节点的复制关系,再重启主节点从而避免这一问题
一主多从架构
一主多从架构又称为星形拓扑结构,一主多从架构如下图所示:

一主多从架构可以实现读写分离来减轻主服务器的压力,对于读占比较大的场景,可以把读命令发送到 从节点来分担主节点压力。同时在日常开发中如果需要执行一些比较耗时的读命令,如:keys、sort等,可以在其中一台从节点上执行,防止慢查询对主节点造成阻塞从而影响线上服务的稳定性。对于写并发量较高的场景,多个从节点会导致主节点写命令的多次发送从而过度消耗网络带宽,同时也加重了主节点的负载影响服务稳定性。
树状主从架构
树状主从架构又称为树状拓扑架构,树状主从架构如下图所示:
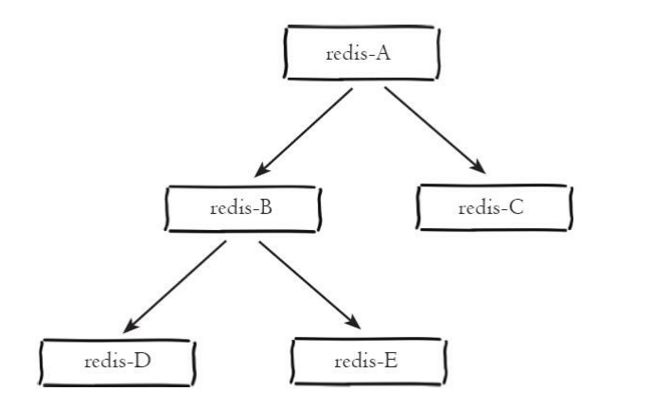
树状主从架构使得从节点不但可以复制主节 数据,同时可以作为其他从节点的主节点继续向下层复制。解决了一主多从架构中的不足,通过引入复制中 间层,可以有效降低主节点负载和需要传送给从节点的数据量。如架构图中,数据写入节点A 后会同步到 B 和 C节点,B节点再把数据同步到 D 和 E节点,数据实现了一层一层的向下复制。当主节点需要挂载多个从节点时为了避免对主节点的性能干扰,可以采用树状主从结构降低主节点压力。
最后
目前互联网上很多大佬都有 Redis 系列教程,如有雷同,请多多包涵了。原创不易,码字不易,还希望大家多多支持。若文中有所错误之处,还望提出,谢谢。
欢迎扫码关注微信公众号:「平头哥的技术博文」,和平头哥一起学习,一起进步。
