hadoop3.3.4集群安装部署
一、环境准备:3台centos7服务器
修改hosts(所有服务器都需要修改)
vim /etc/hosts
10.9.5.114 cdh1
10.9.5.115 cdh2
10.9.5.116 cdh3 
修改主机名,cdh1为主机名,根据自己定义
sysctl kernel.hostname=cdh1安装远程同步工具rsync,用于服务器间同步配置文件
yum install -y rsync设置时间同步,如果时间相差过大启动会报ClockOutOfSyncException异常,默认是30000ms
安装以下包,否则可能会报No such file or directory
yum install autoconf automake libtool配置root用户免密登录(所有服务器执行,因为host配置的是IP,所以本机也需要执行公钥上传)
cd ~/.ssh/
ssh-keygen -t rsa #生成免密登录公私钥,根据提示按回车或y
ssh-copy-id -i ~/.ssh/id_rsa.pub root@cdh1 #将本机的公钥上传至cdh1机器上,实现对cdh1机器免密登录
ssh-copy-id -i ~/.ssh/id_rsa.pub root@cdh2
ssh-copy-id -i ~/.ssh/id_rsa.pub root@cdh3
关闭防火墙,或者放行以下端口:9000、50090、8022、50470、50070、49100、8030、8031、8032、8033、8088、8090
二、下载hadoop3.3.4
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
三、安装Hadoop
1、登录cdh1服务器,将下载的安装包上传至/home/software目录
进入/home/service目录并解压hadoop
cd /home/servers/
tar -zxvf ../software/hadoop-3.3.1.tar.gz2、将Hadoop添加到环境变量vim /etc/profile
vim /etc/profile
export HADOOP_HOME=/home/servers/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin3、新建目录
mkdir /home/hadoop
mkdir /home/hadoop/tmp
mkdir /home/hadoop/var
mkdir /home/hadoop/dfs
mkdir /home/hadoop/dfs/name
mkdir /home/hadoop/dfs/data4、Hadoop集群配置 = HDFS集群配置 + MapReduce集群配置 + Yarn集群配置
HDFS集群配置
1. 将JDK路径明确配置给HDFS(修改hadoop-env.sh)
2. 指定NameNode节点以及数据存储目录(修改core-site.xml)
3. 指定SecondaryNameNode节点(修改hdfs-site.xml)
4. 指定DataNode从节点(修改workers文件,每个节点配置信息占一行) MapReduce集群配置
1. 将JDK路径明确配置给MapReduce(修改mapred-env.sh)
2. 指定MapReduce计算框架运行Yarn资源调度框架(修改mapred-site.xml)
Yarn集群配置
1. 将JDK路径明确配置给Yarn(修改yarn-env.sh)
2. 指定ResourceManager老大节点所在计算机节点(修改yarn-site.xml)
3. 指定NodeManager节点(会通过workers文件内容确定)
修改hadoop-env.sh,放开注释改成jdk安装的路径
cd /home/servers/hadoop-3.3.1/etc/hadoop
vim hadoop-env.sh
修改core-site.xml,在文件的configrue标签内加入以下内容
hadoop.tmp.dir
/home/hadoop/tmp
Abase for other temporary directories.
fs.default.name
hdfs://cdh1:9000

修改hdfs-site.xml文件,在文件的configrue标签内加入以下内容
dfs.name.dir
/home/hadoop/dfs/name
Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
dfs.data.dir
/home/hadoop/dfs/data
Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.
dfs.namenode.secondary.http-address
cdh3:50090
dfs.namenode.servicerpc-address
cdh1:8022
dfs.https.address
cdh1:50470
dfs.https.port
50470
dfs.namenode.http-address
cdh1:50070
dfs.replication
2
修改workers文件加入节点信息,每个节点占一行
cdh1
cdh2
cdh3
修改mapred-env.sh文件,在文件末尾添加JDK路径
export JAVA_HOME=/usr/local/jdk1.8.0_291
修改mapred-site.xml文件,在文件的configrue标签内加入以下内容
mapred.job.tracker
cdh1:49001
mapred.local.dir
/home/hadoop/var
mapreduce.framework.name
yarn
修改yarn-env.sh,,在文件末尾添加JDK路径
export JAVA_HOME=/usr/local/jdk1.8.0_291修改yarn-site.xml,在文件的configrue标签内加入以下内容
yarn.resourcemanager.hostname
cdh1
The address of the applications manager interface in the RM.
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
The address of the scheduler interface.
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
The http address of the RM web application.
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
The https adddress of the RM web application.
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
The address of the RM admin interface.
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.scheduler.maximum-allocation-mb
1024
每个节点可用内存,单位MB,默认8182MB
yarn.nodemanager.vmem-pmem-ratio
2.1
yarn.nodemanager.resource.memory-mb
1024
yarn.nodemanager.vmem-check-enabled
false
修改start-dfs.sh,stop-dfs.sh文件,在文件头部添加以下配置
cd /home/servers/hadoop-3.3.1/sbin/
vim start-dfs.sh 和 vim stop-dfs.sh
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
修改start-yarn.sh,stop-yarn.sh文件,在文件头部添加以下配置
vim start-yarn.sh 和 vim stop-yarn.sh
RN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
YARN_RESOURCEMANAGER_USER=root四、分发配置,
4.1、使用rsync分发配置到其他服务器
cd /home
rsync -rvl hadoop root@cdh2:/home/
rsync -rvl hadoop root@cdh3:/home/
cd /home/service
rsync -rvl hadoop-3.3.1 root@cdh2:/home/servers/
rsync -rvl hadoop-3.3.1 root@cdh3:/home/servers/
rsync /etc/profile root@cdh2:/etc/profile
rsync /etc/profile root@cdh3:/etc/profile4.2、所有服务器执行以下命令,使环境变量生效
source /etc/profile五、启动服务
5.1、hadoop初始化(只需在主服务器执行即可(NameNode节点))
cd /home/servers/hadoop-3.3.4/bin
./hadoop namenode -format有提示以下这行,说明格式化成功
common.Storage: Storage directory /home/hadoop/dfs/name has been successfully formatted
5.2、启动hadoop
cd /home/servers/hadoop-3.3.1/sbin/
./start-all.sh启动没报错即可
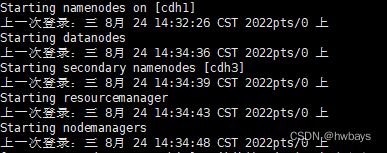
5.3使用jps查看服务
