大数据之Hadoop集群搭建(4个节点)
大数据必备–搭建Hadoop集群(4个节点)
初学大数据肯定第一步先搭建hadoop集群,虽然不知道怎么用,但是先搭建集群是你大数据学习之旅的第一步,操作步骤有以下这几步,用的centos系统
- 对四台虚拟机进网络和静态IP设置
- Hadoop、jdk的安装
- 创建hadoop文件目录
- 导入jdk和hadoop的环境变量
- 修改hadoop配置文件
- 修改虚拟机主机名
- 绑定hostname与ip地址
- 关闭防火墙
- 配置节点之间的免密登录
- 格式化HDFS文件系统
- 启动HDFS文件系统
完成以上步骤就算搭建成功,当然有很多教程说要先配置主机名等等,本教程将配置主机名、实现节点之间的免密登录放到了靠后的位置,初学者不要对此有疑惑,结果都是一样的
以上步骤从第一步(对四台虚拟机进网络和静态IP设置)到第八步(关闭防火墙)在每个节点上都需要操作一遍
1.对四台虚拟机进网络和静态IP设置
所有对虚拟机进行的命令操作建议在xshell中进行,比较方便,可以同时操作多个窗口

本文章不提供xshell安装包,因为xshell并不是必须的
使用下面的命令
[roo@localhost local]$ cd /etc/sysconfig/network-scripts/
[roo@localhost network-scripts]$ vi ifcfg-ens33
删除该文本原来的内容,添加如下内容
TYPE=Ethernet
OXY_METHOD="none"
BROWSER_ONLY=no
BOOTPROTO="static"
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=56ae74d7-3cff-41bb-a86e-707762cb5826
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.5.128
PREFIX=24
IPV6_PRIVACY=no
GATEWAY=192.168.5.0
NETMASK=255.255.255.0
DNS1=114.114.114.114
里面的GATEWAY=192.168.5.0是自己设置的,我设置的是192.168.5.0,在添加文本文件前先在虚拟机中修改

子网ip192.268.5.0中的5是随机的,尽量写大于2的数
文本里面的IPADDR=192.168.5.128是设置你现在操作的节点的ip地址,中的5是保证跟你刚刚设置的子网ip在同一个网段下,后面的128是我随机写的,写成什么都可
重启网络服务
[root@localhost network-scripts]# service network restart
重启虚拟机
[root@localhost network-scripts]#reboot
查看该节点当前ip
[root@localhost]# ifconfig
有如下结果

用以上方法将每个节点的网络配置文件都修改一下

2.Hadoop、jdk的安装
首先将/usr/local/下的所有内容删除,使用如下命令
[root@localhost ~]# rm -rf /usr/local/*
[root@localhost ~]# ls -l /usr/local/
总用量 0
将jdk安装压缩包上传到各个节点,将hadoop安装压缩包上传到各个节点;如果用的xshell工具,直接拖住要传过去的压缩文件到命令框(拖过去之前现在命令框中打开要传入的目录)就可以了,结果就是压缩包到了命令框中打开的相应的文件;当然如果直接用的Vmware也可以拖到桌面上,但是要清楚直接拖过去的话该压缩包文件是传到了桌面文件(可能叫做Desktop)下;
本文章是直接用的xshell拖过去的
网盘链接(提供hadoop、jdk1.8安装包)
链接:https://pan.baidu.com/s/1ssitRxLFs1eNJjSmVB-Jpg
提取码:j9mv
解压安装文件
[root@localhost ~]#cd /usr/local ----到指定存放压缩包的目录,hadoop、jdk压缩包和解压后的文件都存放在了这里
[root@localhost local]# tar -zxvf jdk-8u181-linux-x64.tar.gz
[root@localhost local]# tar -zxvf hadoop-2.8.5.tar.gz
对解压后的文件更改名字
[root@localhost local]# mv hadoop-2.8.5 hadoop2.8.5
[root@localhost local]# mv jdk1.8.0_181 jdk1.8
3.创建hadoop文件目录
[root@localhost ~]# cd /usr/local/hadoop2.8.5 --进入hadoop文件目录下
[root@localhost hadoop2.8.5]# mkdir ./hdfs --以下文件都是后期在配置文件中写到、用到的文件,对后面的代码不要产生疑惑
[root@localhost hadoop2.8.5]# mkdir ./hdfs/name
[root@localhost hadoop2.8.5]# mkdir ./hdfs/data
[root@localhost hadoop2.8.5]# mkdir ./logs
[root@localhost hadoop2.8.5]# mkdir ./tmp
4.导入jdk和hadoop的环境变量
执行如下命令
[root@localhost hadoop2.8.5]# cd /etc/
[root@localhost etc]# vi profile
在文本文件中添加如下内容
export JAVA_HOME=/usr/local/jdk1.8
export HADOOP_HOME=/usr/local/hadoop2.8.5
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=.:$JAVA_HOME/bin:$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_LOG_DIR=/usr/local/hadoop2.8.5/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
使文本配置信息生效
[root@localhost etc]# source profile
检测jdk环境、hadoop环境是否成功
[root@localhost etc]# java -version --jdk环境显示结果如下
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
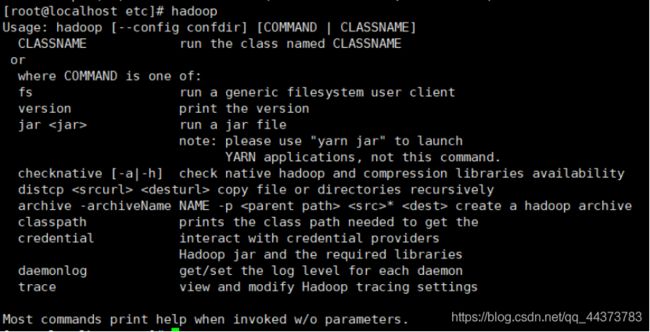
[root@localhost etc]# hadoop --测试hadoop结果如下
5.修改hadoop配置文件

[root@localhost ~]# cd /usr/local/hadoop2.8.5/etc/hadoop/ -----进入配置文件目录
[root@localhost hadoop]# vi hadoop-env.sh
添加或者修改为如下内容:export JAVA_HOME=/usr/local/jdk1.8
(看见文本中带#开头的,作用都类似于注释,是不起任何作用的)
[root@localhost hadoop]# vi yarn-env.sh
添加或者修改为如下内容:export JAVA_HOME=/usr/local/jdk1.8
[root@localhost hadoop]# vi mapred-env.sh
添加或者修改为如下内容:export JAVA_HOME=/usr/local/jdk1.8
[root@localhost hadoop]# vi slaves --配置所有的datanode的节点,里面写的主机名,写的是什么主机名,在后期修改节点主机名的时候记得和该配置文件中相照应
在文件中写入一下内容:(我这里面的hadoop2、3、4是我起的主机名)
hadoop2
hadoop3
hadoop4
[root@localhost hadoop]# vi core-site.xml
添加如下代码:
fs.defaultFS
hdfs://hadoop1:9000/
设定namenode的主机名及端口
hadoop.tmp.dir
/usr/local/hadoop2.8.5/tmp/hadoop-${user.name}
存储临时文件的目录
hadoop.proxyuser.hadoop.hosts
*
hadoop.proxyuser.hadoop.groups
*
[root@localhost hadoop]# vi hdfs-site.xml
添加如下内容:
dfs.namenode.http-address
hadoop1:50070
NameNode地址和端口号
dfs.namenode.secondary.http-address
hadoop2:50090
SecondNameNode地址和端口号
dfs.replication
3
设定HDFS存储文件的副本个数,默认为3
dfs.namenode.name.dir
file:///usr/local/hadoop2.8.5/hdfs/name
namenode用来持续存储命令空间和交换日志的本地文件系统路径
dfs.datanode.data.dir
file:///usr/local/hadoop2.8.5/hdfs/data
DataNode在本地存储块文件的目录列表
dfs.namenode.checkpoint.dir
file:///usr/local/hadoop2.8.5/hdfs/namesecondary
设置secondarynamenode存储临时镜像的本地文件系统路径
dfs.webhdfs.enabled
true
是否允许网页浏览HDFS文件
dfs.stream-buffer-size
131072
默认是4kb,作为Hadoop缓冲区,用于Hadoop读HDFS的文件和写HDFS的文件,还有map的输出都用到了这个缓冲区容量,对于现在的硬件,可以设置为128kb(131072)
mapreduce.framework.name
yarn
Execution framework set to Hadoop YARN.
[root@localhost hadoop]# vi yarn-site.xml
添加如下内容:
yarn.resourcemanager.hostname
hadoop1
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanage.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
hadoop1:8032
yarn.resourcemanager.schduler.address
hadoop1:8030
yarn.resourcemanager.resource-tracker.address
hadoop1:8031
yarn.resourcemanager.admin.address
hadoop1:8033
yarn.resourcemanager.webapp.address
hadoop1:8088
[root@localhost hadoop]# vi mapred-site.xml.template
添加如下内容:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop1:10020
mapreduce.jobhistory.webapp.address
hadoop1:19888
6.修改虚拟机主机名
1).使用命令 hostname查看当前主机名,如下,

2).修改 /etc/hostname文件,该文件中储存着主机名。使用 vi /etc/hostname 命令,修改该文件,删除原有主机名,设置新的主机名。(4台虚拟机都给改一下)重启后设置生效,如下所示
[root@hadoop1 ~]# vi /etc/hostname
写入你设置的主机名,我四个节点的主机名分别为hadoop1,hadoop2,hadoop3,hadoop4
(之前的配置文件中写的是什么这里就写什么,相互照应)
重启虚拟机,查看此时的虚拟机主机名,该图查看的是hadoop1的主机名

7.绑定hostname与ip地址
[root@hadoop1 ~]# vi /etc/hosts
删除文本文件中所有内容,改为如下内容:
192.168.5.128 hadoop1
192.168.5.129 hadoop2
192.168.5.130 hadoop3
192.168.5.131 hadoop4

8.关闭防火墙
使用如下命令查看防火墙状态
[root@hadoop1 ~]# firewall-cmd --state
running
关闭防火墙使用如下命令
[root@hadoop1 ~]# systemctl stop firewalld.service
再次查看防火墙状态
[root@hadoop1 ~]# firewall-cmd --state
not running
关闭防火墙自启
[root@hadoop1 ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
-------------------------------------------------------------------------------------以上所有步骤在所有节点上都执行一遍
9.配置节点之间的免密登录
1).生成密匙,使用命令 ssh-keygen -t rsa
一路回车确定,运行结束后会在用户目录下生成 .ssh 文件夹。
比如使用root用户进行操作,在/root下生成 .ssh 文件夹。

2).进入 .ssh 文件夹,查看有两个文件,id_rsa.pub(公钥)和id_rsa (私钥)
[root@hadoop1 ~]# cd ./.ssh
[root@hadoop1 .ssh]# ls -l
总用量 8
-rw-------. 1 root root 1679 10月 15 10:04
id_rsa-rw-r--r--. 1 root root 394 10月 15 10:04 id_rsa.pub
3).在此目录下,使用命令 cat id_rsa.pub >> authorized_keys 命令,将公钥复制到文件authorized_keys(该文件缺省时自动生成)。完成后修改authorized_keys文件的权限,使用命令chmod 600 authorized_keys
[root@hadoop1 .ssh]# cat id_rsa.pub >> authorized_keys
[root@hadoop1 .ssh]# chmod 600 authorized_keys
4).使用ssh登录本机进行测试(看是否让输入密码)
[root@hadoop1 .ssh]# ssh localhost
The authenticity of host 'localhost (::1%1)' can't be established.
ECDSA key fingerprint is SHA256:yu4JGz3hIB7+FFpD5u/5XdPdrUmQSgtGhaJ/SJC/8/I.
ECDSA key fingerprint is MD5:6a:e0:c0:dd:e7:07:98:8d:5e:79:3d:31:c6:b9:26:c3.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Last login: Tue Oct 15 09:56:59 2019 from 192.168.5.1
[root@hadoop1 ~]# exit
登出
Connection to localhost closed.
1)—4)步骤每个节点都执行一次,每个节点都有自己的密钥
5).在每个节点都有自己的密钥后,将所有用户的公钥都复制到某个远程主机上(本例中都复制到hadoop2节点上)。在其余主机上都使用命令ssh-copy-id 命令,将自己的authorized_keys文件内容复制到hadoop2节点的authorized_keys文件中.
[root@hadoop3 .ssh]# ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop2
若出现找不到hadoop2的地址相关报错,像这样

将hadoop2改成hadoop2的ip地址即可
像这样
涂黄的两句话为现在可以在hadoop3节点上试一下ssh hadoop2看看能否成功
比如将hadoop1的密钥传给hadoop2,则在hadoop1上可以用ssh hadoop2登陆hadoop2节点

执行完如上操作,hadoop1、hadoop3、hadoop4的密钥都传到了hadoop2上,可以查看一下
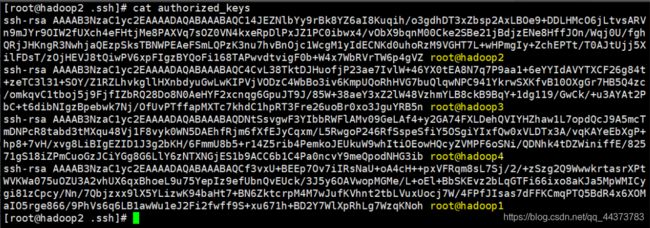
现在只需要将hadoop2中的authorized_keys文件复制到其余的远程主机上即可。在hadoop2节点上分别执行下面的命令,将文件复制到其余3个节点上
分别将文件传到除hadoop2之外的所有节点上**
[root@hadoop2 .ssh]# scp /root/.ssh/authorized_keys hadoop1:/root/.ssh/
[root@hadoop2 .ssh]# scp /root/.ssh/authorized_keys hadoop3:/root/.ssh/
[root@hadoop2 .ssh]# scp /root/.ssh/authorized_keys hadoop4:/root/.ssh/
如下图显示的是将hadoop2的authorized_keys粘贴复制到hadoop1(192.168.5.128)上,写主机名不行的话,还是写ip地址
在各个节点上进行免密登录验证,确保每个节点能登录到其余所有节点,分别执行下面的命令,看是否成功
ssh hadoop1
ssh hadoop2
ssh hadoop3
ssh hadoop4
10.格式化HDFS系统
因为本实验中将hadoop1作为namenode节点,所以对HDFS的格式化在hadoop1上进行。执行下面的命令
[root@hadoopnode1 .ssh]# hdfs namenode -format
11.启动HDFS文件系统
[root@hadoopnode1 ~]# start-all.sh --在namenode主节点上执行该操作
分别在各个节点使用jps命令,查看运行状态

仔细核对,确保jps内容的完整
关闭集群
停止HDFS文件系统
[root@hadoopnode1 ~]# stop-all.sh