【Python】内存管理和random模块

文章目录
-
-
- 1.python内存管理
-
- 1.1内存管理概念
- 1.2内存碎片化解决方式
- 1.3引用计数问题
- 2.随机数random模块
-
1.python内存管理
1.1内存管理概念
-
python是一种动态语言,在变量声明的时候不需要指定类型。
-
变量无需事先声明,也不需要指定类型,这是动态语言的特征
-
变量只是一个标识符,指向一个对象,而这个对象被创建在内存"堆"中
-
python满足写时拷贝的原则,即使用引用记录所有对象的引用数。
- 当对象引用数变为0,它就可以被被垃圾回收,GC
-
计算增加
- 赋值给其他变量就增加引用计算:x=2,y=x
- 实参传参,foo(y)【生成一个临时拷贝的变量】;
-
计算减少
- 函数运行结束,局部变量出作用域,对象引用计算减少
- 变量被被其他值赋值
1.2内存碎片化解决方式
-
对于动态编译的语言(C/C++),随意的申请内存而不销毁,就会出现大量的碎片内存,影响内存的使用。【C/C++可以使用池化技术解决内存碎片化的问题】
-
python依靠虚拟机的垃圾回收机制【引用计数】解决内存碎片化解决方式
-
缺点:动态语言的GC机制【在回收的时候,发生了世界停止】在实现高并发的时候效率太低。
1.3引用计数问题
引用计数是简单实现垃圾标记的方法。
引用计数可能出现循环引用,Python提供了gc模块,解决了循引用问题。
sys.getrefcount(x)查看x的计数量
现象1
import sys
import gc
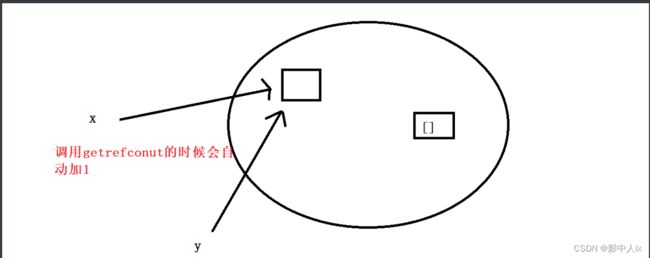
x=[] #在堆创建一个空列表,记录的是x的地址
sys.getrefcount(x) 【调用函数,作用是查看x的计数量】,函数调用完自动减1
输出:2 【实参传参也需要计数量+1】
y=x
sys.getrefcount(x)
输出:3
sys.getrefcount([]) #结果是1
为什么结果是1?
实际上[]的引用计数为0,调用函数时加1【此过程和x没有任何关系】
现象2
a=1
sys.getrefcount(a)
引用计数为:至少为2【比如1471】
b=a
sys.getrefcount(a)
引用计数为1472
原因:
字面常量:数值,字符串,属于常量。
常量的处理方式不同:一旦创建就不允许改动。【甚至Python中的编译器也会引用a创建的字面常量】
2.随机数random模块
- randint(a,b)返回[a,b]之间的整数
- randrange([start],stop,[,step])从指定范围内(start,stop)【开区间】,按指定基数step递增的集合获取一个随机数,基数step的缺省值为1
random.randrange(1,7,2)
在【1,3,5,7】中获取一个随机数
- choice(seq)从非空序列的元素随机挑选一个元素
random.choice(range(10)),从0到9随机挑选一个整数
random.choice([1,3,5,7])在[1,3,5,7]中随机挑选一个整数
- 3.6版本提供choices,一次获取一个或者多个数,可以自定义权重
random.choices(population,weights=None,*,cum_weights=None,k=1)
population:权重
weights:相对权重
cum_weights:累加权重
k:选取次数
import random
a = [1,2,3,4,5]
print(random.choices(a,k=6))
解析:重复6次从列表a中的各个成员中选取一个数输出,各个成员出现概率基本持平。
结果:[4, 5, 1, 4, 5, 4](随机生成的)
print(random.choices(a,weights=[0,0,1,0,0],k=6))
相对权重:权重分别为0,0,1,0,0
解析:重复6次从列表a中提取3,最终得到[3, 3, 3, 3, 3, 3]
结果:[3, 3, 3, 3, 3, 3](固定结果)
print(random.choices(a,weights=[1,1,1,1,1],k=6))
解析:重复6次从列表a中的各个成员中选取一个数输出,各个成员出现概率基本持平。
结果:[4, 3, 2, 1, 5, 1](随机生成的)
print(random.choices(a,cum_weights=[1,1,1,1,1],k=6))
累加权重,第一个元素的权重为1,后面的权重依次为0
print(random.choices(a,cum_weights=[1,3,5,8,11],k=6))
结果:[1, 5, 2, 4, 5, 3]
解释:第一个元素的权重为1
第二个元素的权重为2 :1+2=3
第三个元素的权重为2:3+2=5
第四个元素的权重为3: 5+3=8
......
- random.shuffle(x)打乱一个列表的元素顺序,且在原列表基础上打乱,不会生成新的列表。
l=list(range(0,12))
random.shuffle(l)
print(l)
输出:[1, 0, 7, 5, 9, 11, 2, 3, 4, 10, 8, 6]
- random.seed(a=None,version=2)设置随机种子
random.seed()俗称为随机数种子。不设置随机数种子,你每次随机抽样得到的数据都是不一样的。设置了随机数种子,能够确保每次抽样的结果一样。而random.seed()括号里的数字,相当于一把钥匙,对应一扇门,同样的数值能够使得抽样的结果一致
l1=[]
l2=[]
for i in range(3):
for i in range(5):
l1.append(random.random())
print(l1)
l1=[]
for i in range(3):
random.seed(10)
for i in range(5):
l2.append(random.random())
print(l2)
l2=[]
[0.05734131187693592, 0.16011001087611865, 0.005653631020471894, 0.8164063355610603, 0.8798805481650455]
[0.6537519294905624, 0.12491155732110881, 0.3178830154059781, 0.5727865170907682, 0.3906896577924317]
[0.053825543614678284, 0.9987578005217228, 0.9258901979978362, 0.645989538241693, 0.15997608340867353]
设置随机数种子:每次结果都为固定值。
[0.5714025946899135, 0.4288890546751146, 0.5780913011344704, 0.20609823213950174, 0.81332125135732]
[0.5714025946899135, 0.4288890546751146, 0.5780913011344704, 0.20609823213950174, 0.81332125135732]
[0.5714025946899135, 0.4288890546751146, 0.5780913011344704, 0.20609823213950174, 0.81332125135732]
- random.sample(list,k)从list样本或集合中随机抽取K个不重复的元素形成新的序列
- 注意:random.sample()返回的是一个新的序列,不会破坏原有序列。random.sample()是不重复不放回的抽取,不会出现重复抽取的情况,所以random.sample()的k值不能超出序列的元素个数。
- 抽取的是不同索引的元素,每次抽取,一个索引位置的元素不会再被抽取
list:样本集合
k:抽取次数
print("从0~10抽取3个数字:",random.sample(range(10), k=3))
输出:从0~10抽取3个数字: [1, 8, 2]
L = [0,1,2,3,4,5]
print("从列表L中抽取2个数字:",random.sample(L,2))
从列表L中抽取2个数字: [2, 0]
print(random.sample(['a','a'],2))
输出:['a', 'a']