HTTP长连接
好久没有写网络相关的文章了。正好这两天和同事聊长连接,所以把这方面的内容进行梳理。里面会涉及TCP性能优化和HTTP2.0基础教程的内容,大家有时间可以看一下。
一、长连接优点
HTTP为什么要开启长连接呢?主要是为了节省建立TCP的时间,请求可以复用同一条信道。
如果没有长连接,每次请求都做一次三次握手和四次挥手。
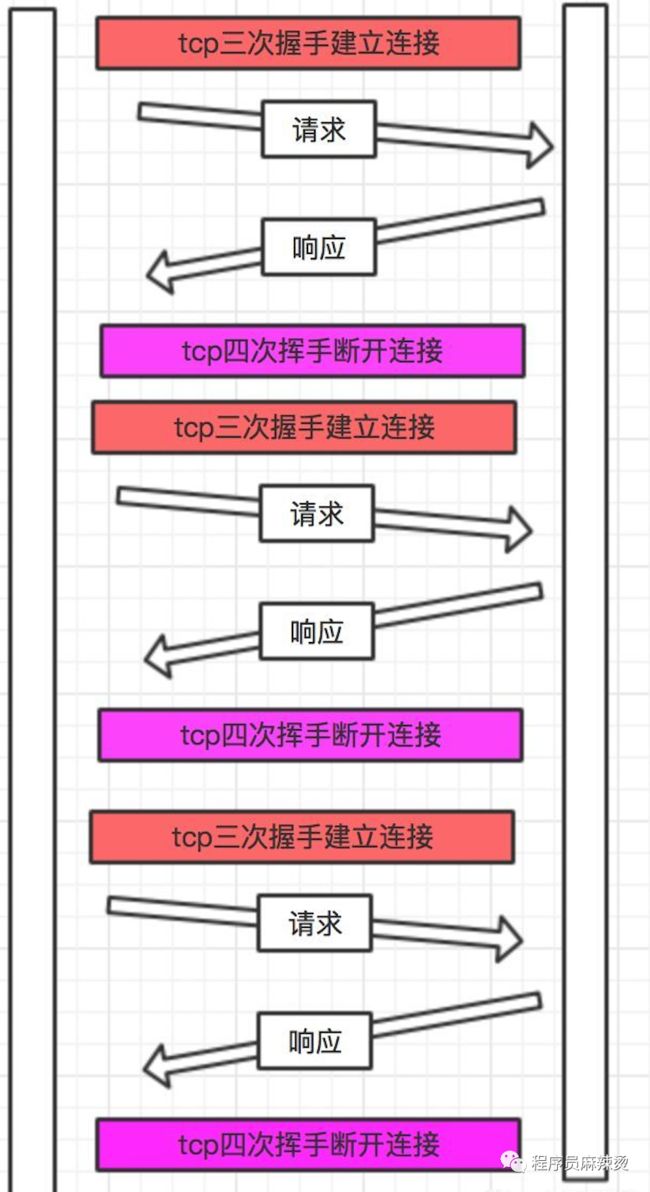
如果有长链接,在一个 TCP 连接中可以持续发送多份数据而不会断开连接,即请求可以复用这个通道。
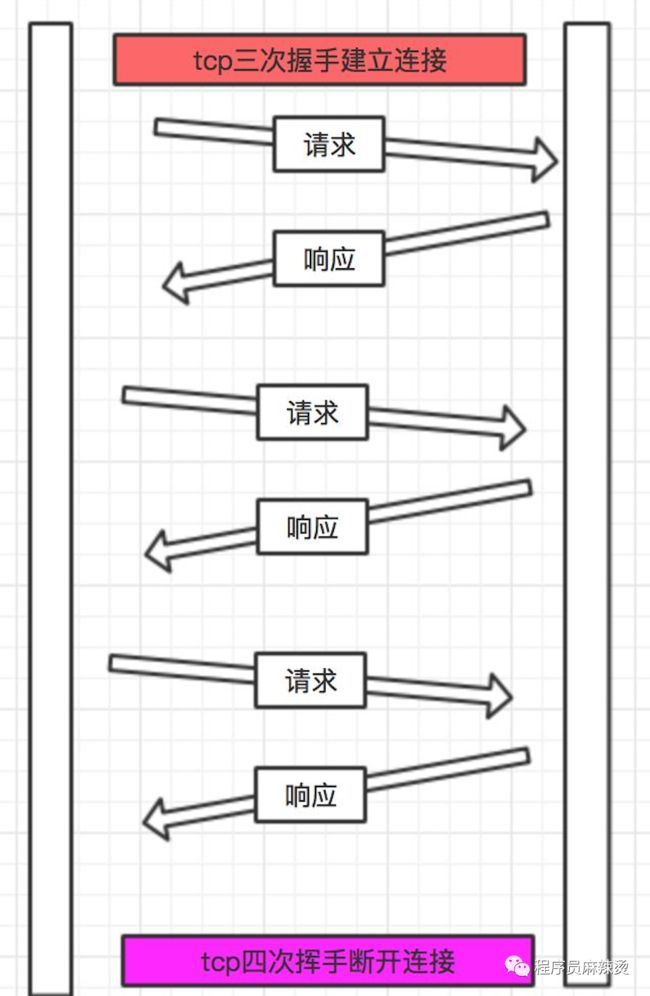
二、长连接缺点
但长连接不是万能的,它存在队头阻塞问题。
队头阻塞
如果仅仅使用一个连接,它需要发起请求、等待响应,之后才能发起下一个请求。在请求应答过程中,如果出现任何状况,剩下所有的工作都会被阻塞在那次请求应答之后。这就是“队头阻塞”,它会阻碍网络传输和Web页面渲染,直至失去响应。为了防止这种问题,现代浏览器会针对单个域名开启6个连接,通过各个连接分别发送请求。它实现了某种程度上的并行,但是每个连接仍会受到“队头阻塞”的影响。
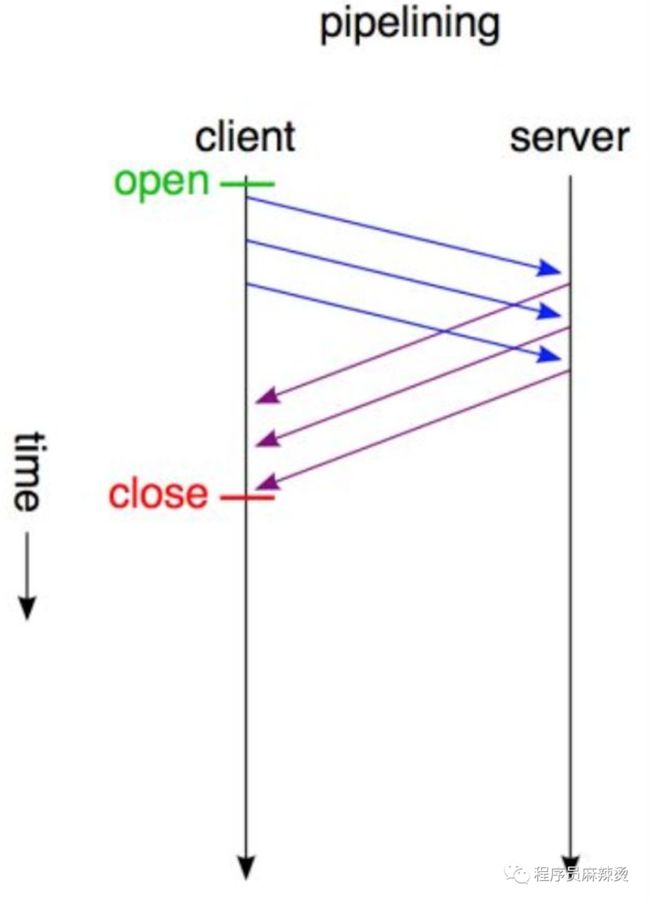
pipline
为解决队头阻塞这个问题,提出了pipline方案。虽然在一个tcp通道中实现了多个http并发,但因为该方案有缺陷,大部分浏览器默认是关闭pipeline的。
其一是因为返回的时候是会阻塞的,谁先到达,谁先返回,顺序绝对不能乱。另一个pipeline限制是,只能是幂等请求(get、head等)才能应用pipeline,
三、HTTP开启长连接
前端
开启HTTP长连接,对前端很简单,方式如下:
| 协议 | 开启 | 关闭 |
|---|---|---|
| HTTP1.0 | Connection: keep-alive | 默认 |
| HTTP1.1 | 默认 | Connection: close |
服务端
Keep-Alive能够实现,需要服务端支持:
Httpd守护进程,如nginx需要设置keepalive_timeout
这个 keepalive_timout时间值意味着:一个http产生的tcp连接在传送完最后一个响应后,还需要hold住 keepalive_timeout秒后,才开始关闭这个连接。
-
keepalive_timeout=0:建立tcp连接 + 传送http请求 + 执行时间 + 传送http响应 + 关闭tcp连接 + 2MSL
-
keepalive_timeout>0:建立tcp连接 + (最后一个响应时间 – 第一个请求时间) + 关闭tcp连接 + 2MSL
TCP的Keep-Alive
HTTP的Keep-Alive需要和TCP的Keep-Alive区分开
TCP自身也有Keep-Alive,是检测TCP连接状况的保鲜机制
-
net.ipv4.tcpkeepalivetime:表示TCP链接在多少秒之后没有数据报文传输启动探测报文
-
net.ipv4.tcpkeepaliveintvl:前一个探测报文和后一个探测报文之间的时间间隔
-
net.ipv4.tcpkeepaliveprobes:探测的次数
逻辑为:tcpkeepalivetime时间没有数据则开始探测,每过tcpkeepaliveintvl探测一次,最多探测tcpkeepaliveprobes次,如果全部失败则关闭TCP连接。
这部分内容一般不需要关注。
四、长连接演练
talk is cheap, show me the code.
我们抓包看看是否真是这样的。
配置
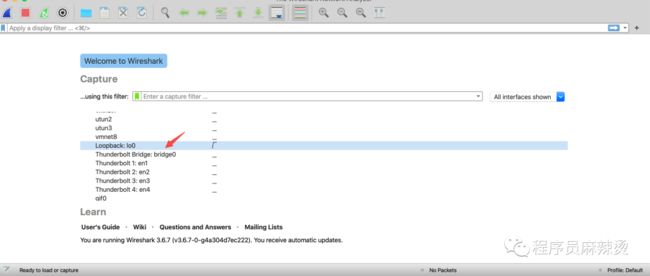
抓包软件:wireshark mac
Client语言:go
Server语言:go
双击,只监听本机请求

服务端代码
服务端默认是开启keep-alive的,可以通过SetKeepAlivesEnabled进行关闭。
package mainimport ( "fmt"
"net/http"
"strings"
"time")func main() {
server := http.Server{
Addr: ":8081",
IdleTimeout: time.Second * 30,
Handler: http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { if strings.Index(r.URL.String(), "test") > 0 {
fmt.Fprintf(w, "这是net/http创建的server第一种方式")
fmt.Println("hello ") return
}
fmt.Println("world") return
}),
} //是否开启长连接
server.SetKeepAlivesEnabled(true)
server.ListenAndServe()
}
客户端不使用长连接
/**
@author: Jason Pang
@desc:
@date: 2022/9/3
**/package mainimport ( "fmt"
"io/ioutil"
"net/http"
"time")func doGet(client *http.Client, url string, id int) {
resp, err := client.Get(url) if err != nil {
fmt.Println(err) return
}
buf, err := ioutil.ReadAll(resp.Body)
fmt.Printf("%d: %s -- %v\n", id, string(buf), err) if err := resp.Body.Close(); err != nil {
fmt.Println(err)
}
}func main() {
transport := &http.Transport{
DisableKeepAlives: true,
MaxIdleConnsPerHost: 1,
}
client := http.Client{
Transport: transport,
} const URL = "http://192.168.199.152:8081/test"
for { go doGet(&client, URL, 1) //go doGet(&client, URL, 2)
time.Sleep(2 * time.Second)
}
}
可以看到执行了三次,每次都进行TCP三次握手和四次挥手,端口每次都变。
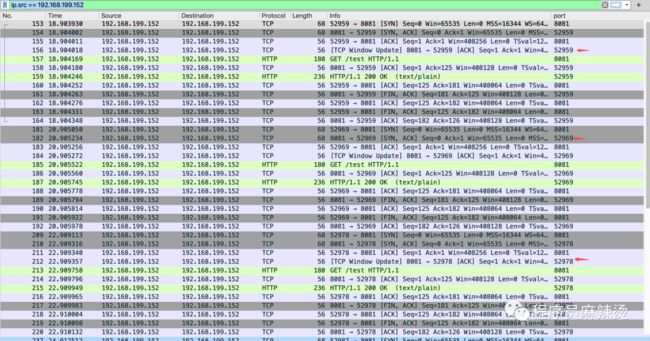
客户端使用长连接
/**
@author: Jason Pang
@desc:
@date: 2022/9/3
**/package mainimport ( "fmt"
"io/ioutil"
"net/http"
"time")func doGet(client *http.Client, url string, id int) {
resp, err := client.Get(url) if err != nil {
fmt.Println(err) return
}
buf, err := ioutil.ReadAll(resp.Body)
fmt.Printf("%d: %s -- %v\n", id, string(buf), err) if err := resp.Body.Close(); err != nil {
fmt.Println(err)
}
}func main() {
transport := &http.Transport{
DisableKeepAlives: false,
MaxIdleConnsPerHost: 1,
}
client := http.Client{
Transport: transport,
} const URL = "http://192.168.199.152:8081/test"
for { go doGet(&client, URL, 1) //go doGet(&client, URL, 2)
time.Sleep(2 * time.Second)
}
}
每次请求全是同一个端口,而且只进行了一次三次握手。
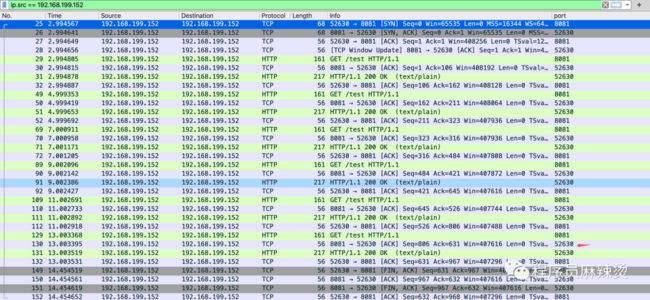
Go的client有个知识点需要说明:
-
它默认会维持两个长连接,所以如果起两个goroutine,会对应两个长连接被不断复用
-
长连接返回的数据需要读取后才能被复用,否则go不知道怎么处理未读取数据的连接,大概率就给close了
五、HTTP2.0
要真正解决队头阻塞问题,肯定不是缝缝补补,这就有了HTTP2.0基础教程。
HTTP/2是完全多路复用的,而非有序并阻塞的
-
只需一个连接即可实现并行
-
提升TCP连接的利用率
多路复用(Multiplexing):一个信道同时传输多路信号。
那它是怎么实现的呢?主要依靠二进制分帧。
HTTP/2 通信都在⼀个tcp连接上完成,这个连接会同时处理多个http的request,http2给每个http的request都分配唯一的streamId,而每个request切割出来的fram都共用这个streamId,这样的话http2就可以基于这个streamid将切割的信息还原,http2通道中同时处理多个request的方式类似处理多个流,所以有些文章会指出http2实现了流方式传递信息。
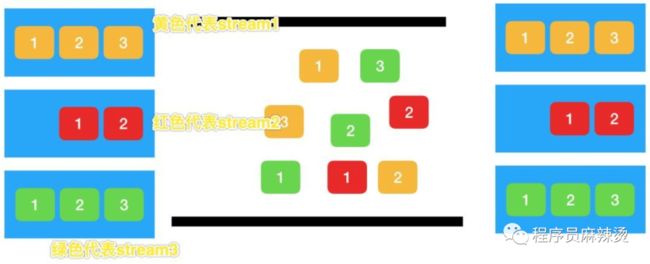
上图中每个大的蓝色方块代表一个http的request,每个request被切割为多个fream,并且被编号,我们用黄红绿三种颜色分别代表三个stream流,不同的颜色代表不同的streamid,http2接收到数据会根据其streamid自动还原数据,这样就实现了在一个TCP连接通道中的流式传输,多个request都会复用这个TCP通道,实现了高效的复用。
六、总结
至此演练了使用HTTP长连接的过程,也讲了和TCP Keep-Alive的区别,同时提供了更好的优化方案。
资料
-
http头之keep-alive
-
HTTP keepalive详解
-
HTTP keep-alive详解
-
nginx的 keepalive_timeout参数是一个请求完成之后还要保持连
-
Nginx中的keepalive配置 详解Nginx中HTTP的keepalive相关配置
-
白话http2的多路复用
-
什么是全双工和半双工
-
全双工与半双工的区别
-
多路复用
-
IO复用
-
彻底理解 IO 多路复用实现机制
-
Http2中的多路复用
-
浅析HTTP/2的多路复用
-
HTTP2 优点
-
http2协议之多路复用
-
单/半双/全双工和多路复用技术概要
-
GoLang里的keep-alive
-
wireshark抓包–127.0.0.1/本地
-
Go HTTP Client 持久连接
最后
往期文章回顾:
-
设计模式
-
招聘
-
思考
-
存储
-
算法系列
-
读书笔记
-
小工具
-
架构
-
网络
-
Go语言