目录:
- 解析 MongoDB 新特性“时序”
- 如何在 MongoDB 中使用时序?
- MongoDB 时序集合性能
- MongoDB 时序 IOT 场景设计
一、解析 MongoDB 新特性“时序”
- MongoDB 时序集合是 MongoDB 5.0 新推出的功能,他能快速将段时间内的数据写入磁盘,并且提供快速时序检索的集合。
- 与普通集合相比,时序集合在数据插入的过程中,自动将数据按照时间维度组织成最优的存储格式,也为后面应用程序对时序数据提高了查询效率。
- MongoDB 传统时序模式:
假设我们有一个传感器每分钟测量温度并将其保存到数据库中,我们需要写入数据库中的数据流:
{_id: ObjectId(), deviceid: 1, date: ISODate ("2019-11-10"), samples : [{ temperature: 10, time: 1573833152},]},
{_id: ObjectId(), deviceid: 1, date: ISODate ("2019-11-10"), samples : [[ temperature: 15, time: 1573833153},]},
{_id: ObjectId(), deviceid: 1, date: ISODate ("2019-11-10"), samples : [[ temperature: 14, time: 1573833154},]},
{_id: ObjectId(), deviceid: 1, date: TSODate("2019-11-10"), samples : [[ temperature: 20, time: 1573833155},]}- 桶模式设计数据模型:
{
_id: objectId(),
deviceid: 1,
date: ISODate ( "2019-11-10") ,
first: 1573833152,
last: 1573833155,
samples : [
{ temperature: 10, time: 1573833152},
{ temperature: 15, time : 1573833153},
{ temperature: 14, time: 1573833154),
{ temperature: 20, time : 1573833155}
]
}字段解释:
- id —文档的ID,这个ID具备唯一性
- deviceld —查询的设备ID
- date—采样日期;我们可以将其存储在此处以简化聚合
- first—存储桶中读取的最旧数据的时间戳
- last—存储桶中读取的最新数据的时间戳
- samples—数据容器
- 用例中桶模式的优势:
- 节省数据和索引的大小
- 简化数据结构
- 可以将需要采集的数据按照时间维度集中在一起,方便快速范围检索
- 提升数据写入速度
二、如何在 MongoDB 种使用时序
- 显示指定创建的集合为时序集合
db.createcollection (
"weather",
{
timeseries: {
timeField: "timestamp",
metaField: "metadata",
granularity: "hours"
}
}字段含义介绍:
- timeField 是时间参数,必须为 BSON data。
- metaField 影响维度基数,好的 metaField 应该选择低基数的,有选择性的指标,高基数必然带来性能的下降
- granularity 是聚合粒度(可选)参数,数据库会将一个时间段的数据聚合存放,这个参数影响性能,不影响功能
- expireAfterSeconds 影响数据的过期,是默认通过每60s一次的检测实现的。过期时间可配置
- CRUD 操作
- 增:单条插入或批量插入集合的方式(跟传统的 collection 没有区别)
- 删(略)
- 改(略)
- 查:
计算时序集合时段平均值(聚合查询):
db.weather.aggregate([
{
project: {
date: {
$dateToParts: { date: "$timestamp" }
},
temp: 1
},
{
$group: {
_id: {
date: {
year : "$date. year",
month: "$date.month",
day : " $date.day"
}
avgTmp: { $avg: "stemp"}
}
])- 注意点:
- 时序集合底层存储依然是 WiredTiger;
- 没有为时序查询定制太多新的语法,各种聚合依然需要通过 aggregate 进行;
- 时序集合已经按照常用的查询模式,对数据进行了存储模型上的优化。在索引上如果有自己的针对 metafield 的过滤需求,可以正常创建二级索引;
- MongoDB时序集合在更新和删除中需要添加指定条件。
- 在当前版本里,时序集合不支持分片(6.0支持分片)。
三、MongoDB 时序集合性能
- 写入性能(4C 8G 128G ssd)
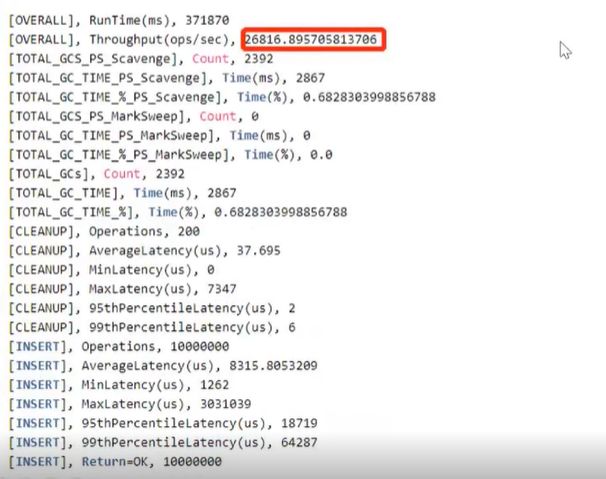
- 读写混合压测性能:
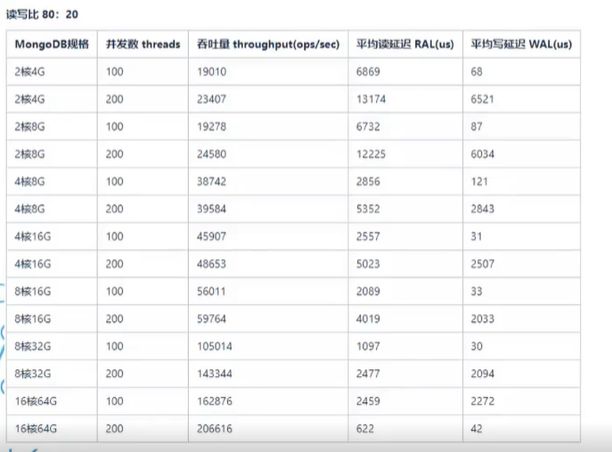
- 磁盘占用:
MongoDB 对数据的压缩支持 snappy、zstd 和 zlib 算法,在以往线上真实的数据空间大小与真实磁盘空间消耗进行对比,可以得出以下结论:
| 压缩算法 | 真实数据量 | 真实磁盘空间消耗 |
|---|---|---|
| snappy 压缩算法 | 3.5T | 1-1.5T |
| zstd 压缩算法 | 3.5T | 0.6-0.9T |
| zlib 压缩算法 | 3.5T | 0.5-0.7T |
Hbase 默认采用的是 snappy 算法,MongoDB 时序集合默认采用 zstd 压缩算法,所以相同数据量,MongoDB 磁盘占用更低。
- MongoDB时序集合使用限制:
- 客户端加密
- ChangeStream
- Relndex 重建索引
- Tiggers
- 更新和删除限制
四、MongoDB时序 IOT 场景设计
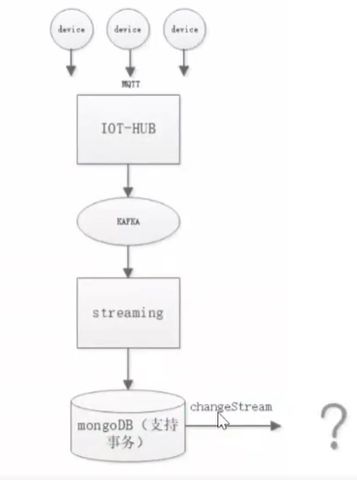
场景需求:
数据质量,实时消费 kafka 数据,并经过流式计算后,需要对数据进行展示,如流程图所示:
- 时序集合
- 读写分离
- ChangeStream 分流查询
- 过期数据清理:
- 可以采用时序集合原生态的TTL索引进行自动过期。
- 可以通过新旧集合替换的方式,对旧集合直接删除的方式。
参考资料: