FactorVAE:基于变分自编码器的动态因子模型

量化投资与机器学习微信公众号,是业内垂直于量化投资、对冲基金、Fintech、人工智能、大数据等领域的主流自媒体。公众号拥有来自公募、私募、券商、期货、银行、保险、高校等行业30W+关注者,荣获2021年度AMMA优秀品牌力、优秀洞察力大奖,连续2年被腾讯云+社区评选为“年度最佳作者”。
量化投资与机器学习公众号 独家解读
量化投资与机器学公众号 QIML Insight——深度研读系列 是公众号全力打造的一档深度、前沿、高水准栏目。

公众号遴选了各大期刊前沿论文,按照理解和提炼的方式为读者呈现每篇论文最精华的部分。QIML希望大家能够读到可以成长的量化文章,愿与你共同进步!
本期遴选论文
标题:FactorVAE: A Probabilistic Dynamic Factor Model Based on Variational Autoencoder for Predicting Cross-sectional Stock Returns
作者:Yitong Duan, Lei Wang, Qizhong Zhang, Jian L
今天分享的文章来自AAAI 2022,四位作者(Yitong Duan, Lei Wang, Qizhong Zhang, Jian Li)都来自清华大学。
本文提出了一种新的基于变分自编码器(VAE)的概率动态因子模型,称为FactorVAE,以弥合噪声数据与有效因子之间的差距。从本质上讲,我们将因子视为潜在随机变量,通过在VAE潜在空间上的分布对数据中的噪声进行建模,然后引入一种前验后验学习方法来指导提取截面收益预测的有效因子。更具体地说,如图1所示,我们首先采用一种编码器-解码器架构,可以访问未来的股票收益,提取最优因子来重建收益,然后训练一个预测器(Predictor),只在给定可观察的历史数据的情况下,预测因子来逼近最优因子。在预测阶段,只使用预测器(Predictor)和解码器(Decoder)以确保不会有任何信息泄漏。还要注意的是,我们的模型是通过带有随机性的因子来计算股票收益的,这衍生出了一个概率模型,用于预测收益之外的风险估计。
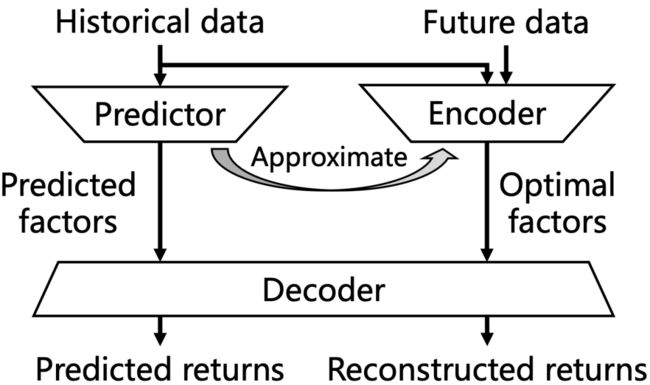
Brief illustration of FactorVAE
本文的主要贡献如下:
提出FactorVAE作为一个动态因子模型,从有噪声的市场数据中提取有效因子,并基于VAE设计了一种前验后验学习方法,进一步指导模型在高噪声市场数据中的学习。
本文是第一个在VAE中将因子作为潜在随机变量来处理的,这增强了对噪声数据建模的能力,并得出了风险估计的概率模型。
本文对真实的股票市场数据进行了大量的实验,结果表明,FactorVAE不仅超过了其他动态因子模型,而且在截面收益预测方面超过其他ML-Based的预测模型。
Variational Autoencoder(VAE)
在介绍FactorVAE模型结构之前,我们先了解一下传统的VAE模型。一个标准的Autoencoder模型由一个encoder和一个decoder组成。其中encoder将输入特征X编码为一个隐含向量z(通常维度更低),而Decoder负责将隐含特征向量z解码为原始特征X。(Autoencoder一般会用在图片压缩中,通过encoder降低存储的大小,利于传输。再使用decoder进行还原)。

标准的Autoencoder存在以下问题,泛化能力很弱,容易过拟合,选择一个随机的潜在变量可能会产生垃圾输出。VAE很好的解决了这些问题,与Autoencoder中encoder从原始特征中学习隐含特征不同的是,VAE从原始特征中学习隐含特征的分布(称之为后验分布,),然后再从这个分布中随机抽样出一个隐含特征 输入到decoder中进行还原。也就是说:
1、标准的Autoencoder中,encoder从原始特征 中学到的隐含特征 ,然后直接将 输入到decoder;
2、VAE中,encoder从原始特征 中学到 的分布(这里需要假定 服从某种分布,比如高斯分布,那encoder的输入就是高斯分布的参数:均值和方差),然后从这个分布 中抽样出 输入到decoder中。
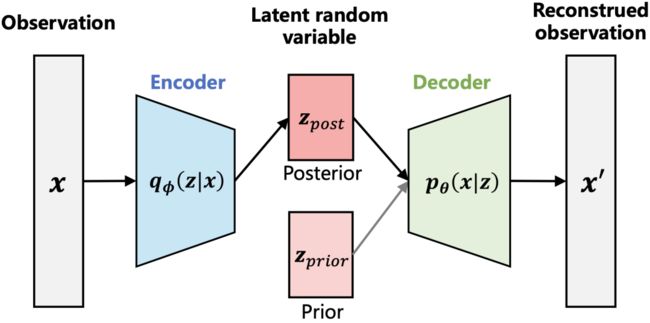
使用以下的损失函数,随着训练的进行,后验分布 就会逼近 的先验分布 。VAE本身是属于生成模型,在需要生成新数据的时候,直接使用 抽样出 ,并输入到decoder中解码出新样本。
402 Payment Required
FactorVAE的模型结构
FactorVAE模型整体上也遵循标准VAE模型的encoder-decoder的结构。但在具体设计上有很多细节,详细的结构如下图所示:
我们首先来看一下模型的损失函数,了解损失函数之后,我们就能更清楚的知道模型各部分在训练过程中扮演的角色。
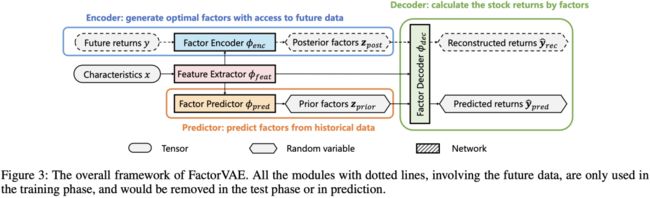
如传统的VAE损失函数一样,第一项是最小化decoder的重构错误(MLE的方法),所以需要知道decoder的概率分布。第二项是最小化encoder学到的z的后验分布与z的先验分布的Kullback–Leibler divergence (KLD)。所以FactorVAE需要以下几个核心模块:
使用encoder学习z的后验分布 ,在假定服从独立高斯分布的情况下,就是学习分布的均值和方差;
使用decoder学习收益率y的后验分布 ,在假定服从独立高斯分布的情况下,就是学习分布的均值和方差;
使用predictor学习z的先验分布,去逼近z的后验分布。
Feature Extractor
首先是Feature Extractor,用于从股票历史因子序列中()提取隐含特征 。本文使用的GRU模型,使用GRU模型最后时间步的隐含状态作为提取后的隐含特征:
Factor Extractor
Factor Encoder()的输入是Feature Extractor的输出 及未来股票截面收益率数据 ,输出为后验高斯分布的均值和标准差:
其中 为一组服从独立高斯分布的向量,均值为 ,方差 。
Factor Encoder( )的详细结构如下图左所示,由于截面中个股数量较大且随时间变化,本文不直接使用股票收益y,而是受(Gu, Kelly, and Xiu 2021)的启发构建了一组投资组合(M个投资组合),这些投资组合收益基于股票潜在特征动态加权计算得到::
其中 表示股票i在组合j中的权重,。
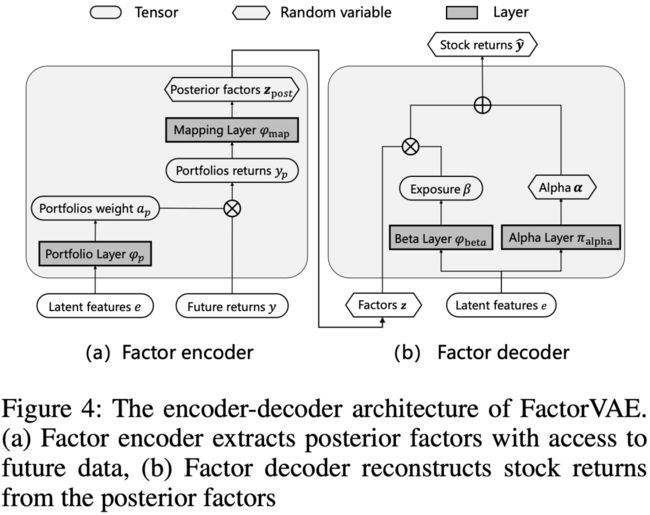
然后使用以下公式计算 和 :
402 Payment Required
402 Payment Required
Factor Decoder
解码器部分的输入是encoder的输出 和Factor Extractor的输出 ,并按因子模型的方式重构股票截面收益:
如上图所示,其中 和 分别通过Alpha layer和Beta layer学习得到。
Alpha layer用于学习股票的特质收益 ,文中假设 服从独立高斯分布:,其中 并通过以下过程学到:
Beta layer:
如前所述,我们的目标是弥合嘈杂的市场数据与预测回报的有效因子模型之间的差距。采用端到端方法训练的模型可能无法从噪声数据中提取出影响因子。因此,我们提出了一种基于VAE的Prior-Posterior Learning学习方法来实现这一目标:训练一个只给出历史观测数据的Factor Predictor,该预测器预测因子以逼近上述最优的后验因子,称为先验因子。然后利用因子decoder在不泄露未来信息的情况下,利用先验因子计算股票收益,作为模型的预测收益。
Factor Predictor
如上所述,Factor Predictor用于逼近后验分布的方式学习 的先验分布,考虑到feature之间的关联性,本文首先使用了多头全局注意力机制提取了 的隐含表征,然后使用上述等式10的方式计算先验分布的均值方差 。
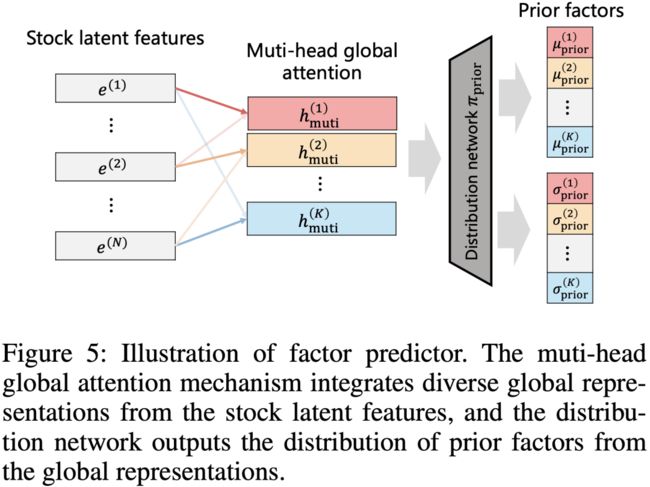
预测阶段
在预测阶段仅使用decoder和predictor,具体流程如下:
402 Payment Required
where
402 Payment Required
本文使用了A股2010年至2020年的日度数据进行了验证,因子使用Qlib Alpha158因子中的20个量价因子,训练时间2010年1月1日至2017年12月31日,验证集2018年1月1日至2018年12月31日,测试集2019年1月1日至2020年12月31日。预测目标月未来第二个收盘价与下一交易日收盘价计算的收益率(t+1与t+2)。
Baseline模型选用了线性因子模型与QLib中已实现的几个模型:GRU、ALSTM、SFM、Trans等。
IC对比
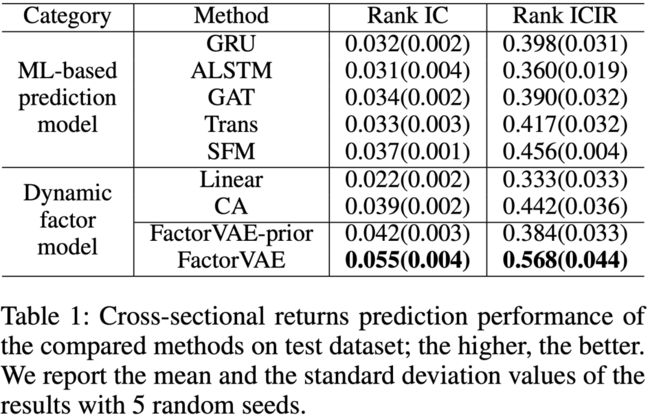
Q1. Prior-Posterior Learning学习方法是否能有效地指导模型的学习?
FactorVAE-prior模型是FactorVAE一种变体,它不包含前验后验学习方法,该方法通过先验因子直接训练来预测收益。从结果中我们可以看到,没有后验因子的引导,很难从真实的市场数据中学习到一个有效的因素模型,这说明前验后验学习方法对我们的模型是至关重要的。
稳健性对比

上表中m表示,训练是随机从样本股票中去除m个股票,测试时使用这m个股票计算IC的结果。
策略表现对比
下图表中,除FactorVAE(TDRisk)以为,均使用QLib内置TopKdropout策略(k=50,n=5)在沪深300成分股内进行测试。
FactorVAE(TDRisk)是TopKdropout策略的变体,主要是在选择前K个股票是不是基于预测的收益率,而是考虑了风险,基于 选择前K个股票。可以看出,该策略相对FactorVAE,夏普比率和收益都有提升。
后记
QIML公众号正在进行FactorVAE的代码实现,请关注后续文章!