『抽丝剥茧』手把手快速上带你开启文心大模型的奇妙冒险
『抽丝剥茧』手把手快速上带你开启文心大模型的奇妙冒险
- 文心大模型简介
- 文心大模型ERNIE 3.0系列&&ERNIE-ViLG文生图系列
-
- 使用文心大模型
-
- 网页快速体验
- 代码调用之ERNIE 3.0系列
-
- 安装文心库
- 代码调用
-
- API Key获取地址
- 参数说明
-
- task_prompt
- 代码调用之ERNIE-ViLG文生图
-
- 安装文心库
- 代码调用
- 参数说明:
- 图片下载
- 图片展示
- 总结
-
- 作者简介
文心大模型简介
随着数据井喷、算法进步和算力突破,效果好、泛化能力强、通用性强的预训练大模型(以下简称“大模型”),成为人工智能发展的关键方向与人工智能产业应用的基础底座。
百度文心大模型源于产业、服务于产业,是产业级知识增强大模型。百度通过大模型与国产深度学习框架融合发展,打造了自主创新的AI底座,大幅降低了AI开发和应用的门槛,满足真实场景中的应用需求,真正发挥大模型驱动AI规模化应用的产业价值。 文心大模型的一大特色是“知识增强”,即引入知识图谱,将数据与知识融合,提升了学习效率及可解释性。
文心ERNIE自2019年诞生至今,在语言理解、文本生成、跨模态语义理解等领域取得多项技术突破,在公开权威语义评测中斩获了十余项世界冠军。 2020年,文心ERNIE荣获世界人工智能大会WAIC最高奖项SAIL奖。
2022年6月,基于文心大模型的度晓晓,写作、绘画、写歌能力密集展示,全国高考作文写作得高分、作画参加西安美术学院毕业展、联合龚俊数字人推出国内首个虚拟偶像 AIGC 创作歌曲。
————上述内容源自百度百科文心大模型
文心大模型ERNIE 3.0系列&&ERNIE-ViLG文生图系列
ERNIE 3.0 系列主要是用于文本处理方向
ERNIE-ViLG文生图系列主要是用于跨模态方向
ERNIE 3.0 系列服务,可以处理几乎所有自然语言理解和生成的任务。提供“零样本”的直接体验功能,例如:写作文、写文案、写摘要、对对联、自由问答、写小说、补全文本等任务,还可以通过提供“小样本”数据进行模型精调,获得您的专属模型。
ERNIE-ViLG文生图系列服务,可以体验通过文本描述来生成相应图片的能力。可以生成水彩,油画,粉笔画,卡通,蜡笔画,儿童画等不同类型的画作/图片
** 跨模态:模态是指数据的存在形式,比如文本、音频、图像、视频等文件格式。同一个事物的存在形式不同,导致检索的时候会出现跨模态检索来实现。
上面的跨模态主要指的是文字转换成图像
使用文心大模型
网页快速体验
ERNIE 3.0系列体验地址:https://wenxin.baidu.com/moduleApi/ernie3
ERNIE-ViLG文生图体验地址:https://wenxin.baidu.com/moduleApi/ernieVilg
- ERNIE 3.0体验展示:
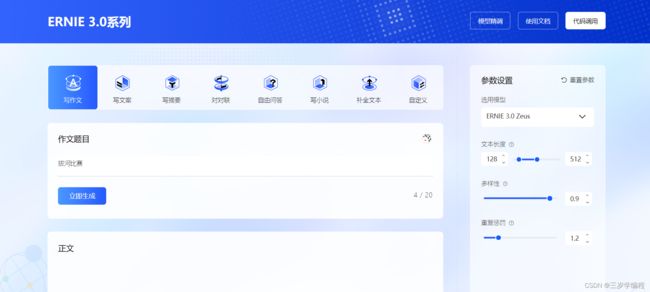
首先选择我们需要的内容(写作文、写文案、写摘要、对对联、自由问答、写小说、补全文本等)
然后根据我们的内容提示进行描述我们的内容。
接着根据我们的需要进行模型参数的设置
最后我们点击 立刻生成 按钮稍等片刻就可以得到我们的内容

生成内容后记得给内容打个分哦~~
- ERNIE-ViLG文生图体验展示:

首先我们选择需要生成的类型
接着使用文字进行描述内容即可
最后点击 立刻生成 按钮稍等片刻就可以得到我们的图片
代码调用之ERNIE 3.0系列
参考文档:https://wenxin.baidu.com/wenxin/docs#9l6llawo2
安装文心库
!pip install wenxin_api
代码调用
注意:
里面的wenxin_api.ak和wenxin_api.sk 需要替换成自己的API Key和Secret key.
API Key获取地址
https://wenxin.baidu.com/moduleApi/key
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2c206PrX-1662118444008)(https://ai-studio-static-online.cdn.bcebos.com/82a033492d3140c8891cf0db56f299cb86ca2ddeca444df584451b382b90cfbe)]
点击创建API key按钮即可
直接复制对应的内容粘贴即可
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eGnIC5ZH-1662118444009)(https://ai-studio-static-online.cdn.bcebos.com/cb8f5fd74d39430d9879f4762a50dedc123111fd05c34bc1a639e3b5b25c1172)]
参数说明
参考地址:https://wenxin.baidu.com/wenxin/docs#dl6tgxw5f
| 参数 | 释义 | 类型 | 默认值 | 取值范围 | 是否必传 | 说明 | 白话说明 |
|---|---|---|---|---|---|---|---|
| text | 用户输入文本 | string | 空 | [1, 1000] | 是 | 模型的输入文本,为prompt形式的输入。 | 输入一个我们想要处理的问题。例:作文题目:拔河比赛 |
| min_dec_len | 最小生成长度 | int | 1 | [1,seq_len] | 是 | 输出结果的最小长度,避免因模型生成END导致生成长度过短的情况,与seq_len结合使用来设置生成文本的长度范围。 | 根据我们实际的需求进行定义最短的长度是多少,比如文章1000字那么我们就可以设置最小长度为1000. |
| seq_len | 最大生成长度 | int | 128 | [1, 1000] | 是 | 输出结果的最大长度,因模型生成END或者遇到用户指定的stop_token,实际返回结果可能会小于这个长度,与min_dec_len结合使用来控制生成文本的长度范围。 | 内容输出的最大长度,例如我们要诗歌律诗什么的,那么长度就7位 |
| topp | 多样性 | float | 1.0 | [0.0,1.0],间隔0.1 | 是 | 影响输出文本的多样性,取值越大,生成文本的多样性越强。 | 就是输出内容改变程度,这个值越大我们重复的概率就越小 |
| penalty_score | 重复惩罚 | float | 1.0 | [1,2] | 否 | 通过对已生成的token增加惩罚,减少重复生成的现象。值越大表示惩罚越大。设置过大会导致长文本生成效果变差。 | 一种惩罚机制,越大越不可能重复,但是效果会变差,建议使用默认值 |
| stop_token | 提前结束符 | string | 空 | 否 | 预测结果解析时使用的结束字符串,碰到对应字符串则直接截断并返回。可以通过设置该值,可以过滤掉few-shot等场景下模型重复的cases。 | 文本中出现该字符则结束,用于特殊场合和需求,建议默认值 | |
| penalty_text | 惩罚文本 | string | 空 | 否 | 模型会惩罚该字符串中的token。通过设置该值,可以减少某些冗余与异常字符的生成。 | 设置的文字会减少输出 | |
| choice_text | 候选文本 | string | 空 | 否 | 模型只能生成该字符串中的token的组合。通过设置该值,可以对某些抽取式任务进行定向调优。 | 优先输出设置的内容 | |
| is_unidirectional | 单双向控制开关 | int | 0 | 0或1 | 否 | 0表示模型为双向生成,1表示模型为单向生成。建议续写与few-shot等通用场景建议采用单向生成方式,而完型填空等任务相关场景建议采用双向生成方式。 | 部分任务需要的内容,根据实际情况进行选择 |
| min_dec_penalty_text | 最小惩罚样本 | string | 空 | 否 | 与最小生成长度搭配使用,可以在min_dec_len步前不让模型生成该字符串中的tokens。 | 与最小的长度共同使用,如果生成数据小于最小长度会激活惩罚,建议使用默认值 | |
| logits_bias | 屏蔽惩罚 | float | -10000 | [1, 1000] | 否 | 配合penalty_text使用,对给定的penalty_text中的token增加一个logits_bias,可以通过设置该值屏蔽某些token生成的概率。 | 和惩罚文本配套,建议默认设置 |
| mask_type | 生成粒度 | string | word | 可选参数为word, sentence, paragraph | 否 | 设置该值可以控制模型生成粒度。 | 生成数据的内容,是文本还是段落还是句子,以实际需要进行选择 |
task_prompt
任务类型
数据类型:string
默认值:空
是否必选:否
特别说明:指定预置的任务模板,效果更好
| 可选值 | 对应内容 |
|---|---|
| PARAGRAPH | 引导模型生成一段文章 |
| ENTITY | 引导模型生成词组 |
| Summarization | 摘要 |
| MT | 翻译 |
| Text2Annotation | 抽取 |
| Correction | 纠错 |
| QA_MRC | 阅读理解 |
| Dialogue | 对话 |
| QA_Closed_book | 闭卷问答 |
| QA_Multi_Choice | 多选问答 |
| QuestionGeneration | 问题生成 |
| Paraphrasing | 复述 |
| NLI | 文本蕴含识别 |
| SemanticMatching | 匹配 |
| Text2SQL | 文本描述转SQL |
| TextClassification | 文本分类 |
| SentimentClassification | 情感分析 |
| zuowen | 写作文 |
| adtext | 写文案 |
| couplet | 对对联 |
| novel | 写小说 |
| cloze | 文本补全 |
| Misc | 其它任务 |
import wenxin_api
from wenxin_api.tasks.composition import Composition
wenxin_api.ak = "You API Key" # 填写自己的API Key
wenxin_api.sk = # "You Secret Key" # 填写自己的Secret Key
input_dict = {
"text": "作文题目:拔河比赛\n正文:", # 题目/内容
"seq_len": 512, # 文本长度(最长生成结果文本长度)
"topp": 0.9, # 多样性(取值越大,生成文本的多样性越强)
"penalty_score": 1.2, # 重复惩罚(1-2之前,通过对已生成的token增加惩罚,减少重复生成的现象)
"min_dec_len": 128, # 最小生成长度
"is_unidirectional": 0, # 单双向控制开关(0表示模型为双向生成,1表示模型为单向生成。)
#建议续写与few-shot等通用场景建议采用单向生成方式,而完型填空等任务相关场景建议采用双向生成方式。
"task_prompt": "zuowen" # 任务类型
}
rst = Composition.create(**input_dict)
print(rst)
# print(rst['result']) # 只输出内容
2022-09-02 17:09:24,072 - model 1: starts writing
{'result': '星期三下午第一节课,我们在操场举行了拔河比赛。太阳火辣辣的照着大地,似乎要把大地烤焦。有些同学擦擦汗,还有几个说:“那么热,怎么能打起精神来呢?”突然,体育老师叫道:“预备--开始!”同学们卯足劲的拉着绳子,像一只只小毛驴使出全身力气往后拉。而李宁泽他们班又是最强的队伍,其它班都不敢轻易去挑战。老师喊完停以后,结果就变成了一九比零了。放学后,刚回到家里,爸爸妈妈就跟我说;明天的作文里你可要写上今天参加拔河比赛这件事哦!虽然爸爸经常会批评我,但我心理知道她这也是为了鼓励我呀!'}
代码调用之ERNIE-ViLG文生图
使用文档:https://wenxin.baidu.com/wenxin/docs#Pl6llwf92
安装文心库
# !pip install wenxin_api
代码调用
注意: 里面的wenxin_api.ak和wenxin_api.sk 需要替换成自己的API Key和Secret key.
API Key获取方式与上方ERNIE 3.0相同
参数说明:
| 参数名 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| text | string | 是 | 输入内容,长度不超过64个字 |
| style | string | 是 | 图片风格,目前支持风格有:油画、水彩画、卡通、粉笔画、儿童画、蜡笔画 |
import wenxin_api
from wenxin_api.tasks.text_to_image import TextToImage
wenxin_api.ak = "You API Key" # 填写自己的API Key
wenxin_api.sk = "You Secret Key" # 填写自己的Secret Key
input_dict = {
"text": "超级月亮,元宇宙风", # 文字描述内容
"style": "水彩" # 生成风格
}
rst = TextToImage.create(**input_dict)
print(rst)
2022-08-30 23:07:55,580 - model is painting now!, taskId: 1088386, waiting: 1m
2022-08-30 23:08:15,774 - model is painting now!, taskId: 1088386, waiting: 30s
{'imgUrls': ['https://wenxin.baidu.com/younger/file/ERNIE-ViLG/670fa2538559cd8aeddef01ab2088e5bex', 'https://wenxin.baidu.com/younger/file/ERNIE-ViLG/670fa2538559cd8aeddef01ab2088e5bi4', 'https://wenxin.baidu.com/younger/file/ERNIE-ViLG/670fa2538559cd8aeddef01ab2088e5b5q', 'https://wenxin.baidu.com/younger/file/ERNIE-ViLG/670fa2538559cd8aeddef01ab2088e5b30', 'https://wenxin.baidu.com/younger/file/ERNIE-ViLG/670fa2538559cd8aeddef01ab2088e5bv9', 'https://wenxin.baidu.com/younger/file/ERNIE-ViLG/670fa2538559cd8aeddef01ab2088e5ba2']}
图片下载
import requests
img_names = []
for i in rst['imgUrls']:
img = requests.get(i)
img_name = i.split('/')[-1]+'.png'
img_names.append(img_name)
with open(img_name, 'wb')as f:
f.write(img.content)
print("下载完成")
下载完成
图片展示
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
img_ = Image.open(img_names[0])
plt.show()
plt.imshow(img_)

总结
以上就是我们文心大模型的基础使用,还有一些神奇的使用方法等待大家的探索~~~
作者简介
作者:三岁
经历:自学python,现在混迹于paddle社区,希望和大家一起从基础走起,一起学习Paddle
csdn地址:https://blog.csdn.net/weixin_45623093/
我在AI Studio上获得至尊等级,点亮9个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/284366