生成对抗网络(GANs)近年来在人工智能领域,尤其是计算机视觉领域非常受欢迎。随着论文“Generative Adversarial Nets” [1]的引入,这种强大生成策略出现了,许多研究和研究项目从那时起兴起并发展成了新的应用,我们现在看到的最新的DALL-E 2[2]或GLIDE3
本文详细解释了GAN优化函数中的最小最大博弈和总损失函数是如何得到的。将介绍原始GAN中优化函数的含义和推理,以及它与模型的总损失函数的区别,这对于理解Generative Adversarial Nets是非常重要的
GANs简介
生成对抗网络(Generative Adversarial Networks)是一种深度学习框架,它被设计为生成模型,目的是生成新的复杂数据(输出)。
为了训练GAN,只需要一组想要模仿的数据(图像、音频、甚至是表格数据……),网络会找出方法来创建看起来像我们提供的数据集示例的新数据。换句话说,我们给模型一些示例数据作为“获得灵感”的输入,并让它完全自由地生成新的输出
因为我们只向网络输入X信息,而不给它们添加任何标签(或期望的输出),所以这种训练过程是无监督学习。
GAN体系结构是由两个相互竞争的网络(因此得名“对抗网络”)组成的。通常将这两个网络称为Generator (G)和Discriminator (D)。Generator的任务是学习从随机噪声开始生成数据的函数,而Discriminator必须决定生成的数据是否“真实”(这里的“真实”是指数据是不是属于示例数据集的),这两个网络同时训练和学习。
GAN有很多不同的变体,所以训练有许多不同的变化。但是如果遵循原始论文 [1],原始的GAN 训练循环如下:
对于训练每次迭代会执行以下操作:
- 从表示的样本分布(即随机噪声 z)生成 m 个示例(图像、音频……):G(z)
- 从训练数据集中取 m 个样本:x
- 混合所有示例(生成和训练数据集)并将它们提供给鉴别器 D。D 的输出将介于 0 和 1 之间,这意味着 示例是假的,1 表示示例是真的
- 获得鉴别器损失函数并调整参数
- 生成新的 m 个示例 G'(z)
- 将 G'(z) 法送到鉴别器。获得 Generator Loss 函数并调整参数。
说明:一般情况下我们对GAN的训练都是在第 4 步测量生成器损失并调整其参数以及鉴别器,这样可以跳过第 5 步和第 6 步,节省时间和计算机资源。
优化函数(最小-最大博弈)和损失函数
GAN的原始论文中模型的优化函数为以下函数:

上式为Optimization函数,即网络(Generator和Discriminator)都要优化的表达式。在这种情况下,G想要最小化它而D想要最大化它。但是这不是模型的总损失函数。
为了理解这个最小-最大博弈,需要考虑如何衡量模型的性能,这样才可以通过反向传播来优化它。由于GAN架构是由两个同时训练的网络组成的,我们必须计算两个指标:生成器损失和鉴别器损失。
1、鉴别器损失函数
根据原始论文 [1] 中描述的训练循环,鉴别器从数据集中接收一批 m 个示例,从生成器接收其他 m 个示例,并输出一个数字 ∈ [0,1],即输入数据属于数据集分布的概率(即数据为“真实”的概率)。
通过鉴别已经知道哪些样本是真实的(来自数据集的样本 x 是真实的),哪些是生成的(生成器的输出 G(z) 生成),可以为它们分配一个标签:y = 0(生成),y = 1(真实)。

这样就可以使用二元交叉熵损失函数将鉴别器训练为一个常见的二元分类器:

由于这是一个二元分类器,我们可以做以下的简化:
-当输入真实数据时,y = 1→∑= log(D(k))
-输入为生成器生成的数据时,y = 0→∑= log(1-D(k))
表达式就可以改写为更简单的形式:

2、优化函数
判别器希望最小化其损失,它希望最小化上述公式。但是如果我们修改公式去掉“负号”的话。就需要最大化它:

最后,我们的操作变为:

然后我们重写这个公式:
![]()
下面我们再看看生成器的情况:生成器的目标是伪造鉴别器。生成器必须与判别器相反,找到 V(G,D) 的最小值。
![]()
总结两个表达式(判别器和生成器优化函数)并得到最后一个:

我们得到了优化函数。但是这不是总损失函数,它只告诉我们模型的整体性能(因为鉴别器来判断真假)。如果需要计算总损失还要添加上生成器相关的部分。
3、生成器损失函数
生成器只参与表达式 E(log(1-D(G(z))) 的第二项,而第一项保持不变。因此生成器损失函数试图最小化的是:

在原始论文中提到了,“Early in learning, when G is poor, D can reject samples with high confidence because they are clearly different from the training data.” 即在训练的早期阶段,判别器很容易区分真实图像和生成的图像,因为生成器还没有学习。在这种情况下,log(1 − D(G(z))) 是饱和的,因为 D(G(z)) ∼ 0
为了避免这种情况,研究人员提出了以下建议:“我们可以训练 G 最大化 log D(G(z)),而不是训练 G 以最小化 log(1 - D(G(z)))”。
这就相当于说,不是训练生成器最小化图像是假的概率,而是最大化图像是真实的概率。因为在本质上这两种优化方法是相同的,我们可以在图中看到:
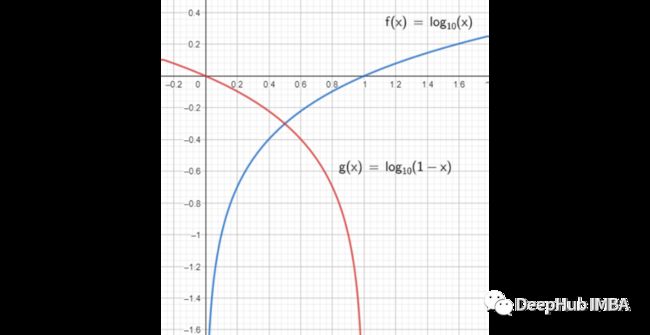
论文中使用的生成器损失函数是:

在实际使用时,编写生成器损失函数通常采用上述公式的负数形式,目的不是使函数最大化而是使其最小化。因为这样就方便了使用Tensorflow等库来调整参数。
总损失函数
上面我们已经给出了生成器和鉴别器的的损失公式,并给出了模型的优化函数。但是如何衡量模型的整体性能呢?
仅仅看优化函数并不是一个很好的衡量标准,因为优化函数是对鉴别器损失函数的修改,因此它并不能反映生成器的性能(尽管生成器损失函数源于它,但我们只是在该函数中考虑了鉴别器的性能),但是如果同时考虑这两个函数来评估性能我们就需要考虑到这两个函数的差别并加以修正:
a,这两个单独的损失函数必须以最小化或最大化为目标。否则,加法所反映的误差将高于或低于应有的误差。例如,让我们以优化函数为例,它希望被D最大化:
![]()
和以G最小为目标的第一个生成器损失函数:
![]()
当D做得很差(低错误)而G做得很好(也是低错误)时,整体性能将产生一个低错误,从指标上看这意味着两个网络(G和D)都做得很好,但是实际上我们知道其中一个不是。
如果一个损失的目标是最小化,另一个是最大化,得到了一个高错误率我们也不知道是好是坏,因为两个目标的方向是不一样的。并且如果以最大化为目标的损失函数,将其称为“错误”可能听起来有点奇怪,因为“错误”越高,性能越好。虽然我们也可以使用对数来转换它,比如log(1+Error)
b,对于构建一个总损失函数,其单独的损失必须在相同的值范围内,让我们继续看下面的损失
![]()
和
![]()
对于第一个问题我们已经将两个函数都转换为满足最小化的条件。但是,D的损失在[0,+∞]范围内,G的损失的输出值在(-∞,0)范围内。这两个函数相加等于是减去了D的损失,因此说整体损失是没有生成器影响的鉴别器损失(即 E(log(D(xi))),其中 E 表示期望值),这样其实是不正确的。
如果我们用D和修改后的G损失的负数形式呢?

这不就是论文中说到的GAN的总损失函数吗,我们还是来检验一下它是否满足我们的要求。
✅我们知道D损失的目的是最小化,并且修改G损失负数形式也是最小化。
✅D损失的输出值在[0,+∞)范围内,结果是负的G损失也将值映射到相同的范围内。
不仅是在方向上是相同的,在数值得取值范围内也是相同的。
总结
- GAN得优化函数(也叫最大-最小博弈)和总损失函数是不同的概念:最小-最大优化≠总损失
- 优化函数的起源来自二元交叉熵(这反过来是鉴别器损失),并从这也衍生出生成器损失函数。
- 在实际应用中生成器损失函数进行了修改,进行了对数操作。这一修改也有助于计算模型的总损失函数。
- 总损失= D损失+ G损失。并且为了进行总损失得计算还进行了修改以保证方向和取值得范围都是相同的。
你喜欢这篇文章,任何反馈或纠正请随时留言。
https://avoid.overfit.cn/post/db7a155b9da9436f993db597d65824b2
作者:Gabriel Furnieles