TCP流量控制与拥塞控制(重要)
本文参考了一些优秀的书籍->图解TCP/IP,TCP协议卷一,小林coding,还有等等的知乎,百度.
小林coding 小林coding
知乎牛客的文章 : 万字长文 | 23 个问题 TCP 疑难杂症全解析_技术交流_牛客网
本文主要讲解TCP可靠性的机制: 流量控制与拥塞控制
尤其拥塞控制的算法是大公司非常愿意考的.你想让面试官心服口服么,那我们一起来学习吧~~~

目录
流量控制
为啥要有流量控制???
流量控制的基本流程
缓冲区会影响接收窗口的大小
服务器繁忙应用进程不能及时的读取数据,导致窗口关闭
服务器系统资源紧张减少了缓冲区大小,导致丢包
啥是窗口关闭???
窗口关闭会出现什么问题呢???
窗口关闭问题如何解决呢??
糊涂窗口综合征
如何解决糊涂窗口综合征呢???
拥塞控制
为啥要有拥塞控制,不是有了流量控制了么???
流量控制与拥塞控制的区别
拥塞控制的算法
慢启动
拥塞避免
拥塞发生
快速恢复
流量控制
为啥要有流量控制???
我们知道发送方在发送数据时不仅要考虑发送方发送的速率也要考虑接收方的处理能力,如果发送方只管发送数据不管接收方就有可能导致接收方因处理不过来数据而导致丢包,丢包就会导致重传,所以浪费了网络流量.
TCP也为我们提供了一种流量控制机制,这个机制就是让发送方根据接收方的处理能力来控制发送窗口的大小.
- 那接收方的处理能力如何衡量呢??
接收方在接收数据的时候会把数据放到缓冲区里面,应用进程就要从接收缓冲区读取数据.

接收方的处理能力就是根据接收方缓冲区剩余空间大小来衡量的.进而确定发送窗口的大小
- 如果接收方的缓冲区剩余空间大,证明传输速率高
- 如果接收方的缓冲区剩余空间小,就证明传输速率低.
流量控制的基本流程

接收方接收数据,当接收方缓冲区满了的时候,也就是可用窗口大小为0,这就导致发送方无法发送数据,当发送方等待时间超过定时器的时间就会给接收方发送窗口探测包,看窗口有没有更新,当窗口腾出来了,也就是窗口有剩余空间了,那么接收方就会给发送方发送窗口更新通知(占一个字节),然后发送方又可以发送数据.
注意点
- 发送方如何知道接收方的接收缓冲区已经满了(也就是窗口大小为0)
接收方是通过返回给发送方的ACK报文来告知窗口的大小.
- 接收缓冲区满了怎么办??
如果接收缓冲区满,发送方会进行等待,如果等待时间超过连续计时器的时间,就会给接收方发送窗口探测包,看看窗口有没有更新.
- 窗口更新通知丢了怎么办??
如果窗口更新通知丢失可能导致无法进行通信,所以发送方会时不时的给接收方发送窗口探测包,来看看可用窗口有没有更新.
发送方根据接收方缓冲区剩余空间大小来进行流量控制,从而避免发送方发送大量数据而导致接收方无法处理.
缓冲区会影响接收窗口的大小
服务器繁忙应用进程不能及时的读取数据,导致窗口关闭
还是可以利用这幅图来解释;
发送方发送数据给接收方,接收方接收到数据,会把数据放到接收缓冲区里面,如果服务器繁忙导致应用进程不能的及时读取数据,从而导致接收缓冲区满了,可用窗口大小变为0了,就会导致窗口关闭.上面也提过解决方案,那就是发送方会等待,超过持续计时器的等待时间就会给接收方发送窗口探测包,为了防止窗口更新通知丢失,发送方就会时不时地给接收方发送窗口探测包.
服务器系统资源紧张减少了缓冲区大小,导致丢包
如果服务器系统资源非常的紧张,就有可能导致服务器就减少了接收缓冲区的大小,而发送方在发送数据时候,很可能就会出现发送方窗口>接收方窗口,从而导致数据报丢失的情况.
为了避免数据报丢失的情况,TCP就规定,不能同时既要缩小窗口大小,又要减小缓冲区的大小,所以这时候可以先进行缩小窗口,等待一段时间之后在减小缓冲区大小,就可以避免丢包.
啥是窗口关闭???
当可用窗口大小为0的时候,就导致接收缓冲区已经满了,发送方就不能在发送数据了,这时窗口就会关闭.不让发送方继续发送数据.
- 发送方是如何知道接收缓冲区已经满了,从而不能发送数据??
接收方接收数据返回给ACK报文时,会将其窗口大小一起告知给发送方,这时发送方就知道不能发送数据了.----窗口关闭
窗口关闭会出现什么问题呢???
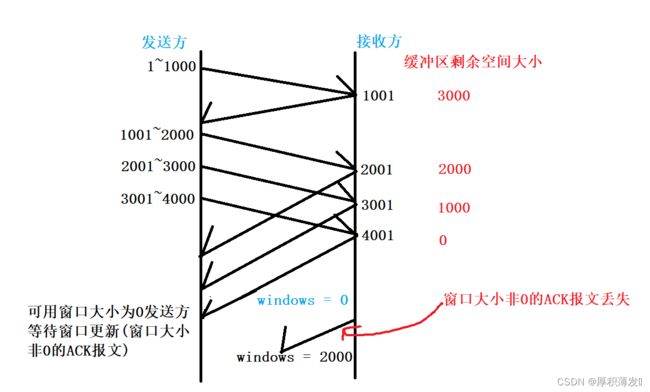
如果窗口大小非0的ACK报文(窗口更新通知)丢失,那么就可能导致死锁问题.即发送方在等待窗口大小非0的ACK报文(窗口更新通知),接收方在等待发送方发送数据.
窗口关闭问题如何解决呢??
TCP会为每一个连接配置一个持续定时器,当发送方接收到窗口为0的通知的ACK时候,发送方就会开始计时进行等待,如果超过计时等待时间,发送方就会给接收方发送窗口探测报文,接收方如果收到了这个探测报文,接收方就会返回当前接收窗口的大小,如果接到的通知,窗口大小还是为0时候,计时器就会重新进行计时.同时为了防止窗口更新这个通知丢失,发送方也会时不时地就发送窗口探测报文.
一般情况下,窗口探测次数为3,计时器等待时间为30~60s,如果超过3次窗口探测,发现窗口大小依然为0,发送方可能就会发送RST报文进行中断连接.
糊涂窗口综合征
百度百科 :
当发送端应用进程产生数据很慢、或接收端应用进程处理接收缓冲区数据很慢,或二者兼而有之;就会使应用进程间传送的报文段很小,特别是有效载荷很小。 极端情况下,有效载荷可能只有1个字节;而传输开销有40字节(20字节的IP头+20字节的TCP头) 这种现象就叫糊涂窗口综合症
发送方发送数据很慢/接收方应用进程读取数据很慢,应用进程传输的报文段就很小,而传输开销要40个字节,这就是糊涂窗口综合征.
这里就好像一辆大客车能够承载50人,如果每次开车时候有1,2个人坐车,车就立马开走,那这个师傅得赔不少钱.家里没有矿的人这样干不正常哈哈~~~.
如何解决糊涂窗口综合征呢???
首先,我们再来分析一下为什么会有糊涂综合征呢??? 原因是什么呢???
从糊涂窗口综合征的定义来看,是由于应用进程读取数据太慢/发送方发送的数据太慢有可能导致传输的报文段比TCP报文传输开销就要40个字节.
根据以上分析:
- 要避免接收方接收小的报文段
- 要避免发送方发送小的报文段
这样就保证了不会出现糊涂窗口综合征.
解决办法 :
- 如何避免接收方接收小数据呢???
先来讲解一下啥是MSS??? 啥是MTU ??
MSS是在通信双方建立连接时,是一个网络包除TCP报头和IP报头之后的容纳TCP数据的最大报文长度.
MTU是一个网络包的最大长度,以太网通常为1500个字节
这里会有一个经常考得面试题:
- 既然IP层会分片,为啥TCP层还需要MSS呢??
先看看将TCP整个报文交给IP分片会有什么影响???
如果IP层有数据大小超过MTU长度,就需要进行IP分片,将每个数据分片,保证每个分片的长度不能超过MTU,分片完成之后,接收方IP目的地主机就会对数据进行重新组装,传给上一层传输层.这时就会出现问题,如果一个IP分片丢失就会重传整个IP报文的所有分片.为什么呢?? 因为IP协议没有超时重传机制,这时就要交给TCP,当接收方接收TCP报文的时候,发现丢失TCP分片,就不会给发送方返回ACK,这时候就需要重传整个TCP报文(头部+数据).
怎么解决呢??
为了提高传输效率,在进行TCP建立连接的时候,通信双方就要协商好双方MSS的值,当数据超过MSS的时候,就会先进行分片,这就让IP分片的时候,每个数据不可能超过MTU,TCP分片后,如果TCP分片丢失,那么就会重传这个分片,重传的大小为MSS,所以不用重传整个IP报文的所有分片,大大提高了传输效率

当发送方发送数据给接收方的时候,如果数据报文段小于MIN(MSS(最大报文长度),缓存区空间/2),那么接收方就不接收,返回给发送方窗口大小为0.当大于MSS或者剩余缓冲区空间超过一半,接收方就可以接收数据.-------这样就避免接收方接收了小数据的情况
- 如何避免发送方发送小数据呢???
避免发送方发送小数据,一般要使用Nagle算法.------延迟处理
Nagle算法满足两个条件:
- 满足发送数据报/数据大于等于MSS的长度
- 收到之前数据的所有ACK.---延迟时间拼接数据包
满足Nagle算法的任意一个条件都可以避免发送方发送小数据.
但是,要避免糊涂窗口综合征的话,那就必须既要避免接收方接收小数据,又要满足避免发送方发送小数据.两者必须都要满足.
- 问题 : 如果不满足接收方接收小数据,但满足Nagle算法的第二个条件可不可以??
是不可以的,因为可能导致ACK回复过快,导致数据包拼接的不多,还是容易发送小数据.
- Nagle算法一般打开么??
Nagle算法一般是默认开启的,但是遇到一些交互性比较强/小数据包交互的特殊场景比如Telnet,SSH,就会关闭Nagle算法.
拥塞控制
为啥要有拥塞控制,不是有了流量控制了么???
流量控制与拥塞控制是不同的两种机制,流量控制是防止发送方发送的数据接收方接收不过来,所以发送方在发送数据的时候要考虑接收方的处理能力.
那拥塞控制是干什么的呢???
因为当我们从客户端发送数据到服务端的时候,不只是有发送方和接收方两个主机,在进行数据传输的过程中还会有很多中间的主机设备进行转发,如果中间的某个主机发生阻塞,就会导致接收方接收不到,这时可能会认为是数据包丢失了,其实是因为中间设备的阻塞原因,然后就进行重传数据包,这时可能网络会更加的阻塞,丢包率也增加.所以这时候就需要拥塞控制
拥塞控制是涉及到通信链路全局的,为了防止数据把网络填满,会根据拥塞窗口的大小变化会试探性的发送一定的数据量来探测网络状况,会根据网络状况来适时调整
- 什么是拥塞窗口??
拥塞窗口也是要控制发送窗口发送的数据量而设定的,拥塞窗口根据当前的网络状况(可能会发生网络拥堵)而适时进行调整,动态变化的.所以有了拥塞窗口,那么发送窗口就是 接收窗口和拥塞窗口的较小值
- 拥塞窗口如何变化的???
当网络状况良好时 : 拥塞窗口就会增大;
当网络状况较差时 : 拥塞窗口就会减小
所以,拥塞窗口是根据当前网络状况动态变化的
- 拥塞窗口与发送窗口的关系???
发送窗口是 接收窗口和拥塞窗口的较小值(至于为什么是较小值==>木桶原理)
- 怎么判断网络是否堵塞呢???
当发送方没有收到接收方返回的ACK,等待一定时间就会超时重传,这时就认为网络堵塞.
也就是当触发超时重传时候,就认为当前网络状态是拥堵的状态.
流量控制与拥塞控制的区别
流量控制是防止发送方发送的数据接收方处理不过来,所以发送方在发送数据的时候,就要考虑接收方的处理能力,接收方的处理能力就是根据接收缓存区剩余空间大小来衡量.流量控制是通信双方协商好的.
拥塞控制是由于在传输数据时,数据会经过多台主机进行传输,这时就有可能网络堵塞,这时就需要拥塞控制来根据当前的网络状况动态调整传输的数据报.可以得知,拥塞控制是涉及到整个通信链路的.
流量控制是通信双方各维护一个接收窗口和发送窗口,接收窗口由本身决定->也就是根据当前接收缓冲区剩余空间大小而决定,对于发送窗口根据接收方返回的ACK报文段可以知道当前窗口大小.
而拥塞控制只维护一个拥塞窗口,拥塞窗口根据当前网络状态动态进行调整.
发送窗口是 接收窗口和拥塞窗口中的较小值来决定.
拥塞控制的算法
拥塞控制需要怎么动态调整拥塞窗口更高效呢???
下面我们来了解一下拥塞控制的算法
从慢启动==>拥塞避免==>拥塞发生==>快速恢复
下面是整个拥塞算法的流程:


慢启动
当TCP建立连接完成时,首先进入慢启动的过程,刚开始网络状况良好(不拥堵),发送方就一点一点增加发送数据报的量,这里慢启动过程中发包的数量是呈指数增长的.发送方每收到一个ACK,拥塞窗口就增加1.
假设初始拥塞窗口为1,当发送方接收到返回的ACK,窗口增加1,此时窗口变为2.当接收到2个ACK的时候,窗口变为4,当接受到4个ACK的时候,窗口变为8.------发包数量呈指数型增长.
这里随着发包数量的增加,网络就会堵塞.这时当拥塞窗口大小>=慢启动门限的时候就使用拥塞避免算法.而当拥塞窗口大小<慢启动门限的时候就继续在慢启动的过程.
慢启动门限一般是65535字节
拥塞避免
当拥塞窗口大小>=慢启动门限的时候,就会使用拥塞避免算法.
拥塞避免算法时,每发送一个数据报,拥塞窗口就增加原来拥塞窗口大小分之一(1/cwnd),(比如mean启动门限是10,当发送方接收到10个ACK之后,拥塞窗口才增加1).
所以使用拥塞避免算法是将慢启动过程中发包的指数型增长变为线性增长.
随着发送一定的数据报,网络又会发生堵塞.就会丢包,也就会超时重传,当触发了重传机制,这时又要进入下一个算法--拥塞发生算法
拥塞发生
当数据报丢失了,这时就需要触发重传机制.这时就会有超时重传和快速重传,两种拥塞发生算法不一样.
超时重传.如果使用超时重传,使用拥塞发生算法是将慢启动门限重新置为拥塞窗口大小的一般,而拥塞窗口大小重新设置为初始化时的拥塞窗口大小.
也就是说使用超时重传就再次进入了慢启动的过程.
由于这样一下就进入了慢启动过程,反应会过于激烈,会造成网络卡顿.
快速重传 : 快速重传是当在传输数据的过程中,中间包有丢失的情况,就会重发上一个包的ACK三次.然后发送方立马就会快速重传这个丢失的数据包.
快速重传使用的拥塞发生算法就是将窗口大小设置为原来拥塞窗口大小的一半,然后将慢启动门限设置为拥塞窗口大小. 接下来就使用了快速恢复算法.
快速恢复
进入了快速恢复算法,一般快速恢复算法与拥塞发生算法同时用,快速恢复算法认为接收方还能返回三次重复的ACK,网络不是那么糟糕.
- 拥塞窗口大小就是等于慢启动门限+3(这里认为三个重复的ACK已经收到了)
- 这时就会重发丢失的数据包
- 如果还没有收到新数据的ACK,拥塞窗口+1
- 如果收到新数据的ACK了,那么就把拥塞窗口大小设置为第一步慢启动门限时候的大小,这时认为新的数据已经收到了,接下来又恢复到原来的状态,回到拥塞避免状态.