全网最详细的Hadoop大数据集群搭建并进行项目分析(基于完全分布式)-----第一部分

##心路历程:这是大学时期做的项目,这个项目对我印象特别的深,当时没有记录在博客上,今后会积极分享自己做项目的历程与经验,希望能帮到需要的朋友,有什么问题或者建议欢迎在评论区留言,废话不多说,咱们就开始干!
##所有需要的资料全部已上传到百度网盘上,请自行下载##
获取镜像,https://pan.baidu.com/s/1ho4hMrvIu1V6W4wWdH8nIA,提取码:ygyg
获取Xshell,https://pan.baidu.com/s/1xWRle9chuNtBpE0fDa7DHA,提取码:u3s6
获取Hadoop,https://pan.baidu.com/s/1a5M23KlUMtqKOoWqDnZBHQ,提取码:y1y3
获取jdk,https://pan.baidu.com/s/1ftofkxBKIYuOhooe2tj_1A,提取码:z9y4
获取 MySQL,https://pan.baidu.com/s/19wa564c6Pln1ReJOmHbh-g,提取码:y4k7
获取MySQL配置jar包,https://pan.baidu.com/s/1vFCKEttZNnd5ZfyeompcqQ,提取码:dsj8
获取Hive,https://pan.baidu.com/s/1YcnL07UVg_Czr1mMFfgJsQ,提取码:n4i7
获取Sqoop,https://pan.baidu.com/s/1wY5NcbI6hwKDt6r9BWu0Hg,提取码:u3x9
获取Zeppelin ,https://pan.baidu.com/s/1xjqbw3FO1sNClLSgd1iFhw,提取码:yw52
目录
-
- ##心路历程:这是大学时期做的项目,这个项目对我印象特别的深,当时没有记录在博客上,今后会积极分享自己做项目的历程与经验,希望能帮到需要的朋友,有什么问题或者建议欢迎在评论区留言,废话不多说,咱们就开始干!
-
- ##所有需要的资料全部已上传到百度网盘上,请自行下载##
- 第一部分:大数据集群搭建完全分布式(共分四部分)
-
- 第一章、安装配置虚拟机
-
- 1、安装虚拟机并配置基础设置.........................
- 2、配置主节点node1........
- 3、新建虚拟机配置其ip并克隆其他两台......................
- 4、基础搭建3台配置ip、网络、免密登录等..................
- 第二章、安装java环境并配置(三台都执行)
-
- 1、创建规范的目录结构....................................
- 2、上传jdk、hadoop等文件...............................
- 3、下载安装lrzsz传输文件................................
- 4、解压jdk、hadoop文件..................................
- 5、修改/etc/profile文件..................................
- 第三章、安装Hadoop环境并配置(只在node1执行)
-
- 1、修改/etc/profile文件..................................
- 2、配置/etc/hadoop文件下6个文件.........................
- 3、分发hadoop文件到其他两台.............................
- 4、初始化hdfs............................................
- 5、测试并查看进程........................................
- 第四章、配置windows上的host文件
-
- 1、配置etc下的host文件.................................
- 第五章、运行MapReduce程序
-
- 1、在Hadoop上测试MapReduce..............................
- 第六章、在HDFS集群上创建规范的文件
- PS:剩余的部分烦请诸位移步到本人博客主页,Hadoop集群搭建与运用专栏中获取,欢迎诸位在评论区留下宝贵意见...............
第一部分:大数据集群搭建完全分布式(共分四部分)
第一章、安装配置虚拟机
1、安装虚拟机并配置基础设置…
1、首先安装VMware Workstation Pro15.5版本,并且下载安装CentOS-7-x86_64-Minimal-1804.iso镜像;新建最小化虚拟机并命名为node1,磁盘为100G,其他不变,正常安装。


2、配置主节点node1…
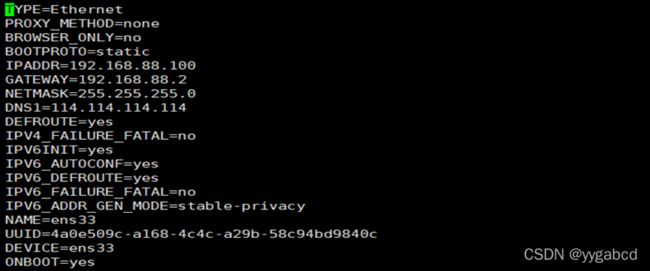
1、node1安装成功后,首先,第一步,设置用户名为root,密码为123456,超级用户密码为root,配置ip,在root环境下,
修改vi /etc/sysconfig/network-scripts/ifcfg-ens33文件:
配置ip网络
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.234.128
NETMASK=255.255.255.0
GATEWAY=192.168.234.2
重启网络
service network restart
结果如下:
3、新建虚拟机配置其ip并克隆其他两台…
1、分别进入node1,node2,修改 vi /etc/sysconfig/network-scripts/ifcfg-ens33文件,更改ip分别为192.168.88.101,192.168.88.102,保存并退出,
service network restart #重启网络
2、修改vi /etc/hostname(3台配置不一样)分别修改为node1.ygy.cn(3台都修改)设置完成后退出vi,输入reboot重启;
3、配置hosts,vi /etc/hosts(3台配置一样)
// An highlighted block
192.168.88.100 node1 node1.ygy.cn
192.168.88.101 node2 node2.ygy.cn
192.168.88.102 node3 node3.ygy.cn
4、三台机器hosts都要修改,ping www.baidu.com测试一下;
4、基础搭建3台配置ip、网络、免密登录等…
1、关闭防火墙:(3台都要配置)
systemctl stop firewalld.service #关闭防火墙
systemctl disable firewalld.service #禁止防火墙自启
systemctl status firewalld.service
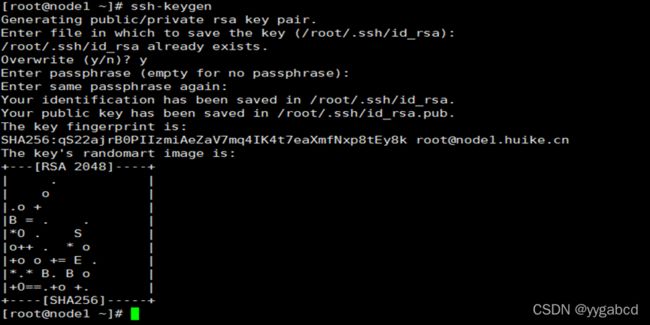
2、生成公钥和私钥:ssh-keygen(只在node1上运行,一直回车)
生成钥匙后:
分别运行ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
(第一次需要输入密码,把主节点的公钥分发给node2,node3)
结果如小图:
3、安装时间同步工具(3台都安装):
yum -y install ntpdate
4、同步阿里的ntp服务器时间(3台都执行):
ntpdate ntp4.aliyun.com
第二章、安装java环境并配置(三台都执行)
1、创建规范的目录结构…
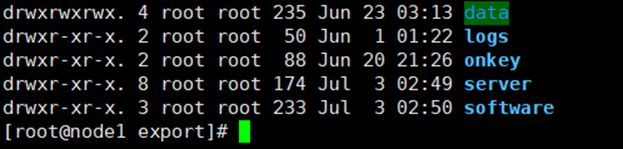
1、创建规范的目录结构(3台都要创建)
export下分别创建data,software,server文件夹
mkdir -p /export/data
mkdir -p /export/software
mkdir -p /export/server
2、上传jdk、hadoop等文件…
3台机器都要将jdk文件jdk-8u65-linux-x64.tar用xftp软件(需配置连结)传到software文件夹下
3、下载安装lrzsz传输文件…
1、安装lrzsz插件,在Xshell上与windows传输文件:
yum -y install lrzsz
2、连接xshell(三台虚拟机都要连接);
4、解压jdk、hadoop文件…
2、解压jdk,hadoop:
tar -zxvf ./jdk-8u65-linux-x64.tar.gz -C /export/server/
tar -zxvf hadoop.tar.gz -C /export/server/
5、修改/etc/profile文件…
添加以下内容:
export JAVA_HOME=/export/server/jdk1.8.0_65
export
CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
配置结果如下:

退出并保存,source /etc/profile,输入java -version测试;
第三章、安装Hadoop环境并配置(只在node1执行)
1、修改/etc/profile文件…
添加内容:
cd /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#退出并保存,source /etc/profile,输入hadoop version测试;
2、配置/etc/hadoop文件下6个文件…
cd /export/server/hadoop-3.1.4/etc/hadoop/下

1、修改:vi hadoop-env.sh
在尾部增加:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/export/server/jdk1.8.0_65
2、修改:vi core-site.xml
在configration之间增加:
<!-- 默认文件系统的名称。通过URI中schema区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs文件系统访问地址:http://nn_host:8020。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1.ygy.cn:8020</value>
</property>
<!-- hadoop本地数据存储目录 format时自动生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.1.4</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
3、修改:vi hdfs-site.cml
在configration之间增加:
<!-- 设定SNN运行主机和端口。-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2.huike.cn:9868</value>
</property>
4、修改:vi mapred-site.xml
在configration之间增加:
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
5、修改:vi yarn-site.xml
在configration之间增加:
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1.ygy.cn</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
6、修改:vi workers
node1.ygy.cn
node2.ygy.cn
node3.ygy.cn
3、分发hadoop文件到其他两台…
配置好hadoop文件后,在node1上开始分发hadoop到node2,node3,进入目录:cd /export/server/
scp -r hadoop-3.1.4 root@node2:/export/server/
scp -r hadoop-3.1.4 root@node3:/export/server/
4、初始化hdfs…
进入cd /export/server/环境下
格式化hdfs: hdfs namenode -format
5、测试并查看进程…
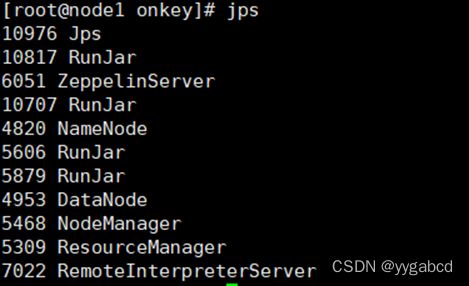
打开网址查看集群http://192.168.88.100:9870/

第四章、配置windows上的host文件
1、配置etc下的host文件…
进入C:\Windows\System32\drivers\etc添加以下内容:
192.168.88.100 node1 node1.ygy.cn
192.168.88.101 node2 node2.ygy.cn
192.168.88.102 node3 node3.ygy.cn
第五章、运行MapReduce程序
1、在Hadoop上测试MapReduce…
#进入hadoop下的MapReduce文件中
cd /export/server/hadoop-3.1.4/share/hadoop/mapreduce/
#输入测试命令
hadoop jar hadoop-mapreduce-examples-3.1.4.jar pi 24;hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
第六章、在HDFS集群上创建规范的文件
hadoop fs -mkdir /common
hadoop fs -mkdir /workspace
hadoop fs -mkdir /tmp
hadoop fs -mkdir /warehouse
hadoop fs -mkdir /source