时空数据挖掘一(城市计算)
Robust Spatio-Temporal Purchase Prediction via Deep Meta Learning
购买预测是线上和线下零售行业的一项重要任务,特别是在重大购物节期间,强大的促销活动会极大地促进消费。对于商家来说,预测这样的销量激增并做好充分准备是很重要的。这是一个具有挑战性的问题,因为购物节期间的购买模式与通常情况有明显的不同,而且在历史数据中也很罕见。由于数据样本极其稀缺,以及无法捕捉城市复杂的宏观时空依赖关系,现有的大多数方法无法解决这一问题。针对这一问题,提出了一种用于购物节购物预测的时空元学习预测模型(Spatio-Temporal Meta-learning Prediction, STMP)。STMP是一种基于元学习的时空多任务深度生成模型。它采用具有小样本学习能力的元学习框架来同时捕获空间和时间数据表示。然后,生成组件使用提取的时空表示和输入数据来推断预测结果。实验验证了STMP的元学习泛化能力。STMP在所有情况下都优于基线,这表明了我们模型的有效性。
背景:
Limited reference samples.
Complex spatio-temporal purchase patterns.

方法:
本文提出时空元学习预测(STMP)模型来应对上述挑战。我们的工作有两方面的贡献:
1)Task-specific spatio-temporal representation learning 它将动态购买时序特征和静态空间特征联合建模,学习出具有代表性的时空嵌入。
2)Knowledge transfer between tasks. 我们设计了一个生成模型,该模型结合了特定任务的时空表征和当前购买数据的嵌入,以实现不同任务之间的知识传递。


作者将该预测任务分为主要三个部分:1)利用时空元学习推理,对不同的时空区域生成对应的时空表示。2)学习不同时空区域间的共享信息,同时结合区域特定的时空表示,得到更加可靠的预测销量。3)通过时空交替训练使得模型在空间以及时间层面都能够得到更加完善的学习。
首先,在模型中利用元学习概率推理(Finn, Abbeel和Levine 2017)来增强罕见和不确定购物节期间少样本预测的鲁棒性。其次,利用任务间共享的隐藏统计结构进行多任务学习(Heskes 2000)。这种处理方式允许任务之间共享关于如何使用元学习学习和执行推理的信息(Thrun和Pratt 2012)。通过平摊变分推理实现不同sd -任务的快速学习(Shu等人。2018),将购买数据实例映射到参数化的近似后验分布。综上所述,提出的时空元学习预测(STMP)框架由摊销网络和生成模型组成。
2)Amortization Network


2)Generative Model for Purchase Prediction

ST-Training

阅读者总结:这里是用了一个生成对抗网络实现购买模拟的,这是值得学习的地方。考虑购买行为在时空上的分布性,文中对这样的分布建模的很好。
CityTraffic: Modeling Citywide Traffic via Neural Memorization and Generalization Approach(CIKM2019)
随着道路上车辆数量的不断增加,感知城市范围内的交通状况变得越来越重要,这对政府的决策和人们的决策有很大的帮助。目前,交通速度信息和交通量信息主要分别来自GPS轨迹数据和体传感器记录。然而,速度和流量信息存在严重的数据缺失问题。速度可以在任意路段和时隙缺失,而音量只能由有限的体积传感器记录。为了对全市交通进行建模,受对交通缺失模式和先验知识的观察启发,提出了一种神经记忆和泛化方法来推断缺失的速度和流量,主要由一个用于速度推理的记忆模块和一个用于流量推理的泛化模块组成。记忆模块充分考虑了交通信息的时间紧密性和周期特性,利用神经多头自注意力架构来记忆历史交通信息的内在相关性。泛化模块采用神经键值注意力架构,利用道路上下文泛化体传感器之间的外部依赖关系。在贵阳和济南两个城市的真实数据集上进行了广泛的实验,实验结果一致证明了所提方法的优势。我们开发了一个名为CityTraffic的云端系统,提供贵阳市全市范围内的交通速度和流量信息以及车辆细粒度污染物排放情况。


Learning to Generate Maps from Trajectories(AAAI2020)
准确和更新的路网数据在许多城市应用中至关重要,如汽车共享和物流。传统的道路网识别方法,即实地调查,需要大量的时间和精力。随着GPS嵌入式设备的广泛使用,不同类型的移动对象产生了大量的轨迹数据,为提取底层路网提供了新的机会。然而,现有的基于轨迹的地图恢复方法需要大量的经验参数,没有利用现有地图中的先验知识,导致重建的路网过于简化或过于复杂。为此,提出一种基于深度学习的地图生成框架DeepMG,通过学习现有路网的结构来克服噪声的GPS位置。更具体地说,DeepMG从空间视图和过渡视图中提取轨迹特征,并使用卷积深度神经网络T2RNet来推断道路中心线。然后,提出一种基于轨迹的后处理算法来细化恢复地图的拓扑连通性。在两个真实轨迹数据集上的广泛实验证实,DeepMG显著优于最先进的方法。



Geometry Translation
1)T2RNet


Topology Construction
几何平移模块可以预测道路中心线,但不能保证拓扑连通性。

Discovering Actual Delivery Locations from Mis-Annotated Couriers’ Trajectories
配送地点是智能物流的基础数据源,可用于路径规划、到达时间估计、包裹分配等。由于地址解析错误、POI数据库粒度过粗或客户偏好不同等原因,仅使用地址的地理编码运单位置作为投递位置是不够的。为了缓解地理编码的不足,一些研究人员提出了在确定运单已送达时利用快递员的位置进行快递员位置推断的方法。然而,这些方法高度依赖快递员标注的质量,并且在快递员确认有延迟的快递时失败。本文建议从快递员的轨迹中推断出地址的实际投递位置。这个想法基于这样一种观察,即递送包裹的语义很好地被快递员的轨迹所捕获(例如,当投递发生时,将生成一个停留点),这甚至允许快递员确认延迟投递。设计了误标注下的快递位置推断(DLInfMA),:(1)从快递员轨迹中的停留点生成候选位置;(2)从地址及其候选位置中提取特征;(3)使用基于注意力的神经网络模型LocMatcher预测每个地址的投递位置。通过在京东物流真实数据集和合成数据集上的实验,验证了DLInfMA的有效性、鲁棒性和可扩展性。同时给出了一个基于DLInfMA的部署系统和两个应用。
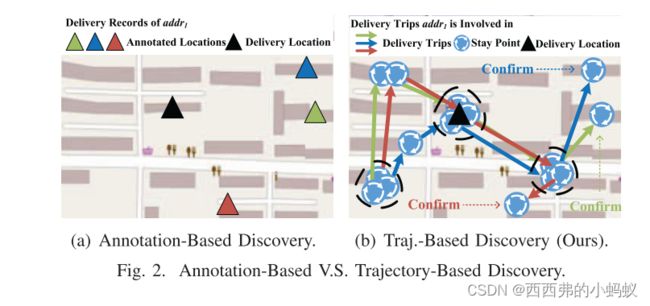
针对配送时间可能存在延迟的情况,提出了一种误标注下的配送位置推断方法(delivery location Inference under misannotation, DLInfMA)。该方法主要包括两个步骤:(1)为缓解候选点冗余问题,从快递员的历史轨迹中提取停留点聚类,生成配送位置候选池(称为候选位置);一旦生成候选地点池,我们就可以轻松地从候选地点集合中筛选出一个地址,并且实际的送货地点应该在这个集合中;(2)针对复杂的决策问题,首先从地址及其过滤后的候选位置中提取几个关键特征,如地址投递时候选位置是否存在、候选位置与地址的唯一性等。然后提出了一种基于注意力机制的地址选择模型LocMatcher,该模型联合考虑了一个地址的候选投递位置,从而预测其实际投递位置。

Doing in One Go: Delivery Time Inference Based on Couriers’ Trajectories
电子商务的快速发展要求高效、可靠的物流服务。如今,快递员仍然是解决物流“最后一公里”问题的主要途径。他们通常需要手动记录每个包裹的准确投递时间,这为投递保险、投递绩效评估和客户可用时间发现等应用提供了重要信息。通过pda生成的快递员轨迹,可以自动推断快递员的投递时间,减轻快递员的负担。然而,直接使用最近的停留点来推断配送时间是令人满意的,因为存在两个挑战:1)配送地点不准确,2)不同的停留场景。为此,提出了送货时间推断(Delivery Time Inference, DTInf),基于快递员的轨迹自动推断运单的送货时间。该方法包括3个步骤:1)数据预处理,从轨迹中检测停留点,并根据配送行程分离停留点和运单;2)配送位置修正,通过挖掘历史配送记录推断运单的真实配送位置;基于京东物流的大规模真实运单和轨迹数据进行了大量实验和案例分析,验证了所提方法的有效性。最后介绍了基于DTInf的京东物流系统,并在京东物流内部进行了部署和使用。

Detecting Loaded Trajectories for Hazardous Chemicals Transportation
危险化学品运输(HCT)带来重大的金融、环境和健康风险。必须建立健全的监管制度,以减少在运输这类危险化学品时发生事故的风险。世界各国政府使用GPS传感器监测HCT卡车的原始轨迹,但难以检测装载轨迹,这对HCT过程的管理至关重要。装载轨迹是指HCT卡车在装载危险化学品过程中跟踪所产生的子轨迹。原始轨迹上的停留点反映了HCT卡车潜在的装卸动作,为检测装载轨迹提供了一定的可行性。然而,由于停留场景复杂和装卸位置众多,直接利用停留点进行加载轨迹检测的效果往往不理想。为了应对这些挑战,我们提出了一个负载轨迹检测框架LEAD,用于从原始HCT轨迹中准确高效地检测负载轨迹。LEAD将原始轨迹处理为一组候选轨迹,将每个候选轨迹编码为一个潜在表示,并使用候选轨迹的潜在表示来检测加载的轨迹。在来自中国南通的真实数据集上的大量实验验证了所提出框架的有效性。实验结果表明,该方法对铅的检测准确率超过83%,比同类方法提高了42%以上。




Interactive Bike Lane Planning Using Sharing Bikes’ Trajectories
自行车作为一种绿色的交通方式已被世界各国政府大力推广。因此,建设有效的自行车道已经成为促进自行车生活方式的一项重要任务,因为精心规划的自行车道可以减少交通拥堵和安全风险。遗憾的是,现有的自行车道规划轨迹挖掘方法没有考虑一个或多个关键的现实政府约束:1)预算限制,2)施工便利性,3)自行车道利用率。基于无站点自行车共享系统摩拜收集的大规模真实自行车轨迹数据,提出了一种数据驱动的自行车道建设方案制定方法。强制执行这些约束来制定问题,并引入一个灵活的目标函数来调整用户覆盖率和他们轨迹长度之间的利益。证明了该问题的np -困难性,并提出了基于贪婪的启发式方法来解决该问题。为了提高面向城市规划师的自行车道规划系统的效率,提出了一种新的轨迹索引结构,并基于并行计算框架(Storm)部署了系统。最后,通过大量实验和案例分析验证了系统的效率和有效性。




Precision CityShield Against Hazardous Chemicals Threats via Location Mining and Self-Supervised Learning
随着工业化和城市化的空前发展,许多危险化学品已经成为我们日常生活中不可缺少的一部分。现代城市每天都在生产、运输、消费危险化学品,由此孕育出许多未被管理部门监管的未知危险化学品相关场所,对城市安全构成巨大威胁。如何识别这些未知的HCLs并识别其风险等级是城市危险化学品管理的一项重要任务。为了完成这一任务,本文提出了一个名为CityShield的系统来发现隐藏的HCLs,并根据危险化学品运输车辆的轨迹对其风险等级进行分类。CityShield系统由三个部分组成。第一部分是数据预处理,过滤原始轨迹中的噪声,从海量的不确定GPS轨迹点中探测出稳定的交通车辆停留点;二是HCL识别,采用HCL- rec算法将停留点聚类成多边形HCL,避免了HCL空间分布偏斜导致的位置归并不当问题。第三部分是HCL分类,引入HCL关系图作为辅助信息,以克服HCL的标签稀缺问题。采用由4个预训练任务组成的自监督方法从图中学习高质量的hcl表示,最终用于hcl类别和风险等级的分类。CityShield系统已应用于我国重要的危化品进出口城市南通。在南通收集的两个大规模真实数据集上的实验和案例研究验证了所提系统的有效性。


Spatio-Temporal Meta Learning for Urban Traffic Prediction
城市交通预测对智能交通系统和公共安全具有重要意义,但具有3个方面的挑战:1)城市交通复杂的时空相关性,包括位置之间的空间相关性和时间戳之间的时间相关性;2)这种时空关联具有空间多样性,受周边地理信息(如兴趣点、道路网等)的影响,随地点的不同而不同;(3)时空关联的时间多样性受交通状态的动态影响较大。为了应对这些挑战,我们提出了一种基于深度元学习的模型ST-MetaNetþ,来同时对所有位置的流量进行联合预测。ST-MetaNetþ采用序列到序列的架构,由学习历史信息的编码器和逐步进行预测的解码器组成。具体而言,编码器和解码器具有相同的网络结构,分别由元图注意力网络和元循环神经网络组成,以捕获不同的空间和时间相关性。然后,根据地理图属性的嵌入和从动态交通状态中学习到的交通上下文,生成元图注意力网络和元循环神经网络的权重(参数);基于三个真实的数据集进行了广泛的实验,以说明ST-MetaNetþ超越几种最先进的方法的有效性。

本文提出一种基于深度元学习的框架ST-MetaNetþ,用于城市交通预测。关键见解是将地理属性和动态交通状态视为ST神经网络的元数据,以捕获ST相关性。因此,为了捕获ST相关性与这些元数据之间的关系,一个直接的解决方案是采用基于权重生成的元学习方法。更具体地说,如图4a所示,我们首先结合空间和时间模型来同时捕获这两种类型的相关性。
然后,由于ST相关性隐含地受到节点(位置)和边(位置间关系)的特征以及动态交通状态的影响,我们必须进一步捕获这种关系,如图4b和4c所示。直观地说,一条边的特征依赖于它的属性,如道路的连通性和节点之间的距离。同样,节点的特征也受到其属性的影响,如GPS位置和附近poi的分布。此外,交通状态包含了隐含的交通上下文信息,会影响ST相关性。基于这些见解,ST-MetaNetþ首先从它们的属性中分别提取节点和边的元知识(即特征),以及从交通状态中提取动态交通上下文。然后,通过数据融合模块简单地聚合提取的信息(即元知识和交通上下文),然后用于对ST相关性进行建模,即生成空间和时间模型的权重
TrajMesa: A Distributed NoSQL Storage Engine for Big Trajectory Data
轨迹数据在许多城市应用中非常有用。然而,由于轨迹数据的时空性和高容量特性,其管理具有挑战性。现有的轨迹数据管理框架存在可扩展性问题,且仅支持有限的轨迹查询。在开源时空数据索引工具GeoMesa的基础上,提出了一种整体性的分布式NoSQL轨迹存储引擎TrajMesa。trjmesa采用了一种新颖的存储模式,极大地减少了存储空间。设计了新颖的索引键设计,并提出了一系列剪枝策略。TrajMesa能够高效地支持丰富的时态查询、空间范围查询、相似性查询、k-NN查询等。实验结果表明,trjmesa具有良好的查询效率和可扩展性。


Vertical Storage Schema 将轨迹存储在键值存储中的一个基本思想是,轨迹数据以每个GPS点作为一行存储,就像大多数基于云的轨迹管理系统所做的那样[9,13]。我们将这种模式称为垂直存储模式(V-Store)。图2a给出了一个例子,其中每个点的值包含两部分:
Horizontal Storage Schema 为了解决上述问题,提出了一种新的水平存储模式——H-Store,将轨迹存储在单行中。如图2b所示,每个条目的值包含4部分
1)ID Temporal Indexing
为了高效地支持ID时态查询,TrajMesa采用GeoMesa的属性索引策略存储轨迹副本。图3展示了ID索引表的键组合,其中shard是一个实现负载均衡的随机数,oid是移动对象ID, XZT由轨迹时间跨度变换而来(后面会详细介绍),tid是轨迹ID。


注意:这里特别好的的点:将轨迹数据转化为数值code,类似于一种码本的方法
A Cross-City Federated Transfer Learning Framework: A Case Study on Urban Region Profiling
由城市服务和基础设施不足或发展水平不平衡导致的数据不足问题(即数据缺失和标签稀缺)严重影响了现实场景中的城市计算任务。现有的迁移学习方法对数据不充分问题给出了优雅的解决方案,但只关注了一类不充分问题,没有兼顾两者。此外,已有的跨城市换乘方法大多忽略了实际应用中普遍关注的跨城市数据隐私问题。为了解决上述挑战性问题,本文提出了一种新的跨城市联邦迁移学习框架(Cross-city federation Transfer Learning framework, CcFTL)来应对数据不足和隐私问题。具体而言,CcFTL将多个富数据源城市的关系知识迁移到目标城市。此外,针对目标任务的模型参数首先在源数据上进行训练,然后通过参数迁移对目标城市进行微调。通过对联邦训练和同态加密设置的自适应,CcFTL可以有效地处理城市间的数据隐私问题。将城市区域轮廓作为智慧城市的一个应用,并通过一项真实的研究对所提出的方法进行了评估。实验表明,所提出的框架与其他几种最先进的方法相比具有显著的优越性。
这篇论文:处理数据稀疏问题与数据隐私保护问题

问题:1)城市计算的关键挑战源于任务数据的不足, 2)上述跨城市迁移学习方法忽略了数据隐私保护问题。

III. METHODOLOGY
框架:



Stage I: Federated Training on Source Cities



2) Urban Task-specific Predicting (UTP) Module
该模块是针对特定的城市计算任务而设计的。我们将其视为一个分类任务,应用于城市区域轮廓的预测,并以居民消费能力预测为例进行了研究。

C. Stage II: Knowledge Transferring on the Target City
所提出的框架CcFTL使用迁移学习来解决目标城市数据不足的挑战。图3 (b)显示了迁移学习在目标城市中的过程。基于来自多个源城市的多源数据,训练领域自适应关系知识学习模块和城市特定任务预测模块,并将其应用于目标城市。
Missing Value Imputation for Multi-view Urban Statistical Data via Spatial Correlation Learning
随着城市化的发展,海量的城市统计数据(如人口、经济等视图)被越来越多地收集并应用于交通服务、区域分析等多个领域。然而,这些被划分为细粒度区域的统计数据在获取和存储过程中往往存在缺失值问题。这主要是由于一些不可避免的情况造成的,如文件的污损、偏远地区的统计困难、信息清洗不准确等。那些使有价值的信息不可见的缺失条目可能会使进一步的城市分析失真。为提高缺失数据填补的质量,结合自适应权重非负矩阵分解策略,提出一种改进的空间多核学习方法来指导填补过程。该模型考虑了区域的潜在相似性和真实的地理位置,以及各种视图之间的相关性,能够精确补全缺失值。进行了密集的实验来评估所提出的方法,并在真实的数据集上与其他最先进的方法进行了比较。实验结果表明,所提出的模型优于其他主流方法。此外,该模型在多个城市中表现出很强的泛化能力。


Distributed Spatio-Temporal Nearest Neighbors Join
定位技术的快速发展产生了海量的时空数据,这些数据包含点、线串、多边形等多种几何类型,或者它们的混合组合。最近邻连接(NN join)作为最基本但耗时的操作之一,受到了广泛的关注。然而,大多数现有的NN连接工作要么忽略了时间信息,要么只考虑点数据。
本文提出了一个新的实用问题ST-NN连接,它同时考虑了空间紧密性和时间并发性。为了高效地支持任意几何类型的海量时空数据的ST-NN连接,提出了一种基于Apache Spark的分布式解决方案。具体而言,该方法采用两轮join框架。在第一轮连接中,我们提出了一种新的时空划分方法,能够同时实现时空局部性和负载均衡。本文还提出了一种轻量级的索引结构,即时间范围计数索引(Time Range Count index, TRCindex),以支持高效的ST-NN连接。在第二轮连接中,为了减少不同机器之间的数据传输,在对局部结果进行洗牌之前,基于时空参考点进行重复删除。在三个真实的大数据集上进行了广泛的实验,结果表明,该方法具有更好的可扩展性,比基线方法快9倍。部署了一个演示系统并发布了源代码。


挑战:

方法:
提出了一种基于Apache Spark的分布式连接方案,能够高效地支持多种几何类型的ST-NN连接。具体来说,我们的解决方案遵循two round join框架。在第一轮连接中,首先根据时空分布对对象进行划分,然后求出每个对象的距离界,使得其最近邻(同时考虑空间紧密性和时间并发性)必须位于一个特定的区域。在第二轮连接中,我们首先执行本地ST-NN连接以获得局部结果,然后将它们合并为全局结果
框架:
