深度学习:如何使用多块 GPU 计算?
本节中我们将展示如何使用多块 GPU 计算,例如,使用多块GPU 训练同一个模型。正如所期望的那样,运行本节中的程序需要至少2块 GPU。事实上,一台机器上安装多块 GPU 很常见,这是因为主板上通常会有多个 PCIe 插槽。如果正确安装了 NVIDIA 驱动,我们可以通过nvidia-smi命令来查看当前计算机上的全部 GPU。
In [1]: !nvidia-smiMon Feb 25 19:19:54 2019+-----------------------------------------------------------------------------+| NVIDIA-SMI 384.111 Driver Version: 384.111 ||-------------------------------+----------------------+----------------------+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. ||===============================+======================+======================|| 0 Tesla V100-SXM2… On | 00000000:00:1B.0 Off | 0 || N/A 46C P0 38W / 300W | 0MiB / 16152MiB | 0% Default |+-------------------------------+----------------------+----------------------+| 1 Tesla V100-SXM2… On | 00000000:00:1C.0 Off | 0 || N/A 44C P0 39W / 300W | 0MiB / 16152MiB | 0% Default |+-------------------------------+----------------------+----------------------+| 2 Tesla V100-SXM2… On | 00000000:00:1D.0 Off | 0 || N/A 42C P0 39W / 300W | 0MiB / 16152MiB | 0% Default |+-------------------------------+----------------------+----------------------+| 3 Tesla V100-SXM2… On | 00000000:00:1E.0 Off | 0 || N/A 45C P0 43W / 300W | 0MiB / 16152MiB | 0% Default |+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+| Processes: GPU Memory || GPU PID Type Process name Usage ||=============================================================================|| No running processes found |+-----------------------------------------------------------------------------+
8.3节介绍过,大部分运算可以使用所有的 CPU 的全部计算资源,或者单块GPU 的全部计算资源。但如果使用多块GPU 训练模型,我们仍然需要实现相应的算法。这些算法中最常用的叫作数据并行。
8.4.1 数据并行
数据并行目前是深度学习里使用最广泛的将模型训练任务划分到多块GPU 的方法。回忆一下我们在7.3节中介绍的使用优化算法训练模型的过程。下面我们就以小批量随机梯度下降为例来介绍数据并行是如何工作的。
假设一台机器上有k块GPU。给定需要训练的模型,每块GPU及其相应的显存将分别独立维护一份完整的模型参数。在模型训练的任意一次迭代中,给定一个随机小批量,我们将该批量中的样本划分成k份并分给每块显卡的显存一份。然后,每块GPU 将根据相应显存所分到的小批量子集和所维护的模型参数分别计算模型参数的本地梯度。接下来,我们把k块显卡的显存上的本地梯度相加,便得到当前的小批量随机梯度。之后,每块GPU 都使用这个小批量随机梯度分别更新相应显存所维护的那一份完整的模型参数。图8-1 描绘了使用2块GPU 的数据并行下的小批量随机梯度的计算。
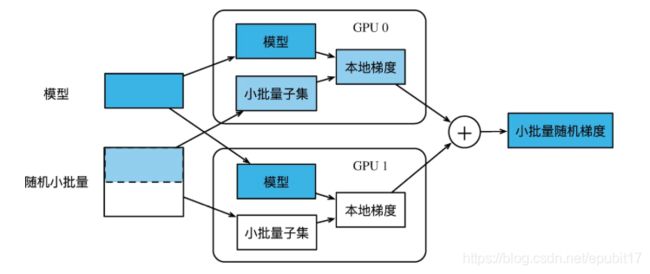
图8-1 使用2块GPU的数据并行下的小批量随机梯度的计算
为了从零开始实现多 GPU 训练中的数据并行,让我们先导入需要的包或模块。
In [2]: import d2lzh as d2limport mxnet as mxfrom mxnet import autograd, ndfrom mxnet.gluon import loss as glossimport time
8.4.2 定义模型
我们使用5.5节里介绍的LeNet来作为本节的样例模型。这里的模型实现部分只用到了 NDArray。
In [3]: # 初始化模型参数scale = 0.01W1 = nd.random.normal(scale=scale, shape=(20, 1, 3, 3))b1 = nd.zeros(shape=20)W2 = nd.random.normal(scale=scale, shape=(50, 20, 5, 5))b2 = nd.zeros(shape=50)W3 = nd.random.normal(scale=scale, shape=(800, 128))b3 = nd.zeros(shape=128)W4 = nd.random.normal(scale=scale, shape=(128, 10))b4 = nd.zeros(shape=10)params = [W1, b1, W2, b2, W3, b3, W4, b4]# 定义模型def lenet(X, params):h1_conv = nd.Convolution(data=X, weight=params[0], bias=params[1],kernel=(3, 3), num_f ilter=20)h1_activation = nd.relu(h1_conv)h1 = nd.Pooling(data=h1_activation, pool_type='avg', kernel=(2, 2),stride=(2, 2))h2_conv = nd.Convolution(data=h1, weight=params[2], bias=params[3],kernel=(5, 5), num_f ilter=50)h2_activation = nd.relu(h2_conv)h2 = nd.Pooling(data=h2_activation, pool_type='avg', kernel=(2, 2),stride=(2, 2))h2 = nd.f latten(h2)h3_linear = nd.dot(h2, params[4]) + params[5]h3 = nd.relu(h3_linear)y_hat = nd.dot(h3, params[6]) + params[7]return y_hat# 交叉熵损失函数loss = gloss.SoftmaxCrossEntropyLoss()
8.4.3 多GPU之间同步数据
我们需要实现一些多GPU之间同步数据的辅助函数。下面的get_params函数将模型参数复制到某块显卡的显存并初始化梯度。
In [4]: def get_params(params, ctx):new_params = [p.copyto(ctx) for p in params]for p in new_params:p.attach_grad()return new_params
尝试把模型参数params复制到gpu(0)上。
In [5]: new_params = get_params(params, mx.gpu(0))print('b1 weight:', new_params[1])print('b1 grad:', new_params[1].grad)b1 weight:[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]b1 grad:[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
给定分布在多块显卡的显存之间的数据。下面的allreduce函数可以把各块显卡的显存上的数据加起来,然后再广播到所有的显存上。
In [6]: def allreduce(data):for i in range(1, len(data)):data[0][:] += data[i].copyto(data[0].context)for i in range(1, len(data)):data[0].copyto(data[i])
简单测试一下allreduce函数。
In [7]: data = [nd.ones((1, 2), ctx=mx.gpu(i)) * (i + 1) for i in range(2)]print('before allreduce:', data)allreduce(data)print('after allreduce:', data)before allreduce: [[[1. 1.]], [[2. 2.]]] after allreduce: [[[3. 3.]], [[3. 3.]]]
给定一个批量的数据样本,下面的split_and_load函数可以将其划分并复制到各块显卡的显存上。
In [8]: def split_and_load(data, ctx):n, k = data.shape[0], len(ctx)m = n // k # 简单起见, 假设可以整除assert m * k == n, '# examples is not divided by # devices.'return [data[i * m: (i + 1) * m].as_in_context(ctx[i]) for i in range(k)]
让我们试着用split_and_load函数将6个数据样本平均分给2块显卡的显存。
In [9]: batch = nd.arange(24).reshape((6, 4))ctx = [mx.gpu(0), mx.gpu(1)]splitted = split_and_load(batch, ctx)print('input: ', batch)print('load into', ctx)print('output:', splitted)input:[[ 0. 1. 2. 3.][ 4. 5. 6. 7.][ 8. 9. 10. 11.][12. 13. 14. 15.][16. 17. 18. 19.][20. 21. 22. 23.]]load into [gpu(0), gpu(1)]output: [[[ 0. 1. 2. 3.][ 4. 5. 6. 7.][ 8. 9. 10. 11.]], [[12. 13. 14. 15.][16. 17. 18. 19.][20. 21. 22. 23.]]]
8.4.4 单个小批量上的多GPU训练
现在我们可以实现单个小批量上的多GPU训练了。它的实现主要依据本节介绍的数据并行方法。我们将使用刚刚定义的多GPU之间同步数据的辅助函数allreduce和split_and_load。
In [10]: def train_batch(X, y, gpu_params, ctx, lr):# 当ctx包含多块GPU及相应的显存时, 将小批量数据样本划分并复制到各个显存上gpu_Xs, gpu_ys = split_and_load(X, ctx), split_and_load(y, ctx)with autograd.record(): # 在各块GPU上分别计算损失ls = [loss(lenet(gpu_X, gpu_W), gpu_y)for gpu_X, gpu_y, gpu_W in zip(gpu_Xs, gpu_ys, gpu_params)]for l in ls: # 在各块GPU上分别反向传播l.backward()# 把各块显卡的显存上的梯度加起来, 然后广播到所有显存上for i in range(len(gpu_params[0])):allreduce([gpu_params[c][i].grad for c in range(len(ctx))])for param in gpu_params: # 在各块显卡的显存上分别更新模型参数d2l.sgd(param, lr, X.shape[0]) # 这里使用了完整批量大小
8.4.5 定义训练函数
现在我们可以定义训练函数了。这里的训练函数和3.6节定义的训练函数train_ch3有所不同。值得强调的是,在这里我们需要依据数据并行将完整的模型参数复制到多块显卡的显存上,并在每次迭代时对单个小批量进行多GPU训练。
In [11]: def train(num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)ctx = [mx.gpu(i) for i in range(num_gpus)]print('running on:', ctx)# 将模型参数复制到num_gpus块显卡的显存上gpu_params = [get_params(params, c) for c in ctx]for epoch in range(4):start = time.time()for X, y in train_iter:# 对单个小批量进行多GPU训练train_batch(X, y, gpu_params, ctx, lr)nd.waitall()train_time = time.time() - startdef net(x): # 在gpu(0)上验证模型return lenet(x, gpu_params[0])test_acc = d2l.evaluate_accuracy(test_iter, net, ctx[0])print('epoch %d, time %.1f sec, test acc %.2f'% (epoch + 1, train_time, test_acc))
8.4.6 多GPU训练实验
让我们先从单 GPU训练开始。设批量大小为 256,学习率为 0.2。
In [12]: train(num_gpus=1, batch_size=256, lr=0.2)running on: [gpu(0)]epoch 1, time 1.7 sec, test acc 0.10epoch 2, time 1.6 sec, test acc 0.69epoch 3, time 1.5 sec, test acc 0.75epoch 4, time 1.6 sec, test acc 0.79
保持批量大小和学习率不变,将使用的GPU数量改为2。可以看到,测试准确率的提升同上一个实验中的结果大体相当。因为有额外的通信开销,所以我们并没有看到训练时间的显著降低。因此,我们将在8.5节实验计算更加复杂的模型。
In [13]: train(num_gpus=2, batch_size=256, lr=0.2)running on: [gpu(0), gpu(1)]epoch 1, time 2.5 sec, test acc 0.10epoch 2, time 2.3 sec, test acc 0.64epoch 3, time 2.4 sec, test acc 0.68epoch 4, time 2.6 sec, test acc 0.78
小结
可以使用数据并行更充分地利用多块GPU 的计算资源,实现多 GPU 训练模型。
给定超参数的情况下,改变 GPU数量时模型的准确率大体相当。
练习
(1)在多 GPU 训练实验中,使用2块GPU 训练并将
batch_size翻倍至512,训练时间有何变化?如果希望测试准确率与单GPU训练中的结果相当,学习率应如何调节?(2)将实验的模型预测部分改为用多 GPU 预测。
8.5 多GPU计算的简洁实现
在 Gluon 中,我们可以很方便地使用数据并行进行多GPU计算。例如,我们并不需要自己实现8.4节里介绍的多 GPU 之间同步数据的辅助函数。
首先导入本节实验所需的包或模块。运行本节中的程序需要至少2块GPU。
In [1]: import d2lzh as d2limport mxnet as mxfrom mxnet import autograd, gluon, init, ndfrom mxnet.gluon import loss as gloss, nn, utils as gutilsimport time
8.5.1 多GPU上初始化模型参数
我们使用 ResNet-18作为本节的样例模型。由于本节的输入图像使用原尺寸(未放大),这里的模型构造与5.11节中的 ResNet-18 构造稍有不同。这里的模型在一开始使用了较小的卷积核、步幅和填充,并去掉了最大池化层。
In [2]: def resnet18(num_classes): # 本函数已保存在d2lzh包中方便以后使用def resnet_block(num_channels, num_residuals, f irst_block=False):blk = nn.Sequential()for i in range(num_residuals):if i == 0 and not f irst_block:blk.add(d2l.Residual(num_channels, use_1x1conv=True, strides=2))else:blk.add(d2l.Residual(num_channels))return blknet = nn.Sequential()# 这里使用了较小的卷积核、步幅和填充, 并去掉了最大池化层net.add(nn.Conv2D(64, kernel_size=3, strides=1, padding=1),nn.BatchNorm(), nn.Activation('relu'))net.add(resnet_block(64, 2, f irst_block=True),resnet_block(128, 2),resnet_block(256, 2),resnet_block(512, 2))net.add(nn.GlobalAvgPool2D(), nn.Dense(num_classes))return netnet = resnet18(10)
之前我们介绍了如何使用initialize函数的ctx参数在内存或单块显卡的显存上初始化模型参数。事实上,ctx可以接受一系列的 CPU及内存和GPU及相应的显存,从而使初始化好的模型参数复制到ctx里所有的内存和显存上。
In [3]: ctx = [mx.gpu(0), mx.gpu(1)]net.initialize(init=init.Normal(sigma=0.01), ctx=ctx)
Gluon提供了上一节中实现的split_and_load函数。它可以划分一个小批量的数据样本并复制到各个内存或显存上。之后,根据输入数据所在的内存或显存,模型计算会相应地使用CPU或相同显卡上的GPU。
In [4]: x = nd.random.uniform(shape=(4, 1, 28, 28))gpu_x = gutils.split_and_load(x, ctx)net(gpu_x[0]), net(gpu_x[1])Out[4]: ([[ 5.4814936e-06 -8.3371094e-07 -1.6316770e-06 -6.3674099e-07-3.8216162e-06 -2.3514044e-06 -2.5469599e-06 -9.4784696e-08-6.9033558e-07 2.5756231e-06][ 5.4710872e-06 -9.4246496e-07 -1.0494070e-06 9.8081841e-08-3.3251815e-06 -2.4862918e-06 -3.3642798e-06 1.0455864e-07-6.1001344e-07 2.0327841e-06]], [[ 5.6176345e-06 -1.2837586e-06 -1.4605541e-06 1.8302967e-07-3.5511653e-06 -2.4371013e-06 -3.5731798e-06 -3.0974860e-07-1.1016571e-06 1.8909889e-06][ 5.1418697e-06 -1.3729932e-06 -1.1520088e-06 1.1507450e-07-3.7372811e-06 -2.8289724e-06 -3.6477197e-06 1.5781629e-07-6.0733043e-07 1.9712013e-06]])
现在,我们可以访问已初始化好的模型参数值了。需要注意的是,默认情况下weight.data()会返回内存上的参数值。因为我们指定了2块GPU来初始化模型参数,所以需要指定显存来访问参数值。我们看到,相同参数在不同显卡的显存上的值一样。
In [5]: weight = net[0].params.get('weight')try:weight.data()except RuntimeError:print('not initialized on', mx.cpu())weight.data(ctx[0])[0], weight.data(ctx[1])[0]not initialized on cpu(0)Out[5]: ([[[-0.01473444 -0.01073093 -0.01042483][-0.01327885 -0.01474966 -0.00524142][ 0.01266256 0.00895064 -0.00601594]]], [[[-0.01473444 -0.01073093 -0.01042483][-0.01327885 -0.01474966 -0.00524142][ 0.01266256 0.00895064 -0.00601594]]])
8.5.2 多GPU训练模型
当使用多块GPU来训练模型时,Trainer实例会自动做数据并行,例如,划分小批量数据样本并复制到各块显卡的显存上,以及对各块显卡的显存上的梯度求和再广播到所有显存上。这样,我们就可以很方便地实现训练函数了。
In [6]: def train(num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)ctx = [mx.gpu(i) for i in range(num_gpus)]print('running on:', ctx)net.initialize(init=init.Normal(sigma=0.01), ctx=ctx, force_reinit=True)trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})loss = gloss.SoftmaxCrossEntropyLoss()for epoch in range(4):start = time.time()for X, y in train_iter:gpu_Xs = gutils.split_and_load(X, ctx)gpu_ys = gutils.split_and_load(y, ctx)with autograd.record():ls = [loss(net(gpu_X), gpu_y)for gpu_X, gpu_y in zip(gpu_Xs, gpu_ys)]for l in ls:l.backward()trainer.step(batch_size)nd.waitall()train_time = time.time() - starttest_acc = d2l.evaluate_accuracy(test_iter, net, ctx[0])print('epoch %d, time %.1f sec, test acc %.2f' % (epoch + 1, train_time, test_acc))
首先在单块GPU上训练模型。
In [7]: train(num_gpus=1, batch_size=256, lr=0.1)running on: [gpu(0)]epoch 1, time 14.9 sec, test acc 0.87epoch 2, time 13.5 sec, test acc 0.90epoch 3, time 13.6 sec, test acc 0.92epoch 4, time 13.6 sec, test acc 0.91
然后尝试在2块GPU上训练模型。与8.4节使用的LeNet 相比,ResNet-18 的计算更加复杂,通信时间比计算时间更短,因此 ResNet-18 的并行计算所获得的性能提升更佳。
In [8]: train(num_gpus=2, batch_size=512, lr=0.2)running on: [gpu(0), gpu(1)]epoch 1, time 7.8 sec, test acc 0.81epoch 2, time 7.0 sec, test acc 0.87epoch 3, time 7.0 sec, test acc 0.89epoch 4, time 7.0 sec, test acc 0.91
小结
- 在Gluon中,可以很方便地进行多GPU计算,例如,在多GPU及相应的显存上初始化模型参数和训练模型。
本文截选自《动手学深度学习》,阿斯顿·张(Aston Zhang),李沐(Mu Li),[美] 扎卡里·C. 立顿 等 著。

本书面向希望了解深度学习,特别是对实际使用深度学习感兴趣的大学生、工程师和研究人员。本书不要求读者有任何深度学习或者机器学习的背景知识,读者只需具备基本的数学和编程知识,如基础的线性代数、微分、概率及Python编程知识。本书的附录中提供了书中涉及的主要数学知识,供读者参考。
本书的英文版Dive into Deep Learning是加州大学伯克利分校2019年春学期“Introduction to Deep Learning”(深度学习导论)课程的教材。截至2019年春学期,本书中的内容已被全球15 所知名大学用于教学。本书的学习社区、免费教学资源(课件、教学视频、更多习题等),以及用于本书学习和教学的免费计算资源(仅限学生和老师)的申请方法在本书配套网站zh.d2l.ai上发布。读者在阅读本书的过程中,如果对书中某节内容有疑惑,也可以扫一扫书中对应的二维码寻求帮助。