案例:决策树decision tree泰坦尼克号幸存者预测
案例包括:(1)数据预处理(2)模型训练(3)做优参数组合选择(交叉验证)
1 数据预处理
import pandas as pd
def read_data(path):
"""数据预处理"""
df=pd.read_csv(path,index_col=0)
#丢弃无用数据
df.drop(['Name','Cabin','Ticket'],axis=1,inplace=True)
#处理性别数据
df['Sex']=(df['Sex']=='male').astype('int')
#处理Embarked数据
labels=df['Embarked'].unique().tolist()
df=df.replace(to_replace=labels,value=[0,1,2,3])
#处理缺失数据
df=df.fillna(0)
return df
train=read_data('train.csv')
train.head(3)| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|---|
| PassengerId | ||||||||
| 1 | 0 | 3 | 1 | 22.0 | 1 | 0 | 7.2500 | 0 |
| 2 | 1 | 1 | 0 | 38.0 | 1 | 0 | 71.2833 | 1 |
| 3 | 1 | 3 | 0 | 26.0 | 0 | 0 | 7.9250 | 0 |
2 模型训练
from sklearn.cross_validation import train_test_split
X=train.iloc[:,1:]
y=train.iloc[:,0]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
print('train dataset:{0};test dataset:{1}'.format(X_train.shape,X_test.shape))train dataset:(712, 7);test dataset:(179, 7)
from sklearn.tree import DecisionTreeClassifier
clf=DecisionTreeClassifier()
clf.fit(X_train,y_train)
train_score=clf.score(X_train,y_train)
test_score=clf.score(X_test,y_test)
print('train_score:{0};test_score:{1};'.format(train_score,test_score))train_score:0.9873595505617978;test_score:0.7541899441340782;
训练评分高,测试评分低,过拟合
3 优化模型参数(手动)
(可跳过,直接看下一节使用模型选择工具包)
3.1 参数选择max_depth
def cv_score(d):
"""选择一系列max_depth参数,并计算得分"""
clf=DecisionTreeClassifier(max_depth=d)
clf.fit(X_train,y_train)
tr_score=clf.score(X_train,y_train)
cv_score=clf.score(X_test,y_test)
return (tr_score,cv_score)
#构造参数范围,在范围内分别计算模型评分,找出评分最高的模型对应的参数
depths=range(2,15)
scores=[cv_score(d) for d in depths]
tr_scores=[s[0] for s in scores]
cv_scores=[s[1] for s in scores]
#找出交叉验证数据集评分最高的索引
import numpy as np
best_secore_index=np.argmax(cv_scores)
best_secore=cv_scores[best_secore_index]
best_param=depths[best_secore_index]
print('best_param:{0};best_secore:{1};'.format(best_param,best_secore))
#画出参数与评分
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure()
plt.grid()
plt.xlabel('max depth of decision tree')
plt.ylabel('score')
plt.plot(depths,cv_scores,'.g-',label='cross_validation score')
plt.plot(depths,tr_scores,'.r--',label='training score')
plt.legend()best_param:3;best_secore:0.7932960893854749;

3.2 参数选择min_impurity_split
def cv_score(val):
"""选择一系列min_impurity_split参数,并计算得分"""
clf=DecisionTreeClassifier(criterion='gini',min_impurity_split=val)
clf.fit(X_train,y_train)
tr_score=clf.score(X_train,y_train)
cv_score=clf.score(X_test,y_test)
return (tr_score,cv_score)
#指定参数范围,分别训练模型并计算评分
values=np.linspace(0,0.5,50)
scores=[cv_score(v) for v in values]
tr_scores=[s[0] for s in scores]
cv_scores=[s[1] for s in scores]
#找出评分最高的模型参数
best_secore_index=np.argmax(cv_scores)
best_secore=cv_scores[best_secore_index]
best_param=values[best_secore_index]
print('best_param:{0};best_secore:{1}'.format(best_secore,best_secore))
#画出模型参数与模型频评分的关系
plt.figure()
plt.grid()
plt.xlabel('min_impurity_split of decision tree')
plt.ylabel('score')
plt.plot(values,cv_scores,'.g-',label='cross_validation score')
plt.plot(values,tr_scores,'.r--',label='train_score')
plt.legend()best_param:0.8156424581005587;best_secore:0.8156424581005587

以上手动对模型参数进行选择,存在缺陷(1)每次运行,训练集,测试集数据随机,因此最优参数每次都不同(2)不能选择多个参数的最优组合
4 模型参数选择工具包
GridSearchCV
4.1 用GridSearchCV选择一个参数的最优值
from sklearn.model_selection import GridSearchCV
thresholds=np.linspace(0,0.5,50)
#设置参数矩阵
param_grid={'min_impurity_split':thresholds}
clf=GridSearchCV(DecisionTreeClassifier(),param_grid,cv=5)
clf.fit(X,y)
print('best_param:{0}\nbest score:{1}'.format(clf.best_params_,clf.best_score_))
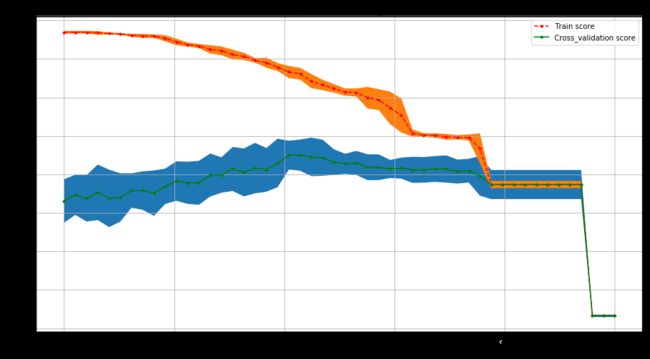
def plot_curve(train_sizes,cv_results,xlabel):
train_scores_mean=cv_results['mean_train_score']
train_scores_std=cv_results['std_train_score']
test_scores_mean=cv_results['mean_test_score']
test_scores_std=cv_results['std_test_score']
plt.figure(figsize=(15,8))
plt.title('parameters turning')
plt.grid()
plt.xlabel(xlabel)
plt.ylabel('score')
plt.fill_between(train_sizes,
test_scores_mean-test_scores_std,
test_scores_mean+test_scores_std
)
plt.fill_between(train_sizes,
train_scores_mean-train_scores_std,
train_scores_mean+train_scores_std
)
plt.plot(train_sizes,train_scores_mean,'.--',color='r',label='Train score')
plt.plot(train_sizes,test_scores_mean,'.-',color='g',label='Cross_validation score')
plt.legend(loc='best')
plot_curve(thresholds,clf.cv_results_,xlabel='gini thresholds')
best_param:{'criterion': 'gini', 'min_impurity_split': 0.2040816326530612}
best score:0.8260381593714927
4.1 用GridSearchCV选择多个参数的最优组合
from sklearn.model_selection import GridSearchCV
entropy_thresholds=np.linspace(0,1,50)
gini_thresholds=np.linspace(0,0.5,50)
#设置参数矩阵
param_grid=[{'criterion':['entropy'],'min_impurity_split':entropy_thresholds},
{'criterion':['gini'],'min_impurity_split':gini_thresholds},
{'max_depth':range(2,10)},
{'min_samples_split':range(2,30,2)}]
clf=GridSearchCV(DecisionTreeClassifier(),param_grid,cv=5)
clf.fit(X,y)
print('best_param:{0}\nbest score:{1}'.format(clf.best_params_,clf.best_score_))best_param:{'criterion': 'gini', 'min_impurity_split': 0.2040816326530612}
best score:0.8260381593714927