机器学习之支持向量机(Support Vector Machine)
机器学习之支持向量机(Support Vector Machine)
-
- 一、关于SVM的理解
- 二、Hard Margin SVM
- 三、Soft Margin SVM
- 四、处理线性的数据
- 五、处理非线性的数据
- 六、核函数
- 七、超函数
一、关于SVM的理解
支撑向量机(Support Vector Machin,SVM)可以解决分类问题,也可以用于解决回归问题。这里仅对分类问题进行一些粗浅的讨论。
在分类问题中,分类算法会将数据空间划分为一个或多个边策边界(高维时称为超平面),边策边界的一边是一类,另一边是另一类。但是,不同的分类算法会对相同的数据生成不同的决策边界。那么,哪个决策边界才是最好的呢?这个问题称为不适定问题对于SVM来说,它的目的就是尽可能地找到一个合适的边界,来提高算法的泛化能力,即鲁棒性。
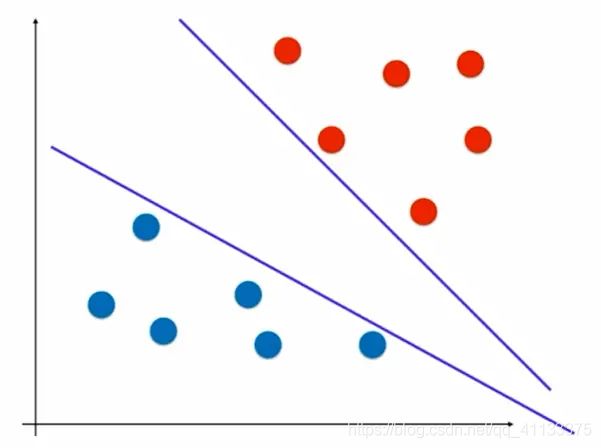
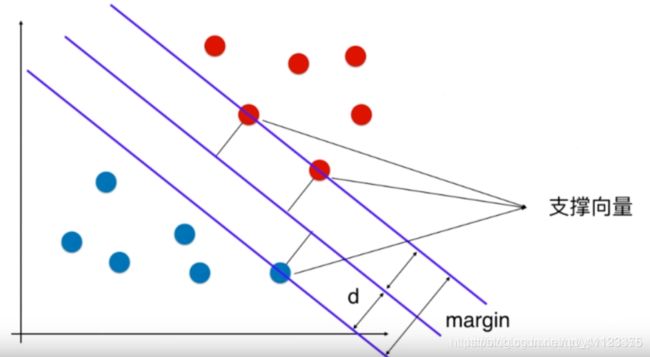
所以说SVM的具体操作是:寻找一个最优的决策边界,距离两个类别的最近的样本最远。最近的样本点称为支撑向量。
我们首先讨论线性可分的问题,当线性不可分的时候,我们有改进的方法。
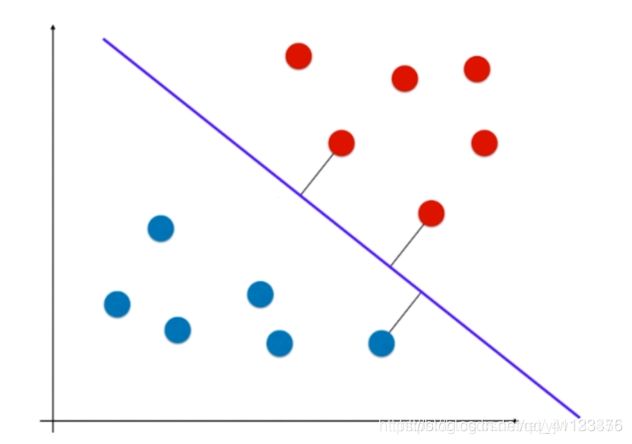
上面这个就是一条比较好的边策边界,它离红色样本点和蓝色样本点一样远。在两个类别中,离决策边界最近的那些点都尽可能的远。红色样本有两个点,蓝色样本有一个点,这三个点到决策边界的距离是所有样本点中最近的,且距离是相等的。
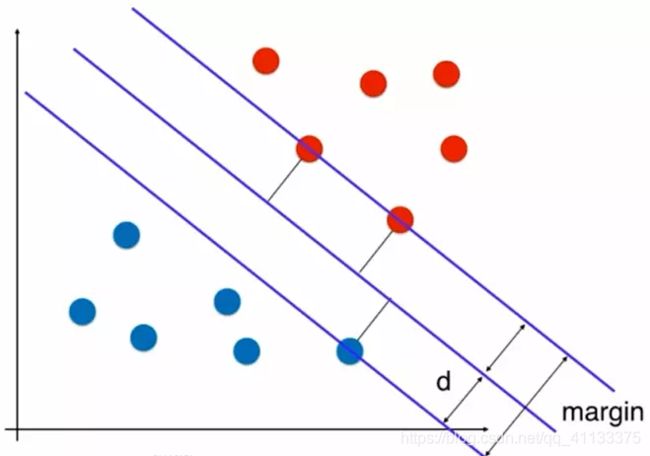
这三个点定义出了两条和决策边界平行的线。这两条平行线之间没有任何的样本点。这就是支持向量机的思想。
SVM尝试找到中间那条最优的决策边界,这个决策边界距离两个类别最近的样本最远。
这两条平行线离决策边界的距离相等,记为d,margin就是2d。
SVM就是要最大化margin。
二、Hard Margin SVM
上面的图中,样本点是线性可分的,即可以找到一条决策边界使得分类不会出错,这时候使用的SVM算法称为Hard Magin SVM。此时的算法至少在训练集上是不会发生错误的。但是实际情况中,很多数据是线性不可分的,这时SVM可以通过改进得到 Soft Margin SVM 。
下面我们用数学语言来表达。
直线的一般式方程:
![]()
点到直线的距离:

当我们拓展到n维空间的时候,可以写成下面这种形式:
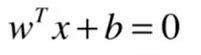
距离公式就变成:
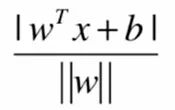
我们定义类A的值为1,类B的值为-1。在图中可以看到,类A的支撑向量距离决策边界的距离为d,类B上的支撑向量距离决策边界的距离也为d。那么我们就可以将公式写成下面这种形式:
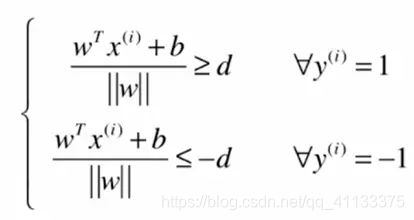
因为向量W的模和距离d都为常数,所以我们可以将两边都除以d:

||w||是一个标量, d也是一个标量,我们可想象把 w^T每个元素和b都除以分母 ||w||d这个标量,我们用新的字母来表示除以之后的结果:
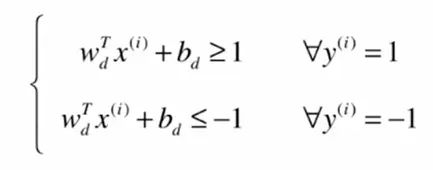
下标d说明截距和向量 w 已经被 d 和 w 的模相除。
因为定义了类A的值为1,类B的值为-1,那么可以写成一个式子:
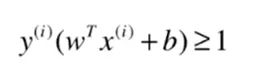
对于所有支撑向量,满足这样的方程:
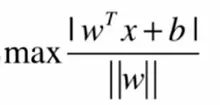
即求模的最小值。实际工程中为了求导得到最小值,使用的是第二个式子
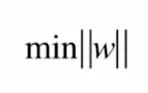

整个支持向量机的最优化问题就变成了,在条件
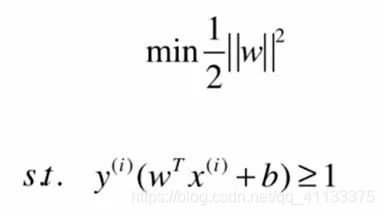
的情况下求最优化。具体的求解比较复杂,大家可以查看相关资料学下 。
三、Soft Margin SVM
如果数据线性不可分,那么如果要使用SVM算法,就需要允许分类算法犯一定的错误,具体方法是让限定条件变得宽松一点:
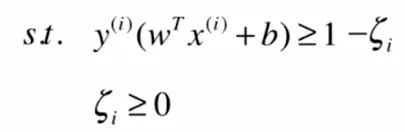
那么随之求解目标也会有所改变。这里增加了一个超参数C,来控制正则项的重要程度。C越小容错空间越大,C趋向于0的时候,允许无限大的误差,趋向于无穷大的时候,算法本质就是Hard Margin SVM。
L1正则化:

L2正则化:
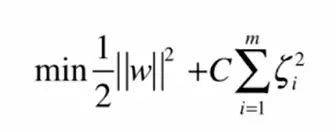
四、处理线性的数据
鸢尾花数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris.data
y = iris.target
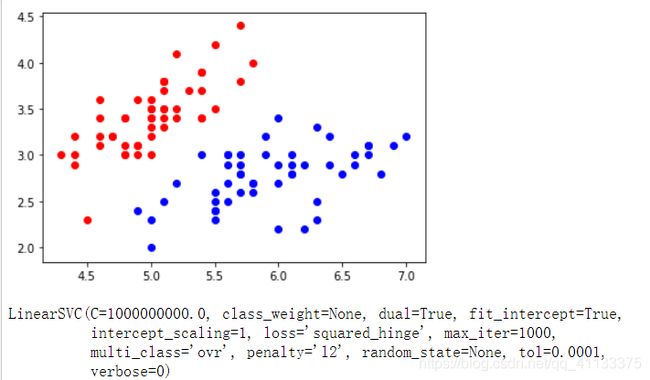
X = X [y<2,:2] #只取y<2的类别,也就是0 1并且只取前两个特征
y = y[y<2] # 只取y<2的类别 # 分别画出类别0和1的点
plt.scatter(X[y==0,0],X[y==0,1],color='red')
plt.scatter(X[y==1,0],X[y==1,1],color='blue')
plt.show()
#标准化
standardScaler = StandardScaler()
standardScaler.fit(X) #计算训练数据的均值和方差
X_standard = standardScaler.transform(X) #再用scaler中的均值和方差来转换X,使X标准化
svc = LinearSVC(C=1e9) #线性SVM分类器
svc.fit(X_standard,y) # 训练svm
原始数据点分布:
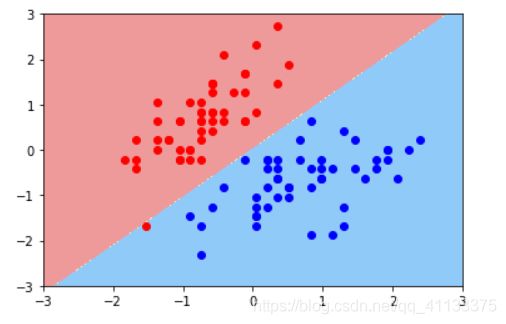
当我们训练好之后,就可以绘制这个决策边界:
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
# 绘制决策边界
plot_decision_boundary(svc,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
边界绘制结果:

我们上面说了C是控制正则项的重要程度,这里我们再次实例化一个svc,并传入一个较小的C。
svc2 = LinearSVC(C=0.01)
svc2.fit(X_standard,y)
plot_decision_boundary(svc2,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
可以很明显的看到和第一个决策边界的不同,在这个决策边界汇总,有一个红点是分类错误的。
C越小容错空间越大。
我们可以通过 svc.coef_ 来获取学习到的权重系数, svc.intercept_ 获取偏差。
五、处理非线性的数据
月亮数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X, y = datasets.make_moons() #使用生成的数据
print(X.shape)
# (100,2)
print(y.shape)
# (100,)
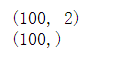
接下来绘制生成的数据:
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
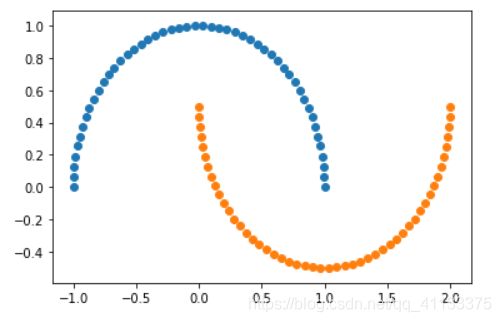
生成的数据集太规范了,我们增加一些噪声点:
X, y = datasets.make_moons(noise=0.15,random_state=777) #随机生成噪声点,random_state是随机种子,noise是方差
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
我们接下来通过多项式特征的SVM来对它进行分类。
```python
from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
def PolynomialSVC(degree,C=1.0):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),#生成多项式
("std_scaler",StandardScaler()),#标准化
("linearSVC",LinearSVC(C=C))])#最后生成svm
这里我们引入了管道,它可以将许多算法模型串联起来,比如将特征提取、归一化、分类组织在一起形成一个典型的机器学习问题工作流。
poly_svc = PolynomialSVC(degree=3)
poly_svc.fit(X,y)
plot_decision_boundary(poly_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()

可以看到生成的边界不再是线性的直线了。
我们还可以使用核技巧来对数据进行处理,使其维度提升,使原本线性不可分的数据,在高维空间变成线性可分的。再用线性SVM来进行处理。
from sklearn.svm import SVC
def PolynomialKernelSVC(degree,C=1.0):
return Pipeline([ ("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="poly"))]) # poly代表多项式特征
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X,y)
plot_decision_boundary(poly_kernel_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
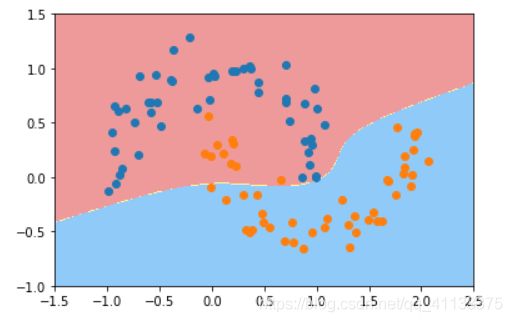
可以看到这种方式也生成了一个非线性的边界。
这里 SVC(kernel=“poly”) 有个参数是 kernel ,就是核函数。
六、核函数
核函数包括线性核函数、多项式核函数、高斯核函数等,其中高斯核函数最常用,可以将数据映射到无穷维,也叫做径向基函数(Radial Basis Function 简称 RBF),是某种沿径向对称的标量函数。
在机器学习中常用的核函数,一般有这么几类,也就是LibSVM中自带的这几类:
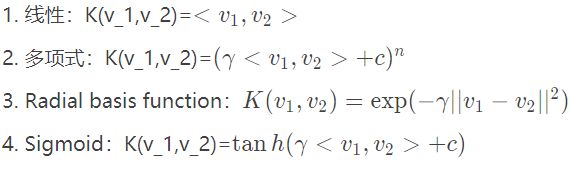
高斯核函数
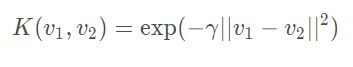
我们看下高斯函数的式子,发现高斯核函数和高斯函数很像。
高斯函数

高斯核函数的本质是将每个样本点映射到一个无穷多维度的特征空间中。
核函数都是依靠升维使得原本线性不可分的数据变得线性可分。
在多项式特征中,假如原本的数据是x的话,我们把原来的数据都变成 x^2这样就变得线性可分了。
原本的数据是一维的,它是线性不可分的,我们无法只画一条直线将它们分开。
下面我们用代码实现升维:
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-4,5,1)#生成测试数据
y = np.array((x >= -2 ) & (x <= 2),dtype='int')
plt.scatter(x[y==0],[0]*len(x[y==0]))# x取y=0的点, y取0,有多少个x,就有多少个y
plt.scatter(x[y==1],[0]*len(x[y==1]))
plt.show()
运行结果:
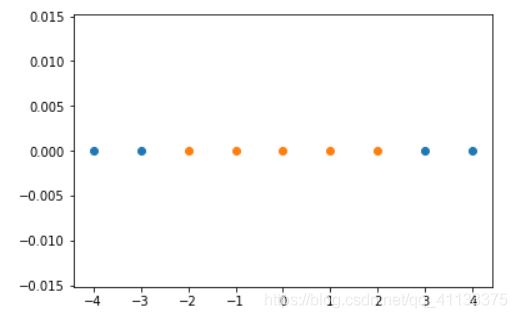
接下来使用高斯核函数,看如何将一个一维的数据映射到二维的空间:
#高斯核函数
def gaussian(x,l):
gamma = 1.0
return np.exp(-gamma * (x -l)**2)
l1,l2 = -1,1
X_new = np.empty((len(x),2)) #len(x) ,2
for i,data in enumerate(x):
X_new[i,0] = gaussian(data,l1)
X_new[i,1] = gaussian(data,l2)
plt.scatter(X_new[y==0,0],X_new[y==0,1])
plt.scatter(X_new[y==1,0],X_new[y==1,1])
plt.show()
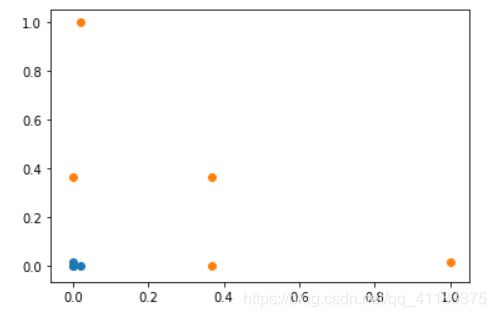
对于这样的二维数据显然是线性可分的:
如果我们的样本点是无穷多个的,那么它就会映射出无穷维的数据(如果向量 y y 每个维度的值都不同的话)。但是通常我们的样本再多也是有限的,因此最终得到的是有限维的映射。
七、超函数
高斯函数
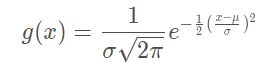
在高斯函数中, σ σ σ越大,分布就越宽。

而核函数中的 γ γ γ类似于 1 2 σ 2 2 σ 21 \frac{1}{2\sigma^2} 2 σ 2 1 2σ212σ21
所以, γ \gamma γ越大,高斯分布越窄; γ \gamma γ 越小,高斯分布越宽。
接下来用代码来演示下 γ \gamma γ 的取值对结果的影响。
首先是生成我们的数据集:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X,y = datasets.make_moons(noise=0.15,random_state=777)
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
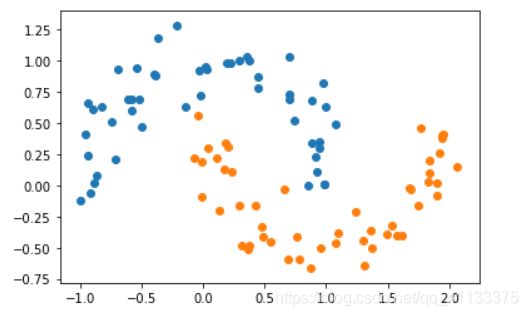
接下来定义一个RBF核的SVM:
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma=1.0):
return Pipeline([ ('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma)) ])
svc = RBFKernelSVC()
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
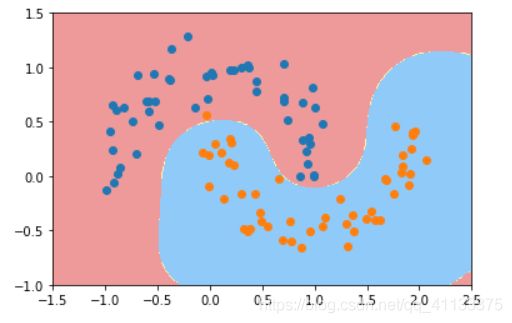
这是我们设置 γ \gamma γ=1.0时所得到的决策边界。我们调整下它的值为100再试下:
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma=1.0):
return Pipeline([ ('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma)) ])
svc = RBFKernelSVC(100)
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
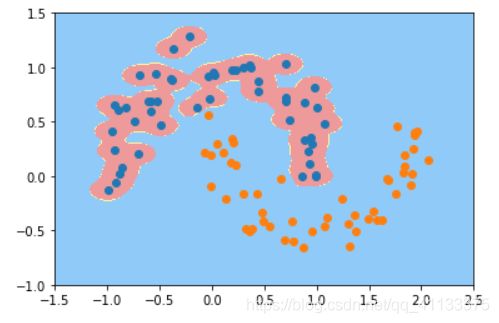
γ \gamma γ取值越大,就是高斯分布的钟形图越窄,这里相当于每个样本点都形成了钟形图。很明显这样是过拟合的。
我们再设置一下 γ \gamma γ,svc = RBFKernelSVC(10)
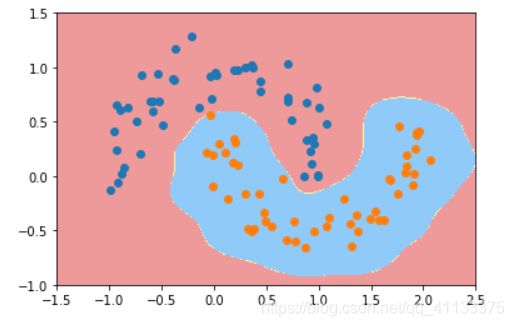
再调整为0.1试试
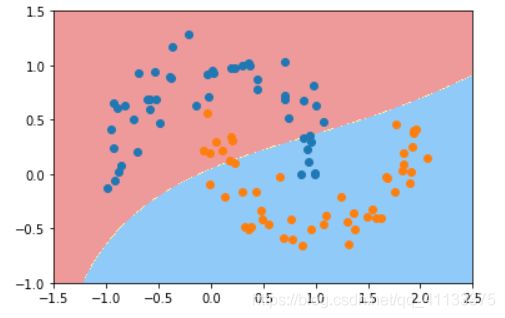
此时它是欠拟合的。
因此,我们可以看出 γ \gamma γ值相当于在调整模型的复杂度。
最后我们再看一下准确度:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=777) # 把数据集拆分成训练数据和测试数据
from sklearn.svm import LinearSVR
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
def StandardLinearSVR(epsilon=0.1):
return Pipeline([ ('std_scaler',StandardScaler()),
('linearSVR',LinearSVR(epsilon=epsilon)) ])
svr = StandardLinearSVR()
svr.fit(X_train,y_train)
svr.score(X_test,y_test) #0.6989278257702748
![]()
大家有什么问题可以提出来一起讨论!