Python 数据分析 —— Numpy
文章目录
- 小引 —— 为什么要学numpy?
- numpy 简介
- numpy用法:
-
- 创建数组 —— numpy.array()
- 生成整数序列 —— numpy.arange()
- 生成等差数列 —— numpy.linspace()
- 生成0到1随机数的数组 —— numpy.random.rand()
- 生成服从标准正态分布随机数的数组 —— numpy.random.randn()
- 生成随机整数数组 —— numpy.random.randint()
- 一维数组基本方法
- 多维数组基本方法
- 多维数组切片
- numpy数组的切片是引用
- 一维花式索引
- 二维花式索引
- 不完全索引 (不完全给出行和列的值)
- where语句
- 数组元素类型转换
-
- asarray 函数
- astype 方法
- 实际操作
-
- 以豆瓣十部高分电影为例
- 数组排序
- 求和
- 最大值
- 最小值
- 均值
- 标准差
- 相关系数矩阵
- 多维数组操作
-
- 数组形状
- 转置
- 普通方法的数组连接
- 其实,Numpy提供了分别对应这三种情况的函数
- 堆叠数组常用的三个函数
- numpy内置函数
-
- numpy.abs(数组)
- numpy.exp(数组)
- numpy.median(数组)
- numpy.cumsum(数组)
- 练习
小引 —— 为什么要学numpy?
当然是方便咯!!!
问题1:
现有一个数组 a = [1,2,3,4] ,想要把里面的每个元素都 加1,变成 [2,3,4,5],如何操作?
解:
[x+1 for x in a]

问题2:
现又有一个数组 b = [2,3,4,5] ,想让 a数组和 b数组对应位置上元素相加,如何操作?
解:
[x+y for (x,y) in zip(a,b)]

这两个问题学了Python基础都可以做出来,但问题是很麻烦!!!
这时候就需要找到一个更简单的方法简化数组的操作。
numpy 简介
NumPy(NumericalPython)
是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested liststructure) 结构要高效的多(该结构也可以用来表示矩阵 matrix),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
使用时注意先导包!!!
import numpy as np
这是最常用的导包方法
如果这样导
import numpy
每用一次numpy方法都得numpy.方法,numpy字母多多呀,不嫌长吗?
如果这样导
from numpy import *
虽然写法简单了,用方法时直接 方法 即可,不用numpy.了。但这样会出现和其他函数或方法重名时的冲突。
所以,我们就用
import numpy as np
写法简单,还不会重名

numpy用法:
创建数组 —— numpy.array()
numpy.array()能创建并自定义一个数组
格式:
numpy.array(里面放数组)
一维:
a = np.array([1,2,3,4])
此时数组a长这样

注意:列表外面是没有array()的,numpy.array()方法创建的数组才有!
此时,数组做任何操作都简单了
二维:
a = np.array([[1,2,3,4],[5,6,7,8]])

数组中每个元素都 +1
a + 1

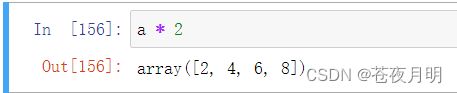
数组中每个元素都 *2
a * 2
两个数组,各位置上元素相加
b = np.array([2,3,4,5])
a + b

也可以这样创建数组
c = np.array([0]*4)

生成整数序列 —— numpy.arange()
numpy.arange() 能生成整数序列
格式:
numpy.arange(开头,结尾,步长)
生成整数序列 1到10,不包括10
a = np.arange(1,10)

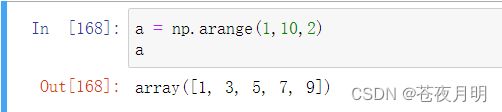
还能指定 步长(间隔)
a = np.arange(1,10,2)
生成等差数列 —— numpy.linspace()
numpy.linspace() 能生成等差数列
格式:
numpy.linspace(开头,结尾,中间有几个数)
生成等差数列 从1到10,一共5个数的等差数列
a = np.linspace(1,10,5)

生成0到1随机数的数组 —— numpy.random.rand()
numpy.random.rand() 能生成多维随机数数组
格式:
numpy.random.rand(d0,d1,d2...,dn)
dn表示每个维度,d0第一维,d1第二维…
生成 从0到1的,第一维有10个随机数的一维数组
np.random.rand(10)

生成 从0到1的,第一维有2个随机数、第二维有3个随机数的二维数组

生成 从0到1的,第一维有2个随机数、第二维有2个随机数、第三维有3个随机数的三维数组

生成服从标准正态分布随机数的数组 —— numpy.random.randn()
numpy.random.randn() 能生成服从标准正态分布的随机数
格式:
numpy.random.randn(d0,d1,d2...,dn)
dn表示每个维度,d0第一维,d1第二维…
生成服从标准正态分布的,第一维有10个随机数的一维数组
np.random.randn(10)

生成服从标准正态分布的,第一维有2个随机数、第二维有3个随机数的二维数组

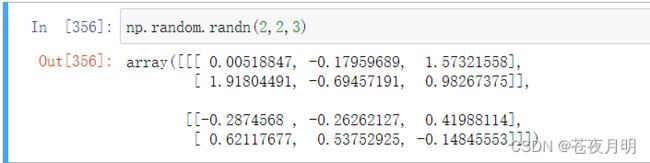
生成服从标准正态分布的,第一维有2个随机数、第二维有2个随机数、第三维有3个随机数的三维数组
生成随机整数数组 —— numpy.random.randint()
numpy.random.randint() 能生成随机整数数组
格式:
numpy.random.randint(开头,结尾,维度)
一维直接写数字就行;大于一维,维度那里写成size=(d0,d1,d2,...,dn)
生成随机整数 1到10,第一维有5个随机数的一维数组
np.random.randint(1,10,5)

生成随机整数 1到10,第一维有2个随机数、第二维有3个随机数的二维数组

生成随机整数 1到10,第一维有2个随机数、第二维有2个随机数、第三维有3个随机数的三维数组

一维数组基本方法
np.zeros 生成的数组里面全为0,并且默认浮点数
d = np.zeros(4)

np.ones 生成的数组里面全为1,并且默认浮点数
f = np.ones(4)

注意:只有zeros和ones,没有twos及往后
dtype 指定数组元素类型
np.ones(4,dtype='bool')

fill 将数组设为指定值
a = np.array([1,2,3,4])
a.fill(5)

如果fill中的数据类型和原数组数据类型不符,则按原数组数据类型转换
a.fill(2.5)
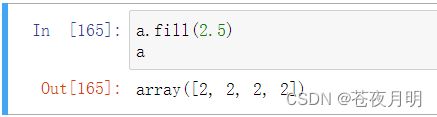
此时数组中元素的数据类型不变,还是原数组的数据类型,fill()中数字的数据类型强制转换了。
astype 强制数据类型转换
a = a.astype('float')
a.fill(2.5)

a.astype(‘float’) 把 a数组强制类型转换为了 floot型数据,再 fill()时,数据类型相同,下面数组就修改成功了。
看变量的类型
type(a)

a是 numpy中多维数组(ndarray)类型的。
查看数组中的数据类型
a.dtype

查看数组形状。会返回一个元组,每一个元组代表这一维的元素数目
a.shape

第一维有5个元素,第二维没元素。
查看数组里元素的数目
a.size

查看数组维度
a.ndim
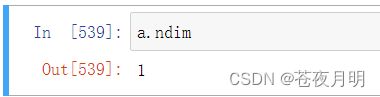
a是一维数组,只有一个维度

a是二维数组,就有两个维度
索引元素
a = np.array([1,2,3,4])
a[0]
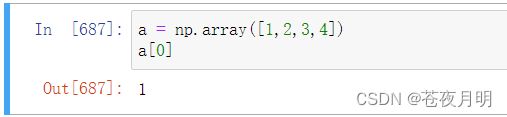
这是基操,不用看都得会!
修改元素
a[0] = 10

切片。支持负索引

省略参数

小问题:
假设记录一部电影的累计票房,并计算每天的票房
# 累计票房
ob = np.array([2100,2180,2224,2345,2500])
# 每天的票房,即[ ob[1]-ob[0],ob[2]-ob[1],ob[3]-ob[2],ob[4]-ob[3] ] 这样一个数组
ob1 = ob[1:] - ob[:-1]

多维数组基本方法
查看数组形状。会返回一个元组,每一个元组代表这一维的元素数目
a = np.array([[1,2,3,4],[5,6,7,8]])
a.shape

数组形状 2行4列。
查看数组里元素的数目
a.size

查看数组维度
a.ndim

a是二维数组,就有两个维度
多维数组索引,传2个数字
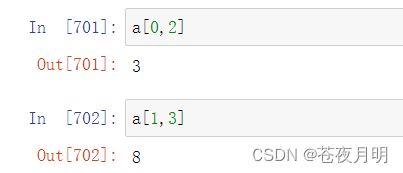
利用索引赋值
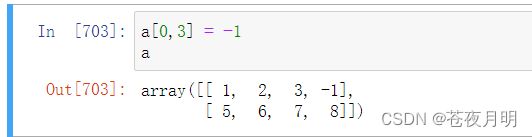
使用单个索引来索引一整行内容

多维数组切片
先创建一个二维数组
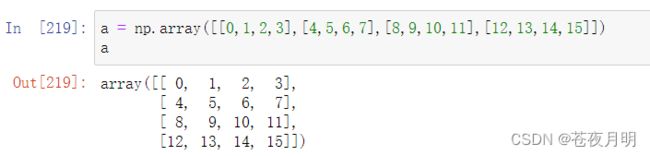
a = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]])


每一维都支持切片的规则,包括负索引、省略
格式:[lower:upper:step]

numpy数组的切片是引用
切片在内存中使用的是引用机制
引用机制意味着:Python不会为这个切片分配新的地址空间储存它的值。因此对切片重新赋值后,整个数组的值也会发生改变。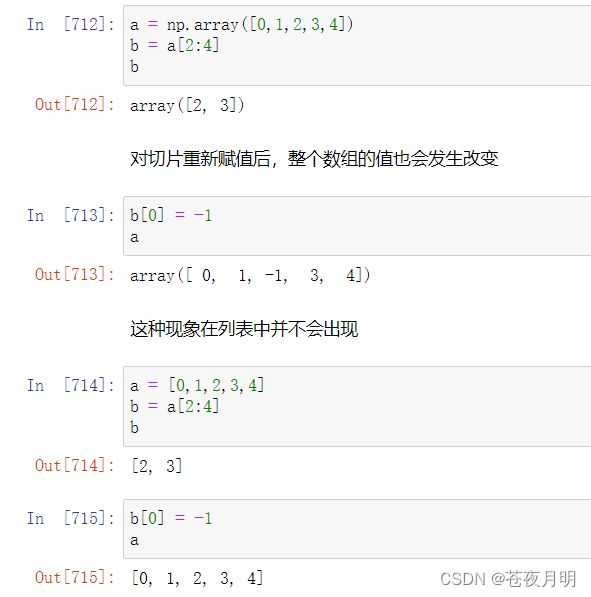
引用机制的
优点在于:对于很大的数组,不用大量复制多余的值,节约了空间;
缺点在于:可能出现改变一个值而间接改变另一个值。
解决方法:用 copy() 方法产生一个复制,这个复制会申请新的内存

PS:切片只能支持连续或者间隔的切片操作,要想实现任意位置的操作,需要使用花式索引
一维花式索引
先使用 arange 函数来产生等差数组
a = np.arange(0,100,10)


这都是基操了,必须会!
但注意,不能写成这样
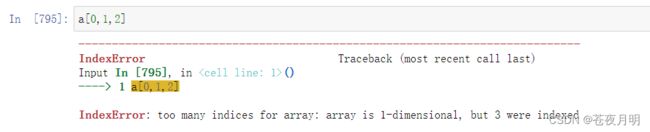
注意 [ ] 中括号个数
还可以使用布尔数组来花式索引(这以前倒是没见过)
利用dtype属性
mask = np.array([2,4,1,0,3,0,4,0,8,1],dtype = bool)

利用 dtype = bool(无 ’ '),把数组中的数据改成了bool类型值。
mask 是布尔数组。长度必须和数组长度相等,才能与数组进行花式索引。
a[mask]

取 mask中True位置的数,False位置的数丢掉

二维花式索引
先创建一个二维数组
a = np.array([[0,1,2,3],[4,5,6,7],[8,9,10,11],[12,13,14,15]])

对于二维花式数组,我们需要给定行和列的值。
返回对角线上的4个值
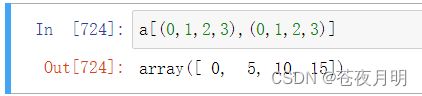
注意两个括号 [ ]()位置,前后两个括号()里元素位置一一对应,相当于取了 (0,0),(1,1),(2,2),(3,3)
返回次对角线(对角线上方挨着的)的3个值

相当于取了(0,1),(1,2),(2,3)
返回后3行的1,3,4列
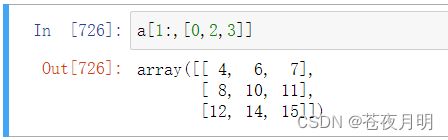
注意括号的改变!!!当一边利用切片时,另一边就得用 [ ] 中括号
错误示范:
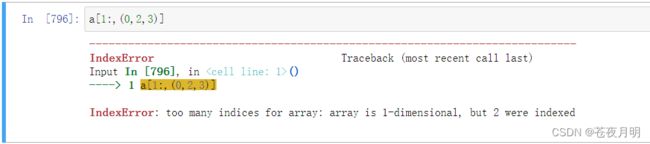
括号没改就会:
IndexError: too many indices for array: array is 1-dimensional, but 2 were indexed
索引器错误:数组的索引太多:数组是一维的,但索引了2个
只用mask进行索引
mask = np.array([1,0,0,1],dtype = bool)
必须把数组中元素类型转化为 bool,否则下面索引时会报错!
mask索引格式:
[ 行,mask ] 第几行被mask索引
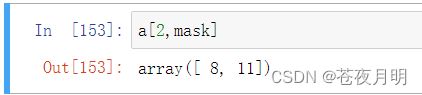
第二行用了 mask索引,[1,0,0,1]意思是 取,不取,不取,取,所以第二行8,11被取了
[mask,列] 第几列被mask索引

第二列用了 mask索引,[1,0,0,1]意思是 取,不取,不取,取,所以第二列2,14被取了
与切片不同,花式索引返回的是原数组的一个复制而不是引用,原数组没变!!!
不完全索引 (不完全给出行和列的值)
只给定索引的时候,返回整行
取前三行

用花式索引取1,3,4行

用花式索引取1,3,4列

0:4 表示取所有行,这个不能省略!
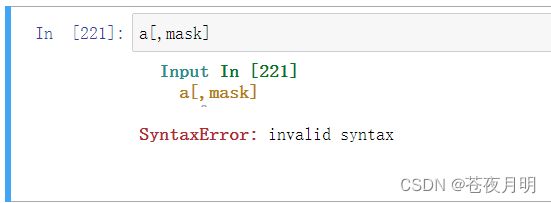
省略就错了!!!
where语句
格式:
numpy.where (array)
where 函数会返回所有非零元素的索引
先创建一个数组
a = np.array([12,0,9,16])
判断数组中的元素是不是大于10:

可以看到每个位置上元素的判断情况
找到数组中所有大于10的元素的索引位置:

0,3 位置的元素都大于10
取数组中所有大于10的元素:

其实就是上一步再加了一步,把下标放进数组里就得到了具体值
也可以用数组操作:
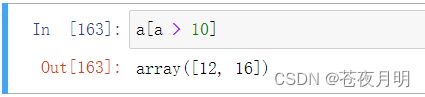
a > 10 返回的是跟 a等长的bool类型数组,这样写相当于mask索引
数组元素类型转换
创建数组时,直接加 dtype属性

asarray 函数
对数组元素的类型进行具体调整

astype 方法
astype 方法返回一个指定类型的新数组

数组a 不变,复制出来个新数组b 变的类型
实际操作
以豆瓣十部高分电影为例
## 电影名称
mv_name = ['肖申克的救赎','控方证人','美丽人生','阿甘正传','霸王别姬','泰坦尼克号','辛德勒名单','这个杀手不太冷','疯狂动物城','海豚湾']
## 评分人数
mv_num = np.array([692795,42995,327855,580897,478523,157074,306904,662552,284652,159302])
## 评分
mv_score = np.array([9.6,9.5,9.5,9.4,9.4,9.4,9.4,9.3,9.3,9.3])
## 电影时长(分钟)
mv_length = np.array([142,116,116,142,171,194,195,133,109,92])
数组排序
sort 函数
排序,默认从小到大
np.sort(mv_num)
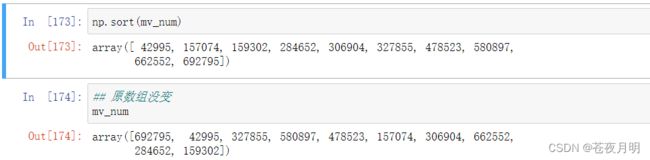
argsort 函数
argsort 返回从小到大排列的数,在数组中的索引位置
order = np.argsort(mv_num)

求和

最大值

最小值

均值

标准差

相关系数矩阵
查看两个数组间的相关性,如:电影评分和电影时长存不存在相关性?

多维数组操作
数组形状
先创建一个数组
a = np.arange(6)

查看数组形状

一维的数组,并且第一维有6个元素
把 a 变成2行3列的矩阵
直接可以 a.shape = 行,列

与shape对应的方法是reshape,但reshape不会修改原来数组的值,而是返回一个新的数组

b = a.reshape(2,3)
a.reshape(2,3)产生并返回了一个新数组给b,此时b就是个2行3列的数组。但a数组的形状并未改变。
转置
转置意思:
行变成列,列变成行
先创建一个数组
a = np.arange(6)
变成2行3列的数组
a = a.reshape(2,3)

转置方法1: 数组.T
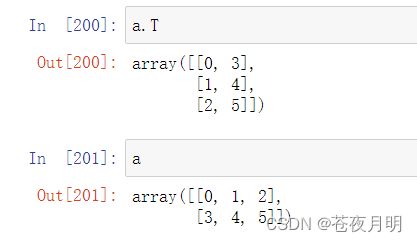
可以看到,数组.T 并不会改变原数组
转置方法2: 数组.transpose()

可以看到,数组.transpose() 也不会改变原数组
总结:
只要转置不赋值给a数组本身,则a数组是不会变化的。
普通方法的数组连接
需求分析:
有时我们需要将不同的数组按照一定的顺序连接起来
方法:
concatenate( ( a0,a1,...,aN ) , axis=0 )
a0,a1…表示数组;axis表示拼接的方向,默认为0:一行一行往下拼接。axis=1:一列一列往右拼接
写法注意:
这些数组要用 () 包括到一个元组中去。除了给定的轴外,这些数组其他轴的长度必须是一样的。
先创建两个2维数组
x = np.array([[0,1,2],[3,4,5]])
y = np.array([[6,7,8],[9,10,11]])
查看一下长相

默认axis=0,沿着第一维进行连接 竖着拼,两个矩阵一上一下

axis=1,沿着第二维进行连接 横着拼,两个矩阵一左一右

还可以把它们连接成三维数组,但是 concatenate 不能提供这样的功能,不过可以这样

其实,Numpy提供了分别对应这三种情况的函数
堆叠数组常用的三个函数
竖向堆叠:vstack
横向堆叠:hstack
构成三维数组:dstack
先回顾一下x,y数组的结构

利用三个函数堆叠数组

numpy内置函数
先创建一个数组
a = np.array([-1,-2,-3,4,-5])
numpy.abs(数组)
数组中每个位置元素都取绝对值

但原数组不变
numpy.exp(数组)
求指数,数组中每个位置元素都求e的x方

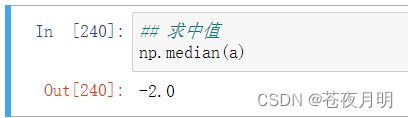
numpy.median(数组)
求中位数
numpy.cumsum(数组)
累计求和,第n个位置上是前n个数之和
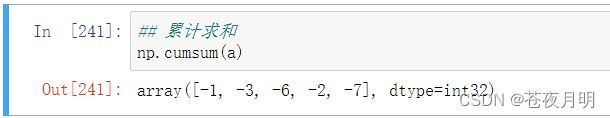
内置函数有很多很多,但不用全记住,也记不住呀。常用的那几个记住就行,不常用的如果用到了,查资料就好。
练习
一、创建一个1到10的数组,然后逆序输出

二、创建一个长度为20的全1数组,然后变成一个4×5的二维矩阵并转置

三、创建一个3×3×3的随机矩阵

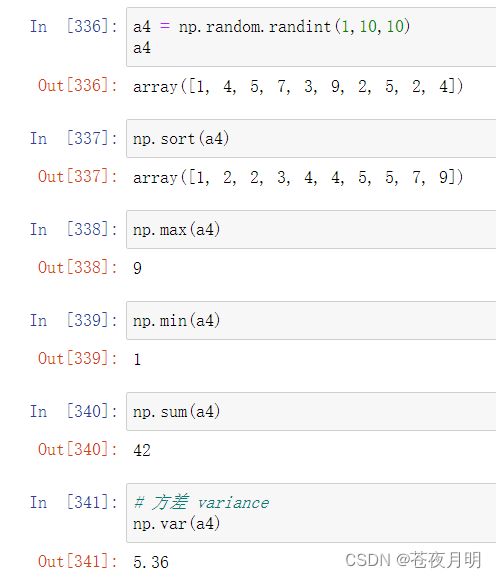
四、从1到10中随机选取10个数,构成一个长度为10的数组,并将其排序。获取其最大值、最小值,求和,求方差
五、从1到10中随机选取10个数,构成一个长度为10的数组,选出其中的奇数

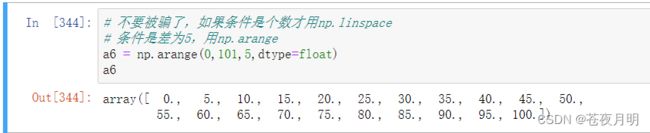
六、生成0到100,差为5的一个等差数列,然后将数据类型转化为浮点数
七、从1到10中随机选取10个数,大于3和小于8的取负数

八、在数组[1,2,3,4,5]中相邻两个数字中间插入1个0

九、新建一个5×5的随机二维数组,交换其中两行,比如交换第一二行

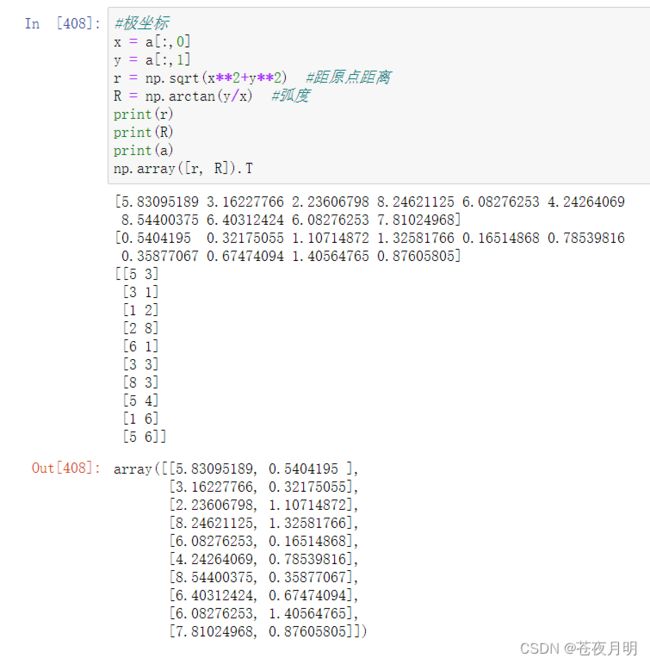
十、把一个10*2的随机生成的笛卡尔坐标转换成极坐标

十一、创建一个长度为10并且除了第五个值为1其余的值为2的向量

十二、创建一个长度为10的随机向量,并将其排序

十三、将数组中的所有奇数替换成-1

十四、构成两个4×3的二维数组,按照3种方法进行连接

十五、获取数组a 和b 中的共同项(索引位置相同,值也相同),a = np.array([1,2,3,2,3,4,3,4,5,6]),b = np.array([7,2,10,2,7,4,9,4,9,8])

十六、从数组a中提取5和10之间的所有项。a = np.array([7,2,10,2,7,4,9,4,9,8])
