基于模板引擎的博客系统
基于模板引擎的博客系统
- 一、搭建项目环境
- 二、设计数据库
- 三、根据数据库设计 Java 对象
-
- 1. Blog 类
- 2. User 类
- 四、封装数据库
-
- JDBC 编程步骤
- 1. 创建一个 DBUtil 类 ( Database Utility )
- 2. 封装 BlogDB ( Blog Database )
- 3. 封装 UserDB( User Database )
- 五、定好思路
-
- 1. 实现每个页面的思想
- 2. 创建 ThymeleafConfig 类
- 3. 使用模板渲染时的步骤
- 六、实现页面
-
- 1. 博客列表页
- 2. 博客内容页
- 3. 博客登录页
-
- 判定登录与注销操作
- 登录用户与文章作者的数据信息
-
- (1) 列表页
- (2) 内容页
- 展示效果
- 4. 博客编辑页
-
- 删除博客
- 总结页面之间的交互逻辑
-
- 1. 博客列表页
- 2. 博客内容页
- 3. 博客登录页
- 4. 博客编辑页
- 总代码
- 页面展示效果
-
- 1. 博客列表页
- 2. 博客内容页
- 3. 博客登录页
- 4. 博客编辑页
一、搭建项目环境
- 创建好目录
- 引入依赖
( Servlet、MySQL、Thymeleaf ) - 往 web.xml 文件中放入一些代码
- 部署程序
( 通过 Smart Tomcat 进行部署 ) - 验证是否就绪
( 通过一个 HelloServlet 类验证 )
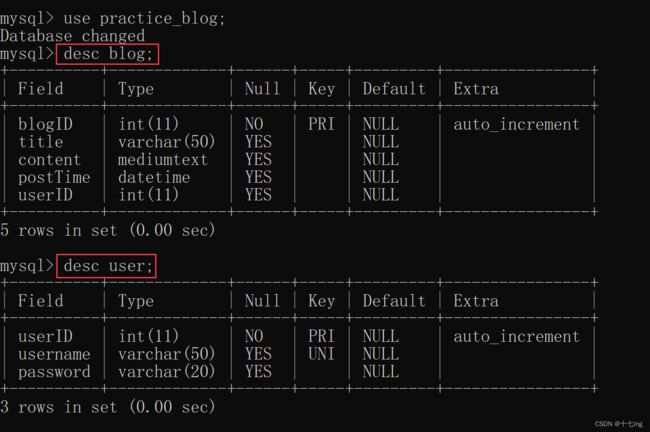
二、设计数据库
- 通过自己写的 sql 语句,往 MySQL 数据库中,插入【blog 表】、【user 表】
【blog 表】 预期用来存储博客的信息 ( 标题、内容、发布时间 )
【user 表】预期用来存储用户的信息 ( 用户账号、用户密码 )
create database if not exists practice_blog;
use practice_blog;
-- 创建博客表
drop if exists blog;
create table blog (
-- 博客 ID (自增主键)
blogID int primary key auto_increment,
-- 博客标题 (字符串类型)
title varchar(50),
-- 博客内容 (字符串类型,表示中等长度文本)
content mediumtext,
-- 博客发布的时间 (日期类型)
postTime datetime,
-- 作者的账号ID
userID int
);
-- 创建用户表
drop if exists user;
create table user (
-- 用户的账号ID (自增主键)
userID int primary key auto_increment,
-- 用户的账号 (保证用户名唯一)
username varchar(50) unique,
-- 用户的密码
password varchar(20)
);
三、根据数据库设计 Java 对象
1. Blog 类
public class Blog {
private int blogID;
private String title;
private String content;
private Timestamp postTime;
private int userID;
}
2. User 类
public class User {
private int userID;
private String username;
private String password;
}
四、封装数据库
JDBC 编程步骤
- 创建数据源
- 和数据库建立连接
- 构造 sql 语句并操作数据库
- 执行 sql
- 遍历结果集(select 查询的时候需要有这一步)
- 释放资源
1. 创建一个 DBUtil 类 ( Database Utility )
DBUtil 这个类,用来封装一些数据库的方法,供外面的类使用。
好处一:外面的类需要创建一些同样的实例, 这些实例是固定的。然而,有了DBUtil这个类,外面的类就不需要每次创建额外的实例,直接从 DBUtil 类 拿即可。
( DBUtil 中的单例模式正是做到了这一点)
好处二:同样地,外面的类需要用到一些同样的方法,有了 DBUtil 这个类,对于代码与数据库之间的一些通用的操作方法,直接从 DBUtil 类 导入即可。
我们可以将 DBUtil 这个类想象成一个充电宝,而将使用这个 DBUtil 公共类的其他类,称为手机、平板、mp3…毫无疑问,充电宝就是为电子设备提供服务的,而这些电子设备其实只有一个目的:通过充电宝这个公共资源为自己充电。
2. 封装 BlogDB ( Blog Database )
(1) insert 方法
插入一篇博客,( 博客从浏览器编写,然后上传到服务器,服务器再上传到数据库 )
(2) searchAll 方法
查找所有博客,为了后续展示在博客列表页
(3) searchOne 方法
查找单篇博客,为了后续展示在博客内容页
(4) deleteOne 方法
删除博客,为了后续在浏览器页面上点击生效
(5) findCount 方法
查找当前用户的文章总数
3. 封装 UserDB( User Database )
(1) insert 方法
插入一名用户,( 从前端输入账号和密码上传到服务器,服务器再上传到数据库 )
(2) searchByUsername 方法
通过 username 来查找用户
(3) searchByUserID 方法
通过 userID 来查找用户
五、定好思路
1. 实现每个页面的思想
- 博客列表页
- 博客内容页
- 博客登录页
- 博客编辑页
博客列表页和博客内容页是基于模板引擎实现的,我们将之前写死的列表页和内容页,稍作改动,变为模板文件,放入 【template】目录下,以备后用。我们可以将这两个模板文件理解为动态页面,即它随着服务器后端的代码改动而改动。
而登录页和编辑页不需要变为模板文件,因为它们本身不需要进行展示,只需要提交,所以,我们可以通过 form 表单的形式来构造 HTTP请求。
必须明确:
-
列表页和内容页是通过 浏览器输入 URL 路径这种形式来构造 HTTP 请求的。这种方式,绝大多数情况下,都是一个 GET 请求,所以,我们需要在 Servlet 代码中,构造 GET 响应。
-
登录页和编辑页是通过 form 表单的形式构造 HTTP 请求的,一般和 input 标签相关的提交按钮,都是 POST 方法。
2. 创建 ThymeleafConfig 类
创建 ThymeleafConfig 类,在类中初始化模板引擎 TemplateEngine,并将其实例化的对象 engine 放入 ServletContext 中,以备后用。
遵循 ( ServletCotext + Listener ) 这个固定写法
ServletCotext 用来存储对象,Listener 是监听器,用来监听 ServletContext.
其他类若想实例化 TemplateEngine 的时候,不必单独实例化了,直接 ServletContext
中拿即可。
// 固定写法: ServletContext + Listener 监听器
@WebListener
public class ThymeleafConfig implements ServletContextListener {
@Override
public void contextInitialized(ServletContextEvent servletContextEvent) {
ServletContext servletContext = servletContextEvent.getServletContext();
// 1. 创建 TemplateEngine 实例, 表示模板引擎
TemplateEngine engine = new TemplateEngine();
// 2. 创建 ServletContextTemplateResolver
ServletContextTemplateResolver resolver = new ServletContextTemplateResolver(servletContext);
resolver.setPrefix("WEB-INF/template/");
resolver.setSuffix(".html");
resolver.setCharacterEncoding("UTF-8");
// 3. 将 resolver 和 engine 联系起来
engine.setTemplateResolver(resolver);
// 4. 将 engine 放到 ServletContext 中,以备后用,它就像冰箱一样,随时拿随时放
servletContext.setAttribute("engine", engine);
System.out.println("TemplateEngine 初始化完毕!");
}
@Override
public void contextDestroyed(ServletContextEvent servletContextEvent) {
}
}
3. 使用模板渲染时的步骤
1. 从 ServletContext 中取出 TemplateEngine 实例
( TemplateEngine 和 ServletContextTemplateResolver 已经在 ThymeleafConfig 类中实现好了,我们直接从 Servlet 中拿对象 engine 即可)
2. 构建好 WebContext,将模板文件的变量和 Java 中的变量联系起来
( 类似于 【 ${blogs} 和 blogs 】这样的替换 )
3. 使用 process 方法,完成模板最终的渲染
六、实现页面
1. 博客列表页
(1) 作用:博客列表页主要用来展示所有博客的摘要
(2) 约定 GET 请求 的路径:" /BlogList "(浏览器通过此路径发送 HTTP 请求)
(3) 针对模板文件:将待显示的内容通过 【 th:text = ${blog…} 】这种形式进行替换
(4) 针对服务器端代码:创建一个 BlogListServlet 来实现模板渲染
(5) 服务器端代码需要遵循模板渲染的步骤。
(6) 通过字符串截取的方式,来控制页面为用户展示的博客字数
// 由于这里显示的是博客内容的摘要,所以,
// 我们约定: 当字符的数量大于 10 的时候,我们通过截取字符串的形式,来放入 blog 对象中
String content = resultSet.getString("content");
if (content.length() > 10) {
content = content.substring(0, 10) + ".......";
}
blog.setContent(content);

(7) 由于页面的内容过长,这就可能导致溢出页面,或者说,内容溢出版心,此时,我们就可以通过设置 CSS 文件来弥补这一缺点。
如下代码:当内容溢出页面的时候,就会自动设置滑动栏,这很实用。
overflow: auto;
2. 博客内容页
(1) 作用:博客内容页用来展示文章的所有信息
(2) 约定 GET 请求 的路径:" /BlogContent?bloglD=… "
(3) 针对模板文件:将待显示的内容通过 【 th:text = ${blog…} 】这种形式进行替换
(4) 针对服务器端代码:创建一个 BlogContentServlet 来实现模板渲染
(5) 服务器端代码需要遵循模板渲染的步骤。
(6) 由于在博客列表页,我们实现了 【查看全文】这样的跳转链接,所以,我们就需要将( 博客列表页 ) 与 ( 博客内容页 ) 配合起来。如何配合?
通过 blogID 这样的路径约定即可,之后,我们就可以在博客内容页中,通过读取请求参数,来锁定到哪篇博客了。
如下代码,在博客列表页对应的模板文件中,将 a 标签用作下列的方式约定。
<a th:href="${ 'BlogContent?blogID=' + blog.blogID }">查看全文 >>a>
3. 博客登录页
(1) 作用:博客登录页是用于实现用户登录的页面,它可以判断用户名和密码各自是否正确。
(2) 约定 POST 请求 的路径:" /BlogLogin "
我们打开写死的博客登录页面,点击【登录】,浏览器自然就发送了 POST 请求,因为我们将【登录】放在了 form 表单下,通过 input 标签实现的。
(3) 针对前端代码:通过 form 表单进行 HTTP 请求的提交,在提交的过程中,需要带上 【username】 和【password】这两个参数,以便于服务器端进行验证。
(4) 针对服务器端代码:创建一个 BlogLoginServlet 来实现 HTTP 响应,登录成功后,预期跳转到博客列表页。
(5) 博客登录页这里,并不需要展示什么,所以,此页面并不需要基于模板文件来支撑渲染。此外,这里的 if 语句进行判断,我们应该考虑到所有的意外情况与不合理的情况
(6) 登录页面的时候,我们可以利用 session 机制。
若登录成功,就将 session 会话创建出来,并将当前登录的用户,以 Java 对象的方式放入会话 session 中,以备后用。若登录失败,就不将 session 会话创建出来。
我们也可以反过来思考:若 session 会话未被创建出来,那就意味着登录失败。
session 机制就和之前的 ServletContext 机制差不多,我们可以将其想象成一个冰箱,随拿随放。
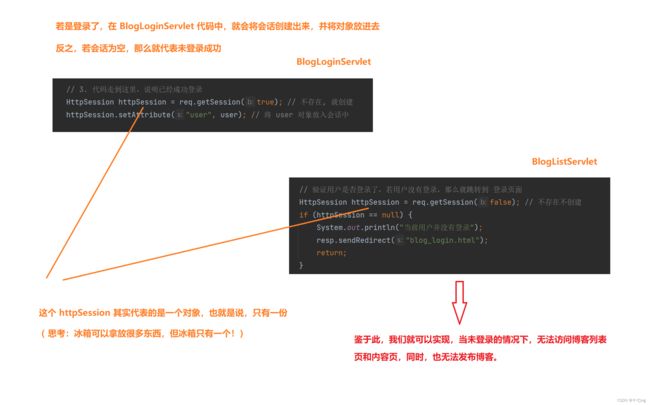
判定登录与注销操作
鉴于上面的思想,我们不仅可以用当前的 session 会话机制判断博客列表页,也可以用它来判断博客内容页,博客发布页的用户登录情况。此外,通过会话机制,也能够应用于注销操作。
所以,我们对上面的代码改进一下,封装一个 Check 类,让上面所说的页面都能够通过这个 Check 类来判断当前用户是否登录了。
public class Check {
public static User checkLogin(HttpServletRequest req) {
HttpSession httpSession = req.getSession(false); // 不存在不创建
if (httpSession == null) {
// 会话未创建,说明当前未登录
return null;
}
User loginUser = (User) httpSession.getAttribute("user");
if (loginUser == null) {
// 用户未创建,说明当前未登录
return null;
}
return loginUser;
}
}
注意 if 语句的顺序,为什么先要判定 httpSession 存在与否呢?这是为了防止空指针异常。【 若 httpSession 为 null,那么,httpSession.getAttribute(“user”) 这行代码就会出现空指针异常 】。
这很好理解:当冰箱都没有的时候,我们怎么从冰箱拿东西呢?所以说,一定是先有冰箱了,我们才能从里面拿东西,才能往里面放东西。
图解验证登录与注销用户的思想:

登录用户与文章作者的数据信息
当用户登录成功后,首先跳转到的是博客列表页,那么,博客列表页就应该显示当前用户的一些信息:头像、昵称、文章总数…接着,若用户点击【查看全文】后,就可以跳转到某一篇博客全文,此时,页面显示的应该是作者信息。
鉴于此,
(1) 将博客列表页展示当前登录者的用户信息
(2) 将博客内容页展示文章作者的用户信息
(1) 列表页
模板文件:(blog_list_template.html)
<h3 th:text="${loginUser.username}">h3>
<span th:text="${count}">span>
服务器端代码:(BlogListServlet)
// 从 BlogDB 这个类中, 查找当前登录用户的文章总数
int count = blogDB.findCount(loginUser.getUserID());
webContext.setVariable("loginUser", loginUser);
webContext.setVariable("count", count);
sql 语句:
// 构造 sql 语句并操作数据库
String sql = " select count(userID) from blog where userID = ?";
(2) 内容页
模板文件:(blog_content_template.html)
<h3 th:text="${author.username}">h3>
<span th:text="${count}">span>
服务器端代码:(BlogContentServlet)
// 将查到的博客,放入 blog 对象中
// 这个时候 blog 对象实际上并不是登录用户,而是代表某篇文章的作者
Blog blog = blogDB.searchOne(Integer.parseInt(blogID));
UserDB userDB = new UserDB();
// 通过 UserDB 类,来查询作者,并将其转化成一个 User 的实例: author
User author = userDB.searchByUserID(blog.getUserID());
int count = blogDB.findCount(blog.getUserID());
webContext.setVariable("author", author);
webContext.setVariable("count", count);
sql 语句:
// 构造 sql 语句并操作数据库
String sql = " select count(userID) from blog where userID = ?";
展示效果
4. 博客编辑页
(1) 作用:博客编辑页是实现让用户用来撰写博客的,它可以在浏览器上进行提交,而后,服务器经过一些处理,让博客的一些数据放入数据库中。
(2) 约定 POST 请求 的路径:" /BlogWriting "
我们打开写死的博客编辑页面,点击【发布文章】,浏览器自然就发送了 POST 请求,因为我们将【发布文章】放在了 form 表单下,通过 input 标签实现的。
(3) 针对前端代码:通过 form 表单进行 HTTP 请求的提交,在提交的过程中,需要带上 【title】 和【content】这两个参数,以便于服务器端进行验证。
然而,这里的代码较为少见,因为当前是根据 jQuery 提供的依赖,才会有这个编辑页面的展示效果,所以,写死的 HTML页面同时需要配合 JS 代码,并且需要基于 【editor.md】的一些写法规则。
body>
<div class="mark">
<form action="BlogWriting" method="POST" style="height: 100%;">
<div class="headline">
<input type="text" class="title" name="title">
<input type="submit" class="submit">
div>
<div id="editor">
<textarea name="content" style="display : none">textarea>
div>
form>
div>
<script>
// 初始化编译器
let editor = editormd("editor", {
//这里的尺寸必须在这里设置,设置样式会被 editormd 覆盖掉
width: "100%",
//设置编译器高度
height: "calc(100% - 60px)",
//编译器的初始内容
markdown: "# 在这里写下一篇博客",
//指定 editor.md 依赖的插件路径
path: "editor.md/lib/",
// 加上这个选项之后,编辑器中的内容才会被放到 textarea 里面
saveHTMLToTextArea: true
});
script>
body>
(4) 针对服务器端代码:创建一个 BlogWritingServlet 来实现 HTTP 响应,登录成功后,预期跳转到博客列表页。
(5) 博客编辑页这里,和博客登录页是一样的思路,并不需要展示什么,所以,此页面并不需要基于模板文件来支撑渲染。此外,这里的 if 语句进行判断,我们应该考虑到所有的意外情况与不合理的情况。
(6) 由于编辑博客的时候,它是依据 markdown 的语法规则,可以让一些字体变成我们想要的格式,例如:一级标题,二级标题,加粗,删除线等等…
我们当前的 CSDN 就是拥有这样的规则。
而在之前的博客列表页显示博客的时候,它是一种素的、原始的文字。就算经过博客发布了,但展示给用户看的时候,并没有经过博客编辑器处理,所以,同样地,我们为博客列表页引入 【editor.md】这样的依赖,并通过 JS 代码,让文字变成处理后的结果。
<div th:text="${blog.content}" id="content" style="background-color: transparent;">div>
<script>
function renderMD() {
let contentDiv = document.querySelector('#content');
// 将博客的原始未被渲染的内容拿出来
let markdown = contentDiv.innerHTML;
// 再将 上面的 content 对应的 div 标签置为空
contentDiv.innerHTML = '';
editormd.markdownToHTML( 'content', {
markdown: markdown
});
}
renderMD();
script>
实现思想:
markdown 的原始内容,放在上面的 div 中,我们可以将这个 div 中的内容给取出来,然后再通过上面的 markdownToHTML 函数进行转换,最后,将转换后的结果写回到原先的这个 div 中。
展示效果:
删除博客
删除博客,可以通过 a 标签构造 GET 请求,之后在服务器端进行处理。
思想:在博客内容页,若当前登录用户和博客作者是同一个人,即可以删除;若不是同一个人,则不能删除,只能观看。
约定 GET 请求 路径:" /BlogDelete?blogID=… "
根据 blogID 进行判断,删除哪一篇博客。
模板文件:
<!-- 这里的跳转链接可以通过 blogID 参数, 来删除博客 -->
<a th:if="${deleteLabel}" th:href=" ${'BlogDelete?blogID=' + blog.blogID} ">删除博客</a>
服务端代码:
下面的是 BlogContentServlet 类下的代码,BlogDeleteServlet 就不展示了,那是业务逻辑,而下面的是模板渲染的关键代码。
// 若登录的用户和博客作者是同一个人,那么就显示【删除博客】这个 a 标签
webContext.setVariable("deleteLabel", loginUser.getUserID() == author.getUserID());
总结页面之间的交互逻辑
1. 博客列表页
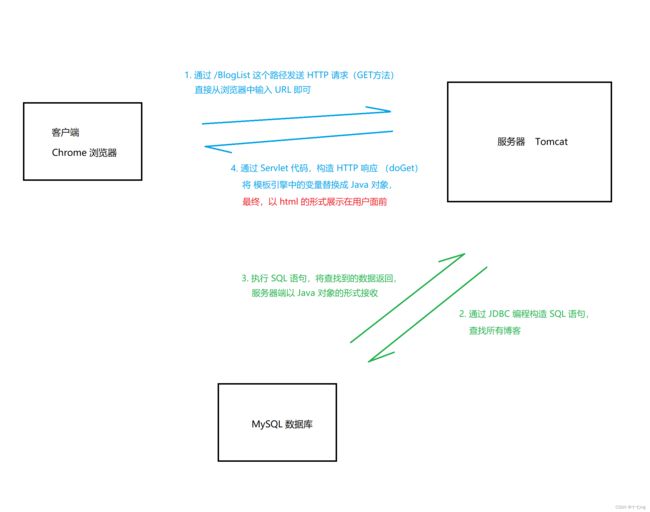
2. 博客内容页

3. 博客登录页

4. 博客编辑页

总代码

页面展示效果
1. 博客列表页
2. 博客内容页
3. 博客登录页
4. 博客编辑页
本篇博客在于理解模板引擎的思想,下一篇博客写的是基于前后端分离的博客系统,以后,对于博客系统的修改,都基于下一篇博客进行。毕竟基于前后端分离的思想,是当前时代的主流 Web 开发方式。