干货!用于文本图表示学习的GNN嵌套Transformer模型:GraphFormers
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

本期AI TIME PhD直播间,我们邀请到微软亚洲研究院与中国科学技术大学联合培养在读博士生——杨俊涵,为我们带来报告分享《用于文本图表示学习的GNN嵌套Transformer模型:GraphFormers》。

杨俊涵:
微软亚洲研究院与中国科学技术大学联合培养在读博士生,主要研究方向为推荐系统、信息检索、文本表示学习。

文本图上的表示学习
(Textual Graph Representation)
旨在构建融合中心与邻域文本特征的图节点向量表示。此类技术在文本检索,在线广告,推荐系统中有着广泛的应用。
预训练语言模型(PLM: Pretrained Language Model)与图神经网络(GNN: Graph Neural Network)是生成高质量的文本图表示的基本模块。
目前主流的研究通常借助级联的架构(Cascaded Framework,如图1.A)来整合PLM与GNN [1,2],即先由PLM(e.g., BERT [4])生成各个节点的文本表示,再借助GNN(e.g., GraphSage [3])来融合中心节点与邻域的语义。
笔者认为级联架构是一种相对低效的整合模式:在PLM的编码阶段,各个节点无法有效参照邻域节点的语义信息,进而对文本表示的质量产生不利的影响。
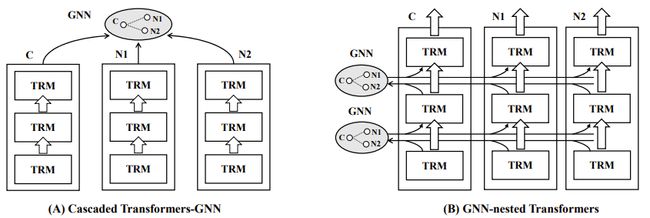
图 1:模型架构对比
在本文中,笔者提出了一种GNN与PLM深度融合的网络架构(GNN-nested Transformers,如图1.B),并将其命名为GraphFormers。
GraphFormers采取了层级化的PLM-GNN整合方式(如图2):在每一层中,每个节点先由各自的Transformer Block进行独立的语义编码,编码结果汇总为该层的特征向量(默认由CLS所关联的hidden state来表征);各节点的特征向量汇集到该层的GNN模块进行信息整合;信息整合的结果被编码至对应各个节点的图增广(graph augmented)特征向量中,并分发至各个节点;各节点依照图增广特征向量进行下一层级的编码。
相较于此前的级联架构,GraphFormers在PLM编码阶段便充分参照了邻域信息,从而大大提升了各节点文本表示的质量。
同时,考虑到节点间的信息交互是借由特征向量在极其轻量GNN模块中进行,每层整体的运算开销与单纯利用 Transformer Block进行各节点独立的编码相差无几。
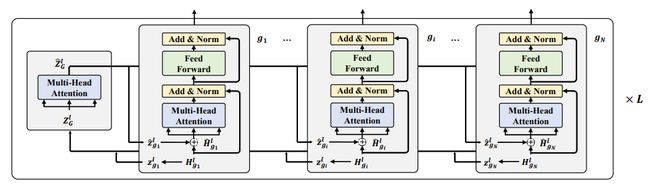
图 2:GNN-nested Transformers详细结构
本文就“边预测任务“在三个大规模文本图数据集上将GraphFormers与目前主流的基于级联架构的方法进行比较。
实验结果显示GraphFormers在各个数据集上均取得了预测精度的大幅提升,进而证明了其强大的语义表征能力(如表1)。
本文同时就推理效率进行了评估:相比传统的级联架构,GraphFormers在引入不同数量邻居时所带来的额外开销微乎其微,从而验证了其高效性与可扩展性(如表2)。
GraphFormers目前已成功应用于微软Bing Search Ads的生产线,并在广告点击量与营收方面取得了显著的提升(如图3)。
最后,本文的方法与模型皆已开源在官方Repo:https://github.com/microsoft/GraphFormers,旨在促进今后图文本表示的技术发展。
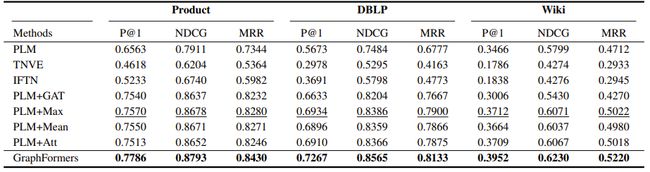
表 1:不同方法在3个数据集上的performance对比。GraphFormers在3个数据集上的性能都超越了之前的SOTA模型。

表 2:模型的时空开销对比。相对原先的级联结构
GraphFormers的额外开销微乎其微

图3:线上 A/B测试。从左至右分别是RPM,CY和CPC的相对提升
(绿色为增长,蓝色为下降)
参考文献:
[1] Zhu J, Cui Y, Liu Y, et al. Textgnn: Improving text encoder via graph neural network in sponsored search[C]//Proceedings of the Web Conference 2021. 2021: 2848-2857.
[2] Li C, Pang B, Liu Y, et al. AdsGNN: Behavior-Graph Augmented Relevance Modeling in Sponsored Search[J]. arXiv preprint arXiv:2104.12080, 2021.
[3] Hamilton W L, Ying R, Leskovec J. Inductive representation learning on large graphs [C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 1025-1035.
[4] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
提
醒
论文题目:
GraphFormers: GNN-nested Transformers for Representation Learning on Textual Graph
论文链接:
https://proceedings.neurips.cc/paper/2021/file/f18a6d1cde4b205199de8729a6637b42-Paper.pdf
点击“阅读原文”,即可观看本场回放
整理:杨俊涵
作者:杨俊涵、刘政、李朝卓
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了600多位海内外讲者,举办了逾300场活动,超150万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看回放!