Kubernetes开放接口:CRI、CNI、CSI
文章目录
- 一、CRI
-
- 1、简介
- 2、OCI具体实现
- 3、运行时的层级
-
-
- (1)高层级运行时
- (2)低层级运行时
-
- 4、docker和containerd
- 5、CRI架构及接口
-
-
- (1)CRI接口大全
- (2)Containerd createContainer接口实现源码
-
- 二、CNI(待整理)
-
- 1、简介
- 2、分类
- 3、运行机制
- 4、插件设计考量
- 5、CNI plugin
-
-
- (1)Flannel
- (2)Calico
-
-
- 【1】原理
- 【2】calico initcontainer(初始化)
- 【3】calico配置文件:
- 【4】calico crd功能介绍
- 【5】CNI插件对比
- 【7】容器内路由策略
-
-
- 三、CSI(待整理)
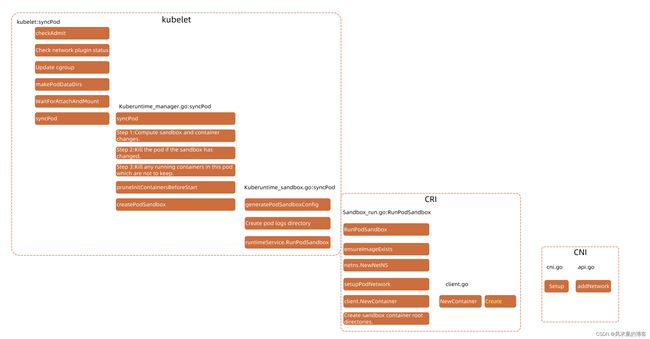
三者执行顺序是怎么样的呢?
严格来说: CSI WaitForAttachAndMount is Attach to node,not mount to container,mount in createContainer) -> CRI(RunPodSandbox) -> CNI(setupPodNetwork) -> CRI(Kubelet NewContainer remote call CRI createContainer)
重点说下CSI WaitForAttachAndMount:
pod被创建时,看到spec.volume,rs可以据此创建pvc,然后会根据storageClass转到相应的provisioner处理,provisioner会根据pvc的参数,再创建一块符合条件的网络存储pv,然后将pv名字填入pvc,就bond在一起了。
然后到了WaitForAttachAndMount阶段之后,因为pod已经明确调度到那个node,因此这里就会
attach pv to node:/data1/kubelet/pods/..., attach好了即可, 而且kubelet还会修改volumeMount字段内容,全部修改成hostPath,如下:
{
"containerPath": "/data100",
"hostPath": "/data1/kubelet/pods/89caa785-cf4a-4411-a2c8-4bbab34a5730/volumes/kubernetes.io~cephfs/pvc-7db18622-e92b-4503-8138-5d3b53c8c166",
"propagation": "PROPAGATION_PRIVATE",
"readonly": false,
"selinuxRelabel": false
},
到了CRI createContainer,就会将container yaml当作参数传给createContainer。
通过上图我们还可以发现,netns.NewNetNS在创建业务容器之前执行的,因此这个应该是根据pause容器设置的,因此可推断同一个pod共享network namespace。复习一下共享:net、ipc(interprocess communication,特例管道不共享,ipcs 查看ipc,ipcmk --queue增加一个队列验证共享消息队列)、user、uts(主机名都是container name)。
一、CRI
1、简介
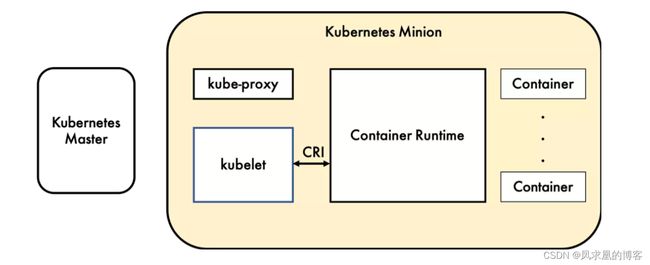
容器运行时(Container Runtime),运行于k8s集群的每个节点中,负责容器的整个生命周期。其中 Docker 是目前应用最广的。
为了解决这些容器运行时和k8s的集成问题,在k8s 1.5版本中,社区推出了 CRI (Container Runtime Interface,容器运行时接口)以支持更多的容器运行时。
2、OCI具体实现
CRI是k8s定义的一组 gRPC 服务。kubelet 作为客户端,基于 gRPC 框架,通过 Socket 和容器运行时通信。
它包括两类服务:镜像服务(Image Service)和运行时服务(Runtime Service)。镜像服务提供下载、检查和删除镜像的远程程序调用。运行时服务包含用于管理容器生命周期,以及与容器交互的调用(exec / attach / port-forward等)
可以看到RuntimeService中包括了容器等一些基本操作,同时也包括了sandbox的一些操作。
3、运行时的层级
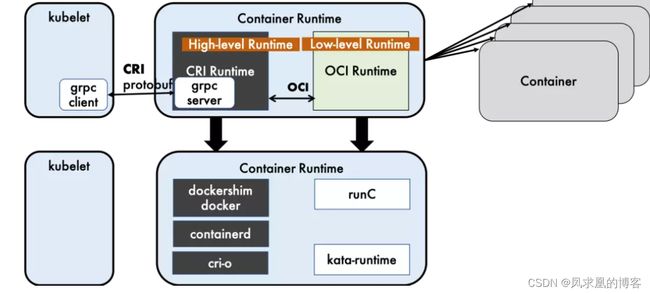
(1)高层级运行时
Docker+Dockershim(docker本身未实现CRI), containerd 和 CRI-O 都是遵循 CRI 的容器运行时,称之为高层级运行时(High-level Runtime)。注意高级运行时,为了更贴合、方便用户,一般是基于低级运行时做了很多扩展丰富的,像docker,可以dockerfile制作镜像、支持zfs 存储驱动等
(2)低层级运行时
OCI (Open Container Initiative,开放容器计划)定义了创建容器的格式和运行时的开源行业标准,包括镜像规范(Image Specification)和运行时规范(Runtime Specification)。
镜像规范定义了 OCI 镜像的标准。高层级运行时将会下载一个 OCI 镜像,并把它解压成 OCI 运行时文件系统包 (filesystem bundle)
运行时规范则描述了如何从 OCI 运行时文件系统包运行容器程序,并且定义它的配置、运行环境和生命周期。如何为新容器设置namepsaces和cgroup,以及挂载根文件系统等等操作。运行时规范的一个参考实现是 runC。我们称其为 低层级运行时(Low-levelRuntime)。除runC 以外,也有很多其他的运行时遵循 OCI 标准,例如 kata-runtime。
4、docker和containerd
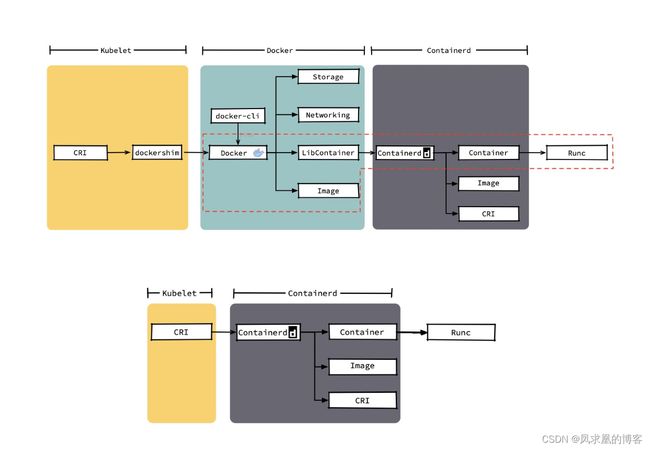
Docker 内部关于容器运行时功能的核心组件是 containerd,现在containerd 也可直接和 kubelet 通过 CRI 对接,独立在 Kubernetes 中使用。
相对于 Docker 而言,containerd 减少了 Docker 所需的处理模块 Dockerd 和 Docker-shim,并且对Docker 支持的存储驱动进行了优化,因此在容器的创建启动停止和删除,以及对镜像的拉取上,都具有性能上的优势。运维更方便。
当然 Docker 也具有很多 containerd 不具有的功能,例如支持
zfs 存储驱动,支持对日志的大小和文件限制,在以 overlayfs2 做存储驱动的情况下,可以通过xfs_quota 来对容器的可写层进行大小限制等。

下图中只要红框内是真正的CRI的docker调用链。其他比如docker-cli,storage,network都是docker附加的。据此可看的出来docker太重了,我们其实只需要能启动、删除容器,拉取镜像,支持CRI就行了,因此 图中下图就是我们想要的,注意下图的Image只能拉取镜像,并不能制作镜像,因此containerd就很轻量级。
5、CRI架构及接口
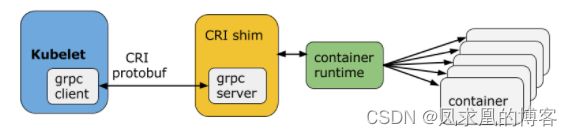
(1)CRI接口大全
Kubernetes1.9中的CRI接口在api.proto中的定义如下:
// Runtime service defines the public APIs for remote container runtimes
service RuntimeService {
// Version returns the runtime name, runtime version, and runtime API version.
rpc Version(VersionRequest) returns (VersionResponse) {}
// RunPodSandbox creates and starts a pod-level sandbox. Runtimes must ensure
// the sandbox is in the ready state on success.
rpc RunPodSandbox(RunPodSandboxRequest) returns (RunPodSandboxResponse) {}
// StopPodSandbox stops any running process that is part of the sandbox and
// reclaims network resources (e.g., IP addresses) allocated to the sandbox.
// If there are any running containers in the sandbox, they must be forcibly
// terminated.
// This call is idempotent, and must not return an error if all relevant
// resources have already been reclaimed. kubelet will call StopPodSandbox
// at least once before calling RemovePodSandbox. It will also attempt to
// reclaim resources eagerly, as soon as a sandbox is not needed. Hence,
// multiple StopPodSandbox calls are expected.
rpc StopPodSandbox(StopPodSandboxRequest) returns (StopPodSandboxResponse) {}
// RemovePodSandbox removes the sandbox. If there are any running containers
// in the sandbox, they must be forcibly terminated and removed.
// This call is idempotent, and must not return an error if the sandbox has
// already been removed.
rpc RemovePodSandbox(RemovePodSandboxRequest) returns (RemovePodSandboxResponse) {}
// PodSandboxStatus returns the status of the PodSandbox. If the PodSandbox is not
// present, returns an error.
rpc PodSandboxStatus(PodSandboxStatusRequest) returns (PodSandboxStatusResponse) {}
// ListPodSandbox returns a list of PodSandboxes.
rpc ListPodSandbox(ListPodSandboxRequest) returns (ListPodSandboxResponse) {}
// CreateContainer creates a new container in specified PodSandbox
rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {}
// StartContainer starts the container.
rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {}
// StopContainer stops a running container with a grace period (i.e., timeout).
// This call is idempotent, and must not return an error if the container has
// already been stopped.
// TODO: what must the runtime do after the grace period is reached?
rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {}
// RemoveContainer removes the container. If the container is running, the
// container must be forcibly removed.
// This call is idempotent, and must not return an error if the container has
// already been removed.
rpc RemoveContainer(RemoveContainerRequest) returns (RemoveContainerResponse) {}
// ListContainers lists all containers by filters.
rpc ListContainers(ListContainersRequest) returns (ListContainersResponse) {}
// ContainerStatus returns status of the container. If the container is not
// present, returns an error.
rpc ContainerStatus(ContainerStatusRequest) returns (ContainerStatusResponse) {}
// UpdateContainerResources updates ContainerConfig of the container.
rpc UpdateContainerResources(UpdateContainerResourcesRequest) returns (UpdateContainerResourcesResponse) {}
// ExecSync runs a command in a container synchronously.
rpc ExecSync(ExecSyncRequest) returns (ExecSyncResponse) {}
// Exec prepares a streaming endpoint to execute a command in the container.
rpc Exec(ExecRequest) returns (ExecResponse) {}
// Attach prepares a streaming endpoint to attach to a running container.
rpc Attach(AttachRequest) returns (AttachResponse) {}
// PortForward prepares a streaming endpoint to forward ports from a PodSandbox.
rpc PortForward(PortForwardRequest) returns (PortForwardResponse) {}
// ContainerStats returns stats of the container. If the container does not
// exist, the call returns an error.
rpc ContainerStats(ContainerStatsRequest) returns (ContainerStatsResponse) {}
// ListContainerStats returns stats of all running containers.
rpc ListContainerStats(ListContainerStatsRequest) returns (ListContainerStatsResponse) {}
// UpdateRuntimeConfig updates the runtime configuration based on the given request.
rpc UpdateRuntimeConfig(UpdateRuntimeConfigRequest) returns (UpdateRuntimeConfigResponse) {}
// Status returns the status of the runtime.
rpc Status(StatusRequest) returns (StatusResponse) {}
}
// ImageService defines the public APIs for managing images.
service ImageService {
// ListImages lists existing images.
rpc ListImages(ListImagesRequest) returns (ListImagesResponse) {}
// ImageStatus returns the status of the image. If the image is not
// present, returns a response with ImageStatusResponse.Image set to
// nil.
rpc ImageStatus(ImageStatusRequest) returns (ImageStatusResponse) {}
// PullImage pulls an image with authentication config.
rpc PullImage(PullImageRequest) returns (PullImageResponse) {}
// RemoveImage removes the image.
// This call is idempotent, and must not return an error if the image has
// already been removed.
rpc RemoveImage(RemoveImageRequest) returns (RemoveImageResponse) {}
// ImageFSInfo returns information of the filesystem that is used to store images.
rpc ImageFsInfo(ImageFsInfoRequest) returns (ImageFsInfoResponse) {}
}
这其中包含了两个gRPC服务:
- RuntimeService:容器和Sandbox运行时管理
- ImageService:提供了从镜像仓库拉取、查看、和移除镜像的RPC。
(2)Containerd createContainer接口实现源码
package server
import (
runtime "k8s.io/cri-api/pkg/apis/runtime/v1alpha2"
containerstore "github.com/containerd/cri/pkg/store/container"
)
// CreateContainer creates a new container in the given PodSandbox.
func (c *criService) CreateContainer(ctx context.Context, r *runtime.CreateContainerRequest) (_ *runtime.CreateContainerResponse, retErr error) {
// config is container.yaml
config := r.GetConfig()
// Get SandboxConfig
sandboxConfig := r.GetSandboxConfig()
// Prepare container image snapshot. For container, the image should have
// been pulled before creating the container, so do not ensure the image.
image, err := c.localResolve(config.GetImage().GetImage())
// Create container image volumes mounts.
var volumeMounts []*runtime.Mount
volumeMounts = c.volumeMounts(containerRootDir, config.GetMounts(), &image.ImageSpec.Config)
// Generate container mounts.
mounts := c.containerMounts(sandboxID, config)
// Get SandboxRuntime(pause container runtime)
ociRuntime, err := c.getSandboxRuntime(sandboxConfig, sandbox.Metadata.RuntimeHandler)
// Get container complete spec from volumeMounts、sandbox_messages、config...
spec, err := c.containerSpec(id, sandboxID, sandboxPid, sandbox.NetNSPath, containerName, config, sandboxConfig, &image.ImageSpec.Config, append(mounts, volumeMounts...), ociRuntime)
// Create initial internal container metadata.
meta := containerstore.Metadata{
ID: id,
Name: name,
SandboxID: sandboxID,
Config: config,
}
specOpts, err := c.containerSpecOpts(config, &image.ImageSpec.Config)
containerLabels := buildLabels(config.Labels, containerKindContainer)
runtimeOptions, err := getRuntimeOptions(sandboxInfo)
opts = append(opts,
containerd.WithSpec(spec, specOpts...),
containerd.WithRuntime(sandboxInfo.Runtime.Name, runtimeOptions),
containerd.WithContainerLabels(containerLabels),
containerd.WithContainerExtension(containerMetadataExtension, &meta))
if cntr, err = c.client.NewContainer(ctx, id, opts...); err != nil {
return nil, errors.Wrap(err, "failed to create containerd container")
}
return &runtime.CreateContainerResponse{ContainerId: id}, nil
}
二、CNI(待整理)
1、简介
Kubernetes 网络模型设计的基础原则是:
- 所有的 Pod 能够不通过 NAT 就能相互访问。
- 所有的节点能够不通过 NAT 就能相互访问。
- 容器内看见的1P 地址和外部组件看到的容器 IP 是一样的。
Kubernetes 的集群里,ip地址是以 Pod 为单位进行分配的,每个 Pod 都拥有一个独立的ip地址。一个 Pod 内部的所有容器共享一个网络栈,即宿主机上的一个网络命名空间,包括它们的ip地址、网络设备、配置等都是共享的。
也就是说,Pod 里面的所有容器能通过 localhost:port 来连接对方。在 Kubernetes 中,提供了一个轻量的通用容器网络接口 CNI (Container Network Interface),专门用于设置和删除容器的网络连通性。容器运行时通过 CNI 调用网络插件来完成容器的网络设置。
2、分类
- IPAM:IP 地址分配
- 主插件:网卡设置
[1] bridge:创建一个网桥,并把主机端口和容器端口插入网桥
[2] ipvlan:为容器添加 ipvlan 网口
[3] loopback:设置 loopback 网口 - Meta:附加功能
[1] portmap:设置主机端口和容器端口映射
[2] bandwidth:利用 Linux Traffic Control 限流
[3] firewall:通过 iptables 或 firewalld 为容器设置防火墙规则
3、运行机制
CNI是由container runtime直接从 CNI 的配置目录中读取 JSON 格式的可执行文件,文件后缀为".conf" “.conflist” “json”。如果配置目录中包含多个文件,一般情况下,会以名字排序选用第一个配置文件作为默认的网络配置,并加载获取其中指定的 CNI 插件名称和配置参数。
对于容器网络管理,容器运行时一般需要配置两个参数--cni-bin-dir 和--cni-conf-dir。有一种特殊情况,kubelet 使用 Docker 作为容器运行时,是由 kubelet 来查找 CNI 插件的,运行插件来为容器设置网络,这两个参数应该配置在 kubelet 处:
- cni-conf-dir:网络插件的配置文件所在目录。默认是
/etc/cni/net.d。
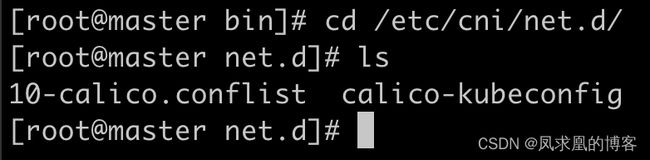
- cni-bin-dir:网络插件的可执行文件所在目录。默认是
/opt/cni/bin。

上图中可以看出来:主插件(calico)、ipam插件(calico-ipam)、meta插件(bandwidth。附加限流功能), kubelet就是通过运行这三个二进制可执行文件来实现为容器设置网络的
4、插件设计考量
- 容器运行时
必须在调用任何插件之前为容器创建一个新的网络命名空间(即netns.NewNetNS)。 - 容器运行时必须决定这个容器属于哪些网络,针对每个网络,哪些插件必须要执行。
- 容器运行时必须加载配置文件,并确定设置网络时哪些插件必须被执行。
- 网络配置采用JSON 格式,可以很容易地存储在文件中。
- 容器运行时
必须按顺序执行配置文件(10-calico.conflist)里相应的插件。 - 在
完成容器生命周期后,容器运行时必须按照与执行添加容器相反的顺序执行插件,以便将容器与网络断开连接。 - 容器运行时被同一容器调用时不能并行操作,但被不同的容器调用时,允许并行操作。
- 容器运行时
针对一个容器必须按顺序执行 ADD 和 DEL 操作,ADD 后面总是跟着相应的 DEL。DEL 可能跟着额外的DEL,插件应该允许处理多个 DEL。 - 容器必须由 ContainerID 来唯一标识,需要存储状态的插件需要使用网络名称、容器ID 和网络接口组成的主key 用于索引。
- 容器运行时
针对同一个网络、同一个容器、同一个网络接口,不能连续调用两次ADD 命令。
5、CNI plugin
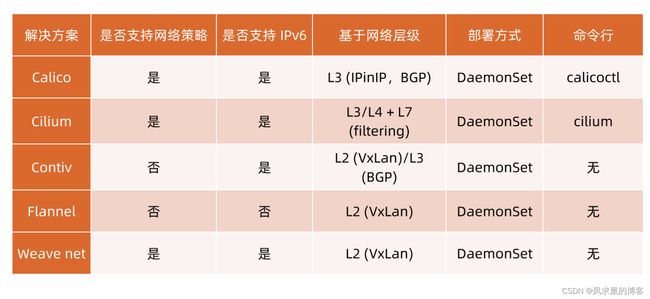
ContainerNetworking 组维护了一些 CNI 插件,包括网络接口创建的 bridge、 ipvlan、 loopback、macvlan、 ptp、 host-device 等,P 地址分配的 DHCP、 host-local 和 static,其他的Flannel、tunning、 portmap、 firewall等。
社区还有些第三方网络策略方面的插件,例如 Calico、Cilium 和 Weave 等。
(1)Flannel
(2)Calico
Calico 以其性能、灵活性和网络策略而闻名,不仅涉及在主机和 Pod 之间提供网络连接,而且还涉及网络安全性和策略管理。
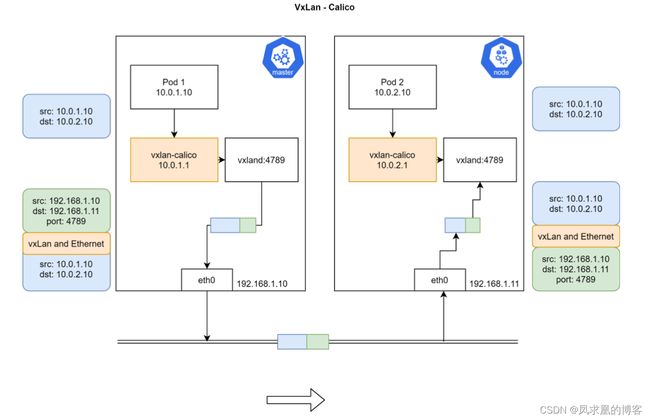
对于同网段通信,基于第3层,Calico 使用 BGP路由协议在主机之间通信,使用 BGP 意味着数据包在主机之间移动时不需要额外的封装。
对于跨网段通信,基于IPinIIP 使用虚拟网卡设备 tunl0,用一个 IP 数据包封装另一个 IP 数据包,外层 IP 数据包头的源地址为隧道入口设备的 IP 地址,目标地址为隧道出口设备的IP 地址。
网络策略是 Calico 最受欢迎的功能之一,使用 ACLS 协议和 kube-proxy 来创建 iptables 过滤规则,从而实现隔离容器网络的目的。
此外,Calico 还可以与服务网格 Istio 集成,在服务网格层和网络基础结构层上解释和实施集群中工作负载的策略。这意味着你可以配置功能强大的规则,以描述 Pod 应该如何发送和接收流量,提高安全性及加强对网络环境的控制。
【1】原理
calico也是以daemonset运行在node上。felix agent是配置防火墙规则的;bird是做路由交换的,进程启动后node可以模拟成一个路由器,这样就可以通过路由协议(BGP)进行通信;confd是做配置推送的。

calico vxlan
【2】calico initcontainer(初始化)
k get ds calico-node -n calico-system -o yaml
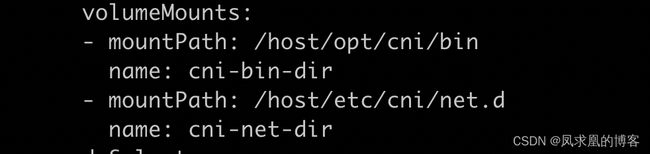
可以看到calico-node有initcontainer,容器命令是/opt/cni/bin/install,配置了volume,通过hostpath的方式把cni插件和配置文件mount到容器中。同时,这些文件是构建在镜像中的,calico-node容器启动时就会把这些文件拷贝到主机上,这样containerd就能调用cni插件了。
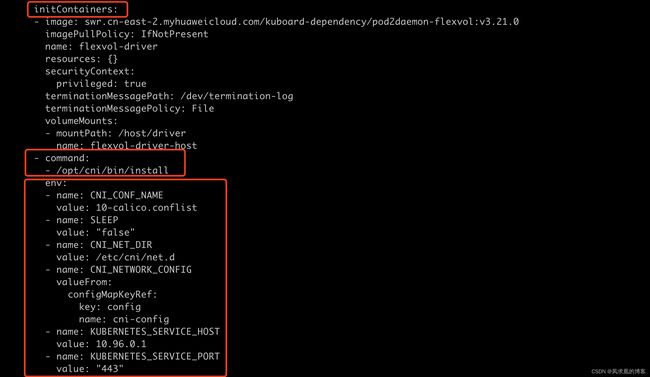
volume:

volumeMounts:
【3】calico配置文件:
cd /etc/cni/net.d/
cat 10-calico.conflist
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1", # CNI的版本
"plugins": [ # plugin列表
{
"type": "calico", # plugin类型,主插件
"datastore_type": "kubernetes",
"mtu": 0,
"nodename_file_optional": false,
"log_level": "Info",
"log_file_path": "/var/log/calico/cni/cni.log",
"ipam": { "type": "calico-ipam", "assign_ipv4" : "true", "assign_ipv6" : "false"}, # ipam类型calico-ipam
"container_settings": {
"allow_ip_forwarding": false
},
"policy": {
"type": "k8s"
},
"kubernetes": { # calico要和apiserver通信
"k8s_api_root":"https://10.96.0.1:443",
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "bandwidth", # meta plugin,开启限流
"capabilities": {"bandwidth": true}
},
{"type": "portmap", "snat": true, "capabilities": {"portMappings": true}}
]
}
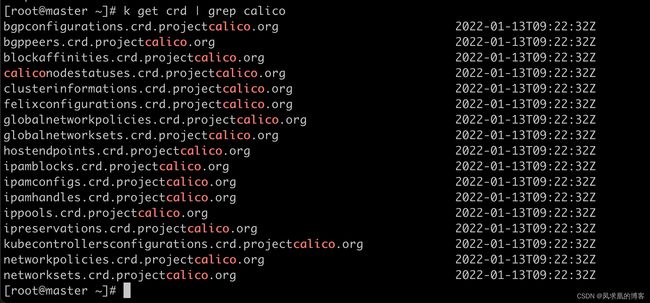
【4】calico crd功能介绍
k get crd | grep calico
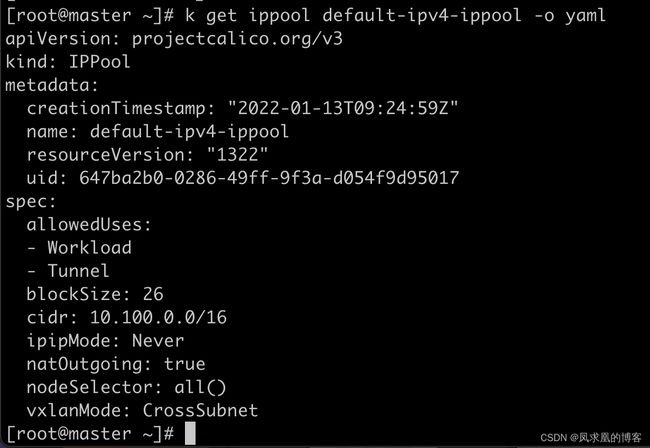
- IPPool CRD
IPPool 用来定义集群的IP地址段。
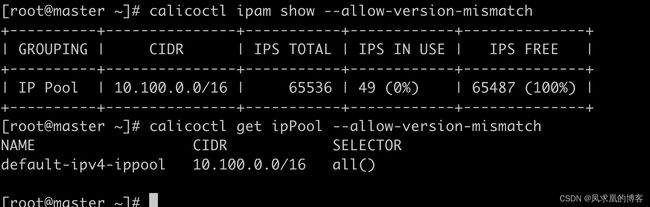
也可以用calicoctl来查看。
calicoctl get ipPool --allow-version-mismatch
calicoctl ipam show --allow-version-mismatch
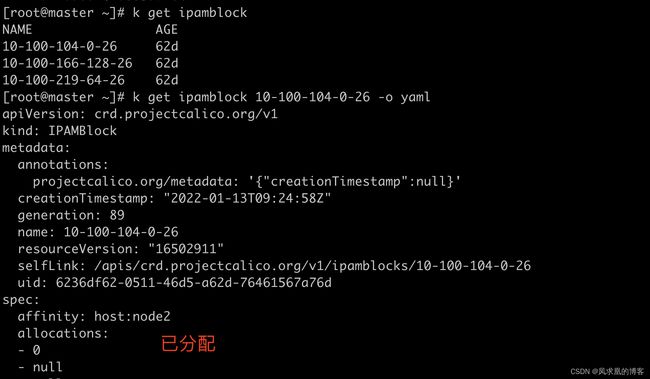
- IPAMBlock CRD
IPAMBlock 用来定义每个主机预分配的IP段。
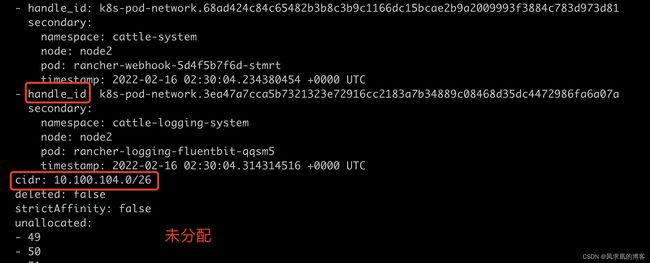
affinity表明是哪个node。这样路由的时候calico就知道往哪个node上转发,即calico知道下一跳是哪个node。
handle_id和secondry表明是哪个pod。
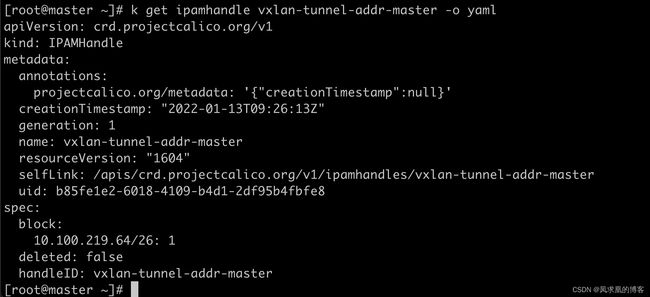
- IPAMHandle CRD
IPAMHandle 用来记录IP分配的具体细节。
【5】CNI插件对比
大型集群,calico的BGP可以采用 RR模式(route reflector)路由反射器模式,即多个节点上报给一个主节点,然后多个主节点之间组成一个mesh网络进行通信。
【7】容器内路由策略
- 查看容器内的路由
nsenter -t 30626 -n ip route

可以看到默认路由下一跳通过eth0发送到169.254.1.1。
- 查看169.254.1.1设备信息
nsenter -t 30626 -n arping 169.254.1.1
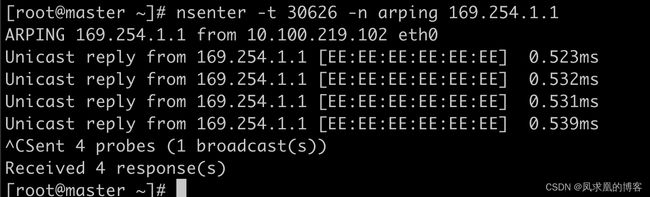
可以看到169.254.1.1和 [EE:EE:EE:EE:EE:EE] 这个mac地址绑定。
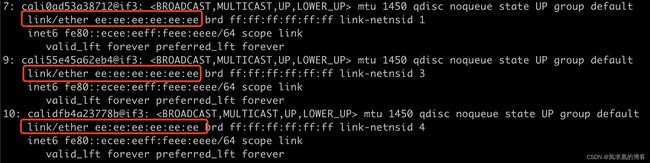
- 查看主机网卡信息
ip a
可以看到所有cali开头的网卡的mac地址都是ee:ee:ee:ee:ee:ee。
三、CSI(待整理)
早期的 Docker 采用 Device Mapper 作为容器运行时存储驱动,因为 OverlayFS 尚未合并进kernel。
目前 Docker 和 containerd 都默认以OverlayFS 作为运行时存储驱动;
OverlayFS 目前已经有非常好的性能,与DeviceMapper 相比优20%,与操作主机文件性能几乎一致。