你好呀,我是居家十三天只出了一次小区门的歪歪。
这篇文章是来填坑的,我以前写文章的时候也会去填之前的一些坑,但是由于拖延症,大多都会隔上上几个月。
这次这个坑比较新鲜,就是之前发布的《没有二十年功力,写不出这一行“看似无用”的代码!》这篇文章,太多太多的朋友看完之后问出了一个相同的问题:

首先非常感谢阅读我文章的朋友,同时也特别感谢阅读的过程中带着自己的思考,提出有价值的问题的朋友,这对我而言是一种正反馈。
我当时写的时候确实没有想到这个问题,所以当突然问起的时候我大概知道原因,由于未做验证,所以也不敢贸然回答。
于是我寻找了这个问题的答案,所以先说结论:
就是和 JIT 编译器有关。由于循环体中的代码被判定为热点代码,所以经过 JIT 编译后 getAndAdd 方法的进入安全点的机会被优化掉了,所以线程不能在循环体能进入安全点。
是的,被优化了,我打这个词都感觉很残忍。

接下来我准备写个“下集”,告诉你我是怎么得到这个结论的。但是为了让你丝滑入戏,我先带你简单的回顾一下“上集”。
另外,先把话说在前面,这知识点吧,属于可能一辈子都遇不到的那种。因此我把它划分到我写的“没有卵用系列”,看着也就图一乐。
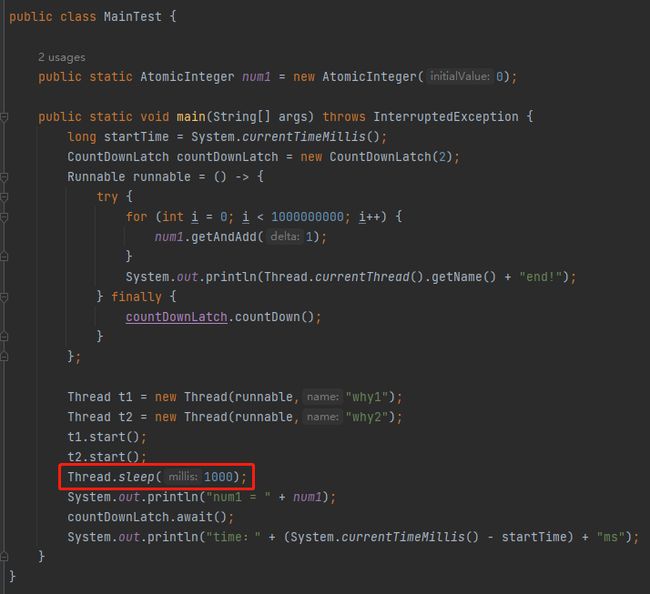
好了,在之前的那篇文章中,我给出了这样的一个测试用例:
public class MainTest {
public static AtomicInteger num = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Runnable runnable=()->{
for (int i = 0; i < 1000000000; i++) {
num.getAndAdd(1);
}
System.out.println(Thread.currentThread().getName()+"执行结束!");
};
Thread t1 = new Thread(runnable);
Thread t2 = new Thread(runnable);
t1.start();
t2.start();
Thread.sleep(1000);
System.out.println("num = " + num);
}
}按照代码来看,主线程休眠 1000ms 后就会输出结果,但是实际情况却是主线程一直在等待 t1,t2 执行结束才继续执行。
运行结果是这样的:

其实我在这里埋了“彩蛋”,这个代码虽然你直接粘贴过去就能跑,但是如果你的 JDK 版本高于 10,那么运行结果就和我前面说的不一样了。
从结果来看,还是有不少人挖掘到了这个“彩蛋”:

所以看文章的时候,有机会自己亲自验证一下,说不定会有意外收获的。
针对程序表现和预期不一致的问题,第一个解决方案是这样的:
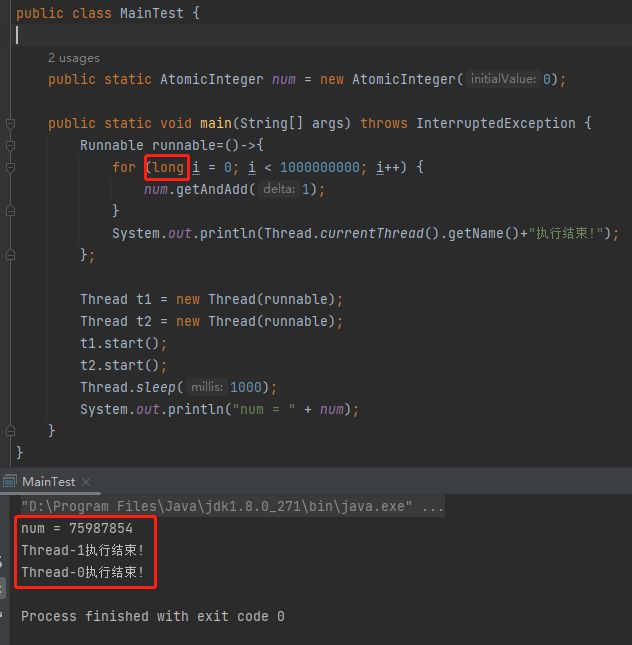
把 int 修改为 long 就搞定了。至于为什么,之前的文章中已经说明了,这里就不赘述了。
关键的是下面这个解决方案,所有的争议都围绕着它展开。
受到 RocketMQ 源码的启示,我把代码修改为了这样:
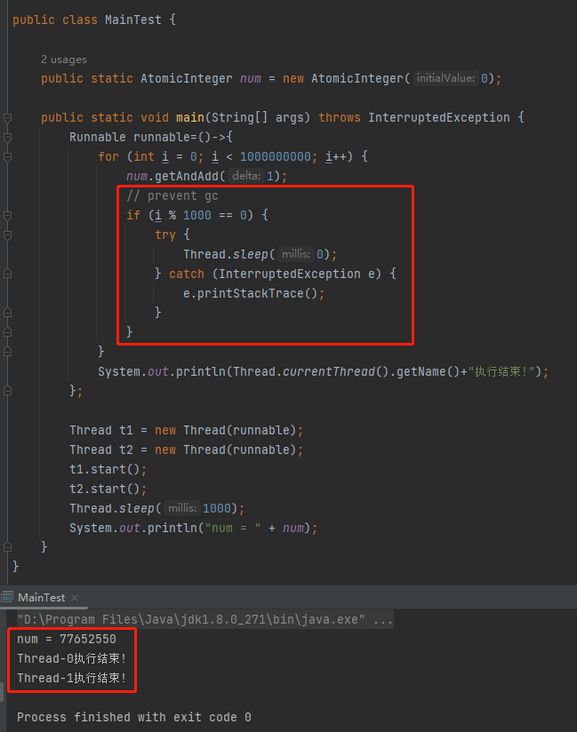
从运行结果上来看 ,即使 for 循环的对象是 int 类型,也可以按照预期执行。
为什么呢?
因为在上集中关于 sleep 我通过查阅资料得出了这样的两个结论:
- 1.正在执行 native 函数的线程可以看作“已经进入了safepoint”。
- 2.由于 sleep 方法是 native 的,所以调用 sleep 方法的线程会进入 Safepoint。
论点清晰、论据合理、推理完美、事实清楚,所以上集演到这里就结束了...

直到,有很多朋友问出了这个问题:
可是 num.getAndAdd 底层也是 native 方法调用啊?
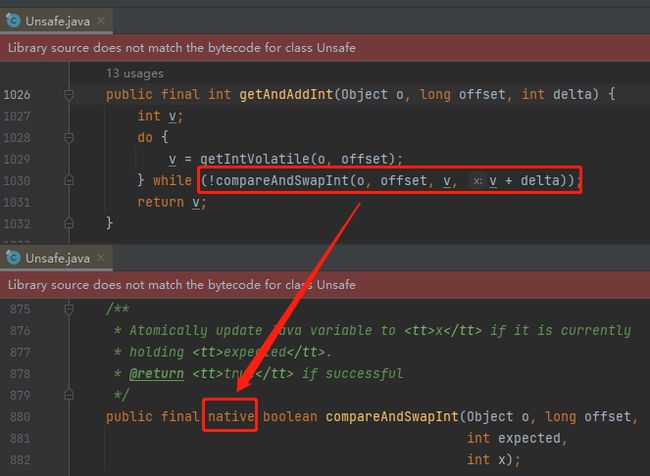
对啊,和 sleep 方法一样,这也是 native 方法调用啊,完全符合前面的结论啊,它为什么不进入安全点呢,为什么要搞差别对待呢?

大胆假设
看到问题的时候,我的第一反应就是先把锅甩给 JIT 吧,毕竟除了它,其他的我也实在想(不)不(了)到(解)。
为什么我会直接想到 JIT 呢?
因为循环中的这一行的代码属于典型的热点代码:
num.getAndAdd(1);
引用《深入理解JVM虚拟机》里面的描述,热点代码,主要是分为两类:
- 被多次调用的方法。
- 被多次执行的循环体。
前者很好理解,一个方法被调用得多了,方法体内代码执行的次数自然就多,它成为“热点代码”是理所当然的。
而后者则是为了解决当一个方法只被调用过一次或少量的几次,但是方法体内部存在循环次数较多的循环体,这样循环体的代码也被重复执行多次,因此这些代码也应该认为是“热点代码”。很明显,我们的示例代码就属于这种情况。
在我们的示例代码中,循环体触发了热点代码的编译动作,而循环体只是方法的一部分,但编译器依然必须以整个方法作为编译对象。
因为编译的目标对象都是整个方法体,不会是单独的循环体。
既然两种类型都是“整个方法体”,那么区别在于什么地方?
区别就在于执行入口(从方法第几条字节码指令开始执行)会稍有不同,编译时会传入执行入口点字节码序号(Byte Code Index,BCI)。
这种编译方式因为编译发生在方法执行的过程中,因此被很形象地称为“栈上替换”(On Stack Replacement,OSR),即方法的栈帧还在栈上,方法就被替换了。
说到 OSR 你就稍微耳熟了一点,是不是?毕竟它也偶现于面试环节中,作为一些高(装)阶(逼)面试题存在。
其实也就这么回事。
好,概念就先说到这里,剩下的如果你想要详细了解,可以去翻阅书里面的“编译对象与触发条件”小节。
我主要是为了引出虚拟机针对热点代码搞了一些优化这个点。
基于前面的铺垫,我完全可以假设如下两点:
- 1.由于 num.getAndAdd 底层也是 native 方法调用,所以肯定有安全点的产生。
- 2.由于虚拟机判定 num.getAndAdd 是热点代码,就来了一波优化。优化之后,把本来应该存在的安全点给干没了。

小心求证
其实验证起来非常简单,前面不是说了吗,是 JIT 优化搞的鬼,那我直接关闭 JIT 功能,再跑一次,不就知道结论了吗?
如果关闭 JIT 功能后,主线程在睡眠 1000ms 之后继续执行,说明什么?
说明循环体里面可以进入 safepoint,程序执行结果符合预期。
所以结果是怎么样的呢?
我可以用下面的这个参数关闭 JIT:
-Djava.compiler=NONE
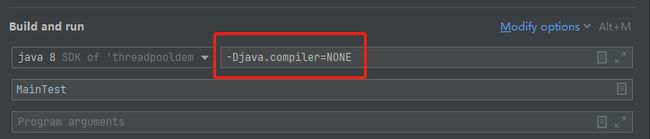
然后再次运行程序:
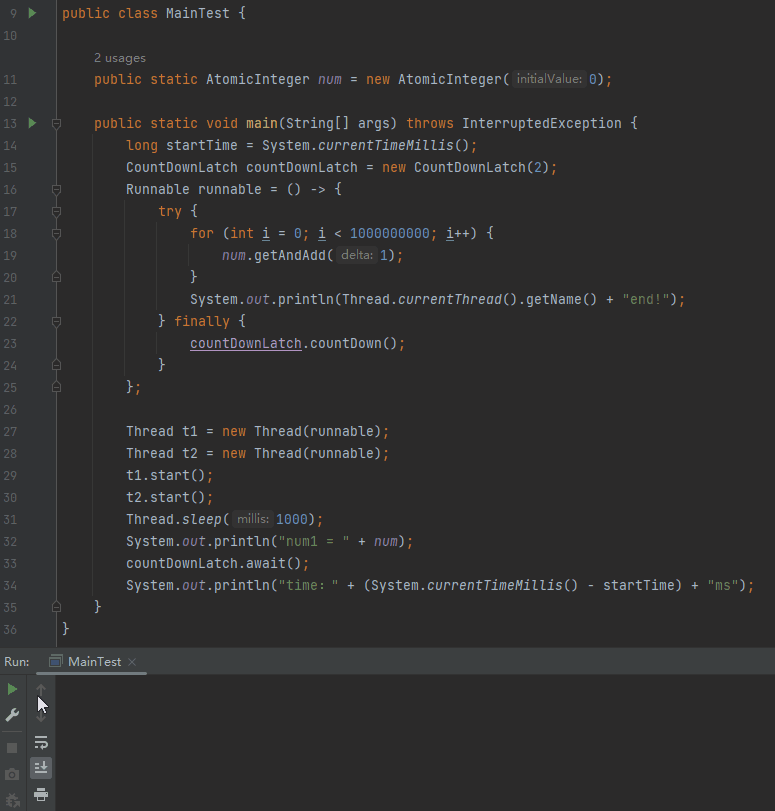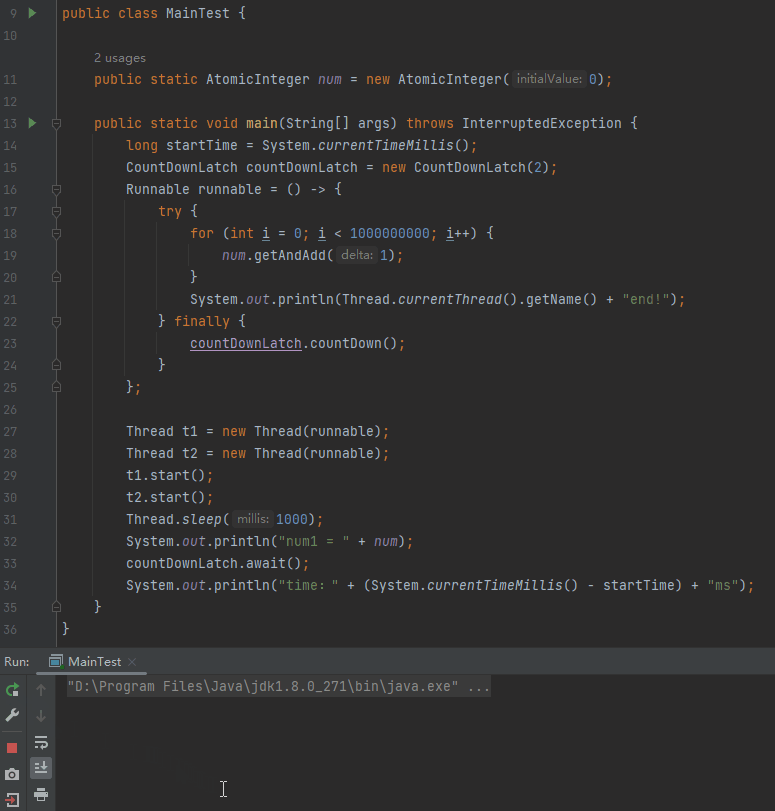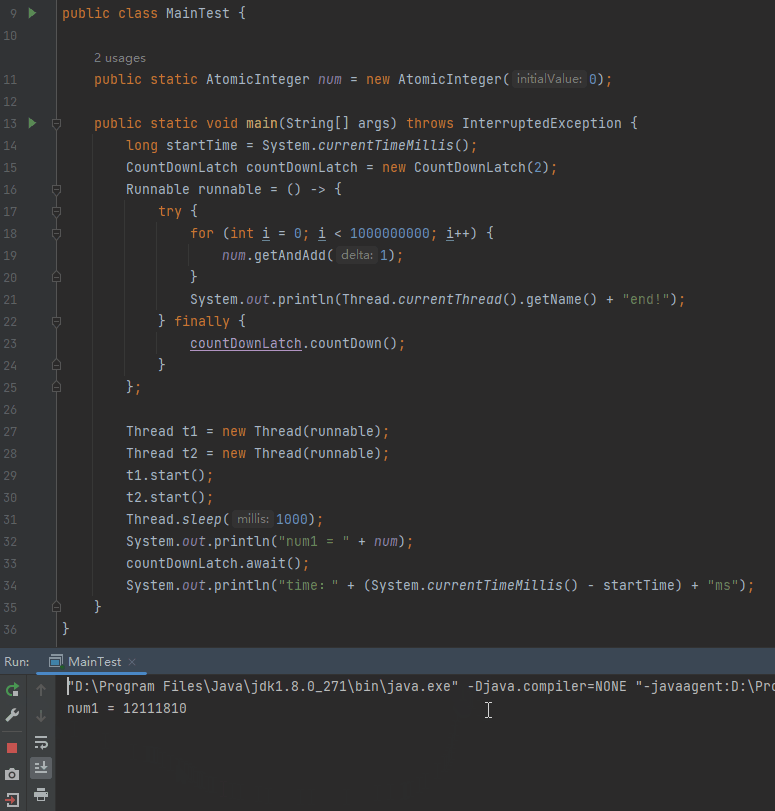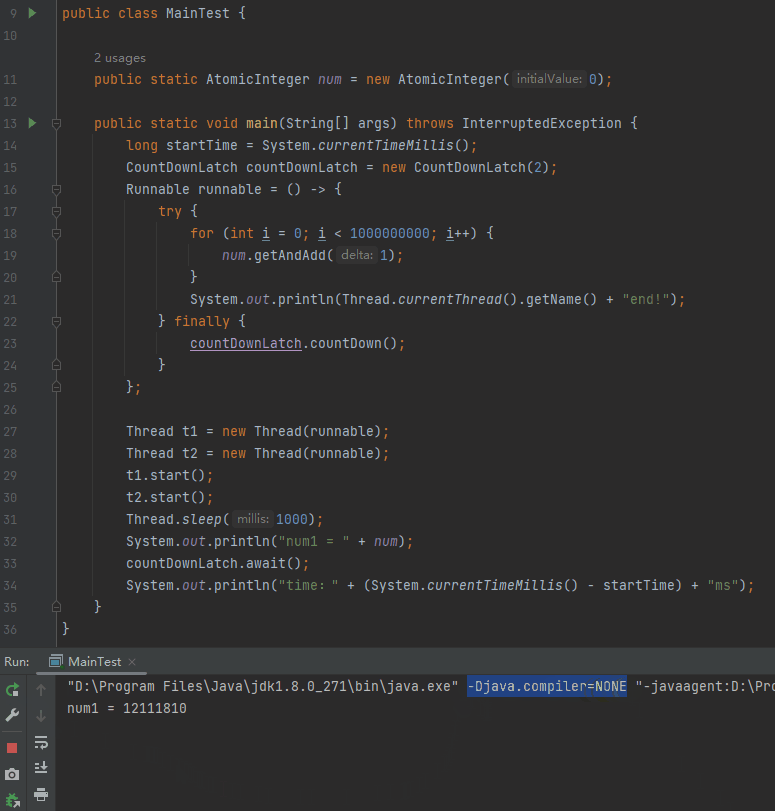
可以看到关闭 JIT 之后,主线程并没有等待子线程运行结束后才输出 num。效果等同于前面说的把 int 修改为 long,或者加入 Thread.sleep(0) 这样的代码。
因此我前面的那两点假设是不是就成立了?
好,那么问题就来了,说好的是小心求证,但是我这里只是用了一个参数关闭了 JIT,虽然看到了效果,但是总感觉中间还缺点东西。
缺什么东西呢?
前面的程序我已经验证了:经过 JIT 优化之后,把本来应该存在的安全点给干没了。
但是这句话其实还是太笼统了,经过 JIT 优化之前和之后,分别是长什么样子的呢,能不能从什么地方看出来安全点确实是没了?
不能我说没了就没了,这得眼见为实才行。
诶,你说巧不巧。
我刚好知道有个东西怎么去看这个“优化之前和之后“。

有个工具叫做 JITWatch,它就能干这个事儿。
https://github.com/AdoptOpenJ...
如果你之前没用过这个工具的话,可以去查查教程。不是本文重点,我就不教了,一个工具而已,不复杂的。
我把代码贴到 JITWatch 的沙箱里面:
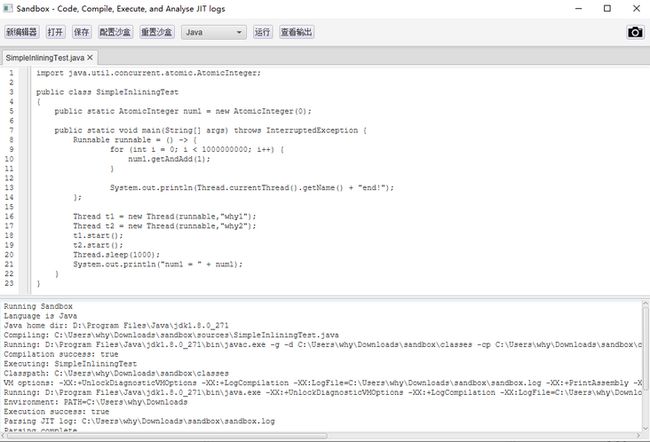
然后点击运行,最后就能得到这样的一个界面。
左边是 Java 源码,中间是 Java 字节码,右边是 JIT 之后的汇编指令:

我框起来的部分就是 JIT 分层编译后的不同的汇编指令。
其中 C2 编译就是经过充分编译之后的高性能指令,它于 C1 编译后的汇编代码有很多不同的地方。
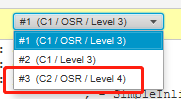
这一部分如果之前没接触过,看不懂没关系,也很正常,毕竟面试也不会考。
我给你截这几张的意思就是表明,你只要知道,我现在已经可以拿到优化之前和之后的汇编指令了,但是他们自己的差异点很多,那么我应该关注的差异点是什么呢?
就像是给你两个文本,让你找出差异点,很容易。但是在众多差异点中,哪个是我们关心的呢?
这个才是关键问题。
我也不知道,但是我找到了下面这一篇文章,带领我走向了真相。
关键文章
好了,前面都是一些不痛不痒的东西,这里的这篇文章才是关键点:
http://psy-lob-saw.blogspot.c...
因为我在这个文章中,找到了 JIT 优化之后,应该关注的“差异点”是什么。
这篇文章的标题叫做《安全点的意义、副作用以及开销》:

作者是一位叫做 nitsanw 的大佬,从他博客里面的文章看,在 JVM 和性能优化方面有着很深的造诣,上面的文章就发布于他的博客。
这是他的 github 地址:
https://github.com/nitsanw
用的头像是一头牦牛,那我就叫他牛哥吧,毕竟是真的牛。
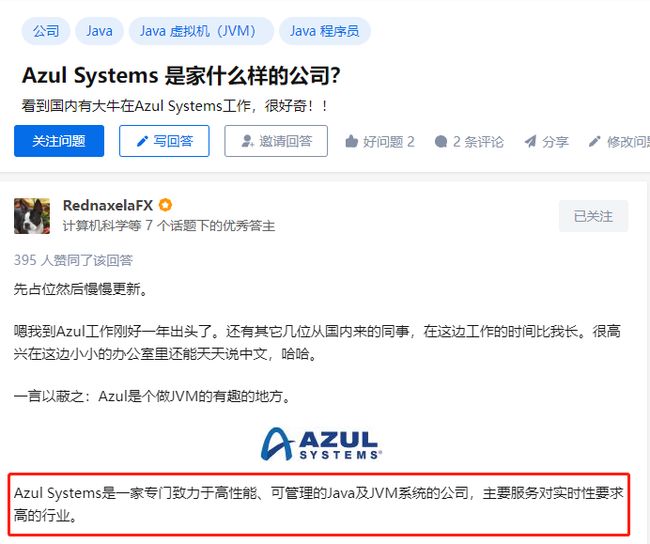
同时牛哥就职于 Azul 公司,和 R 大是同事:
他这篇文章算是把安全点扒了个干净,但是内容非常多,我不可能面面俱到,只能挑和本文相关度非常大的地方进行简述,但是真的强烈建议你读读原文。文章也分为了上下两集,这是下集的地址:
http://psy-lob-saw.blogspot.c...
看完之后,你就知道,什么叫做透彻,什么叫做:

在牛哥的文章中分为了下面这几个小节:
- What's a Safepoint?(啥是安全点?)
- When is my thread at a safepoint?(线程啥时候处于安全点?)
- Bringing a Java Thread to a Safepoint。(将一个Java线程带到一个安全点)
- All Together Now。(搞几个例子跑跑)
- Final Summary And Testament。(总结和嘱咐)
和本文重点相关的是“将一个Java线程带到一个安全点”这个部分。
我给你解析一下:

这一段主要在说 Java 线程需要每隔一个时间间隔去轮询一个“安全点标识”,如果这个标识告诉线程“请前往安全点”,那么它就进入到安全点的状态。
但是这个轮询是有一定的消耗的,所以需要 keep safepoint polls to a minimum,也就是说要减少安全点的轮询。因此,关于安全点轮询触发的时间就很有讲究。
既然这里提到轮询了,那么就得说一下我们示例代码里面的这个 sleep 时间了:
有的读者把时间改的短了一点,比如 500ms,700ms 之类的,发现程序正常结束了?
为什么?
因为轮询的时间由 -XX:GuaranteedSafepointInterval 选项控制,该选项默认为 1000ms:

所以,当你的睡眠时间比 1000ms 小太多的时候,安全点的轮询还没开始,你就 sleep 结束了,当然观察不到主线程等待的现象了。
好了,这个只是随口提一句,回到牛哥的文章中,他说综合各种因素,关于安全点的轮询,可以在以下地方进行:
第一个地方:
Between any 2 bytecodes while running in the interpreter (effectively)
在解释器模式下运行时,在任何 2 个字节码之间都可以进行安全点的轮询。
要理解这句话,就需要了解解释器模式了,上个图:
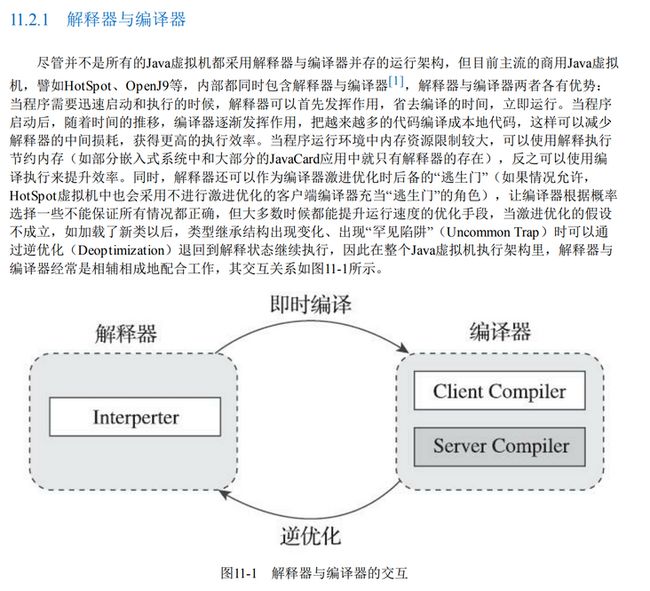
从图上可以知道,解释器和编译器之间是相辅相成的关系。
另外,可以使用 -Xint 启动参数,强制虚拟机运行于“解释模式”:

我们完全可以试一试这个参数嘛:
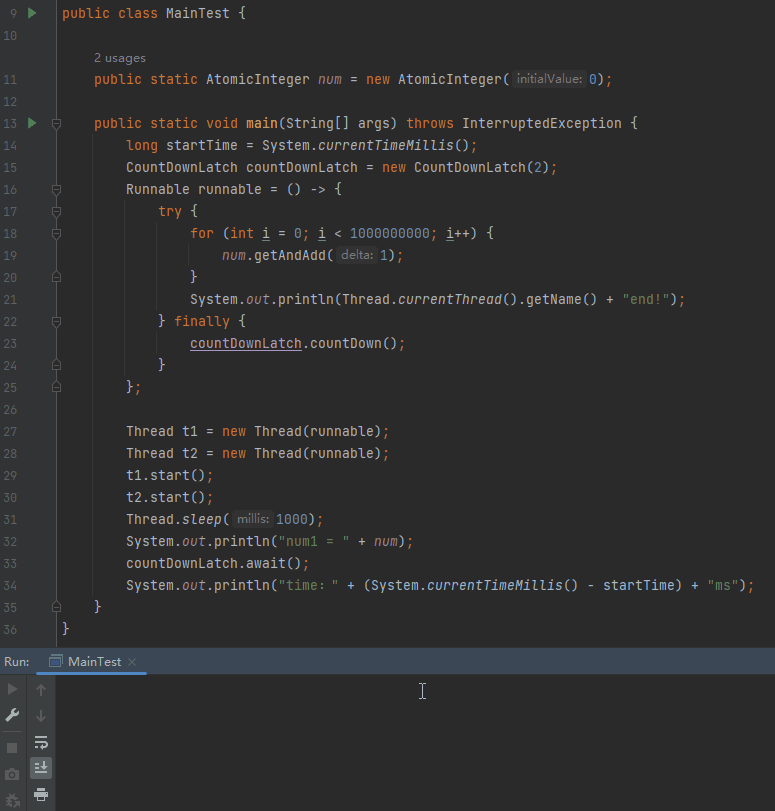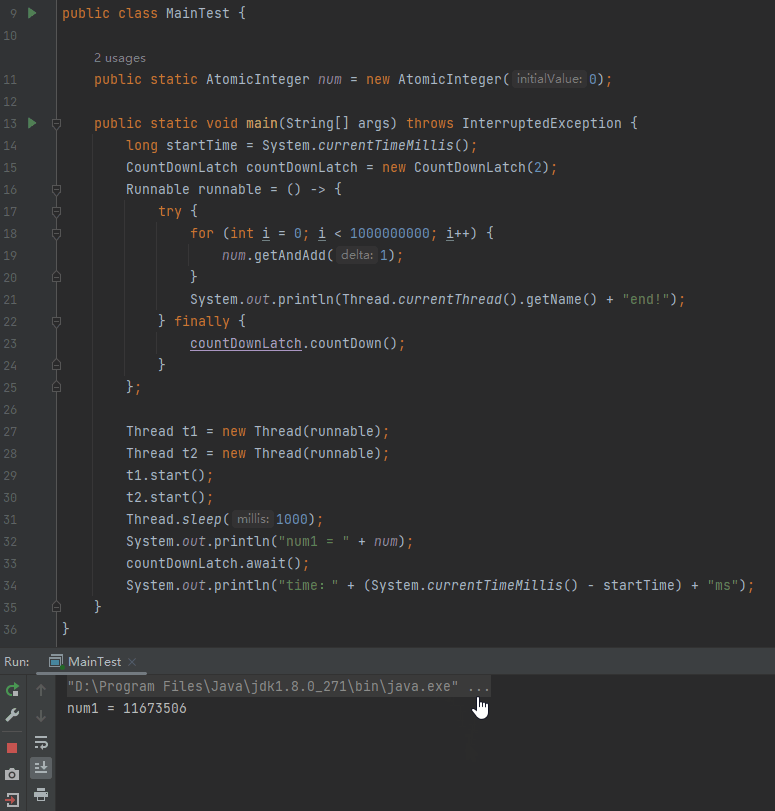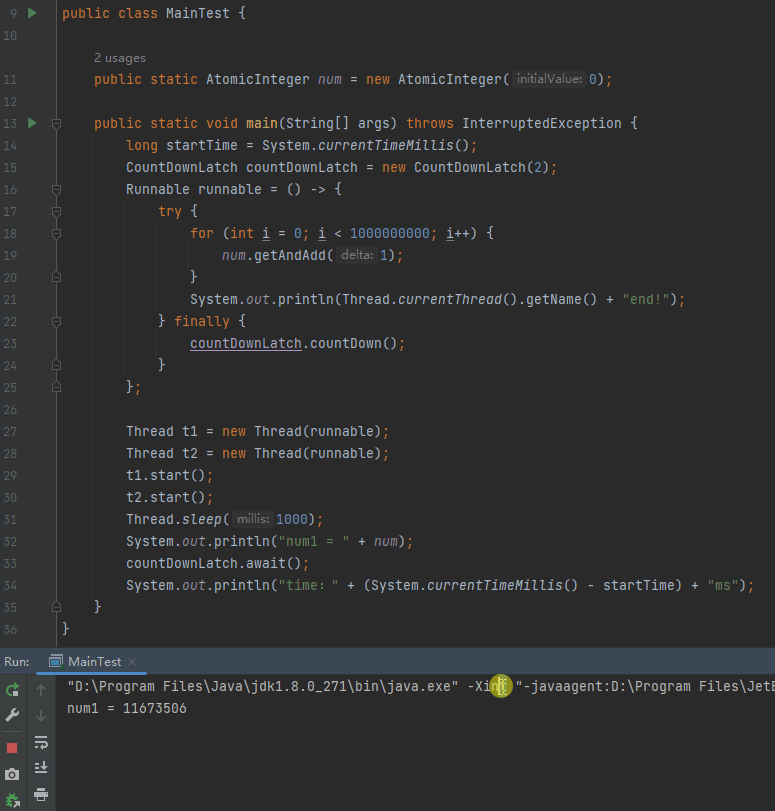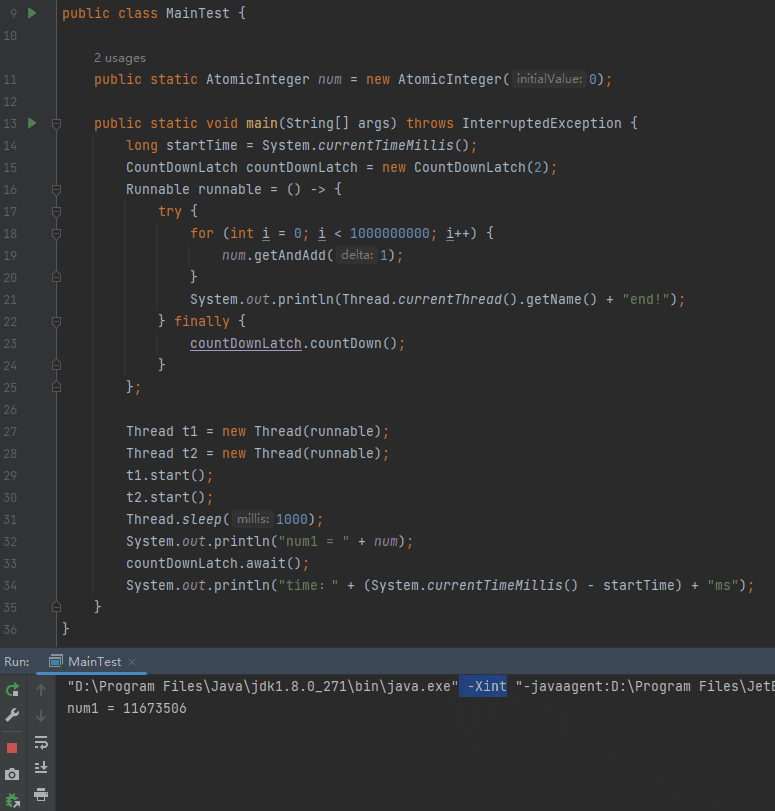
程序正常停下来了,为什么?
刚刚才说了:
在解释器模式下运行时,在任何 2 个字节码之间都可以进行安全点的轮询。
第二个地方:
On 'non-counted' loop back edge in C1/C2 compiled code
在 C1/C2 编译代码中的 "非计数 "循环的每次循环体结束之后。
关于这个“计数循环”和“非计算循环”我在上集里面已经说过了,也演示过了,就是把 int 修改为 long,让“计数循环”变成“非计算循环”,就不赘述了。
反正我们知道这里说的没毛病就行。
第三个地方:
这是前半句:Method entry/exit (entry for Zing, exit for OpenJDK) in C1/C2 compiled code.
在 C1/C2 编译代码中的方法入口或者出口处(Zing 为入口,OpenJDK 为出口)。
前半句很好理解,对于我们常用的 OpenJDK 来说,即使经过了 JIT 优化,但是在方法的入口处还是设置了一个可以进行安全点轮询的地方。
主要是关注后半句:
Note that the compiler will remove these safepoint polls when methods are inlined.
当方法被内联时编译器会删除这些安全点轮询。
这不就是我们示例代码的情况吗?
本来有安全点,但是被优化没了。说明这种情况是真实存在的。

然后我们接着往下看,就能看到我一直在找的“差异点”了:

牛哥说,如果有人想看到安全点轮询,那么可以加上这个启动参数:
-XX:+PrintAssembly
然后在输出里面找下面的关键词:
- 如果是 OpenJDK,就找 {poll} 或 {poll return} ,这就是对应的安全点指令。
- 如果是 Zing,就找 tls.pls_self_suspend 指令
实操一把就是这样的:
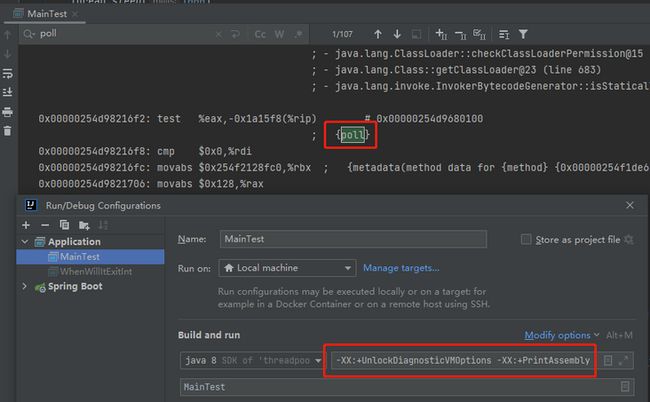
确实找到了类似的关键字,但是在控制台输出的汇编太多了,根本没法分析。
没关系,这不重要,重要的是我到了这个关键的指令:{poll}
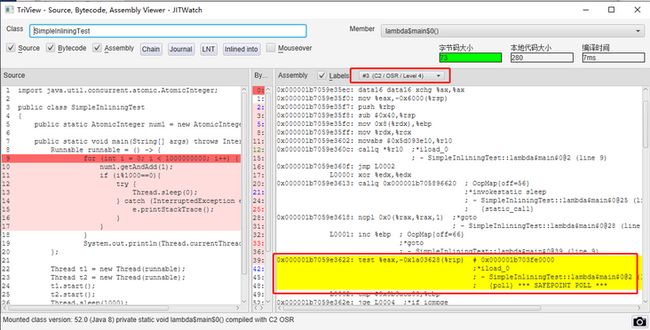
也就是说,如果在初始的汇编中有 {poll} 指令,但是在经过 JIT 充分优化之后的代码,也就是前面说的 C2 阶段的汇编指令里面,找不到 {poll} 这个指令,就说明安全点确实是被干掉了。
所以,在 JITWatch 里面,当我选择查看 for 循环(热点代码)在 C1 阶段的编译结果的时候,可以看看有 {poll} 指令:

但是,当我选择 C2 阶段的编译结果的时候,{poll} 指令确实都找不到了:
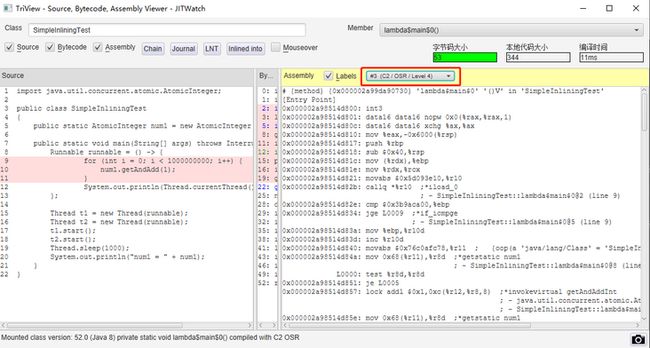
接着,如果我把代码修改为这样,也就是前面说的会正常结束的代码:
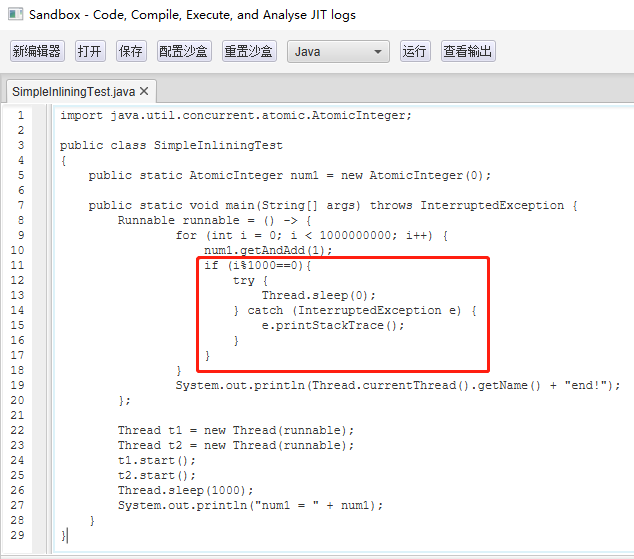
正常结束,说明循环体内可以进入安全点,也就是说明有 {poll} 指令。
所以,再次通过 JITWarch 查看 C2 的汇编,果然看到了它:
为什么呢?
从最终输出的汇编上来看,因为 Thread.sleep(0) 这行代码的存在,阻止了 JIT 做过于激进的优化。
那么为什么 sleep 会阻止 JIT 做过于激进的优化呢?
好了,
别问了,
就到这吧,
再问,
就不礼貌了。

牛哥的案例
牛哥的文章中给了下面五个案例,每个案例都有对应的代码:
- Example 0: Long TTSP Hangs Application
- Example 1: More Running Threads -> Longer TTSP, Higher Pause Times
- Example 2: Long TTSP has Unfair Impact
- Example 3: Safepoint Operation Cost Scale
- Example 4: Adding Safepoint Polls Stops Optimization
我主要带大家看看第 0 个和第 4 个,老有意思了。
第 0 个案例
它的代码是这样的:
public class WhenWillItExit {
public static void main(String[] argc) throws InterruptedException {
Thread t = new Thread(() -> {
long l = 0;
for (int i = 0; i < Integer.MAX_VALUE; i++) {
for (int j = 0; j < Integer.MAX_VALUE; j++) {
if ((j & 1) == 1)
l++;
}
}
System.out.println("How Odd:" + l);
});
t.setDaemon(true);
t.start();
Thread.sleep(5000);
}
}牛哥是这样描述这个代码的:
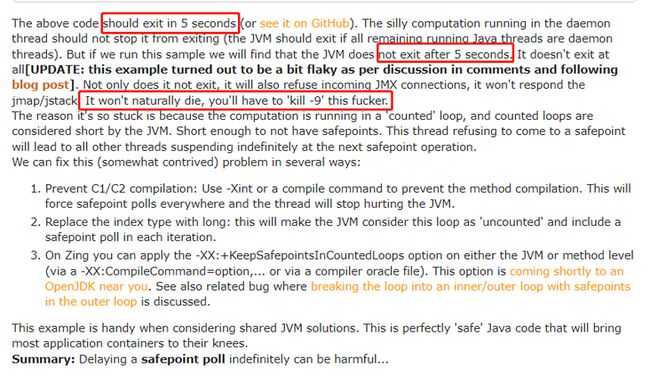
他说这个代码应该是在 5 秒之后结束,但是实际上它会一直运行下去,除非你用 kill -9 命令强行停止它。
但是当我把代码粘贴到 IDEA 里面运行起来,5 秒之后,程序停了,就略显尴尬。
我建议你也粘出来跑一下。
这里为什么和牛哥说的运行结果不一样呢?
评论区也有人问出了这个问题:
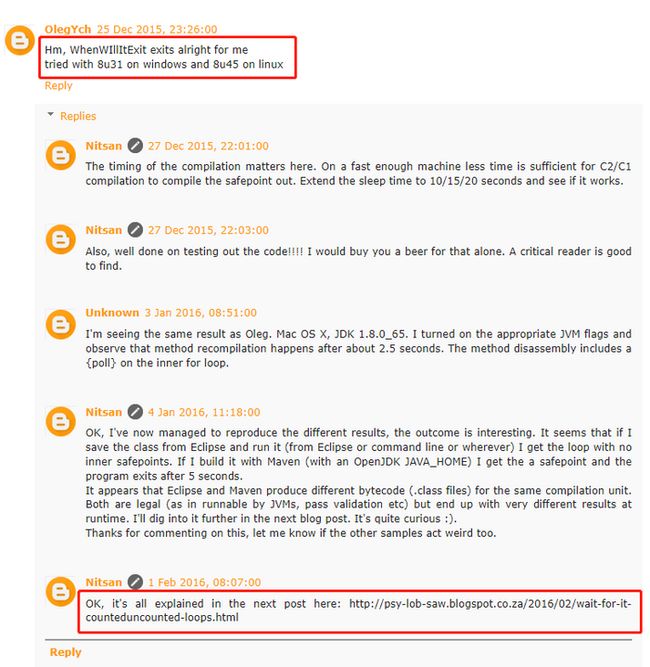
于是牛哥又写了一篇下集,详细的解释了为什么:
http://psy-lob-saw.blogspot.c...
简单来说就是他是在 Eclipse 里面跑的,而 Eclipse 并不是用的 javac 来编译,而是用的自己的编译器。
编译器差异导致字节码的差异,从而导致运行结果的差异:
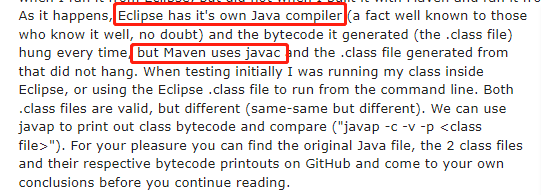
然后牛哥通过一顿分析,给出了这样的一段代码,
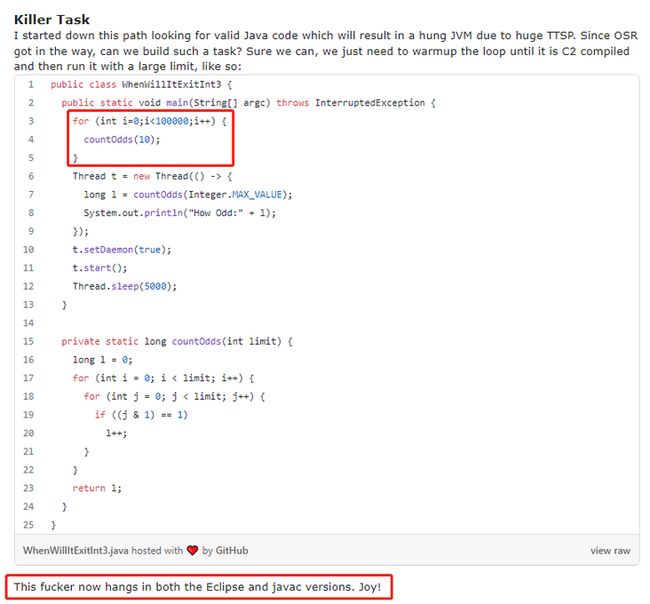
和之前的代码唯一不一样的地方,就是在子线程里面调用 countOdds 方法之前,在主线程里面先进行了 10w 次的运行调用。
这样改造之后代码运行起来就不会在 5 秒之后停止了,必须要强行 kill 才行。
为什么呢?
别问,问就是答案就在他的下集里面,自己去翻,写的非常详细。
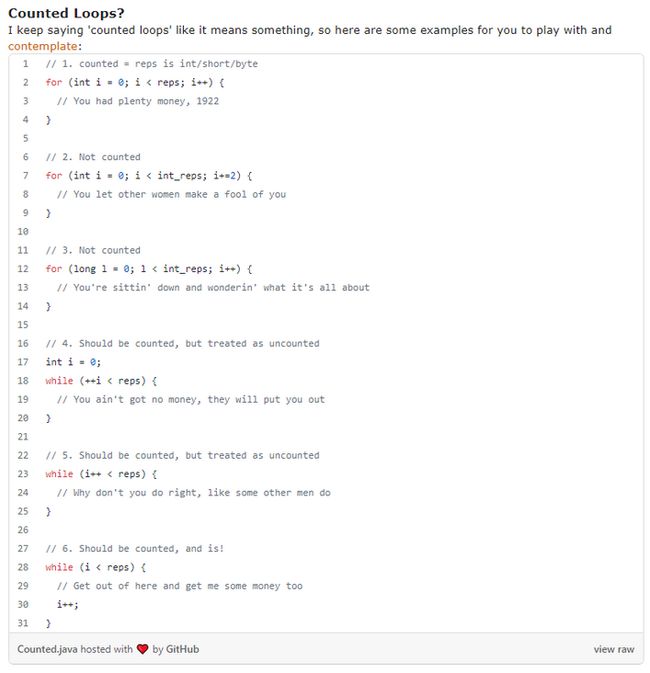
同时在下集中,牛哥还非常贴心的给你贴出了他总结的六种循环的写法,那些算是“counted Loops”,建议仔细辨别:
第 4 个案例
这个案例是一个基准测试,牛哥说它是来自 Netty 的一个 issue:
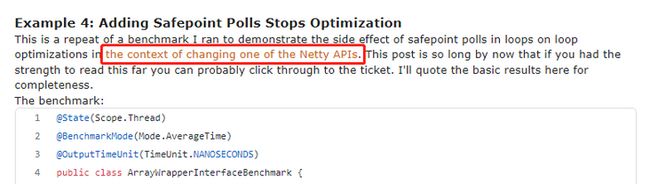
这里怎么突然提到 Netty 了呢?
牛哥给了一个超链接:
https://github.com/netty/nett...
这个 pr 里面讨论的内容非常的多,其中一个争论的点就是循环到底用 int 还是 long。
这个哥们写了一个基准测试,测试结果显示用 int 和 long 似乎没啥差别:

需要说明的是,为了截图方便,我截图的时候把这个老哥的基准测试删除了。如果你想看他的基准测试代码,可以通过前面说的链接去找到。
然后这个看起来头发就很茂盛的老哥直接用召唤术召唤了牛哥:
等了一天之后,牛哥写了一个非常非常详细的回复,我还是只截取其中一部分:
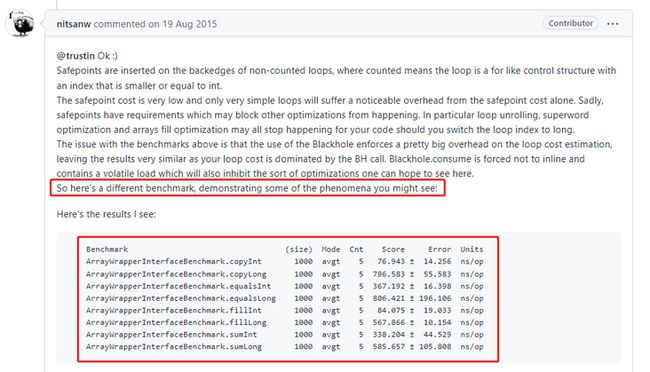
他上来就说前面的老哥的基准测试写的有点毛病,所以看起来差不多。你看看我写的基准测试跑出来的分,差距就很大了。
牛哥这里提到的基准测试,就是我们的第四个案例。
所以也可以结合着 Netty 的这个特别长的 pr 去看这个案例,看看什么叫做专业。

最后,再说一次,文中提到的牛哥的两篇文章,建议仔细阅读。
另外,关于安全点的源码,我之前也分享过这篇文章,建议一起食用,味道更佳:《关于安全点的那点破事儿》
我只是给你指个路,剩下的路就要你自己走了,天黑路滑,灯火昏暗,小心脚下,不要深究,及时回头,阿弥陀佛!
最后,感谢你阅读我的文章。欢迎关注公众号【why技术】,文章全网首发哦。