redis-数据结构与对象
一、redisObject
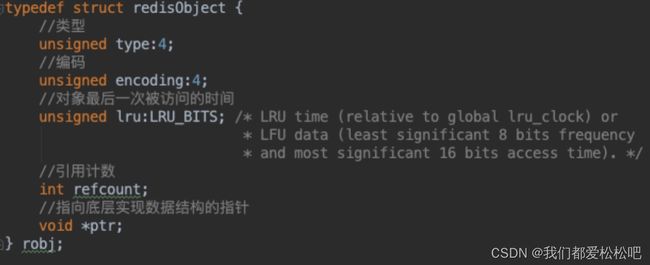
Redis中的每个对象都由一个redisObject结构表示
type:表示对象的类型,占4个bit,就是string,hash,list,set,zset这些类型
encoding:表示对象的编码,占用4个bit
4. ptr:指针对象,64位系统寻址地址固定是 64bits , 当encoding为int时, ptr 为数字的值;
1.type类型
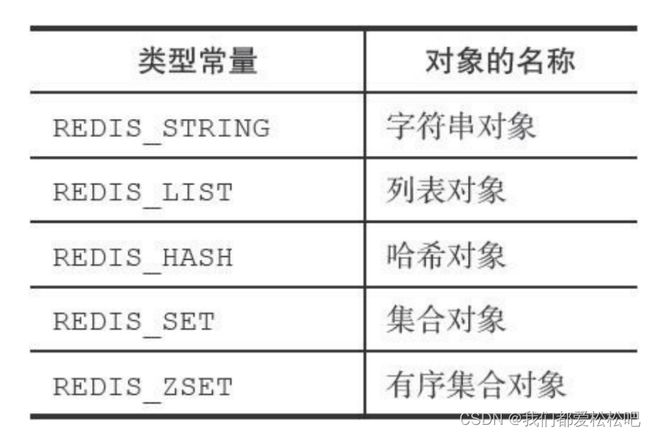
type 记录了对象的类型,所有的类型如下:
2.encoding类型
encoding 表示 ptr 指向的具体数据结构,即这个对象使用了什么数据结构作为底层实现
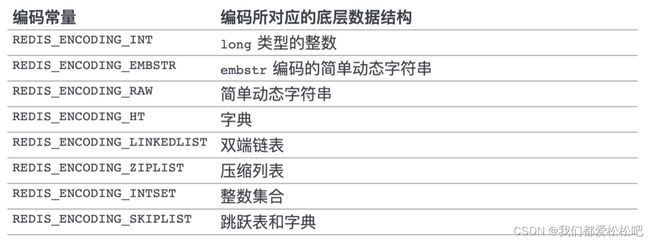
每种类型的对象都至少使用了两种不同的编码
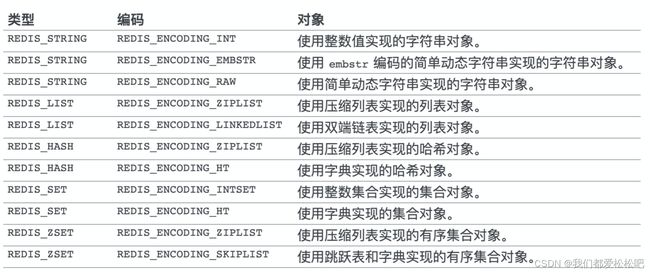
3.不同类型和编码的对象
二、字符串对象(string)
1.int-使用整数值实现
如果一个字符串对象保存的是整数值,并且这个整数值可以用 long 类型来表示
那么字符串对象会将整数值保存在字符串对象结构的 ptr 属性里面(将 void* 转换成 long )
并将字符串对象的编码设置为 int

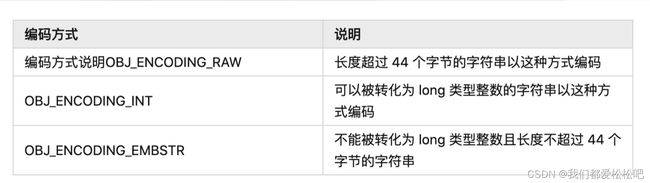
可以被转化为 long 类型整数的字符串以这种方式编码,大小:16字节
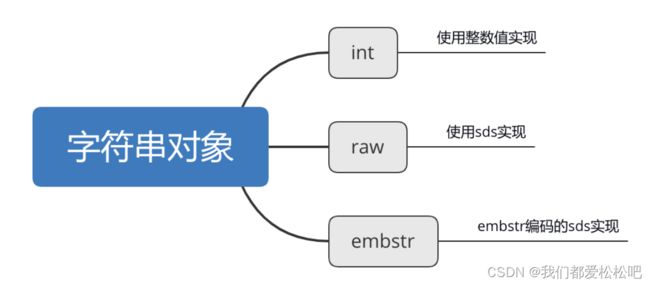
2.embstr-使用embstr编码的sds实现
embstr编码是专门用于保存短字符串的一种优化编码方式,
当字符串的长度小于等于 44 的时候,将采用 embstr 编码
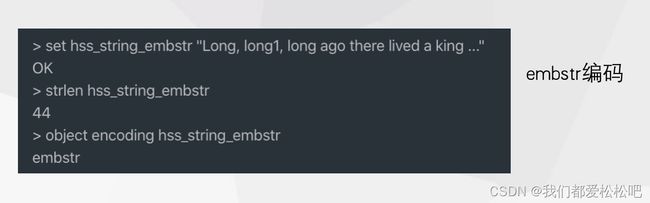

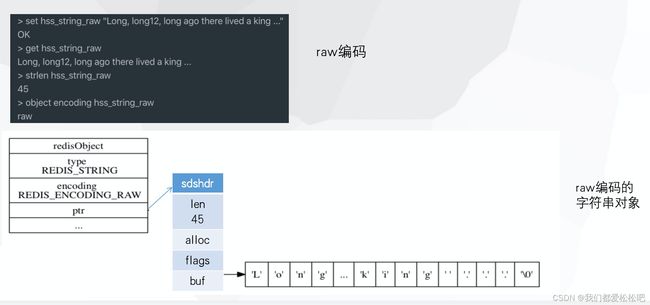
3.raw-使用sds实现
如果字符串对象保存的是一个字符串值,并且这个字符串值的长度大于 44 字节(redis3.2版本之前是39),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值,并将对象的编码设置为 raw
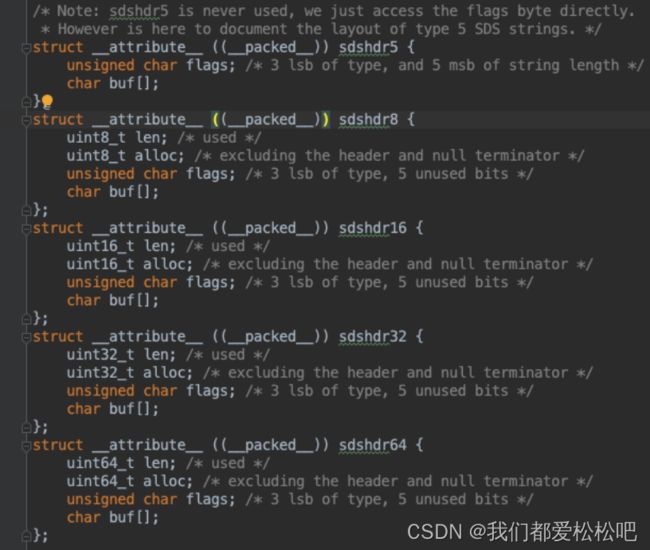
4.简单动态字符串-sds
一种用于存储二进制数据的一种结构, 具有动态扩容的特点

5.为什么使用sds?
6.字符串对象编码转换
二、列表对象(list)
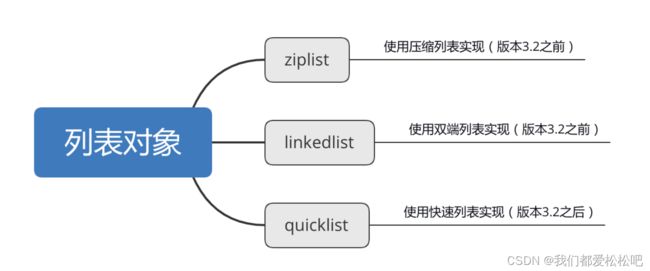
1.ziplist-使用压缩列表实现(版本3.2之前)
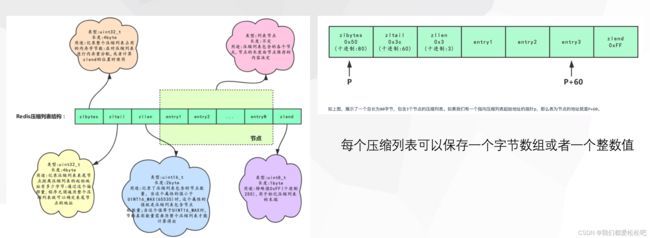
压缩列表是 ZSET、HASH和 LIST 类型的其中一种编码的底层实现,
是由一系列特殊编码的连续内存块组成的顺序型数据结构,其目的是节省内存;
当列表对象的所有字符串元素长度都小于64字节,并且保存的元素数量小于512个时,使用压缩列表;
如果不满足上述条件中的任意一个,都会使用链表。

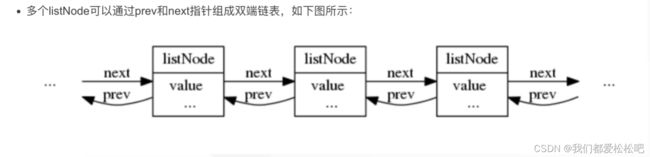
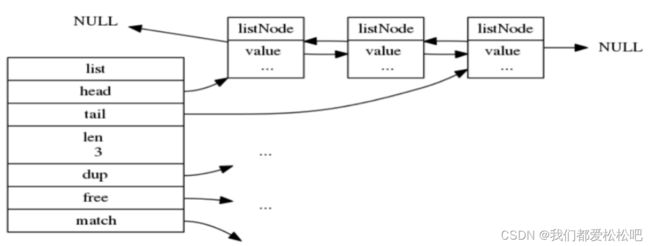
2.linkedlist-使用双端链表实现(版本3.2之前)
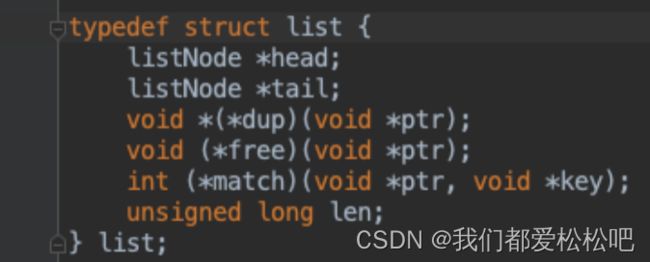
head:表头节点、tail:表尾节点
len:链表所包含的节点数量
dup:节点值复制函数
free:节点值释放函数
match:节点值对比函数
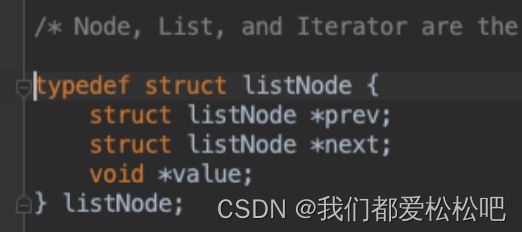
prev:前置节点、next:后置节点、value:节点的值

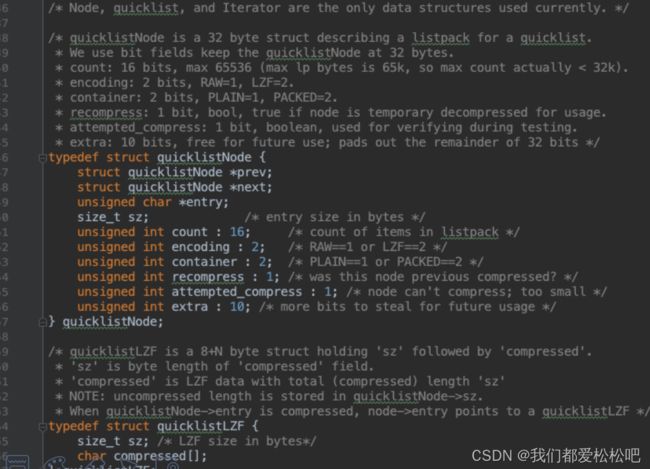
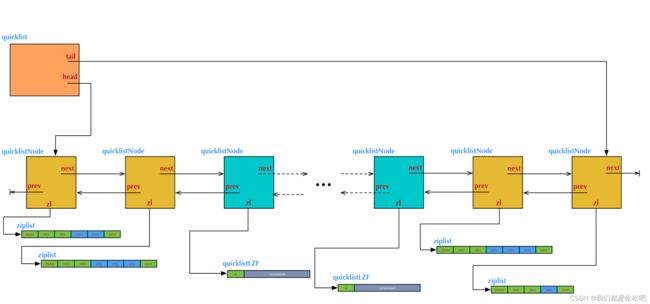
3.quicklist-使用快速列表实现(版本3.2之后)

数据结构:
示例:
qucikList总体结构图:
三、哈希对象(hash)
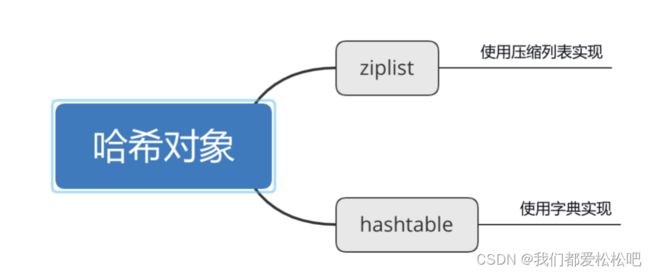
1.hashtable-使用字典实现
Redis中的字典采用哈希表作为底层实现,一个哈希表有多个节点,每个节点保存一个键值对。
数据结构:
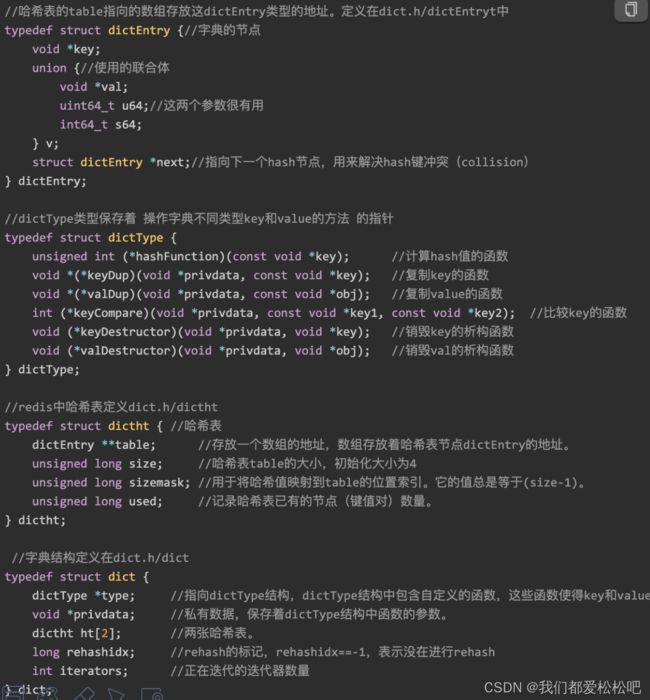
结构图:
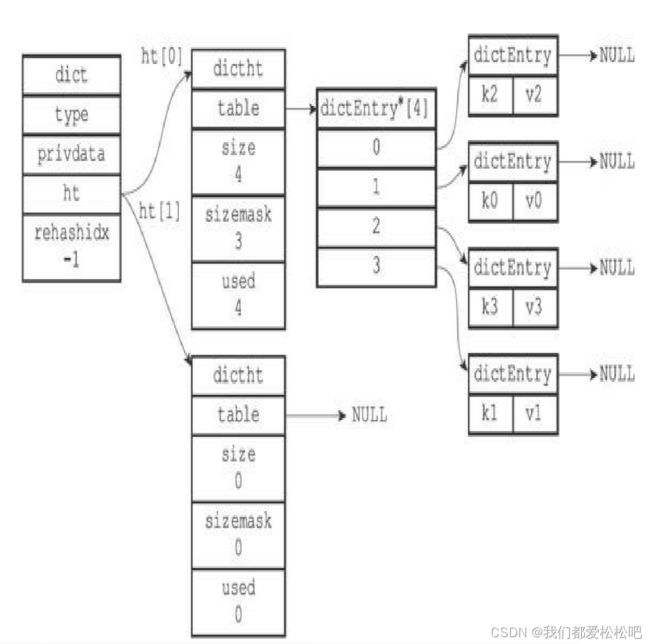
链地址法解决键冲突
一个包含两个键值对的哈希表:
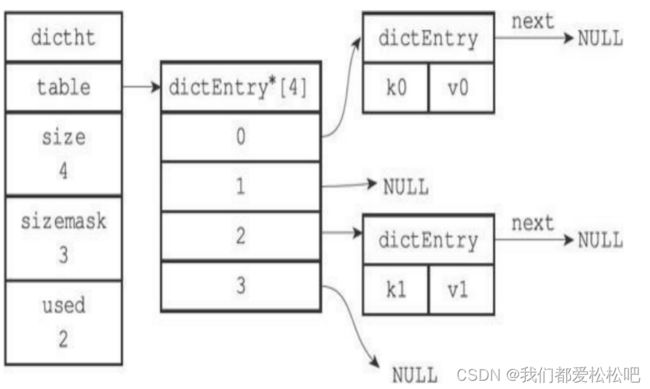
使用链表解决k2和k1的冲突
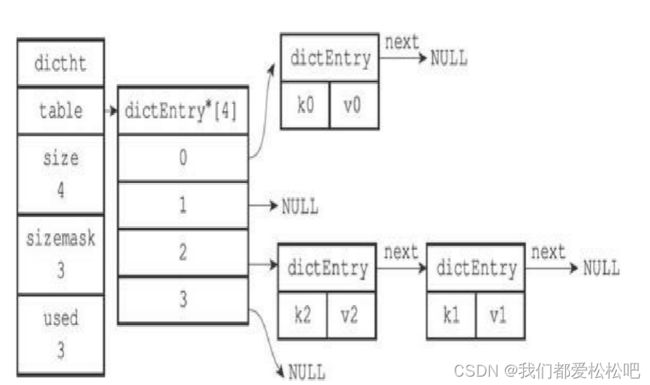
因为dictEntry节点组成的链表没有指向链表表尾的指针,所以为了 速度考虑,程序总是将新节点添加到链表的表头位置(复杂度为 O(1)),排在其他已有节点的前面。
rehash:

示例:
(1)执行rehash之前的字典
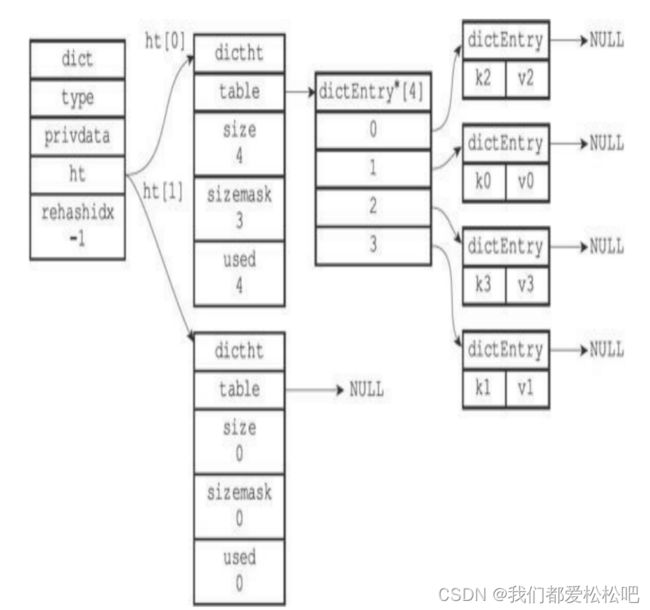
(2)为字典的ht[1]哈希表分配空间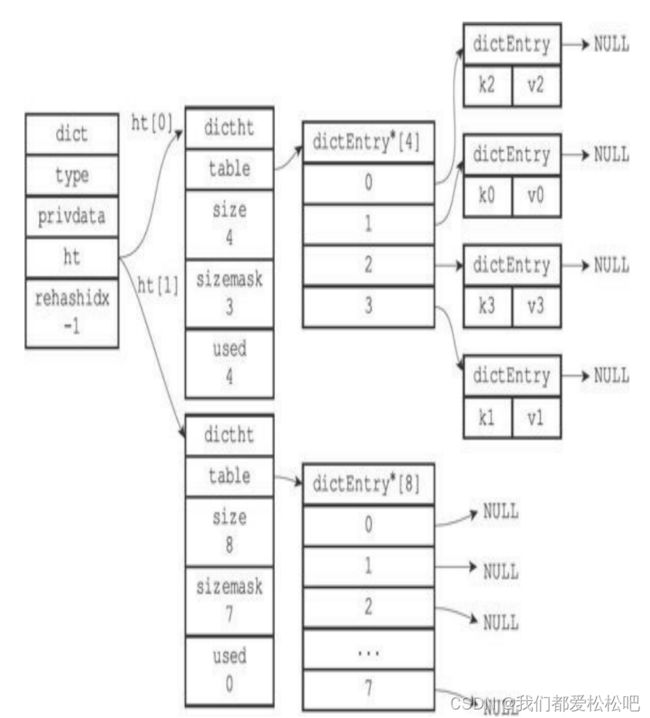
(3)ht[0]的所有键值对都已经被迁移到ht[1]
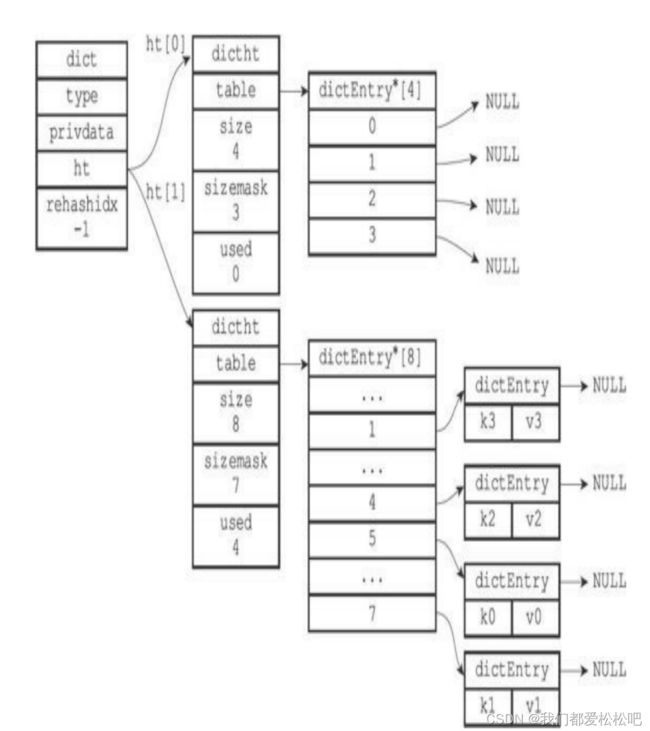
(4)完成rehash之后的字典
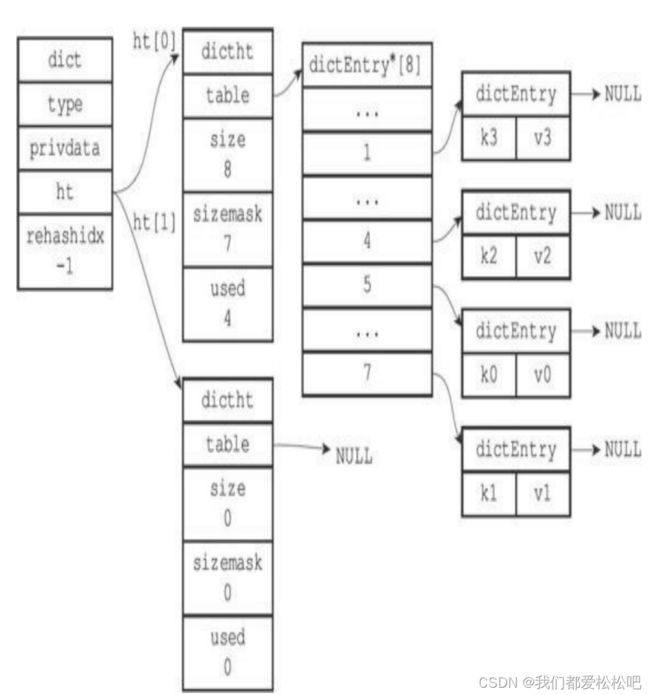
2.编码转换

四、集合对象(set)
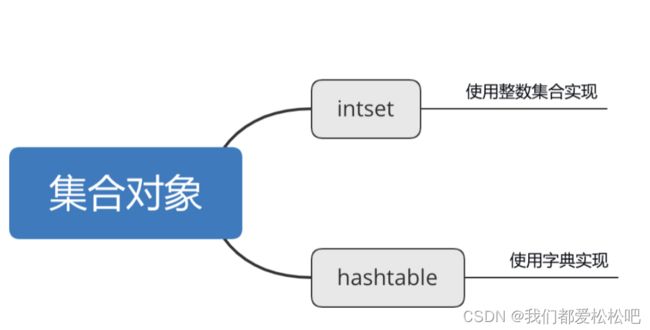
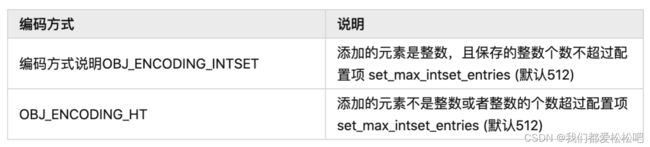
1.intset-使用整数集合实现
整数集合(intset)是集合键的底层实现之一,当一个集合只包含整 数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合 作为集合键的底层实现。
数据结构:
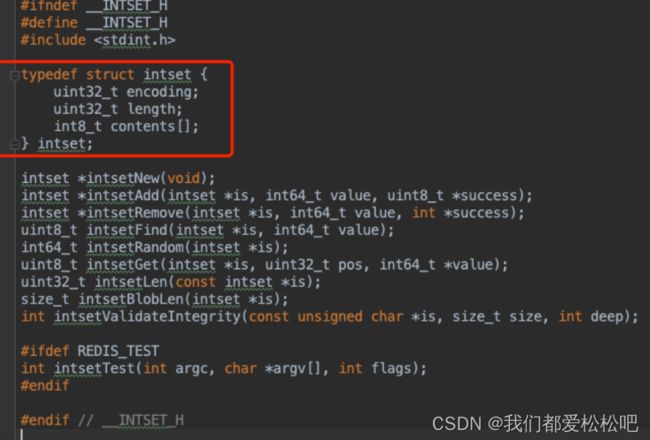

结构图:
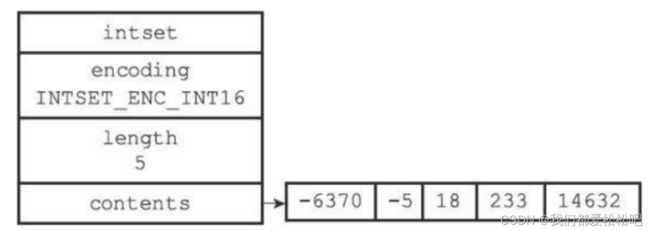
示例:

2.编码转换
五、有序集合对象(zset)
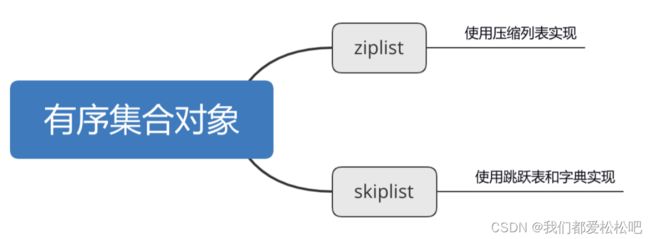
1.skiplist-使用跳跃表和字典实现
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持
多个指向其他节点的指针,从而达到快速访问节点的目的
数据结构:
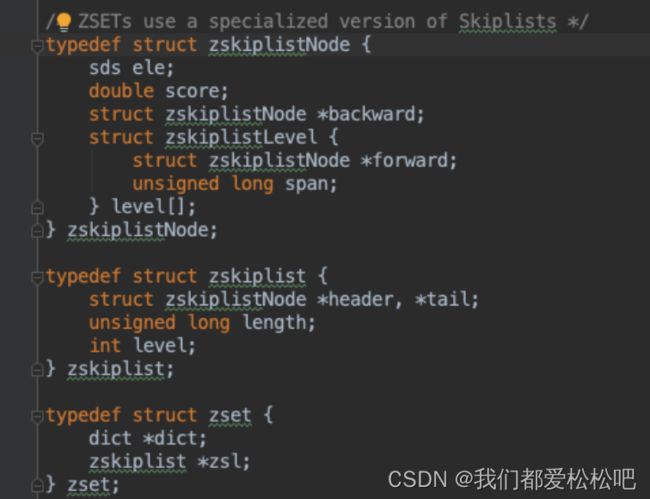
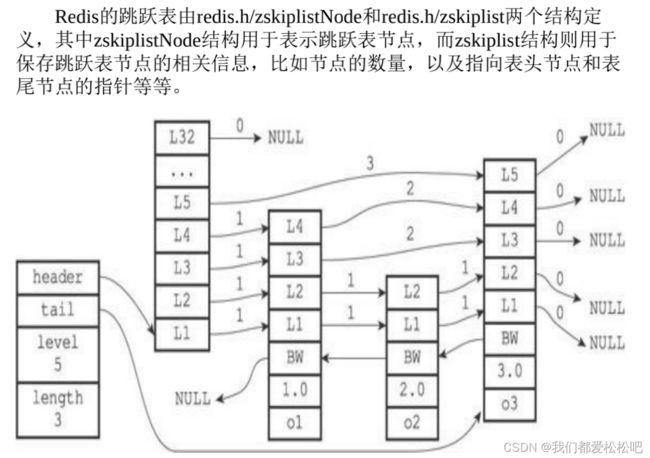
结构图:
zslGetRank函数:返回给定成员和分值的节点在表中的排位
时间复杂度是O(logN)
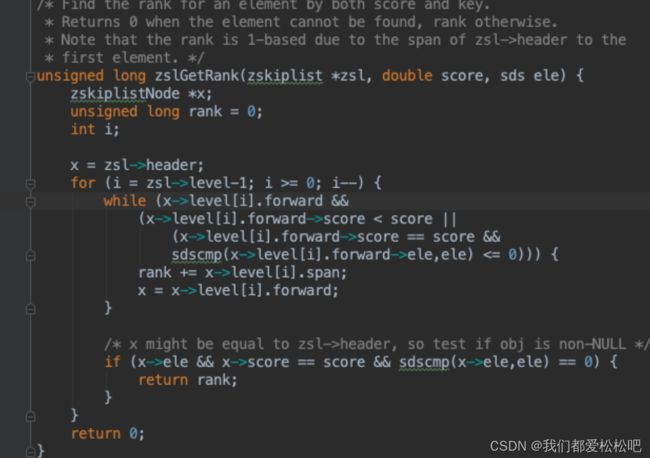
sdscmp函数是比较两个sds的大小
跳跃表的查找
1.优先从高层查找
2.若当前节点的值, 小于要查找的值,
并且next指针指向大于目标值的节点, 就要降一级寻找,
或者next指针指向了null, 那么也需要降一级查找
使用跳跃表和字典实现:
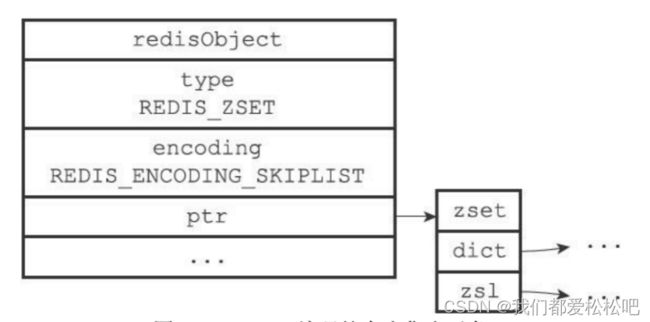
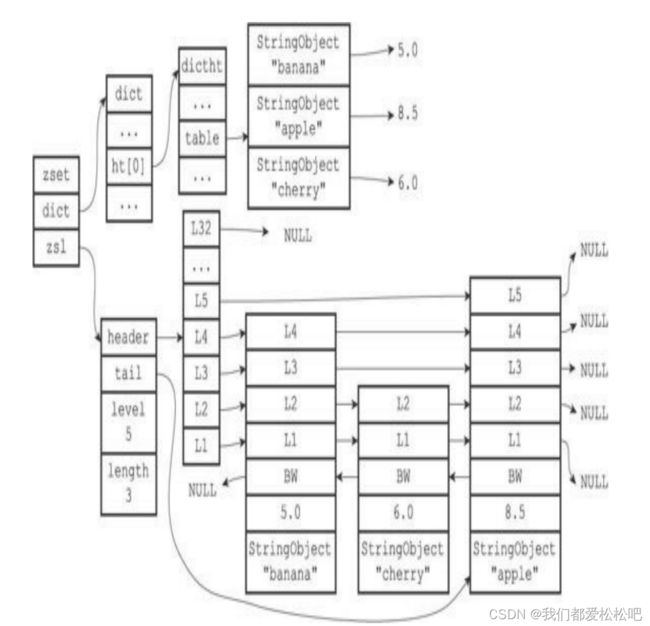

为什么有序集合需要同时使用字典和跳跃表实现?不会浪费内存吗?
(1)如果只是用字典来实现,那么虽然在查找成员时复杂度为O(1),但因为字典是无序保存元素的,当执行范围性操作例如 ZRANK 时,程序都需要进行排序;
如果只是使用跳跃表来实现,虽然执行范围性操作复杂度很低,当时在根据成员查找分值时因为没有了字典,复杂度会从O(1)变为O(longN)。
(2)这两种数据结构都会通过指针来共享相同元素的成员和分值,不会浪费内存。
2.编码转换

六、预估内存大小
1.set aaa bbb占用多少内存?
(1)数据结构
key + value:dicEntry(24字节,jemalloc会分配32字节)
key:sds(短字符串用的是sdshdr8,占用4字节,aaa占用3字节,总共分配8字节)
value :redisObject(16字节) + sds(同上,8字节)
总共:dicEntry(32)+ redisObject(16) + sds(8)+ sds(8)= 64字节。
总结
以上内容是作者在网上收集总结而来,如有雷同,请联系作者删除,谢谢支持!