DDD 学习笔记
DDD
- Domain Primitive
-
- 为什么会出现 DP
- DP 使用以及好处
- 架构以及包名
- 六边形架构的包
-
- Presentation(Web、Interfaces)模块
- Application 模块
- Domain 模块
- Infrastructure 模块
- 模型以及模型之间的转换
-
- VO、DTO、DO、PO
- DDD 中的3种模型
- 模型之间的转换
- 开发的流程
因为公司的包结构参考借鉴了 DDD 的思想,被迫无奈学习了一下 DDD 相关知识
每一种架构都是为了解决实际工程中的问题,就像设计模式看起来什么用都没有,但是其实是解决了现实工程中遇到的各种问题,主要是为了降低代码的维护与修改的代价,而这个 DDD 个人认为也是这个作用
Domain Primitive
对实体类的属性进行显示化
为什么会出现 DP
数据验证和错误处理:每个入参都需要方法校验,就算前端已经校验过了,后端为了程序健壮性以及规范,还是要校验一次。虽然现在可以用注解来简化校验过程,但是还有一些需要业务校验的情况在代码中经常出现,在每个方法里这段校验逻辑还是会被重复
在需要新增校验规则与维护原来的校验规则时,会比较麻烦,有没有一种方法,能够一劳永逸的解决所有校验的问题以及降低后续的维护成本和异常处理成本呢?
大量的工具类:问题时从一些入参里抽取一部分数据,然后调用一个外部依赖获取更多的数据,然后通常从新的数据中再抽取部分数据用作其他的作用。这种代码通常被称作“胶水代码”,其本质是由于外部依赖的服务的入参并不符合我们原始的入参导致的。为了解决这个问题,一个常见的办法是将这段代码抽离出来,变成独立的一个或多个方法
可测试性:假如一个方法有 N 个参数,每个参数有 M 个校验逻辑,至少要有 N * M 个 TC,要如何降低测试成本呢?
DP 使用以及好处
将隐性的概念显性化:比如下面例子
public class TestEntityPo {
private String username;
private String email;
}
原来 username 仅仅是TestEntityPo 的一个参数,属于隐形概念,如果此时 username 参与了真正的业务逻辑,为了减少维护成本我们需要将username的概念显性化
public class UserName {
@NotNull
String str;
public String getName() {
return str;
}
public isEng() {
// 判断逻辑
...
}
}
我们将之前的username写成一个类,此时:
校验逻辑都放在了 UserName 里面,确保只要该类被创建出来后,一定是校验通过的,数据验证和错误处理都在类中处理
只对该属性操作的方法变成了 UserName 类里的方法
刨除了数据验证代码、胶水代码,在业务层剩下的都是核心业务逻辑
架构以及包名
如果忽略应用内部的架构设计,很容易导致代码逻辑混乱,很难维护,容易产生bug而且很难发现
一个应用最大的成本一般都不是来自于开发阶段,而是应用整个生命周期的总维护成本,所以代码的可维护性代表了最终成本,强依赖其他三方组件与基层数据库的脚本式代码通常可维护性能差,它可能出现以下几个问题
- 数据结构的不稳定性:数据库的表结构和设计是应用的外部依赖,都有可能会改变,如果改了POJO要改流程也要改
- 第三方服务依赖的不确定性:第三方服务,比如Yahoo的汇率服务未来很有可能会有变化:轻则API签名变化,重则服务不可用需要寻找其他可替代的服务。在这些情况下改造和迁移成本都是巨大的。同时,外部依赖的兜底、限流、熔断等方案都需要随之改变。
- 中间件或者数据库更换:今天我们用Kafka发消息,明天如果要上阿里云用RocketMQ该怎么办?后天如果消息的序列化方式从String改为Binary该怎么办?
事务脚本式代码的第二大缺陷是:虽然写单个用例的代码非常高效简单,但是当用例多起来时,其扩展性会变得越来越差。
可扩展性减少做新需求或改逻辑时,需要新增/修改多少代码
- 数据来源被固定、数据格式不兼容:原有的AccountDO是从本地获取的,而跨行转账的数据可能需要从一个第三方服务获取,而服务之间数据格式不太可能是兼容的,导致从数据校验、数据读写、到异常处理、金额计算等逻辑都要重写
- 业务逻辑无法复用:数据格式不兼容的问题会导致核心业务逻辑无法复用。每个用例都是特殊逻辑的后果是最终会造成大量的if-else语句,而这种分支多的逻辑会让分析代码非常困难,容易错过边界情况,造成bug
- 逻辑和数据存储的相互依赖:当业务逻辑增加变得越来越复杂时,新加入的逻辑很有可能需要对数据库schema或消息格式做变更。而变更了数据格式后会导致原有的其他逻辑需要一起跟着动。在最极端的场景下,一个新功能的增加会导致所有原有功能的重构,成本巨大
设计模式六大原则给了我们不错的解决思路,依赖与抽象而不依赖与具体。调用每一个三方时都使用接口或者加防腐层,调用每一个底层组件时都使用抽象,同时按逻辑分离代码操作,使代码复用性增加
六边形架构的包
DDD 最直观的体现就是包名跟 MVC 不一样,领域驱动设计的四层结构为:
- 表现层(Presentation)
- 应用层(Application)
- 领域层(Domain)
- 基础设施层(Infrastructure)
设计人员可以根据实际问题填充不同的模块到这四层中,填充的原则如下:
Presentation(Web、Interfaces)模块
Web模块包含Controller等相关代码,同时在该模块中可以加入 VO,Param 等,该层即为协议层
我们单独会抽取出来 Interface 接口层,作为所有对外的门户,将网络协议和业务逻辑解耦,该层需要做以下这些事情:
- 异常处理:通常在接口层要避免将异常直接暴露给调用端,所以需要在接口层做统一的异常捕获,转化为调用端可以理解的数据格式。在其他层,遇到错误直接抛异常是最合理的方法
- 日志:在接口层打调用日志,用来做统计和debug等。一般微服务框架可能都直接包含了这些功能
- 统一鉴权:比如在一些需要AppKey+Secret的场景,需要针对某个租户做鉴权的,包括一些加密串的校验
- Session管理:一般在面向用户的接口或者有登陆态的,通过Session或者RPC上下文可以拿到当前调用的用户,以便传递给下游服务
- 限流配置:对接口做限流避免大流量打到下游服务
Application 模块
主要包含 Application Service,该模块依赖 Domain 模块。Application 层主要职责为组装 domain 层各个组件及基础设施层的公共组件,完成具体的业务服务。Application 层可以理解为粘合各个组件的胶水,使得零散的组件组合在一起提供完整的业务服务
该层的出参应该是标准的 DTO,并且不应该做任何逻辑处理,而入参则是 CQE 对象,一般入参的校验应该在这一层,这样就保证了非业务代码不会混杂在业务代码之间

判断是否业务流程的几个点:
- 不要有任何计算,基于对象的计算逻辑应该封装到实体里
- for 循环一般为业务判断
- 允许有 if 判断中断条件,一般如果条件不满足抛异常或者返回
Domain 模块
业务核心模块,包含有状态的 Entity、领域服务 Domain Service、Types、以及各种外部依赖的接口类
有状态的 Entity 指对应原来 MVC 中的 DO,只不过加入了对 DO 中属性的一些操作;Types 包下装了前文说的 DP;Domain Service则是多个 Entity 的复合操作
Infrastructure 模块
包含数据库 DAO 的实现,包含 PO、ORM Mapper、Entity 到 PO 的转化类等;包含 Service,不过没有业务代码,都是一些类似日志什么的 Service 操作;包含要具体依赖的 ORM 类库配置,比如 MyBatis
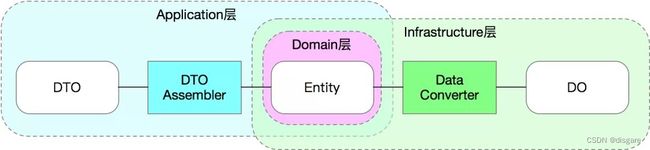
模型以及模型之间的转换
VO、DTO、DO、PO
模型对象代码规范其实只有3种模型,Entity、Data Object (DO)和Data Transfer Object (DTO),不过思路都是类似的,先来看看包括了大众理解的模型

- VO(View Object):视图对象,用于展示层,只要是这个东西是让人看到的就叫VO
- DTO(Data Transfer Object):数据传输对象,泛指用于展示层与服务层之间的数据传输对象,即前后端之间的传输;在微服务盛行的现在,服务和服务之间调用的传输对象也可以叫 DTO
- DO(Domain Object):领域对象,就是从现实世界中抽象出来的有形或无形的业务实体。还有一个版本叫 DO(Data Object),等同于下面的 PO
- PO(Persistent Object):持久化对象,它跟持久层(通常是关系型数据库)的数据结构形成一一对应的映射关系,如果持久层是关系型数据库,那么,数据表中的每个字段(或若干个)就对应PO的一个(或若干个)属性
DDD 中的3种模型
- Data Object (DO、数据对象):在DDD的规范里,DO应该仅仅作为数据库物理表格的映射,不能参与到业务逻辑中
- Entity(实体对象):实体对象是我们正常业务应该用的业务模型,它的字段和方法应该和业务语言保持一致,和持久化方式无关。也就是说,Entity和DO很可能有着完全不一样的字段命名和字段类型,甚至嵌套关系。Entity的生命周期应该仅存在于内存中,不需要可序列化和可持久化。等同于上图中的 BO
- DTO(传输对象):主要作为 Application 层的入参和出参,在表现层,可以被看做 param 入参以及 VO 出参,应该避免让业务对象变成一个万能大对象
在实际开发中DO、Entity 和 DTO 不一定是1:1:1的关系,一个 Entity 应该可以对应多个 DO,应该 DTO 又可以对应多个 Entity

模型之间的转换
@mapper 注解可以直接作用与接口上,实现模型之间的转换,默认让对象中相同名称的属性相互转换,入参为需要转换的对象,返回值为被转换的对象,同时,list也可以进行转换
@Mapper
public interface UserConvert {
UserConvert INSTANCE = Mappers.getMapper(UserConvert.class);
UserVo convert(UserPo userPo);
UserPo convert(UserVo userVo);
List<UserPo> convert(List<UserVo> userVo);
}
如果有不相同名称的属性需要转换,可以加上 @Mapping 注解
@Mapper
public interface UserConvert {
@Mapping(source = "name", target = "userName")
UserVo convert(UserPo userPo);
}
其对应的信息不仅仅来自一个类, 那么, 我们也可以通过配置来实现多到一的转换
@Mapping(target = "periodId", source = "studentDetailsPo.periodId")
@Mapping(target = "studentName", source = "userPo.name")
StudentInfoVo convert(UserPo userPo, StudentDetailsPo studentDetailsPo);
转换器的位置应该放在这里
开发的流程
首先应该理清自己负责的系统的关系,画好时序图和类结构图。同时进行数据库的建表与接口的设计,一切以需求为核心
进行参数校验,写代码的过程中额外注意空指针的情况,变量命名,应该从上向下的实现功能