大数据ClickHouse进阶(四):ClickHouse的索引深入了解

文章目录
ClickHouse的索引深入了解
一、一级索引
二、二级索引(跳数索引)
ClickHouse的索引深入了解
一、一级索引
在MergeTree中PRIMARY KEY 主键并不用于去重,而是用于索引,加快查询速度,MergeTree会根据index_granularity间隔(默认8192行),为数据表生成一级索引并保存至primary.idx文件内,索引数据按照PRIMARY KEY 排序,相对于使用PRIMARY KEY 更常见的方式是通过ORDER BY 方式指定主键。
- 稀疏索引
primary.idx文件内的一级索引采用稀疏索引实现。有稀疏索引就有稠密索引,二者区别如下:

在稠密索引中每一行索引标记都会对应到一行具体的数据记录。而在稀疏索引中每一行索引标记对应的是一段数据,而不是一行。
稀疏索引的优势显而易见,仅需要使用少量的索引标记就能够记录大量的数据区间位置信息,而且数据量越大优势越明显。在MergeTree系列引擎表中对应的primary.idx文件就是稀疏索引,由于稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存。
-
索引粒度
在ClickHouse MergeTree引擎中默认的索引粒度是8192,参数为index_granularity,一般我们不会修改此值,按照默认8192即可。我们可以通过以下sql语句查看每个MergeTree引擎表对应的index_granulariry的值:
node1 :) show create table t_mt;
索引粒度对于MergeTree表引擎非常重要,可以根据整个数据的长度,按照索引粒度对数据进行标注,然后抽取对应的数据形成索引。
- 索引形成过程
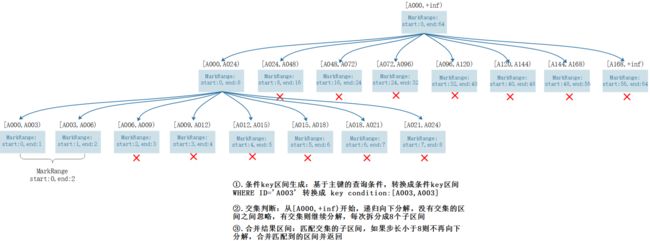
表数据以index_granularity的粒度(默认8192)被标记成多个小区间,其中每个区间最多8192行数据,每个区间标记后形成一个MarkRange,通过start和end表示MarkRange的具体范围,数据文件也会按照index_granularity的间隔粒度生成压缩数据块。由于是稀疏索引,MergeTree需要间隔index_granularity行数据生成一条索引,同时对应一个索引编号,每个MarRange与一个索引编号对应,通过与start及end对应的索引编号的取值,可以得到对应的数值区间;索引编号对应的索引值会依据声明的主键字段获取,最终索引编号和索引值被写入primary.idx文件中保存。
假设现在有一份测试数据,共192行记录,其中主键ID为String类型,ID值从A000开始,后面依次为A001、A002...直到A192为止,假设我们设置MergeTree的索引粒度index_granularity=3,根据索引的生成规则,primary.idx文件内的索引数据如下:

根据索引数据,MergeTree将此数据片段划分成192/3=64个小的MarkRange,其中所有MarkRange的最大数值区间为[A000,+inf),划分的MarkRange如下:

- 索引查询过程
使用索引查询其实就是两个数值区间的交集判断,其中一个区间是有基于主键的查询条件转换而来的条件区间,而另一个区间是上图中MarkRange对应的数值区间。
整个索引查询的过程大致分为3个步骤:
1、生成查询条件区间
查询时首先将查询条件转换为条件区间,即便是单个值的查询条件也会转换成区间的形式,例如:
WHERE ID='A003'
['A003','A003']
WHERE ID>'A000'
['A000',+inf]
WHERE ID<'A188'
(-inf,'A188']
WHERE ID like 'A006%'
('A006','A007']2、递归交集判断
以递归的方式依次对MarkRange的数值区间与条件区间做交集判断,从最大的区间[A000,+inf)开:
- 如果不存在交集,则直接忽略掉整段MarkRange
- 如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个区间(由merge_tree_coarse_index_granularity指定,默认值为8),并重复此规则,继续做递归交集判断。
- 如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。
3、合并MarkRange区间
将最终匹配的MarkRange聚在一起,合并他们的范围。
当查询条件WHERE ID ='A003'的时候,最终读取[A000,A003)和[A003,A006]两个区间的数据即可,他们对应的MarkRange(start:0,end:2)范围,而无其他无用的区间都被裁剪过滤掉,因为MarkRange转换的数值区间是闭区间,所以会额外匹配到临近的一个区间,完整的逻辑图如下图所示:
二、二级索引(跳数索引)
除了一级索引之外,MergeTree同样支持二级索引,二级索引又称为跳数索引,由数据的聚合信息构建而成,根据索引类型的不同,其聚合信息的内容也不同,跳数索引的目的与一级索引一样,也是帮助查询时减少数据扫描的范围。
跳数索引需要在Create语句内定义,完整语法如下:
INDEX index_name expr TYPE index_type(...) GRANULARITY granularity对以上参数的解释如下:
- index_name:定义的二级索引名称
- index_type:跳数索引类型,最常用就是minmax索引类型。minmax索引记录了一段数据内的最小和最大极值,其索引的作用类似分区目录,能够快速跳过无用的数据区间。
- granularity:定义聚合信息汇总的粒度。
- 与一级索引一样,如果在建表语句中声明了跳数索引,则会在路径“/var/lib/ClickHouse/data/DATABASE/TABLE/PARTITION/”目录下生成索引与标记文件(skp_idx.idx与skp_idx.mrk)。
- 在接触跳数索引时,很容易将index_granularity与granularity概念混淆,对于跳数索引而言,index_granularity定义了数据的粒度,而granularity定义了聚合信息汇总的粒度,也就是说,granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据。
minmax跳数索引的生成规则
minmax跳数索引聚合信息是在一个index_granularity区间内数据的最小和最大极值。首先,数据按照index_granularity粒度间隔将数据划分成n段,总共有[0~n-1]个区间(n=total_rows/index_granularity,向上取整),接着根据跳数索引从0区间开始,依次按index_granularity粒度从数据中获取聚合信息,每次向前移动1步,聚合信息逐步累加,最后当移动granularity次区间时,则汇总并生成一行跳数索引数据。
以下图为例:假设index_granularity=8192且granularity=3,则数据会按照index_granularity划分成n等份,MergeTree从第0段分区开始,依次获取聚合信息,当获取到第3个分区时(granularity=3),则汇总并生成第一行minmax索引(前3段minmax极值汇总后取值为[1,9])。

minmax跳数索引案例:
#删除表 t_mt
node1 :) drop table t_mt;
#重新创建t_mt表,包含二级索引
node1 :)CREATE TABLE t_mt
(
id UInt8,
name String,
age UInt8,
birthday Date,
location String,
INDEX a id TYPE minmax GRANULARITY 5
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(birthday)
ORDER BY (id, age)
PRIMARY KEY id
#插入数据
insert into t_mt values (1,'张三',18,'2021-06-01','上海'), (2,'李四',19,'2021-02-10','北京'), (3,'王五',12,'2021-06-01','天津'), (1,'马六',10,'2021-06-18','上海'), (5,'田七',22,'2021-02-09','广州');
#查看数据分区路径 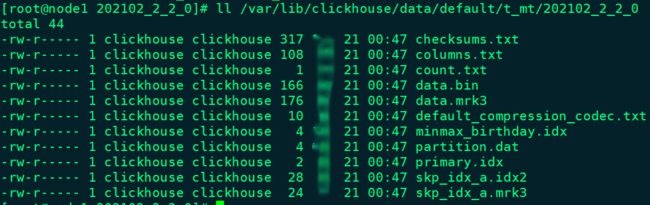
- 博客主页:https://lansonli.blog.csdn.net
- 欢迎点赞 收藏 ⭐留言 如有错误敬请指正!
- 本文由 Lansonli 原创,首发于 CSDN博客
- 停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨