【极富参考价值!】第1章 ClickHouse 简介《ClickHouse 企业级大数据分析引擎实战》...

《ClickHouse 企业级大数据分析引擎实战》全书目录
目录
第1章 ClickHouse 简介
第2章 MergeTree 表存储引擎
第3章 ClickHouse SQL 执行原理
第4章 分布式的 ClickHouse:集群、分片、副本
第5章 项目实战:Spring Boot 集成 ClickHouse
第6章 ClickHouse 函数
第7章 集成外部数据源
第8章 ClickHouse 配置最佳实践
第9章 运维监控
第10章 用户标签画像平台:大数据分析引擎实战
内容简介
书名:企业级大数据分析引擎 ClickHouse 实战
作者简介
资深程序员。著有《Kotlin 极简教程》《Spring Boot 开发实战》《Kotlin 从入门到进阶实战》。
公众号:禅与计算机程序设计艺术
第1章 ClickHouse 简介《ClickHouse 企业级大数据分析引擎实战》
本章内容
总体介绍 ClickHouse 的起源。我们将介绍 ClickHouse 是什么和不是什么,把 ClickHouse 和其他NoSQL数据库进行行对比,介绍一些通用的使用场景。我们会帮你判断对于你的项目和公司来说 ClickHouse 是否是正确的技术选择。第1章包括简单安装 ClickHouse 和开始存储一点儿数据。
ClickHouse 简介
ClickHouse 概述
ClickHouse is a column-oriented database management system (DBMS) for online analytical processing of queries (OLAP).
Clickhouse一个用于联机分析处理(OLAP)的列式数据库管理系统(columnar DBMS),由俄罗斯最大的搜索引擎Yandex在2016年开源)。其采用了面向列的存储方式,性能远超传统面向行的DBMS,近几年受到广泛关注。ClickHouse 提供海量数据上更强的查询服务和数据写入性能,应用场景包括数据多维分析、机器学习模型评估、微服务监控和统计等。
源码:https://github.com/yandex/ClickHouse
大数据领域的 MapReduce 的基本思想
我们有一些问题。这对我们来说太大了,无法在一台计算机上解决。
假设我们正在尝试推出一个高吞吐量的批量生产三明治店。我们有很多原材料,我们需要尽快生产三明治。我们将其分为三个阶段。
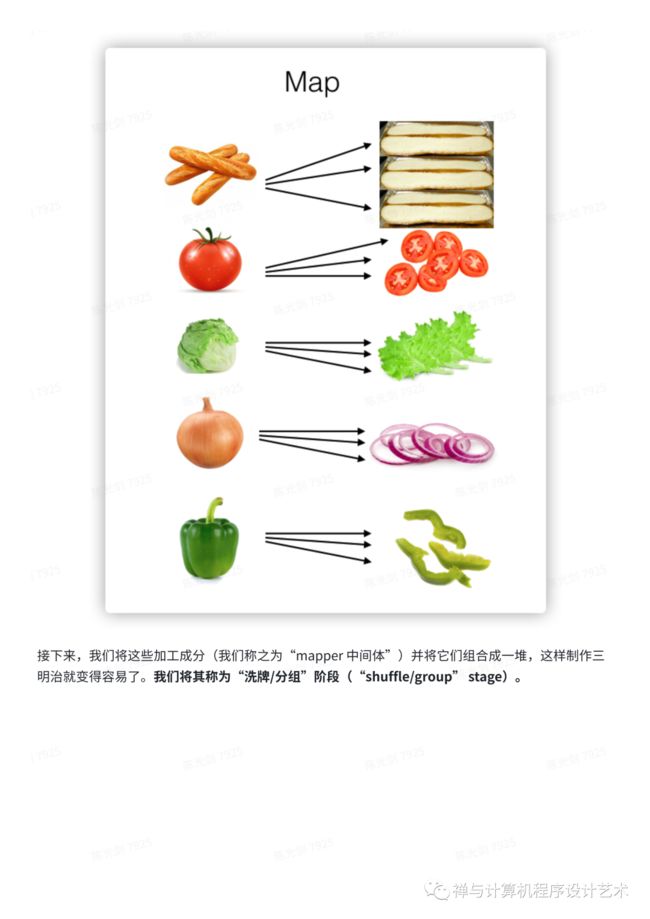
首先,我们将原材料分发给我们店里的工人。一个人拿西红柿,一个人拿生菜,一个人拿洋葱,依此类推。我们称之为“map”阶段。

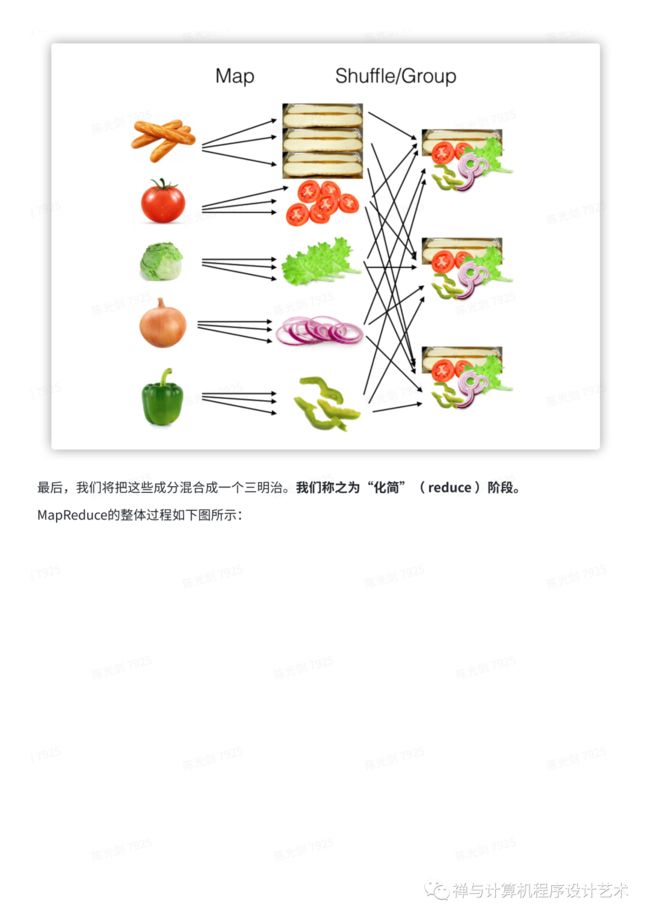
接下来,我们将这些加工成分(我们称之为“mapper 中间体”)并将它们组合成一堆,这样制作三明治就变得容易了。我们将其称为“洗牌/分组”阶段(“shuffle/group” stage)。
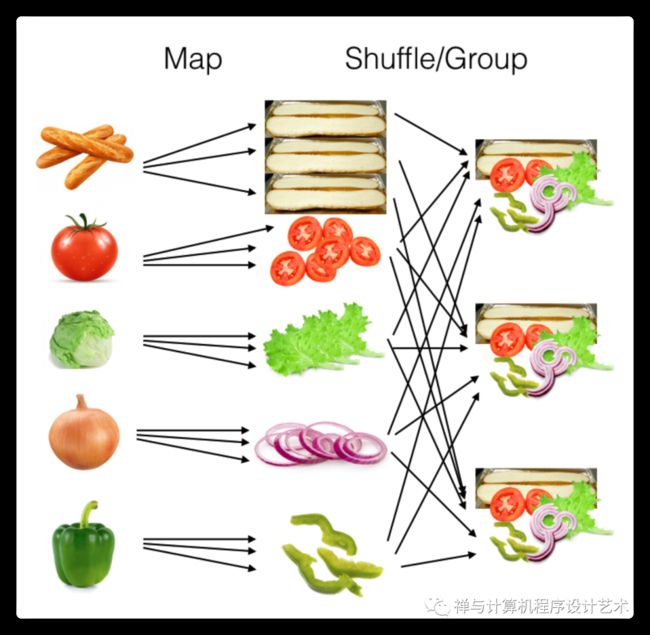
最后,我们将把这些成分混合成一个三明治。我们称之为“化简”( reduce )阶段。
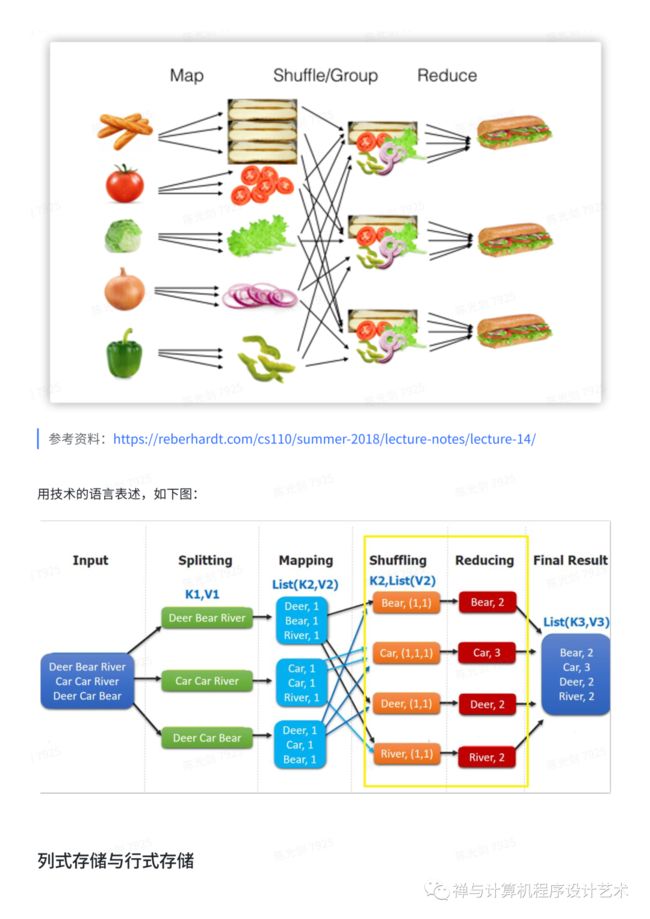
MapReduce的整体过程如下图所示:
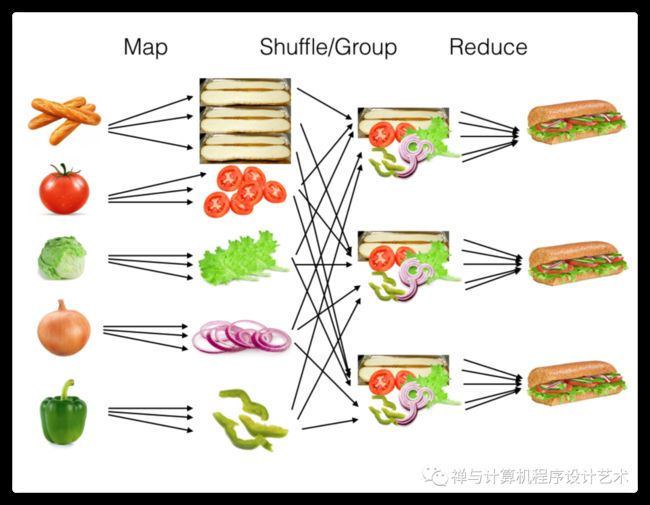
参考资料:https://reberhardt.com/cs110/summer-2018/lecture-notes/lecture-14/
Map Reduce 思想用动画表示如下:
1.Map : 剁碎

2.Shuffle (Group):洗牌,分组
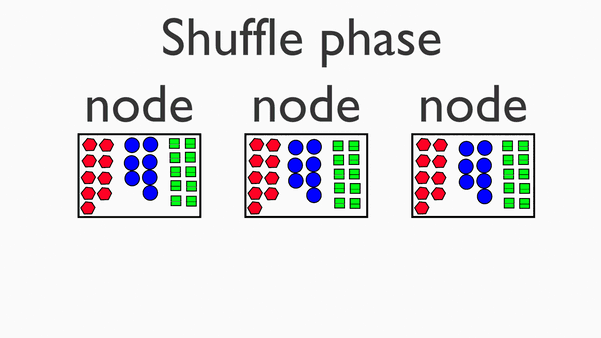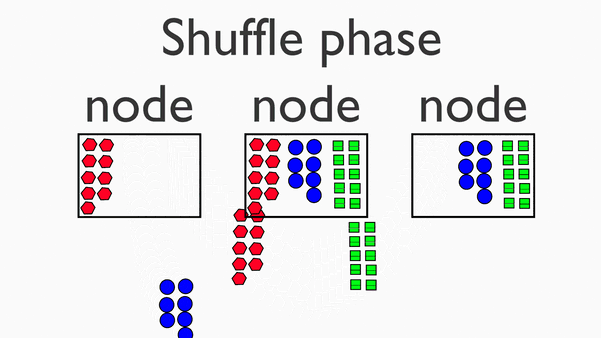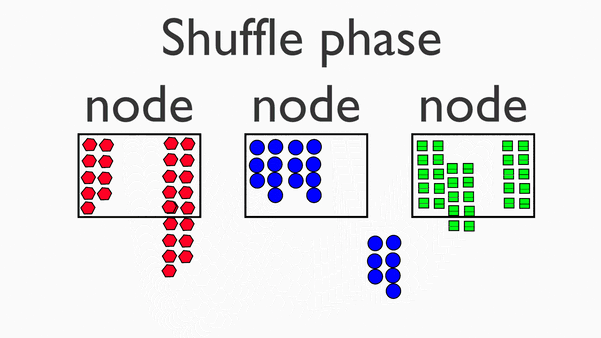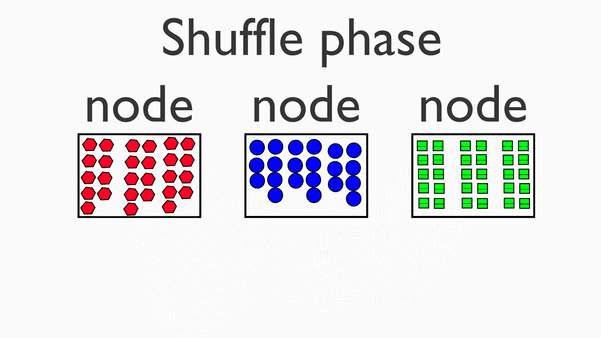
3.Reduce:化简
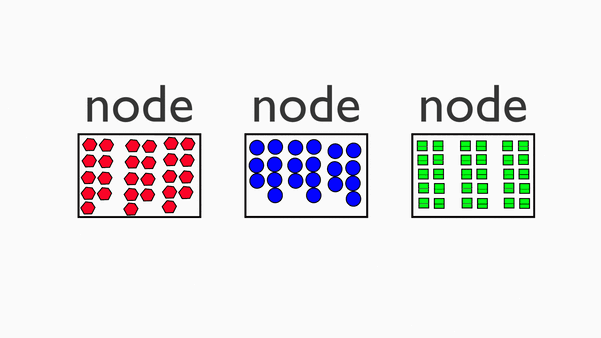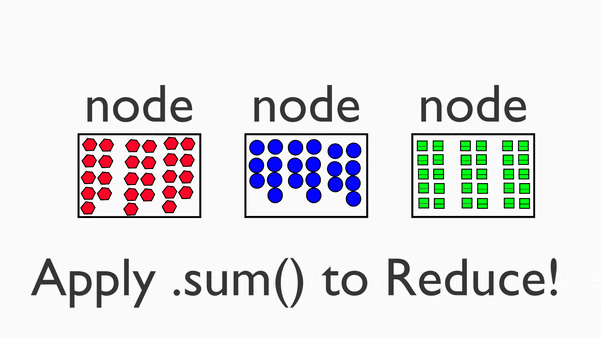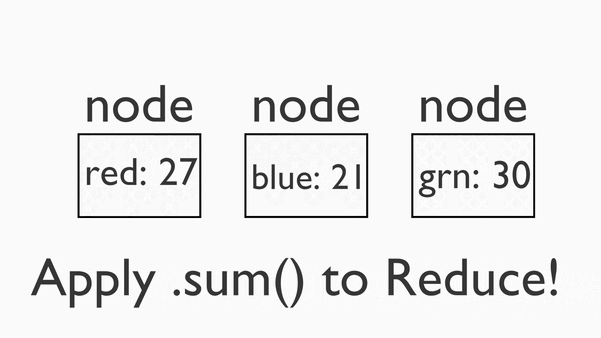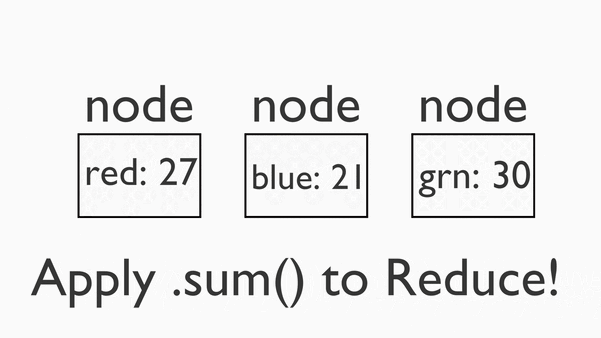
列式存储与行式存储
行存与列存
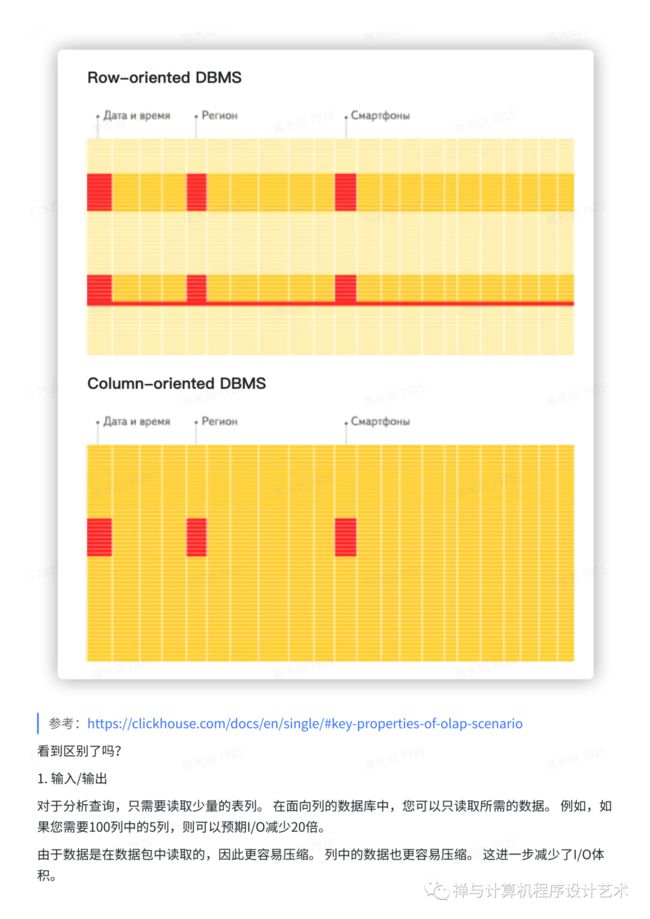
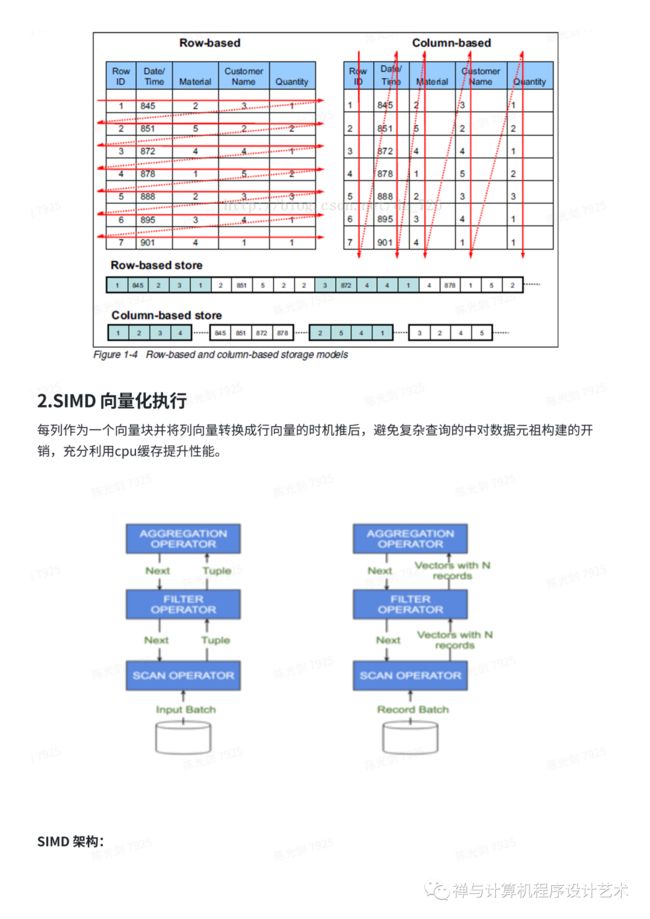
In a “normal” row-oriented DBMS, data is stored in this order:
In other words, all the values related to a row are physically stored next to each other. Examples of a row-oriented DBMS are MySQL, Postgres, and MS SQL Server. In a column-oriented DBMS, data is stored like this:
用具体的数据结构代码实例说明就是:
列式存储:
Kotlin package ck class ColumnStorageTable { var WatchID: List var JavaEnable: List var Title: List var GoodEvent: List var EventTime: List } class ColumnStorageTableData { var columnStorageTable = ColumnStorageTable() } |
行式存储
Kotlin package ck class RowStorageTable { var WatchID: String = "" var JavaEnable: String = "" var Title: String = "" var GoodEvent: String = "" var EventTime: String = "" } class RowStorageTableData { val lines = listOf } |
用图来形象化说明:
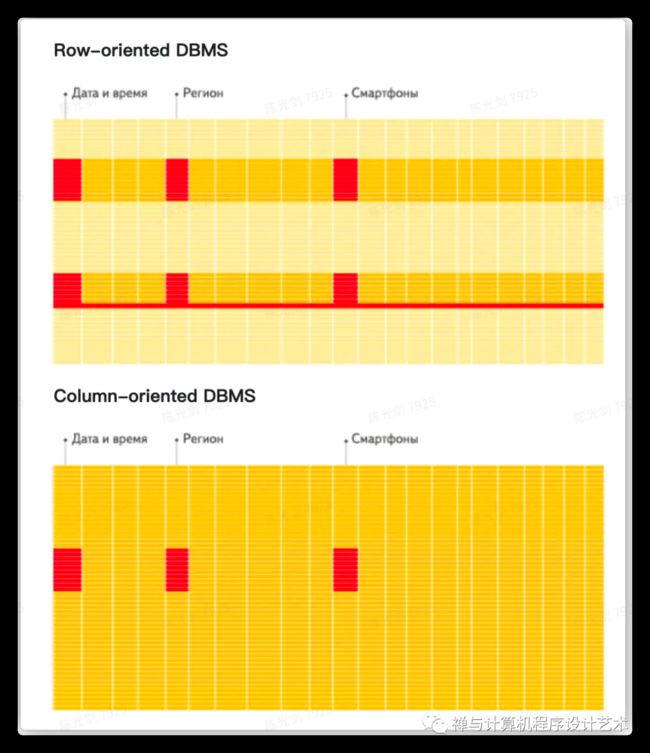
参考:https://clickhouse.com/docs/en/single/#key-properties-of-olap-scenario
看到区别了吗?
1. 输入/输出
对于分析查询,只需要读取少量的表列。 在面向列的数据库中,您可以只读取所需的数据。 例如,如果您需要100列中的5列,则可以预期I/O减少20倍。
由于数据是在数据包中读取的,因此更容易压缩。 列中的数据也更容易压缩。 这进一步减少了I/O体积。
由于减少了I/O,更多数据适合系统缓存。
例如,查询"统计每个广告平台的记录数"需要读取一个"广告平台ID"列,该列占用未压缩的1个字节。如果大部分流量不是来自广告平台,您可以预期此列的压缩率至少为10倍。当使用快速压缩算法时,可以以每秒至少几千兆字节的未压缩数据的速度进行数据解压缩。换句话说,可以在单个服务器上以大约每秒数十亿行的速度处理此查询。这种速度实际上是在实践中实现的。
2. CPU 中央处理器
由于执行查询需要处理大量行,因此它有助于为整个向量而不是单独的行调度所有操作,或者实现查询引擎,以便几乎没有调度成本。 如果不这样做,对于任何半体面的磁盘子系统,查询解释器不可避免地会使CPU停滞不前。将数据存储在列中并在可能的情况下按列进行处理是有意义的。
有两种方法可以做到这一点:
(1)矢量引擎。所有操作都是针对向量编写的,而不是针对单独的值编写的。这意味着您不需要经常调用操作,并且调度成本可以忽略不计。操作代码包含优化的内部循环。
(2)代码生成。为查询生成的代码中包含所有间接调用。
这不是在"normal" 数据库中完成的,因为它在运行简单查询时没有意义。但是,也有例外。例如,MemSQL使用代码生成来减少处理SQL查询时的延迟。(为了进行比较,分析型DBMS需要优化吞吐量,而不是延迟。)
请注意,为了提高CPU效率,查询语言必须是声明式的(SQL或MDX),或者至少是向量(J,K)。查询应该只包含隐式循环,允许优化。
列式存储的特点
• 高性能
• 高可靠,无中心、数据分片:支持多主机异步复制,可以跨多个数据中心进行部署
• 列式存储与压缩:按列存储、对列进行数据压缩
• 向量化处理
• 并行和分布式查询:Distribute_Engine支持分布式查询
• 实时查询处理和数据导入:clickHouse就是干这个的
• SQL支持:支持类SQL语句建库、建表、查询,学习使用成本低
○ 支持繁多库函数:IP转化、URL分析、预估计算/HyperLoglog等
• OLAP:不支持事务、不支持update/delete、不支持自增主键、数据不去重
列式数据库组织磁盘或内存中给定的连续列数据。基于列的存储方式,有助于减少联机分析处理 (OLAP) 的负载,因为查询会涉及到列的一个子集,但这些列都有大量的行数,对于这类查询,使用列数据格式可以大大减少从磁盘到内存和从内存到寄存器的数据转换。这样可以有效地提高整个存储体系的吞吐量。此外,列式存储让我们可以使用一些基于每列的轻量级压缩算法,节省了空间,提升了IO性能。常见的列式存储有:Vertical、HBase等。
行式存储 |
列式存储 |
|
优点 |
行数据保存在一起 便于Insert/Update |
查询时只需读取涉及的列 任何列都可以做索引 |
缺点 |
大表查询性能差、不适合数据压缩、读取某几列需要读到所有的列 |
不适用于Insert/Update、不支持事务 |
应用 |
OLTP,数据库mysql |
OLAP,HBase、clickHouse |
OLAP 和 OLTP
OLTP |
OLAP |
|
概念 |
联机事务处理(on-line transaction processing) |
联机分析处理(On-Line Analytical Processing) |
功能 |
日常操作处理 |
查询统计分析 |
工作单位 |
简单事务 |
复杂查询 |
时间要求 |
实时性 |
时间要求不严格 |
主要应用 |
数据库 mysql |
数据仓库 |
OLAP场景:
○ 绝大多数操作是读、极少更新甚至无需更新
○ 读取大量行的数据,但是一次查询往往只关注某些列
○ 无需事务的支持、数据一致性要求低,追求极致的速度
○ 统计分析场景、多维度聚合查询
数据库发展简史
计算机科学领域的所有问题,都可以通过添加一层中间层来解决。通过在用户和计算机中间添加一层逻辑层(概念模型层),于是就有了“数据库的三级模式”:数据库在三个级别 (层次)上进行抽象,使用户能够逻辑地、抽象地处理数据,而不必关心数据在计算机中的物理表示和存储。 光剑,2021.
1973: Charles Bachman with “The Programmer as Navigator”
1981: E. F. (Ted) Codd with “Relational Database: A Practical Foundation for Productivity”
2001: Ole-Johan Dahl and Kristen Nygaard for ideas fundamental to the emergence of object-oriented programming
2014: Michael Stonebraker with “The Land Sharkx are on the Squawk Box.”
在数据库的发展历史上,数据库先后经历了:
1.层次数据库
2.网状数据库
3.关系数据库
等阶段。

数据建模和数据库一起发展,它们的历史可以追溯到 1960 年代。数据库演变发生在五个“浪潮”中:
1.第一波由网络、分层、倒排列表和(在 1990 年代)面向对象的 DBMS 组成;它大约发生在 1960 年至 1999 年之间。
2.关系浪潮在 1990 年左右推出了所有 SQL 产品(以及一些非 SQL),并在 2008 年左右开始失去用户。
3.决策支持浪潮在 1990 年左右引入了在线分析处理 (OLAP) 和专门的 DBMS,并且今天仍然有效。
4.图浪潮始于 1999 年万维网联盟的语义网络堆栈,2008 年左右出现了属性图
5.NoSQL 浪潮包括大数据等等;它始于2008年。
随着云计算的发展和大数据时代的到来,关系型数据库越来越无法满足需要,这主要是由于,越来越多的半关系型和非关系型数据,需要用数据库进行存储管理。以此同时,分布式技术等新技术的出现也对数据库的技术提出了新的要求。
数仓概述
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)和唯一事实(Reality)的数据集合,用于支持管理决策(Decision Making Support)。
数据库 VS 数据仓库
数据库就是我们常用的关系型数据库(MySQL、Oracle、PostgreSQL...),还有什么非关系型数据库,它主要存放业务数据,那数据仓库有些什么数据呢?
说到他们的区别,我们一般会提到OLTP和OLAP,
OLTP:on-line transaction processing,联机事务处理,主要是业务数据,需要考虑高并发、考虑事务
OLAP:On-Line Analytical Processing,联机分析处理,重点主要是面向分析,会产生大量的查询,一般很少涉及增删改
建模理论
ClickHouse 系统架构
ClickHouse 整体架构图如下:
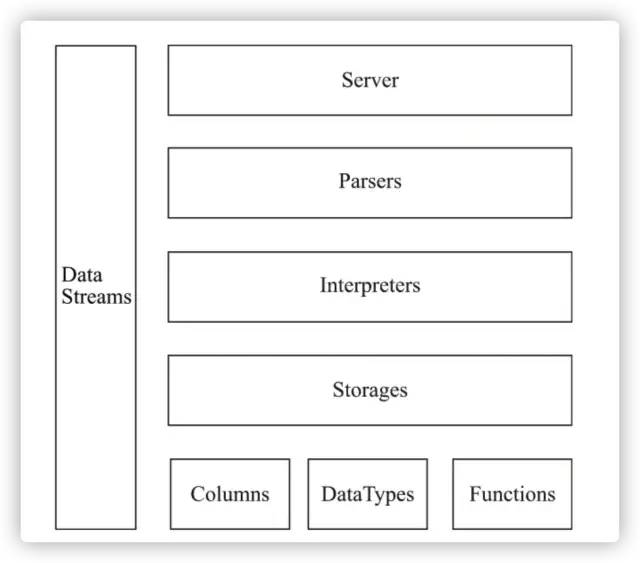
ClickHouse 是一个真正的列式数据库管理系统(DBMS)。
在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。只要有可能,操作都是基于矢量进行分派的,而不是单个的值,这被称为«矢量化查询执行»(SIMD),它有利于降低实际的数据处理开销。
这个想法并不新鲜,其可以追溯到 APL 编程语言及其后代:A +、J、K 和 Q。矢量编程被大量用于科学数据处理中。即使在关系型数据库中,这个想法也不是什么新的东西:比如,矢量编程也被大量用于 Vectorwise 系统中。
通常有两种不同的加速查询处理的方法:矢量化查询执行和运行时代码生成。在后者中,动态地为每一类查询生成代码,消除了间接分派和动态分派。这两种方法中,并没有哪一种严格地比另一种好。运行时代码生成可以更好地将多个操作融合在一起,从而充分利用 CPU 执行单元和流水线。矢量化查询执行不是特别实用,因为它涉及必须写到缓存并读回的临时向量。如果 L2 缓存容纳不下临时数据,那么这将成为一个问题。但矢量化查询执行更容易利用 CPU 的 SIMD 功能。朋友写的一篇研究论文表明,将两种方法结合起来是更好的选择。ClickHouse 使用了矢量化查询执行,同时初步提供了有限的运行时动态代码生成。
列(Columns)
要表示内存中的列(实际上是列块),需使用 IColumn 接口。该接口提供了用于实现各种关系操作符的辅助方法。几乎所有的操作都是不可变的:这些操作不会更改原始列,但是会创建一个新的修改后的列。比如,IColumn::filter 方法接受过滤字节掩码,用于 WHERE 和 HAVING 关系操作符中。另外的例子:IColumn::permute 方法支持 ORDER BY 实现,IColumn::cut 方法支持 LIMIT 实现等等。
不同的 IColumn 实现(ColumnUInt8、ColumnString 等)负责不同的列内存布局。内存布局通常是一个连续的数组。对于数据类型为整型的列,只是一个连续的数组,比如 std::vector。对于 String 列和 Array 列,则由两个向量组成:其中一个向量连续存储所有的 String 或数组元素,另一个存储每一个 String 或 Array 的起始元素在第一个向量中的偏移。而 ColumnConst 则仅在内存中存储一个值,但是看起来像一个列。
字段(Field)
尽管如此,有时候也可能需要处理单个值。表示单个值,可以使用 Field。Field 是 UInt64、Int64、Float64、String 和 Array 组成的联合。IColumn 拥有 operator[] 方法来获取第 n 个值成为一个 Field,同时也拥有 insert 方法将一个 Field 追加到一个列的末尾。这些方法并不高效,因为它们需要处理表示单一值的临时 Field 对象,但是有更高效的方法比如 insertFrom 和 insertRangeFrom 等。
Field 中并没有足够的关于一个表(table)的特定数据类型的信息。比如,UInt8、UInt16、UInt32 和 UInt64 在 Field 中均表示为 UInt64。
抽象漏洞
IColumn 具有用于数据的常见关系转换的方法,但这些方法并不能够满足所有需求。比如,ColumnUInt64 没有用于计算两列和的方法,ColumnString 没有用于进行子串搜索的方法。这些无法计算的例程在 Icolumn 之外实现。
列(Columns)上的各种函数可以通过使用 Icolumn 的方法来提取 Field 值,或根据特定的 Icolumn 实现的数据内存布局的知识,以一种通用但不高效的方式实现。为此,函数将会转换为特定的 IColumn 类型并直接处理内部表示。比如,ColumnUInt64 具有 getData 方法,该方法返回一个指向列的内部数组的引用,然后一个单独的例程可以直接读写或填充该数组。实际上,«抽象漏洞(leaky abstractions)»允许我们以更高效的方式来实现各种特定的例程。
数据类型
IDataType 负责序列化和反序列化:读写二进制或文本形式的列或单个值构成的块。IDataType 直接与表的数据类型相对应。比如,有 DataTypeUInt32、DataTypeDateTime、DataTypeString 等数据类型。
IDataType 与 IColumn 之间的关联并不大。不同的数据类型在内存中能够用相同的 IColumn 实现来表示。比如,DataTypeUInt32 和 DataTypeDateTime 都是用 ColumnUInt32 或 ColumnConstUInt32 来表示的。另外,相同的数据类型也可以用不同的 IColumn 实现来表示。比如,DataTypeUInt8 既可以使用 ColumnUInt8 来表示,也可以使用过 ColumnConstUInt8 来表示。
IDataType 仅存储元数据。比如,DataTypeUInt8 不存储任何东西(除了 vptr);DataTypeFixedString 仅存储 N(固定长度字符串的串长度)。
IDataType 具有针对各种数据格式的辅助函数。比如如下一些辅助函数:序列化一个值并加上可能的引号;序列化一个值用于 JSON 格式;序列化一个值作为 XML 格式的一部分。辅助函数与数据格式并没有直接的对应。比如,两种不同的数据格式 Pretty 和 TabSeparated 均可以使用 IDataType 接口提供的 serializeTextEscaped 这一辅助函数。
块(Block)
Block 是表示内存中表的子集(chunk)的容器,是由三元组:(IColumn, IDataType, 列名) 构成的集合。在查询执行期间,数据是按 Block 进行处理的。如果我们有一个 Block,那么就有了数据(在 IColumn 对象中),有了数据的类型信息告诉我们如何处理该列,同时也有了列名(来自表的原始列名,或人为指定的用于临时计算结果的名字)。
当我们遍历一个块中的列进行某些函数计算时,会把结果列加入到块中,但不会更改函数参数中的列,因为操作是不可变的。之后,不需要的列可以从块中删除,但不是修改。这对于消除公共子表达式非常方便。
Block 用于处理数据块。注意,对于相同类型的计算,列名和类型对不同的块保持相同,仅列数据不同。最好把块数据(block data)和块头(block header)分离开来,因为小块大小会因复制共享指针和列名而带来很高的临时字符串开销。
块流(Block Streams)
块流用于处理数据。我们可以使用块流从某个地方读取数据,执行数据转换,或将数据写到某个地方。IBlockInputStream 具有 read 方法,其能够在数据可用时获取下一个块。IBlockOutputStream 具有 write 方法,其能够将块写到某处。
块流负责:
读或写一个表。表仅返回一个流用于读写块。
完成数据格式化。比如,如果你打算将数据以 Pretty 格式输出到终端,你可以创建一个块输出流,将块写入该流中,然后进行格式化。
执行数据转换。假设你现在有 IBlockInputStream 并且打算创建一个过滤流,那么你可以创建一个 FilterBlockInputStream 并用 IBlockInputStream 进行初始化。之后,当你从 FilterBlockInputStream 中拉取块时,会从你的流中提取一个块,对其进行过滤,然后将过滤后的块返回给你。查询执行流水线就是以这种方式表示的。
还有一些更复杂的转换。比如,当你从 AggregatingBlockInputStream 拉取数据时,会从数据源读取全部数据进行聚集,然后将聚集后的数据流返回给你。另一个例子:UnionBlockInputStream 的构造函数接受多个输入源和多个线程,其能够启动多线程从多个输入源并行读取数据。
块流使用«pull»方法来控制流:当你从第一个流中拉取块时,它会接着从嵌套的流中拉取所需的块,然后整个执行流水线开始工作。»pull«和«push»都不是最好的方案,因为控制流不是明确的,这限制了各种功能的实现,比如多个查询同步执行(多个流水线合并到一起)。这个限制可以通过协程或直接运行互相等待的线程来解决。如果控制流明确,那么我们会有更多的可能性:如果我们定位了数据从一个计算单元传递到那些外部的计算单元中其中一个计算单元的逻辑。阅读这篇文章来获取更多的想法。
我们需要注意,查询执行流水线在每一步都会创建临时数据。我们要尽量使块的大小足够小,从而 CPU 缓存能够容纳下临时数据。在这个假设下,与其他计算相比,读写临时数据几乎是没有任何开销的。我们也可以考虑一种替代方案:将流水线中的多个操作融合在一起,使流水线尽可能短,并删除大量临时数据。这可能是一个优点,但同时也有缺点。比如,拆分流水线使得中间数据缓存、获取同时运行的类似查询的中间数据以及相似查询的流水线合并等功能很容易实现。
格式(Formats)
数据格式同块流一起实现。既有仅用于向客户端输出数据的»展示«格式,如 IBlockOutputStream 提供的 Pretty 格式,也有其它输入输出格式,比如 TabSeparated 或 JSONEachRow。
此外还有行流:IRowInputStream 和 IRowOutputStream。它们允许你按行 pull/push 数据,而不是按块。行流只需要简单地面向行格式实现。包装器 BlockInputStreamFromRowInputStream 和 BlockOutputStreamFromRowOutputStream 允许你将面向行的流转换为正常的面向块的流。
I/O
对于面向字节的输入输出,有 ReadBuffer 和 WriteBuffer 这两个抽象类。它们用来替代 C++ 的 iostream。不用担心:每个成熟的 C++ 项目都会有充分的理由使用某些东西来代替 iostream。
ReadBuffer 和 WriteBuffer 由一个连续的缓冲区和指向缓冲区中某个位置的一个指针组成。实现中,缓冲区可能拥有内存,也可能不拥有内存。有一个虚方法会使用随后的数据来填充缓冲区(针对 ReadBuffer)或刷新缓冲区(针对 WriteBuffer),该虚方法很少被调用。
ReadBuffer 和 WriteBuffer 的实现用于处理文件、文件描述符和网络套接字(socket),也用于实现压缩(CompressedWriteBuffer 在写入数据前需要先用一个 WriteBuffer 进行初始化并进行压缩)和其它用途。ConcatReadBuffer、LimitReadBuffer 和 HashingWriteBuffer 的用途正如其名字所描述的一样。
ReadBuffer 和 WriteBuffer 仅处理字节。为了实现格式化输入和输出(比如以十进制格式写一个数字),ReadHelpers 和 WriteHelpers 头文件中有一些辅助函数可用。
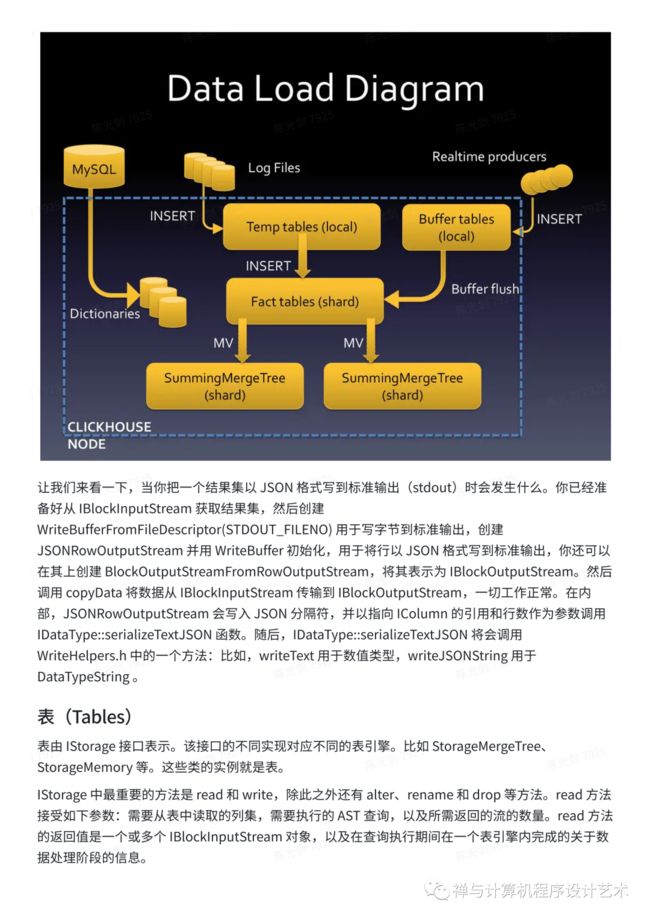
让我们来看一下,当你把一个结果集以 JSON 格式写到标准输出(stdout)时会发生什么。你已经准备好从 IBlockInputStream 获取结果集,然后创建 WriteBufferFromFileDescriptor(STDOUT_FILENO) 用于写字节到标准输出,创建 JSONRowOutputStream 并用 WriteBuffer 初始化,用于将行以 JSON 格式写到标准输出,你还可以在其上创建 BlockOutputStreamFromRowOutputStream,将其表示为 IBlockOutputStream。然后调用 copyData 将数据从 IBlockInputStream 传输到 IBlockOutputStream,一切工作正常。在内部,JSONRowOutputStream 会写入 JSON 分隔符,并以指向 IColumn 的引用和行数作为参数调用 IDataType::serializeTextJSON 函数。随后,IDataType::serializeTextJSON 将会调用 WriteHelpers.h 中的一个方法:比如,writeText 用于数值类型,writeJSONString 用于 DataTypeString 。
表(Tables)
表由 IStorage 接口表示。该接口的不同实现对应不同的表引擎。比如 StorageMergeTree、StorageMemory 等。这些类的实例就是表。
IStorage 中最重要的方法是 read 和 write,除此之外还有 alter、rename 和 drop 等方法。read 方法接受如下参数:需要从表中读取的列集,需要执行的 AST 查询,以及所需返回的流的数量。read 方法的返回值是一个或多个 IBlockInputStream 对象,以及在查询执行期间在一个表引擎内完成的关于数据处理阶段的信息。
在大多数情况下,read 方法仅负责从表中读取指定的列,而不会进行进一步的数据处理。进一步的数据处理均由查询解释器完成,不由 IStorage 负责。
但是也有值得注意的例外:
AST 查询被传递给 read 方法,表引擎可以使用它来判断是否能够使用索引,从而从表中读取更少的数据。
有时候,表引擎能够将数据处理到一个特定阶段。比如,StorageDistributed 可以向远程服务器发送查询,要求它们将来自不同的远程服务器能够合并的数据处理到某个阶段,并返回预处理后的数据,然后查询解释器完成后续的数据处理。
表的 read 方法能够返回多个 IBlockInputStream 对象以允许并行处理数据。多个块输入流能够从一个表中并行读取。然后你可以通过不同的转换对这些流进行装饰(比如表达式求值或过滤),转换过程能够独立计算,并在其上创建一个 UnionBlockInputStream,以并行读取多个流。
另外也有 TableFunction。TableFunction 能够在查询的 FROM 字句中返回一个临时的 IStorage 以供使用。
要快速了解如何实现自己的表引擎,可以查看一些简单的表引擎,比如 StorageMemory 或 StorageTinyLog。
作为 read 方法的结果,IStorage 返回 QueryProcessingStage - 关于 storage 里哪部分查询已经被计算的信息。当前我们仅有非常粗粒度的信息。Storage 无法告诉我们«对于这个范围的数据,我已经处理完了 WHERE 字句里的这部分表达式»。我们需要在这个地方继续努力。
解析器(Parsers)
查询由一个手写递归下降解析器解析。比如, ParserSelectQuery 只是针对查询的不同部分递归地调用下层解析器。解析器创建 AST。AST 由节点表示,节点是 IAST 的实例。
由于历史原因,未使用解析器生成器。
解释器(Interpreters)
解释器负责从 AST 创建查询执行流水线。既有一些简单的解释器,如 InterpreterExistsQuery 和 InterpreterDropQuery,也有更复杂的解释器,如 InterpreterSelectQuery。查询执行流水线由块输入或输出流组成。比如,SELECT 查询的解释结果是从 FROM 字句的结果集中读取数据的 IBlockInputStream;INSERT 查询的结果是写入需要插入的数据的 IBlockOutputStream;SELECT INSERT 查询的解释结果是 IBlockInputStream,它在第一次读取时返回一个空结果集,同时将数据从 SELECT 复制到 INSERT。
InterpreterSelectQuery 使用 ExpressionAnalyzer 和 ExpressionActions 机制来进行查询分析和转换。这是大多数基于规则的查询优化完成的地方。ExpressionAnalyzer 非常混乱,应该进行重写:不同的查询转换和优化应该被提取出来并划分成不同的类,从而允许模块化转换或查询。
函数(Functions)
函数既有普通函数,也有聚合函数。对于聚合函数,请看下一节。
普通函数不会改变行数 - 它们的执行看起来就像是独立地处理每一行数据。实际上,函数不会作用于一个单独的行上,而是作用在以 Block 为单位的数据上,以实现向量查询执行。
还有一些杂项函数,比如 块大小、rowNumberInBlock,以及 跑累积,它们对块进行处理,并且不遵从行的独立性。
ClickHouse 具有强类型,因此隐式类型转换不会发生。如果函数不支持某个特定的类型组合,则会抛出异常。但函数可以通过重载以支持许多不同的类型组合。比如,plus 函数(用于实现 + 运算符)支持任意数字类型的组合:UInt8 + Float32,UInt16 + Int8 等。同时,一些可变参数的函数能够级接收任意数目的参数,比如 concat 函数。
实现函数可能有些不方便,因为函数的实现需要包含所有支持该操作的数据类型和 IColumn 类型。比如,plus 函数能够利用 C++ 模板针对不同的数字类型组合、常量以及非常量的左值和右值进行代码生成。
这是一个实现动态代码生成的好地方,从而能够避免模板代码膨胀。同样,运行时代码生成也使得实现融合函数成为可能,比如融合«乘-加»,或者在单层循环迭代中进行多重比较。
由于向量查询执行,函数不会«短路»。比如,如果你写 WHERE f(x) AND g(y),两边都会进行计算,即使是对于 f(x) 为 0 的行(除非 f(x) 是零常量表达式)。但是如果 f(x) 的选择条件很高,并且计算 f(x) 比计算 g(y) 要划算得多,那么最好进行多遍计算:首先计算 f(x),根据计算结果对列数据进行过滤,然后计算 g(y),之后只需对较小数量的数据进行过滤。
聚合函数(AggregateFunction)
聚合函数是状态函数。它们将传入的值激活到某个状态,并允许你从该状态获取结果。聚合函数使用 IAggregateFunction 接口进行管理。状态可以非常简单(AggregateFunctionCount 的状态只是一个单一的UInt64 值),也可以非常复杂(AggregateFunctionUniqCombined 的状态是由一个线性数组、一个散列表和一个 HyperLogLog 概率数据结构组合而成的)。
为了能够在执行一个基数很大的 GROUP BY 查询时处理多个聚合状态,需要在 Arena(一个内存池)或任何合适的内存块中分配状态。状态可以有一个非平凡的构造器和析构器:比如,复杂的聚合状态能够自己分配额外的内存。这需要注意状态的创建和销毁并恰当地传递状态的所有权,以跟踪谁将何时销毁状态。
聚合状态可以被序列化和反序列化,以在分布式查询执行期间通过网络传递或者在内存不够的时候将其写到硬盘。聚合状态甚至可以通过 DataTypeAggregateFunction 存储到一个表中,以允许数据的增量聚合。
聚合函数状态的序列化数据格式目前尚未版本化。如果只是临时存储聚合状态,这样是可以的。但是我们有 AggregatingMergeTree 表引擎用于增量聚合,并且人们已经在生产中使用它。这就是为什么在未来当我们更改任何聚合函数的序列化格式时需要增加向后兼容的支持。
服务器(Server)
服务器实现了多个不同的接口:
一个用于任何外部客户端的 HTTP 接口。
一个用于本机 ClickHouse 客户端以及在分布式查询执行中跨服务器通信的 TCP 接口。
一个用于传输数据以进行拷贝的接口。
在内部,它只是一个没有协程、纤程等的基础多线程服务器。服务器不是为处理高速率的简单查询设计的,而是为处理相对低速率的复杂查询设计的,每一个复杂查询能够对大量的数据进行处理分析。
服务器使用必要的查询执行需要的环境初始化 Context 类:可用数据库列表、用户和访问权限、设置、集群、进程列表和查询日志等。这些环境被解释器使用。
我们维护了服务器 TCP 协议的完全向后向前兼容性:旧客户端可以和新服务器通信,新客户端也可以和旧服务器通信。但是我们并不想永久维护它,我们将在大约一年后删除对旧版本的支持。
对于所有的外部应用,我们推荐使用 HTTP 接口,因为该接口很简单,容易使用。TCP 接口与内部数据结构的联系更加紧密:它使用内部格式传递数据块,并使用自定义帧来压缩数据。我们没有发布该协议的 C 库,因为它需要链接大部分的 ClickHouse 代码库,这是不切实际的。
Table Engine
Log引擎簇
Log引擎单列以压缩文件形式存储、对于并发读写不做任何控制,一次写入,多次读取。
MergeTree引擎簇
MergeTree引擎是clickHouse最强大的引擎。按照主键字典序排序、支持稀疏索引、支持分区、数据复制、数据抽样。不同分区的数据分割在不同数据块(part)中,MergeTree引擎会合并不同数据块的数据,适用于单个大型表,以小块的形式不断添加数据。
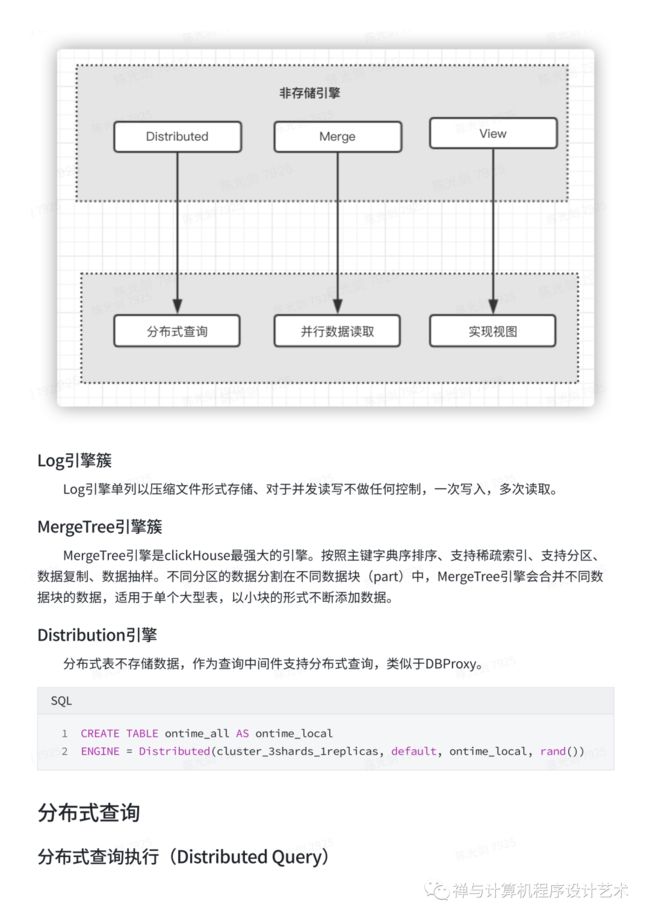
Distribution引擎
分布式表不存储数据,作为查询中间件支持分布式查询,类似于DBProxy。
SQL CREATE TABLE ontime_all AS ontime_local ENGINE = Distributed(cluster_3shards_1replicas, default, ontime_local, rand()) |
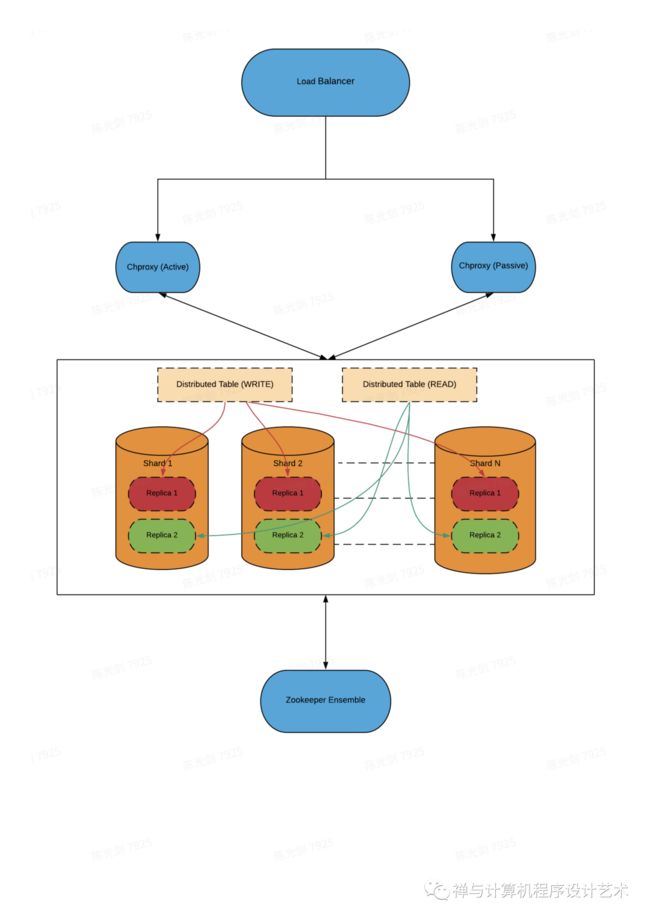
分布式查询
分布式查询执行(Distributed Query)
当面向集群查询数据的时候,通过Distributed表引擎实现。当Distributed表接收到SELECT查询的时候,它会依次查询每个分片的数据,再合并汇总返回。
首先它会将针对分布式表的SQL语句,按照分片数量将查询拆分成若干个针对本地表的子查询,然后向各个分片发起查询,最后再汇总各个分片的返回结果。
集群设置中的服务器大多是独立的。你可以在一个集群中的一个或多个服务器上创建一个 Distributed 表。Distributed 表本身并不存储数据,它只为集群的多个节点上的所有本地表提供一个«视图(view)»。当从 Distributed 表中进行 SELECT 时,它会重写该查询,根据负载平衡设置来选择远程节点,并将查询发送给节点。Distributed 表请求远程服务器处理查询,直到可以合并来自不同服务器的中间结果的阶段。然后它接收中间结果并进行合并。分布式表会尝试将尽可能多的工作分配给远程服务器,并且不会通过网络发送太多的中间数据。
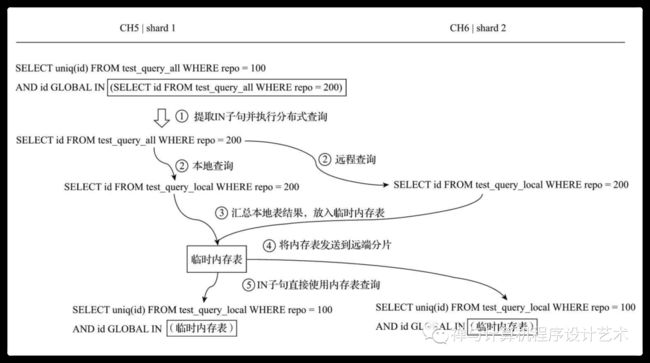
例如,一个分布式查询 SQL 如下:
SELECT uniq(id)
FROM test_query_all
WHERE repo = 100
AND id GLOBAL IN
(SELECT id FROM test_query_all WHERE repo = 200)查询的核心过程,由上至下大致分成5个步骤:
(1)将IN子句单独提出,发起了一次分布式查询。
(2)将分布式表转local本地表后,分别在本地和远端分片执行
查询。
(3)将IN子句查询的结果进行汇总,并放入一张临时的内存表进
行保存。
(4)将内存表发送到远端分片节点。
(5)将分布式表转为本地表后,开始执行完整的SQL语句,IN子
句直接使用临时内存表的数据。
整个查询的流程示意图如下(使用GLOBAL IN):
Clickhouse 表引擎
Clickhouse表引擎决定了:
• 数据如何存储,如何读取
• 支持何种查询
• 并发数据访问能力
• 索引的使用
• 是否支持多线程请求执行
• 数据如何同步
当读取数据时, 引擎只需要抽取必要的列簇. 然而,在一些场景下,引擎可以半处理数据
对于大多数场合下,应该使用 MergeTree家族 引擎
以下包括官方介绍的17种表引擎的介绍:
1. TinyLog引擎
TinyLog 是最简单的表引擎, 它将数据保存到磁盘. 每一列都以单独压缩文件形式保存. 当写入数据时, 数据追加到文件的末尾
并发数据访问不限制任何形式
同时读写,读操作将报错
同时写,数据损坏
典型使用场景:一次写入,多次读取的应用场景。此引擎适用于相对较小的表(建议最多100W行)。如果您有许多小表,则使用此表引擎是有意义的,因为它比Log引擎更简单(需要打开的文件更少)。当您拥有大量小表时,这种情况可能会导致生产效率低下。
TinyLog 引擎 不支持索引
在Yandex.Metrica中,TinyLog表用于数据的小批量处理的中间表
2. Log引擎
类似TinyLog,不同于TinyLog在于:标记 "marks"的小文件同时保留在列存储文件中. 这些标记写到每个数据块中 ,标记中包含偏移量,可以知道从哪开始读文件,跳过特定的行数. 此机制使得能够支持多线程并行读取
并发读取,写入时阻塞读取,如果写入失败,表将会被破坏
Log 引擎不支持索引
Log引擎适用于临时数据,一次写入表以及测试或演示目的
3. Memory引擎
内存表引擎保存在内存中, 数据处于未压缩状态. 数据保存格式与读取数据的格式相同
并发数据访问是同步的. 无锁访问
读写数据操作互相不受影响. 但数据索引不支持
因为无磁盘读写, 压缩/解压缩, 和序列化/反序列化操作,因此单个SQL语句查询可达到 10 GB/秒(高效率,多数情况下,效率能等同于Merge Tree)
当重启服务器后, 数据会在表中清空
它可用于小数据量(1亿条左右)的高速读取数据场景或用于测试环境.
内存引擎也可用于外部数据的临时表查询和实现 GLOBAL IN 操作
4. Buffers引擎
将数据写入到内存中,周期性刷新数据到另外的表中。在读取操作的过程中,数据从 Buffer 和另外的表中同时读取。
周期性刷新数据到下级表,可以设置 时间/条数/size,满足就进行刷新
Buffer表不支持索引,完全扫描大缓存区的数据可能会很慢(下级表使用自己的索引)
如果Buffer表中的列集与下级表中的列集不匹配,则会插入两个表中存在的列的子集
如果Buffer表和下级表中的某列在类型上不匹配,则会输出异常,并清除缓存
如果对应的下级表不存在,同样会输出异常,并清除缓存
如果需要执行Alert,建议先删除buffer表,则Alert下级表,然后再次创建Buffer表
如果服务器异常重启,缓冲区中的数据将丢失
PREWHERE,FINAL和SAMPLE对缓冲表不起作用,这些条件直接传递到下级表,不用于Buffer中的数据
当添加数据到Buffer时,如果一个缓冲区被锁,这时读操作可能会出现延迟
写入到Buffer中的数据,最终可能会以不同的顺序被刷新不同的块中,因此,Buffer表很难用于正确写入CollapsingMergeTree
对于目标表是表,Buffer 表中的数据会丢失表的相关特性,在使用过程中容易出问题
只建议在极少数情况下使用Buffer表
• 当在一个单位时间内从大量服务器接收到太多INSERT并且在插入之前无法缓冲数据时使用缓冲表,这意味着INSERT不能足够快地运行
• 请注意,一次插入一行数据是没有意义的,即使对于Buffer表也是如此。这只会产生每秒几千行的速度,而插入更大的数据块每秒可以产生超过一百万行
5. 外部数据
ClickHouse允许向服务器发送处理查询所需的数据以及SELECT查询。此数据放在临时表中(请参阅“临时表”一节),可以在查询中使用(例如,在IN运算符中)。
如果需要使用大量外部数据运行多个查询,请不要使用此功能,最好提前将数据上传到数据库
可以使用命令行客户端(在非交互模式下)或使用HTTP接口上载外部数据。
6. Merge Tree 引擎
Merge Tree系列引擎,是Clickhouse 最强大的引擎
主要特性:
1. 按主键排序存储
2. 支持稀疏索引,便于更快查找数据
3. 支持分区,在使用分区的某些操作时,Clickhouse有自动机制确保更佳的查询性能
4. 支持数据**,见ReplicatedMergeTree家族引擎
5. 支持数据抽样
MergeTree 表存储引擎,在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往复合并的特点也正是合并树的名称由来。
MergeTree 核心引擎如下:
ReplacingMergeTree:在后台数据合并期间,对具有相同排序键的数据进行去重操作。
SummingMergeTree:当合并数据时,会把具有相同主键的记录合并为一条记录。根据聚合字段设置,该字段的值为聚合后的汇总值,非聚合字段使用第一条记录的值,聚合字段类型必须为数值类型。
AggregatingMergeTree:在同一数据分区下,可以将具有相同主键的数据进行聚合。
CollapsingMergeTree:在同一数据分区下,对具有相同主键的数据进行折叠合并。
VersionedCollapsingMergeTree:基于CollapsingMergeTree引擎,增添了数据版本信息字段配置选项。在数据依据ORDER BY设置对数据进行排序的基础上,如果数据的版本信息列不在排序字段中,那么版本信息会被隐式的作为ORDER BY的最后一列从而影响数据排序。
GraphiteMergeTree:用来存储时序数据库Graphites的数据。
MergeTree是该系列引擎中最核心的引擎,其他引擎均以MergeTree为基础,并在数据合并过程中实现了不同的特性,从而构成了MergeTree表引擎家族。下面我们通过MergeTree来具体了解MergeTree表系列引擎。
数据存储
插入数据时,会创建单独的数据块(part),每个数据部分按主键排序按字典顺序排序;例如,如果主键是(CounterID,Date),则part中的数据先按CounterID排序,再按Date排序。
属于不同分区的数据被分割在不同的块中(part),为了更高效的存储,Clickhouse会合并不同的part。不同分区中的数据块不会进行合并,合并机制不保证具有相同主键的所有行都在同一数据部分中
对于每个数据部分,ClickHouse创建一个索引文件,其中包含每个索引行的主键值(“mark”)。索引行号被定义为n * index_granularity。最大值n等于将总行数除以index_granularity的整数部分。对于每列,“标记”也写入与主键相同的索引行。这些“标记”允许您直接在列中查找数据。
MergeTree引擎的适合场景:单个大型表,并且以小块的形式不断向其中添加数据
对于主键和索引在查询中的高效原理
两个clickhouse的特性:
• 数据按照主键排序
• 稀疏索引
举例:主键(CounterID, Date),排序后的数据及生成的索引类似于:
SQL Whole data: [-------------------------------------------------------------------------] CounterID: [aaaaaaaaaaaaaaaaaabbbbcdeeeeeeeeeeeeefgggggggghhhhhhhhhiiiiiiiiikllllllll] Date: [1111111222222233331233211111222222333211111112122222223111112223311122333] Marks: | | | | | | | | | | | a,1 a,2 a,3 b,3 e,2 e,3 g,1 h,2 i,1 i,3 l,3 Marks numbers: 0 1 2 3 4 5 6 7 8 9 10 |
当数据查询为:
• CounterID in ('a', 'h'), the server reads the data in the ranges of marks [0, 3) and [6, 8)
• CounterID IN ('a', 'h') AND Date = 3, the server reads the data in the ranges of marks [1, 3) and [7, 8).
上面的示例表明,使用索引总是比完全扫描更有效。
稀疏索引
• 稀疏索引允许读取额外的数据,当读取单个主键范围时,可以从每个数据块中额外读取 index_granularity * 2行,在index_granularity=8192时,Clickhouse并不会有性能问题
• 稀疏索引能够支撑处理非常大的数据表行,因为索引存储在RAM中
• Clickhouse并不要求唯一主键。支持重复插入相同主键的数据
如何选择主键
主键中的列数没有明确限制,可以通过增减主键中的列,以达到:
提高索引性能
○ 如果主键是(a,b),则在满足以下条件时添加另一列c将提高性能:
▪ 在列c上存在条件的查询。
▪ 具有相同(a,b)值的长数据范围(比index_granularity长几倍)是常见的。换句话说,添加另一列时,您可以跳过很长的数据范围。
提高数据压缩率.
○ ClickHouse按主键对数据进行排序,因此一致性越高,压缩越好。
在CollapsingMergeTree和SummingMergeTree引擎中合并数据部件时提供其他逻辑
多列主键会对插入性能和内存消耗产生负面影响,但主键中的额外列在进行select查询时不会影响ClickHouse性能。
选择与排序键不同的主键
可以指定与排序键(用于对数据部分中的行进行排序的表达式)不同的主键(表达式,其值被写入每个标记的索引文件中)。在这种情况下,主键表达式元组必须是排序键表达式元组的前缀
排序键的ALTER是一个轻量级操作,因为当一个新列同时添加到表和排序键时,数据部分不需要更改(它们仍然按新的排序键表达式排序)
使用SummingMergeTree和AggregatingMergeTree表引擎时,此功能很有用。在使用这些引擎的常见情况下,该表有两种类型的列:维度和度量。典型查询使用任意GROUP BY聚合度量列的值并按维度过滤。由于SummingMergeTree和AggregatingMergeTree使用相同的排序键值聚合行,因此很自然地向其添加所有维度。因此,键表达式包含一长串列,并且必须使用新添加的维度频繁更新此列表。在这种情况下,在主键中只留下几列可以提供有效的范围扫描并将剩余的维列添加到排序键元组是有意义的。
在查询中使用索引和分区
对于SELECT查询,ClickHouse会判断是否可以使用索引:
对于在主键或者分区键的列,如果
WHERE / PREWHERE子句具有表示相等或不等式比较操作的表达式(作为连接元素)
或者在列操作或表达式上具有固定前缀的IN或LIKE
或某些部分重复的函数
或存在逻辑关系的表达式。
因此,Clickhouse可以利用索引机制在主键的一个或多个范围上进行快速高效查询。
在下面的示例中,针对特定跟踪代码运行时查询会很快; 对于特定标签和日期范围; 对于特定的标签和日期; 对于具有日期范围的多个标签,依此类推。
示例:
让我们看看配置如下的引擎:
SQL ENGINE MergeTree() PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate) SETTINGS index_granularity=8192 |
查询sql:
SQL SELECT count() FROM table WHERE EventDate = toDate(now()) AND CounterID = 34 SELECT count() FROM table WHERE EventDate = toDate(now()) AND (CounterID = 34 OR CounterID = 42) SELECT count() FROM table WHERE ((EventDate >= toDate('2014-01-01') AND EventDate <= toDate('2014-01-31')) OR EventDate = toDate('2014-05-01')) AND CounterID IN (101500, 731962, 160656) AND (CounterID = 101500 OR EventDate != toDate('2014-05-01')) |
ClickHouse将使用主键索引来筛选合适数据,使用月分区键来确定在日期范围内的分区。
从上面的示例sql可以看出,复杂表达式也是可以支持索引的,clickhouse从表中扫描数据是有规则的,使用索引不会比全表scan慢
下面的查询sql示例,将不能使用SQL
SQL SELECT count() FROM table WHERE CounterID = 34 OR URL LIKE '%upyachka%' |
要在运行查询时**ClickHouse是否可以使用索引,请使用设置force_index_by_date和force_primary_key。
按月分区的关键是只允许读取包含适当范围日期的数据块。 在这种情况下,数据块可能包含许多日期(最多整月)的数据。 在块中,数据按主键排序,主键可能不包含日期作为第一列。 因此,使用仅具有未指定主键前缀的日期条件的查询将导致读取的数据多于单个日期。
对于并发
• 使用多版本控制方案,支持并发表访问。 换句话说,当同时读取和更新表时,从查询时当前的一组part读取数据。没有冗长的锁。插入不会妨碍读取操作。
• 从表中读取会自动并行化。
7. Distributed 引擎
分布式引擎本身不存储数据,但允许从服务器上执行分布式查询被写⼊入,做转发查询,作为中间件, 聚合后返回给⽤用户。
Clusters配置如下:
XML
|
其他详细见Clickhouse_Distributed_引擎一文
8. Dictionary 引擎
Clickhouse 支持从其他数据源引入数据作为字典使用,字典完全存储在内存中,不同的存储方式支持100W-1000W左右的数据,详细见Clickhouse_Dictionaries_xxx系列文章
9. Merge Engine
不同于MergeTree引擎,也不属于MergeTree家族引擎
Merge engine 本身也不存储数据
允许同时从任意数量的其他表读取数据,读取过程自动并行化。
不支持写入表
读取时,如果存在,则使用实际读取的表的索引。
使用Merge引擎的典型场景是使用大量TinyLog表,就像使用单个表一样。
Merge引擎接收参数:数据库名称和表的正则表达式。
SQL #hits库,以WatchLog 开头的表 Merge(hits, '^WatchLog') |
通过正则选择要合并的表时,不会选择Merge表本身,这是为了避免无限循环。注意,多个Merge表间,可能会出现无休止地尝试读取彼此的数据。
Merge表引擎示例:
SQL CREATE TABLE WatchLog_old(date Date, UserId Int64, EventType String, Cnt UInt64) ENGINE=MergeTree(date, (UserId, EventType), 8192); INSERT INTO WatchLog_old VALUES ('2018-01-01', 1, 'hit', 3); CREATE TABLE WatchLog_new(date Date, UserId Int64, EventType String, Cnt UInt64) ENGINE=MergeTree PARTITION BY date ORDER BY (UserId, EventType) SETTINGS index_granularity=8192; INSERT INTO WatchLog_new VALUES ('2018-01-02', 2, 'hit', 3); CREATE TABLE WatchLog as WatchLog_old ENGINE=Merge(currentDatabase(), '^WatchLog'); SELECT * FROM WatchLog *───────date─*─UserId─*─EventType─*─Cnt─* * 2018-01-01 * 1 * hit * 3 * *────────────*────────*───────────*─────* *───────date─*─UserId─*─EventType─*─Cnt─* * 2018-01-02 * 2 * hit * 3 * *────────────*────────*───────────*─────* |
10. 其他特殊引擎
10.1 File
数据源是特定格式(TabSeparated, Native, etc.)的文件
The data source is a file that stores data in one of the supported input formats (TabSeparated, Native, etc.).
应用场景举例:
• 数据从Clickhouse导出到文件
• 数据格式转换
• 通过export - 修改文件 - import 的方式来实现 Update
10.2 Null
写入Null表时,将忽略数据。从Null表读取时,响应为空。
但是,您可以在Null表上创建实例化视图。因此写入表中的数据将最终出现在视图中。
10.3 Set
始终在RAM中的数据集。它适用于IN运算符的右侧(请参见“IN运算符”部分)。
可以使用INSERT在表中插入数据。新元素将添加到数据集中,而重复项将被忽略。但是你不能从表中执行SELECT。检索数据的唯一方法是在IN运算符的右半部分使用它。
数据始终位于RAM中。对于INSERT,插入数据块也会写入磁盘上的表目录。启动服务器时,此数据将加载到RAM。换句话说,重新启动后,数据仍然存在。
对于非正常的服务器重启,磁盘上的数据块可能会丢失或损坏。 如果出现数据文件损坏,则需要手动删除包含损坏数据的文件。
10.4 Join
为JOIN 操作 预处理的数据结构,始终位于RAM中。
Apache Join(ANY|ALL, LEFT|INNER, k1[, k2, ...]) |
参数:
• ANY | ALL - 严格;
• LEFT | INNER - 类型。这些参数设置不带引号,并且必须与表将用于的JOIN匹配。
• k1,k2,…是USING子句中将要进行连接的关键列。
该表不能用于GLOBAL JOIN。
您可以使用INSERT向表中添加数据,类似于Set引擎。对于任何情况,将忽略重复键的数据。对于ALL,它将被计算在内。您无法直接从表中执行SELECT。检索数据的唯一方法是将其用作JOIN的“右手”表。
在磁盘上存储数据与Set引擎相同。
10.5 URL
类似于File引擎。只不过数据源是通过访问URL地址获取
示例:
1.创建url表引擎:
SQL CREATE TABLE url_engine_table (word String, value UInt64) ENGINE=URL('http://127.0.0.1:12345/', CSV) |
2.模拟http服务:
Python from http.server import BaseHTTPRequestHandler, HTTPServer class CSVHTTPServer(BaseHTTPRequestHandler): def do_GET(self): self.send_response(200) self.send_header('Content-type', 'text/csv') self.end_headers() self.wfile.write(bytes('Hello,1\nWorld,2\n', "utf-8")) if __name__ == "__main__": server_address = ('127.0.0.1', 12345) HTTPServer(server_address, CSVHTTPServer).serve_forever() |
Shell python3 server.py |
3.查询:
SQL SELECT * FROM url_engine_table |
• 读写并行
• 不支持:
○ ALTER and SELECT…SAMPLE operations.
○ Indexes
○ Replication
10.6 View 视图
用于实现视图(有关更多信息,请参阅CREATE VIEW查询)。它不存储数据,但仅存储指定的SELECT查询。从表中读取时,它会运行此查询(并从查询中删除所有不必要的列)。
执行查询时等同于:
SQL SELECT a, b, c FROM (SELECT ...) |
10.7 MaterializedView:物化视图
相对于 View:
• View视图是虚拟表,不存储数据
• MaterializedView存储相应Select查询转换的数据
Select查询转换可以包含DISTINCT, GROUP BY, ORDER BY, LIMIT…
注意的是:相应的转化是在每次插入数据块上执行的,例如Group By,只针对插入数据的单个数据包的数据聚合,数据不会进一步汇总。例外情况是使用执行数据聚合的ENGINE,例如SummingMergeTree。
ClickHouse 高性能背后的核心原理
ClickHouse 高性能 = 列式存储 + 向量化 + Code Generation(局部) + CPU底层指令集(SIMD)优化 + MPP架构
1.列式存储
由于ClickHouse的数据是按照列式存储,在分析性数据查询中,只需查询所关心的列,相比于行式存储,降低了I/O;此外列式存储更易于做数据压缩,也进一步降低I/O量,提升了效率;
2.SIMD 向量化执行
每列作为一个向量块并将列向量转换成行向量的时机推后,避免复杂查询的中对数据元祖构建的开销,充分利用cpu缓存提升性能。
SIMD 架构:
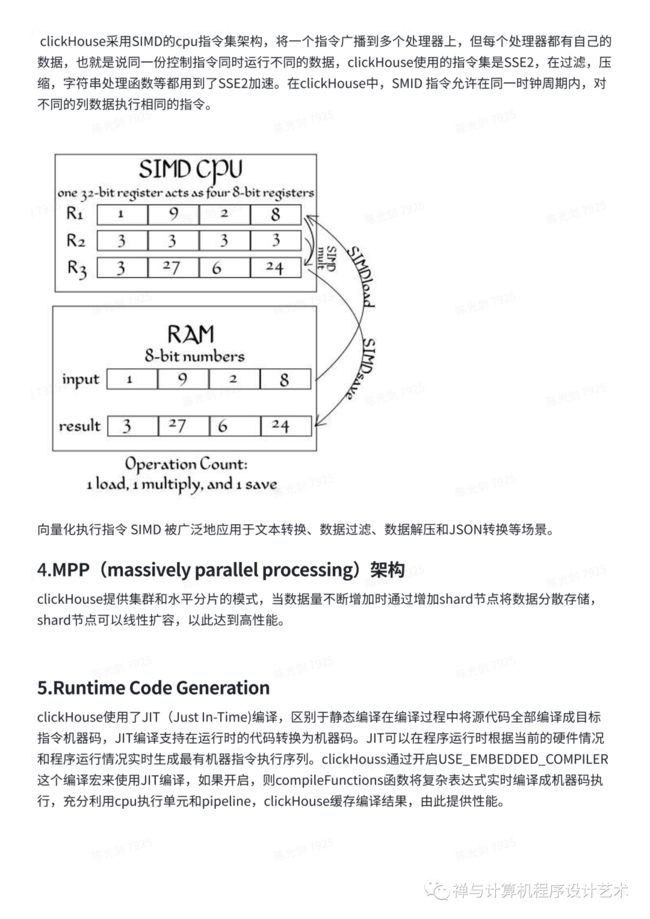
ClickHouse采用SIMD的cpu指令集架构,将一个指令广播到多个处理器上,但每个处理器都有自己的数据,也就是说同一份控制指令同时运行不同的数据,clickHouse使用的指令集是SSE2,在过滤,压缩,字符串处理函数等都用到了SSE2加速。在clickHouse中,SMID 指令允许在同一时钟周期内,对不同的列数据执行相同的指令。
向量化执行指令 SIMD 被广泛地应用于文本转换、数据过滤、数据解压和JSON转换等场景。
4.MPP(massively parallel processing)架构
ClickHouse提供集群和水平分片的模式,当数据量不断增加时通过增加shard节点将数据分散存储,shard节点可以线性扩容,以此达到高性能。
5.Runtime Code Generation
ClickHouse使用了JIT(Just In-Time)编译,区别于静态编译在编译过程中将源代码全部编译成目标指令机器码,JIT编译支持在运行时的代码转换为机器码。JIT可以在程序运行时根据当前的硬件情况和程序运行情况实时生成最有机器指令执行序列。clickHouss通过开启USE_EMBEDDED_COMPILER这个编译宏来使用JIT编译,如果开启,则compileFunctions函数将复杂表达式实时编译成机器码执行,充分利用cpu执行单元和pipeline,ClickHouse缓存编译结果,由此提供性能。
对于数据结构比较清晰的场景,会通过代码生成技术实现循环展开,以减少循环次数。
6. 字符串匹配算法
在字符串搜索方面,针对不同的场景,ClickHouse最终选择了这些算法:对于常量,使用Volnitsky算法;对于非常量,使用CPU的向量化执行SIMD,暴力优化;正则匹配使用re2和hyperscan 算法(hyperscan 基于有限自动机,背后使用了SIMD)。性能是算法选择的首要考量指标。
有限自动机(Finite Automata Machine)是计算机科学的重要基石,它在软件开发领域内通常被称作有限状态机(Finite State Machine),是一种应用非常广泛的软件设计模式。自动机 (Automata) 原来是模仿人和动物的行动而做成的机器人的意思。但是现已被抽象化为如下的机器: 时间是离散的(t=0,1,2……),在每一个时刻它处于所存在的有限个内部状态中的一个。对每一个时刻给予有限个输入中的一个。那么下一个时刻的内部状态就由现在的输入和现在的内部状态所决定。每个时刻的输出只由那个时刻的内部状态所决定。作为自动机的例子可以举出由McCulloch-pitts的神经模型组合所得到的神经网络模型、数字计算机等。
ClickHouse存储引擎
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
列式存储
与行存将每一行的数据连续存储不同,列存将每一列的数据连续存储。示例图如下:
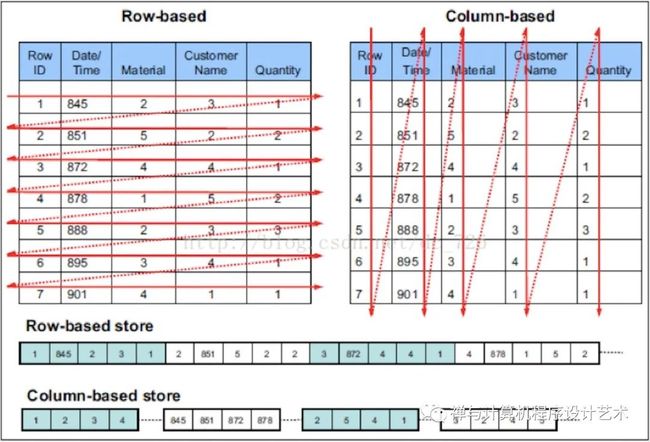
相比于行式存储,列式存储在分析场景下有着许多优良的特性。
1)如前所述,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
5)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
数据有序存储
ClickHouse支持在建表时,指定将数据按照某些列进行sort by。
排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block, 大幅减少需要IO的block数量。另外,连续IO也能够充分利用操作系统page cache的预取能力,减少page fault。
主键索引
ClickHouse支持主键索引,它将每列数据按照index granularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。
对于where条件中含有primary key的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
但是值得注意的是:ClickHouse的主键索引与MySQL等数据库不同,它并不用于去重,即便primary key相同的行,也可以同时存在于数据库中。要想实现去重效果,需要结合具体的表引擎ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree实现,我们会在未来的文章系列中再进行详细解读。
稀疏索引
ClickHouse支持对任意列创建任意数量的稀疏索引。其中被索引的value可以是任意的合法SQL Expression,并不仅仅局限于对column value本身进行索引。之所以叫稀疏索引,是因为它本质上是对一个完整index granularity(默认8192行)的统计信息,并不会具体记录每一行在文件中的位置。目前支持的稀疏索引类型包括:
minmax: 以index granularity为单位,存储指定表达式计算后的min、max值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少IO。
set(max_rows):以index granularity为单位,存储指定表达式的distinct value集合,用于快速判断等值查询是否命中该块,减少IO。
ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):将string进行ngram分词后,构建bloom filter,能够优化等值、like、in等查询条件。
tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed): 与ngrambf_v1类似,区别是不使用ngram进行分词,而是通过标点符号进行词语分割。
bloom_filter([false_positive]):对指定列构建bloom filter,用于加速等值、like、in等查询条件的执行。
数据Sharding
ClickHouse支持单机模式,也支持分布式集群模式。在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上。不同的分片策略在应对不同的SQL Pattern时,各有优势。ClickHouse提供了丰富的sharding策略,让业务可以根据实际需求选用。
1) random随机分片:写入数据会被随机分发到分布式集群中的某个节点上。
2) constant固定分片:写入数据会被分发到固定一个节点上。
3)column value分片:按照某一列的值进行hash分片。
4)自定义表达式分片:指定任意合法表达式,根据表达式被计算后的值进行hash分片。
数据分片,让ClickHouse可以充分利用整个集群的大规模并行计算能力,快速返回查询结果。
更重要的是,多样化的分片功能,为业务优化打开了想象空间。比如在hash sharding的情况下,JOIN计算能够避免数据shuffle,直接在本地进行local join; 支持自定义sharding,可以为不同业务和SQL Pattern定制最适合的分片策略;利用自定义sharding功能,通过设置合理的sharding expression可以解决分片间数据倾斜问题等。
另外,sharding机制使得ClickHouse可以横向线性拓展,构建大规模分布式集群,从而具备处理海量数据的能力。
数据Partitioning
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。
数据Partition在ClickHouse中主要有两方面应用:
在partition key上进行分区裁剪,只查询必要的数据。灵活的partition expression设置,使得可以根据SQL Pattern进行分区设置,最大化的贴合业务特点。
对partition进行TTL管理,淘汰过期的分区数据。
数据TTL
在分析场景中,数据的价值随着时间流逝而不断降低,多数业务出于成本考虑只会保留最近几个月的数据,ClickHouse通过TTL提供了数据生命周期管理的能力。
ClickHouse支持几种不同粒度的TTL:
1) 列级别TTL:当一列中的部分数据过期后,会被替换成默认值;当全列数据都过期后,会删除该列。
2)行级别TTL:当某一行过期后,会直接删除该行。
3)分区级别TTL:当分区过期后,会直接删除该分区。
高吞吐写入能力
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
有限支持delete、update
在分析场景中,删除、更新操作并不是核心需求。ClickHouse没有直接支持delete、update操作,而是变相支持了mutation操作,语法为alter table delete where filter_expr,alter table update col=val where filter_expr。
目前主要限制为删除、更新操作为异步操作,需要后台compation之后才能生效。
主备同步
ClickHouse通过主备复制提供了高可用能力,主备架构下支持无缝升级等运维操作。而且相比于其他系统它的实现有着自己的特色:
1)默认配置下,任何副本都处于active模式,可以对外提供查询服务;
2)可以任意配置副本个数,副本数量可以从0个到任意多个;
3)不同shard可以配置不提供副本个数,用于解决单个shard的查询热点问题;
ClickHouse计算引擎
ClickHouse在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与SIMD指令、代码生成等多种重要技术。
多核并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
分布式计算
除了优秀的单机并行处理能力,ClickHouse还提供了可线性拓展的分布式计算能力。ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。
在存在多副本的情况下,ClickHouse提供了多种query下发策略:
随机下发:在多个replica中随机选择一个;
最近hostname原则:选择与当前下发机器最相近的hostname节点,进行query下发。在特定的网络拓扑下,可以降低网络延时。而且能够确保query下发到固定的replica机器,充分利用系统cache。
in order:按照特定顺序逐个尝试下发,当前一个replica不可用时,顺延到下一个replica。
first or random:在In Order模式下,当第一个replica不可用时,所有workload都会积压到第二个Replica,导致负载不均衡。first or random解决了这个问题:当第一个replica不可用时,随机选择一个其他replica,从而保证其余replica间负载均衡。另外在跨region复制场景下,通过设置第一个replica为本region内的副本,可以显著降低网络延时。
向量化执行与SIMD
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
1)对每一行数据都要调用相应的函数,函数调用开销占比高;
2)存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重;
3)按行处理,无法利用高效的SIMD指令;
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
动态代码生成 Runtime Codegen
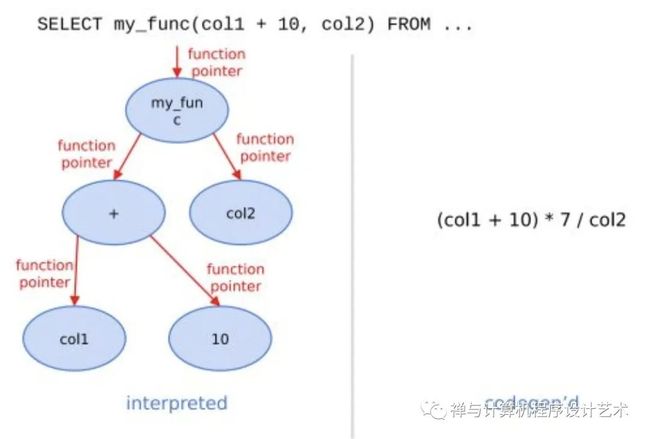
在经典的数据库实现中,通常对表达式计算采用火山模型,也即将查询转换成一个个operator,比如HashJoin、Scan、IndexScan、Aggregation等。为了连接不同算子,operator之间采用统一的接口,比如open/next/close。在每个算子内部都实现了父类的这些虚函数,在分析场景中单条SQL要处理数据通常高达数亿行,虚函数的调用开销不再可以忽略不计。另外,在每个算子内部都要考虑多种变量,比如列类型、列的size、列的个数等,存在着大量的if-else分支判断导致CPU分支预测失效。
ClickHouse实现了Expression级别的runtime codegen,动态地根据当前SQL直接生成代码,然后编译执行。如下图例子所示,对于Expression直接生成代码,不仅消除了大量的虚函数调用(即图中多个function pointer的调用),而且由于在运行时表达式的参数类型、个数等都是已知的,也消除了不必要的if-else分支判断。
近似计算
近似计算以损失一定结果精度为代价,极大地提升查询性能。在海量数据处理中,近似计算价值更加明显。
ClickHouse实现了多种近似计算功能:
近似估算distinct values、中位数,分位数等多种聚合函数;
建表DDL支持SAMPLE BY子句,支持对于数据进行抽样处理;
复杂数据类型支持
ClickHouse还提供了array、json、tuple、set等复合数据类型,支持业务schema的灵活变更。
结语
近年来ClickHouse发展趋势迅猛,社区和大厂都纷纷跟进使用。本文尝试从OLAP场景的需求出发,介绍了ClickHouse存储层、计算层的主要设计。ClickHouse实现了大多数当前主流的数据分析技术,具有明显的技术优势:
提供了极致的查询性能:开源公开benchmark显示比传统方法快1001000倍,提供50MB200MB/s的高吞吐实时导入能力)
以极低的成本存储海量数据: 借助于精心设计的列存、高效的数据压缩算法,提供高达10倍的压缩比,大幅提升单机数据存储和计算能力,大幅降低使用成本,是构建海量数据仓库的绝佳方案。
简单灵活又不失强大:提供完善SQL支持,上手十分简单;提供json、map、array等灵活数据类型适配业务快速变化;同时支持近似计算、概率数据结构等应对海量数据处理。
相比于开源社区的其他几项分析型技术,如Druid、Presto、Impala、Kylin、ElasticSearch等,ClickHouse更是一整套完善的解决方案,它自包含了存储和计算能力(无需额外依赖其他存储组件),完全自主实现了高可用,而且支持完整的SQL语法包括JOIN等,技术上有着明显优势。
相比于hadoop体系,以数据库的方式来做大数据处理更加简单易用,学习成本低且灵活度高。当前社区仍旧在迅猛发展中,相信后续会有越来越多好用的功能出现。
参考:https://zhuanlan.zhihu.com/p/98135840
ClickHouse 快速开始
安装 ClickHouse
Mac OS
Shell wget 'https://builds.clickhouse.com/master/macos/clickhouse' chmod a+x ./clickhouse ./clickhouse |
Ubuntu
Shell sudo apt-get install apt-transport-https ca-certificates dirmngr sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E0C56BD4 echo "deb https://repo.clickhouse.com/deb/stable/ main/" | sudo tee \ /etc/apt/sources.list.d/clickhouse.list sudo apt-get update sudo apt-get install -y clickhouse-server clickhouse-client sudo service clickhouse-server start clickhouse-client |
参考:https://clickhouse.com/#quick-start
命令行参考
Shell clickhouse local [args] clickhouse client [args] clickhouse benchmark [args] clickhouse server [args] clickhouse extract-from-config [args] clickhouse compressor [args] clickhouse format [args] clickhouse copier [args] clickhouse obfuscator [args] clickhouse git-import [args] clickhouse keeper [args] clickhouse keeper-converter [args] clickhouse install [args] clickhouse start [args] clickhouse stop [args] clickhouse status [args] clickhouse restart [args] clickhouse static-files-disk-uploader [args] clickhouse hash-binary [args] |
启动 ClickHouse Server
Shell $./clickhouse server |
Server 默认的端口号是:8123
Application: Listening for http://127.0.0.1:8123
$./clickhouse server
Processing configuration file 'config.xml'.
There is no file 'config.xml', will use embedded config.
Logging trace to console
2021.11.23 16:46:27.329801 [ 71536 ] {}
...
客户端连接 ClickHouse
Shell ./clickhouse client ClickHouse client version 21.12.1.8808 (official build). Connecting to localhost:9000 as user default. Connected to ClickHouse server version 21.12.1 revision 54450. |
Quick tips for clickhouse-client Interactive mode:
clickhouse-client
clickhouse-client --host=... --port=... --user=... --password=...
Enable multiline queries:
clickhouse-client -m
clickhouse-client --multiline
Run queries in batch-mode:
clickhouse-client --query='SELECT 1'echo'SELECT 1'|clickhouse-clientclickhouse-client<<<'SELECT 1'
Insert data from a file in specified format:
clickhouse-client --query='INSERT INTO table VALUES'< data.txt
clickhouse-client --query='INSERT INTO table FORMAT TabSeparated'< data.tsv
创建数据库
ClickHouse支持的表引擎官:Ordinary/Dictionary/Memory/Mysql/Lazy
创建数据库指定数据库引擎语法:
SQL create database xxxx engine = 数据库引擎 |
示例:
1.创建一个默认引擎的 clickhouse 数据库:
SQL create database mydb engine=Ordinary comment 'mydb'; |
默认引擎Ordinary, 如果不指定数据库引擎创建的就是 Ordinary 数据库.
2. 创建 clickhouse 数据库, 使用 Mysql 引擎:
SQL create database mysqlDB engine=MySQL('xx:3306','database','username','password'); |
3. 创建 Lazy 引擎的数据库:
SQL create database testlazy engine=Lazy(expiration_time_in_seconds); |
上次访问之后 expiration_time_in_seconds 秒之前,表放内存.
该库引擎下只能创建 *Log表引擎
查询当前 server 实例所有的 databases:
SQL SELECT * FROM system.databases; |
建表
SQL create table test ( dim_id String, tag_code String, tag_option_code String, tag_option_value String, object_ids Array(String), p_date DateTime ) engine =MergeTree partition by p_date order by (dim_id,tag_code,tag_option_code,p_date) ; |
插入数据
SQL INSERT INTO `mydb`.`test` (`dim_id`, `tag_code`, `tag_option_code`, `tag_option_value`, `object_ids`, `p_date`) VALUES ('1', 't1', 'f1', 'a', null, '2021-11-23 17:19:29') |
查询数据
select * from test;
本章小结
参考资料
https://reberhardt.com/cs110/summer-2018/






























INSERT INTO `mydb`.`test` (`dim_id`, `tag_code`, `tag_option_code`, `tag_option_value`, `object_ids`, `p_date`) VALUES ('1', 't1', 'f1', 'a', null, '2021-11-23 17:19:29')查询数据
select * from test;

本章小结
参考资料
https://reberhardt.com/cs110/summer-2018/