深入浅出pytorch笔记——第一章
文章目录
- 第一章
-
- 1.1pytorch的安装
-
- 1.1.1虚拟环境
-
- 创建虚拟环境:
- 删除虚拟环境:
- pip换源
- conda换源
- 1.1.2cuda
-
- 概念
- 显卡与cuda
- pytorch与cuda
第一章
1.1pytorch的安装
1.1.1虚拟环境
创建虚拟环境:
conda create -n env_name python==version,3.6-3.8之间
删除虚拟环境:
conda remove -n env_name --all
pip换源
- 源
- 阿里云
http://mirrors.aliyun.com/pypi/simple/ - 清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/ - 中国科学技术大学
http://pypi.mirrors.ustc.edu.cn/simple/ - 华中科技大学
http://pypi.hustunique.com/
- 阿里云
- linux
Linux下的换源,我们首先需要在用户目录下新建文件夹.pip,并且在文件夹内新建文件pip.conf,具体命令如下:
然后在pip.conf添加下方的内容:cd ~ #用户目录 mkdir .pip/ #新建文件夹.pip vi pip.conf #在文件夹内新建文件pip.conf[global] index-url = http://pypi.douban.com/simple [install] use-mirrors =true mirrors =http://pypi.douban.com/simple/ trusted-host =pypi.douban.com - Windows
文件管理器文件路径地址栏敲:%APPDATA%回车,快速进入 C:\Users\电脑用户\AppData\Roaming 文件夹中。新建 pip 文件夹并在文件夹中新建 pip.ini 配置文件。我们需要在pip.ini 配置文件内容,我们可以选择使用记事本打开,输入以下内容,并按下ctrl+s保存,在这里我们使用的是豆瓣源为例子:[global] index-url = http://pypi.douban.com/simple [install] use-mirrors =true mirrors = http://pypi.douban.com/simple/ trusted-host = pypi.douban.com
conda换源
- linux
在Linux系统下,我们还是需要修改.condarc来进行换源
在vim下,我们需要输入i进入编辑模式,将下方内容粘贴进去,按ESC退出编辑模式,输入:wq保存并退出cd ~ vi .condarc
我们可以通过ssl_verify: true show_channel_urls: true channels: - http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64/ - http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/conda config --show default_channels检查下是否换源成功
同时,我们仍然需要conda clean -i清除索引缓存,保证用的是镜像站提供的索引 - windows
TUNA 提供了 Anaconda 仓库与第三方源的镜像,各系统都可以通过修改用户目录下的.condarc 文件。Windows 用户无法直接创建名为 .condarc 的文件,可先执行conda config --set show_channel_urls yes生成该文件之后再修改
完成这一步后,我们需要修改C:\Users\User_name.condarc这个文件,打开后将文件里原始内容删除,将下面的内容复制进去并保存
这一步完成后,我们需要打开Anaconda Prompt 运行ssl_verify: true show_channel_urls: true channels: - http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64/ - http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/conda clean -i清除索引缓存,保证用的是镜像站提供的索引。
1.1.2cuda
概念
原文链接
- 显卡
- 显卡: 简单理解这个就是我们前面说的GPU,尤其指NVIDIA公司生产的GPU系列,因为后面介绍的cuda,cudnn都是NVIDIA公司针对自身的GPU独家设计的
- 显卡驱动:很明显就是字面意思,通常指NVIDIA Driver,其实它就是一个驱动软件,而前面的显卡就是硬件
- gpu架构:Tesla、Fermi、Kepler、Maxwell、Pascal。gpu架构指的是硬件的设计方式,例如流处理器簇中有多少个core、是否有L1 or L2缓存、是否有双精度计算单元等等。每一代的架构是一种思想,如何去更好完成并行的思想
- 芯片型号:GT200、GK210、GM104、GF104等。芯片就是对上述gpu架构思想的实现,例如芯片型号GT200中第二个字母代表是哪一代架构,有时会有100和200代的芯片,它们基本设计思路是跟这一代的架构一致,只是在细节上做了一些改变,例如GK210比GK110的寄存器就多一倍。有时候一张显卡里面可能有两张芯片,Tesla k80用了两块GK210芯片。这里第一代的gpu架构的命名也是Tesla,但现在基本已经没有这种设计的卡了,下文如果提到了会用Tesla架构和Tesla系列来进行区分
- 显卡系列:GeForce、Quadro、Tesla。GeFore用于家庭娱乐,Quadro用于工作站,而Tesla系列用于服务器
- GeForce显卡型号:G/GS、GT、GTS、GTX。是不同的硬件定制,越往后性能越好,时钟频率越高显存越大,即G/GS
- cuda:CUDA英文全称是Compute Unified Device Architecture,是显卡厂商NVIDIA推出的运算平台。CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。按照官方的说法是,CUDA是一个并行计算平台和编程模型,能够使得使用GPU进行通用计算变得简单和优雅
- cudnn:这个其实就是一个专门为深度学习计算设计的软件库,里面提供了很多专门的计算函数,如卷积等。从上图也可以看到,还有很多其他的软件库和中间件,包括实现c++ STL的thrust、实现gpu版本blas的cublas、实现快速傅里叶变换的cuFFT、实现稀疏矩阵运算操作的cuSparse以及实现深度学习网络加速的cuDNN等等,具体细节可参阅GPU-Accelerated Libraries
- CUDA Toolkit由以下组件组成:
- Compiler: CUDA-C和CUDA-C++编译器NVCC位于**bin/**目录中。它建立在NVVM优化器之上,而NVVM优化器本身构建在LLVM编译器基础结构之上。希望开发人员可以使用nvm/目录下的Compiler SDK来直接针对NVVM进行开发。
- Tools: 提供一些像profiler,debuggers等工具,这些工具可以从**bin/**目录中获取
- Libraries: 下面列出的部分科学库和实用程序库可以在lib/目录中使用(Windows上的DLL位于bin/中),它们的接口在include/目录中可获取。
- cudart: CUDA Runtime
- cudadevrt: CUDA device runtime
- cupti: CUDA profiling tools interface
- nvml: NVIDIA management library
- nvrtc: CUDA runtime compilation
- cublas: BLAS (Basic Linear Algebra Subprograms,基础线性代数程序集)
- cublas_device: BLAS kernel interface
- CUDA Samples: 演示如何使用各种CUDA和library API的代码示例。可在Linux和Mac上的samples/目录中获得,Windows上的路径是C:\ProgramData\NVIDIA Corporation\CUDA Samples中。在Linux和Mac上,samples/目录是只读的,如果要对它们进行修改,则必须将这些示例复制到另一个位置
- CUDA Driver: 运行CUDA应用程序需要系统至少有一个具有CUDA功能的GPU和与CUDA工具包兼容的驱动程序。每个版本的CUDA工具包都对应一个最低版本的CUDA Driver,也就是说如果你安装的CUDA Driver版本比官方推荐的还低,那么很可能会无法正常运行。CUDA Driver是向后兼容的,这意味着根据CUDA的特定版本编译的应用程序将继续在后续发布的Driver上也能继续工作**(通过
nvidia-smi查看的driver version越高越好)**。通常为了方便,在安装CUDA Toolkit的时候会默认安装CUDA Driver。在开发阶段可以选择默认安装Driver,但是对于像Tesla GPU这样的商用情况时,建议在官方安装最新版本的Driver
- nvcc&nvdia-smi
- nvidia-smi
全称是NVIDIA System Management Interface ,它是一个基于前面介绍过的NVIDIA Management Library(NVML)构建的命令行实用工具,旨在帮助管理和监控NVIDIA GPU设备。 - nvcc
nvcc其实就是CUDA的编译器,可以从CUDA Toolkit的**/bin**目录中获取,类似于gcc就是c语言的编译器。
由于程序是要经过编译器编程成可执行的二进制文件,而cuda程序有两种代码,一种是运行在cpu上的host代码,一种是运行在gpu上的device代码,所以nvcc编译器要保证两部分代码能够编译成二进制文件在不同的机器上执行

- 二者cuda版本为何不同(nvidia-smi>nvcc -V)
- CUDA有两个主要的API:driver API和runtime API。这两个API都有对应的CUDA版本。
- 用于支持driver API的必要文件(如libcuda.so)是由GPU driver installer安装的。nvidia-smi就属于这一类API。
- 用于支持runtime API的必要文件(如libcudart.so以及nvcc)是由CUDA Toolkit installer安装的。(CUDA Toolkit Installer有时可能会集成了GPU driver Installer)。nvcc是与CUDA Toolkit一起安装的CUDA compiler-driver tool,它只知道它自身构建时的CUDA runtime版本。它不知道安装了什么版本的GPU driver,甚至不知道是否安装了GPU driver。
- 综上,如果driver API和runtime API的CUDA版本不一致可能是因为你使用的是单独的GPU driver installer,而不是CUDA Toolkit installer里的GPU driver installer。二者是互斥的,开发过程中,你只能选择其中一种API。runtime是更高级的封装,开发人员用起来更方便,而driver API更接近底层,速度可能会更快
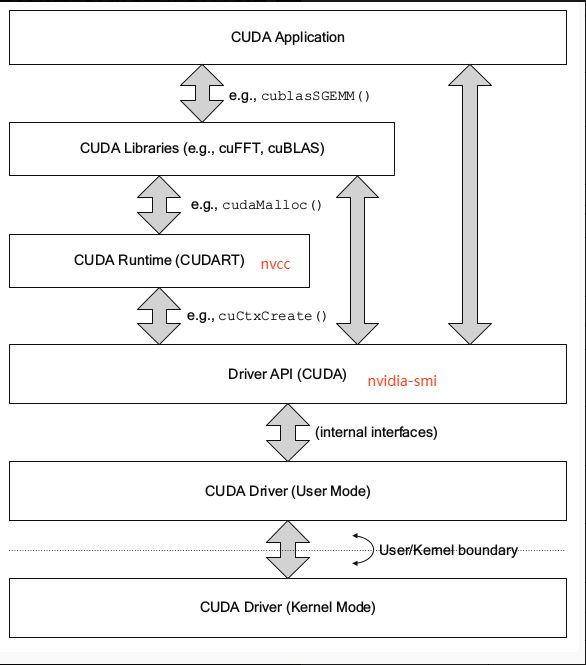
- CUDA有两个主要的API:driver API和runtime API。这两个API都有对应的CUDA版本。
- nvidia-smi
显卡与cuda
- cuda驱动版本
输入nvidia-smi查看自己是否有NVIDIA的独立显卡及其型号.查看CUDA驱动版本
一个driver version与cuda version,此cuda version是支持的最高cuda运行版本 - cuda运行版本(包含工具包)
输入nvcc -V查看cuda运行版本 orprint(torch.version.cuda)
linux还可以:cat /usr/local/cuda/version.txt
conda list或者pip list查看cuda toolkit和cudnn程序包版本 - 关系
- CUDA工具包cuda toolkit和其最低可兼容驱动版本driver version的表格,Table 3. CUDA Toolkit and Corresponding Driver Versions
即driver要高,nvidia-smi的cuda version>=nvcc -V的cuda运行版本

- CUDA工具包cuda toolkit和其最低可兼容驱动版本driver version的表格,Table 3. CUDA Toolkit and Corresponding Driver Versions
- 问题
-
driver低,cuda运行高:
nvidia-smi的cuda version<nvcc -V查看cuda运行版本时,报错CUDA driver version is insufficient for CUDA runtime version,即对于我们的CUDA运行版本来说,驱动版本太低了!
解决:- 升级驱动
- 降级CUDA工具包,即降级cuda运行版本(但不能太低,因为cuda支持算力要高于显卡,见下方)
先卸载python中安装cudatoolkit和cudnn程序包:pip uninstall cudnn;pip uninstall cudatoolkit
然后安装对应版本的cudatoolkit和cudnn程序包:pip install cudatoolkit=9.0;pip install cudnn=9.0
-
cuda运行版本与显卡算力问题:报错原文
- cuda运行版本过低,cuda支持算力低于显卡
torch/cuda/__init__.py:104: UserWarning: NVIDIA GeForce RTX 3080 Ti with CUDA capability sm_86 is not compatible with the current PyTorch installation. The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 compute_37. If you want to use the NVIDIA GeForce RTX 3080 Ti GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/翻译一下就是:NVIDIA GeForce RTX 3080 Ti with CUDA capability sm_86意思是RTX 3080 Ti的算力是8.6,但是当前的PyTorch依赖的CUDA版本支持的算力只有3.7、5.0、6.0、6.1、7.0、7.5及3.7以下。也就是说显卡算力和pytorch版本不匹配
如果pytorch下载是按照cuda运行版本下载的话:上面表面上是说PyTorch,实际上是PyTorch依赖的CUDA版本的问题- cuda运行版本高,cuda支持算力高于显卡(不报错)
A CUDA application binary (with one or more GPU kernels) can contain the compiled GPU code in two forms, binary cubin objects and forward-compatible PTX assembly for each kernel. Both cubin and PTX are generated for a certain target compute capability. A cubin generated for a certain compute capability is supported to run on any GPU with the same major revision and same or higher minor revision of compute capability. For example, a cubin generated for compute capability 7.0 is supported to run on a GPU with compute capability 7.5, however a cubin generated for compute capability 7.5 is not supported to run on a GPU with compute capability 7.0, and a cubin generated with compute capability 7.x is not supported to run on a GPU with compute capability 8.x算力7.0的显卡可以在支持最高算力7.5的CUDA版本下运行,但是算力7.5的显卡不可以在支持最高算力7.0的CUDA版本下运行
- 解决(那我怎么知道nvidia显卡该用什么CUDA版本呢)
- 直接去官网下载最新版本的cuda,肯定就可以让所有显卡都可以用(上述不报错的情况, cuda支持算力高于显卡)。缺点:pytorch不一定支持最新版本的CUDA,如官网下最新pytorch仅支持11.1的cuda,则装11.2的cuda运行此pytorch会报错(即pytorch要与cuda兼容,见下述);cuda运行版本过高,还会导致driver低(见上述)
- 已知:CUDA10.x最高支持算力7.x;CUDA11.0最高支持算力8.0(注:这感觉应该是8.x),即8.x显卡使用的cuda版本应该大于等于11.0。
查阅显卡算力
如果你是cuda版本太低的话,加装一个高版本cuda就可以了(多版本cuda安装管理可以参考linux和windows)
-
pytorch与cuda
- 查看pytorch版本:
print(torch.__version__) - 查看pytorch和cuda运行版本是否匹配:
print(torch.cuda.is_available())返回True说明版本是匹配的,且pytorch安装成功 - 关系:pytorch与cuda要兼容
- 问题
-
print(torch.cuda.is_available())返回False说明版本不匹配,解决pytorch和cuda版本不匹配问题:到pytorch官网下载cuda运行版本对应的pytorch- cuda运行版本过低,pytorch运行版本过高:高版本的pytorch不能向下兼容低版本cuda(1.10太高了)
测试显卡算力与当前pytorch是否匹配,可以进入python命令行,依次输入如下两行代码:
import torch torch.zeros(1).cuda()如果不匹配,则发生如下报错
torch/cuda/__init__.py:104: UserWarning: NVIDIA GeForce RTX 3080 Ti with CUDA capability sm_86 is not compatible with the current PyTorch installation. The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 compute_37. If you want to use the NVIDIA GeForce RTX 3080 Ti GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/见上述报错,实际上是cuda运行版本与算力问题
- cuda运行版本过高,pytorch运行版本过低:
- 装低版本pytorch时cuda将不可用,会默认使用cpu进行计算(1.7太低了,1.7pytorch+11.0cuda不可,即不带gpu加速也就是不带后缀(+cu11));
- pytorch不一定支持最新版本的cuda,如官网下最新pytorch仅支持11.1的cuda,则装11.2的cuda运行此pytorch会报错(上述)
- 总结:下载1.8版本的pytorch,且对应相应的cuda运行版本。只能在官网下在,国内清华源不全
- cuda运行版本过低,pytorch运行版本过高:高版本的pytorch不能向下兼容低版本cuda(1.10太高了)
-
python,torch,torchvision的关系[原文](pytorch/vision: Datasets, Transforms and Models specific to Computer Vision (github.com))

-
STUffT&夏日回音