HAProxy + Keepalived 配置架构解析
离职后的交接是一件有意思的事,被交接的时候有多头大,交接给别人的时候就有多爽,哈哈哈哈哈,不多说了,接手工作的同事要来打我了(手动狗头保命.jpg)。
不过话说回来,交接工作本身真的是学习和提升的好机会,在之前一次次接手同事工作的时候,自己也得到了快速的成长,虽然痛苦,但也学到了很多之前没接触过的技能;而当自己辞职把工作交接给同事的时候,也是回顾总结、反省自我和共同提升的好机会。
回想工作的 5 年里,一个人前前后后接下了系统的后端代码、架构、部署,从对后端一知半解到能够独立设计开发功能,到经验慢慢丰富可以给别人建议,再到掌握底层原理,一路走来,也感谢自己的坚持和不放弃。
目前对系统中使用的架构和部署方面还不够熟练,正好借着整理这篇博客的机会好好学习下 HAProxy + Keepalived 架构,也希望能给小伙伴们带来一些收获。
为什么选择 HAProxy
首先,先来了解一下 HAProxy 是什么。
HAProxy 是一个使用 C 语言编写的自由开源软件,提供了高性能的负载均衡能力,是一个基于 TCP 和 HTTP 的反向代理服务器。
它支持双机热备,支持虚拟主机,配置简单,拥有非常不错的服务器健康检查功能。当其代理的后端服务器出现故障,HAProxy会自动将该服务器摘除,故障恢复后再自动将该服务器加入。
那么我们的系统又为什么偏偏要用 HAProxy?Nginx 也可以用于负载均衡,难道它不香么?
这就要结合具体的应用场景来说了,系统当年的场景和开发要求如下:
- 高可用。系统的业务是 7 * 24 小时运行的,几分钟的服务不可用就需要提供故障报告并杀掉一个或多个程序员祭天的那种;
- 高并发。虽然实际场景下的并发程度没那么高,但是甲方爸爸要求提供高并发的架构方案,不然不打钱;
- 安全可靠。稳定!稳定!稳定!重要的事情说三遍;
而 HAProxy 的特点如下:
- 相较于 Nginx,HAProxy 更专注于反向代理,它可以支持更多的选项,更精细的控制,更多的健康状态检测机制和负载均衡算法。
- 它尤其适合于要求高可用性的高并发环境,本身的运行模式也使得它可以很简单安全地整合进当前的架构中, 同时可以保护 web 服务器不被暴露到网络上。
- 此外,它拥有功能强大的后端服务器的状态监控 web 页面,可以实时了解设备的运行状态,还可实现设备上下线等简单操作,这个是 Nginx 不具备的。
这么一看,HAProxy 略胜一筹,猜测这大概是当年选择它的原因吧。
架构解析
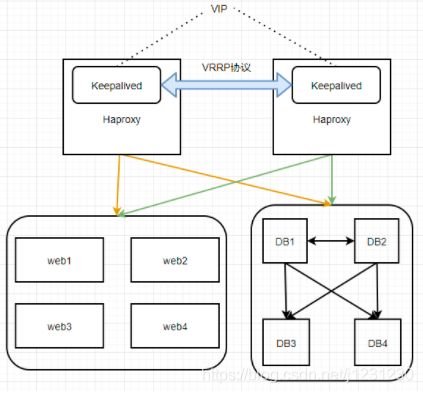
如上图所示,系统中使用了 虚拟 IP + Haproxy + Keepalived + 服务节点 的服务方式。
我们的系统对高可用的要求是非常高的,如果有一台 Haproxy 无法正常提供服务,那系统访问就会出现问题。所以我们需要对 Haproxy 进行实时检测和故障转移处理,这时,Keepalived 就派上用场了。
这个 Keepalived 是什么?具体是怎么工作的?
Keepalived 软件起初是专为 LVS 负载均衡软件设计的,用来管理并监控 LVS 集群系统中各个服务节点的状态,是一种有效的高可用解决方案。
一般来说,会有 2 台服务器运行 Keepalived,一台为主服务器,一台为备份服务器,对外表现为一个虚拟 IP。
Keepalived 一旦检测到 Haproxy 进程停止,会尝试重启 Haproxy,如果重启失败,Keepalived 就会自杀,另一台 Keepalived 节点检测到对方消失,则会自动接管服务,此时的虚拟 IP 就漂移至另一台 Keepalived 节点上,由另一台 Haproxy 分发请求。
那 Keepalived 之间又是如何实现相互检测的呢?
Keepalived 服务正常工作时,主节点会以多播的方式不断地向备节点发送心跳消息,告诉备节点自己还活着,当主节点发生故障无法发送心跳消息时,备节点无法继续检测到来自主节点的心跳,就会调用自身的接管程序,接管主节点的 IP 资源及服务。
而当主节点恢复时,备节点又会释放主节点故障时自身接管的 IP 资源及服务,恢复到原来的备用角色。
配置部署
Haproxy 的配置部署
1. 安装
yum install -y haproxy rsyslog2. 编辑配置文件
vim /etc/haproxy/haproxy.cfg配置文件内容如下:
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 40000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
log global
option dontlognull
option http-server-close
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout http-keep-alive 10s
timeout check 10s
maxconn 30000
#---------------------------------------------------------------------
# frontend
#---------------------------------------------------------------------
frontend main *:9007
mode http
option httplog
option forwardfor header x-real-ip
timeout client 10m
timeout client-fin 10m
default_backend main-servers
frontend db *:3306
mode tcp
option tcplog
timeout client 470m
timeout client-fin 470m
default_backend db-servers
frontend db-slave *:3307
mode tcp
option tcplog
timeout client 470m
timeout client-fin 470m
default_backend db-slave-servers
backend main-servers
mode http
balance roundrobin
timeout server 10m
server main-ip1:9000 ip1:9000 check
server main-ip2:9000 ip2:9000 check
server main-ip3:9000 ip3:9000 check
server main-ip4:9000 ip4:9000 check
# 两台主DB
backend db-servers
mode tcp
balance roundrobin
option tcplog
timeout server 470m
timeout server-fin 470m
timeout tunnel 470m
server db-ip5:3306 ip5:3306 maxconn 16000 check
server db-ip6:3306 ip6:3306 maxconn 16000 check backup
# 两台从DB
backend db-slave-servers
mode tcp
balance roundrobin
option tcplog
timeout server 470m
timeout server-fin 470m
timeout tunnel 470m
server db-ip7:3306 ip7:3306 maxconn 16000 check
server db-ip8:3306 ip8:3306 maxconn 16000 check
listen admin_stats
stats enable
bind *:8000 #监听的ip端口号
mode http #开关
option httplog
timeout client 1m
log global
maxconn 10
stats refresh 10s #统计页面自动刷新时间
stats uri /haproxy/status #访问的uri ip:8000/haproxy/status
stats realm haproxy
stats auth xy:superHelloKitty #认证用户名和密码
stats hide-version #隐藏HAProxy的版本号
stats admin if TRUE #管理界面,如果认证成功了,可通过webui管理节点
3.日志配置
在 /etc/rsyslog.conf 文件追加以下内容:
local2.* /var/log/haproxy.log并将以下配置项的注释去掉:
$ModLoad imudp
$UDPServerRun 514新建 /etc/rsyslog.d/haproxy.conf 文件,输入以下内容:
local2.* /var/log/haproxy.log4.启动
service rsyslog start
service haproxy startKeepalived 的配置部署
1.安装
yum install -y ipvsadm keepalived rsyslog2.修改配置文件 /etc/keepalived/keepalived.conf
主服务的配置文件:
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_haproxy {
script "/etc/keepalived/chk_haproxy.sh" #服务探测,返回0说明服务是正常的
interval 1 #每隔1秒探测一次
weight 2 #haproxy上线,权重加2;下线,权重减2
fall 1
rise 1
}
vrrp_instance VI_1 { #双主实例1
state MASTER #主
interface eth0 #网卡
virtual_router_id 88 #实例1的VRID为88
priority 100 #主的优先级为100,从的优先级为99
advert_int 1 #检查时间为1s
authentication {
auth_type PASS
auth_pass passwd@#$?1234@
}
virtual_ipaddress {
10.136.48.65 #虚拟IP
}
track_script { #脚本追踪
chk_haproxy
}
}从服务的配置文件:
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_haproxy {
script "/etc/keepalived/chk_haproxy.sh" #服务探测,返回0说明服务是正常的
interval 1 #每隔1秒探测一次
weight 2 #haproxy上线,权重加2;下线,权重减2
fall 1
rise 1
}
vrrp_instance VI_1 { #双主实例1
state BACKUP #从
interface eth0 #网卡
virtual_router_id 88 #实例1的VRID为88
priority 99 #主的优先级为100,从的优先级为99
advert_int 1 #检查时间为1s
authentication {
auth_type PASS
auth_pass passwd@#$?1234@
}
virtual_ipaddress {
10.136.48.65 #虚拟IP
}
track_script { #脚本追踪
chk_haproxy
}
}Haproxy 进程状态检查脚本 chk_haproxy.sh:
#!/bin/bash
A=`ps -C haproxy --no-header |wc -l`
if [ $A -eq 0 ];then
service haproxy start
sleep 3
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
service keepalived stop
exit 1
fi
fi
exit 0需要把检查脚本 chk_haproxy.sh 上传到每台机器的 /etc/keepalived 目录下。
3. 启动
service keepalived start