【OpenCV图像处理13】图像拼接
文章目录
- 十三、图像拼接
-
- 1、基础知识
- 2、读取图像,设置相同尺寸
- 3、找特征点、描述子,计算单应性矩阵
- 4、根据单应性矩阵对图像进行变换,然后再平移
- 5、拼接并输出最终结果(完整代码)
十三、图像拼接
1、基础知识
原始图像:

结果图像:

图像拼接的步骤:
- 读取图像并重置尺寸
- 根据特征点和描述子,得到单应性矩阵
- 图像变换
- 图像拼接并输出图像
坐标系:
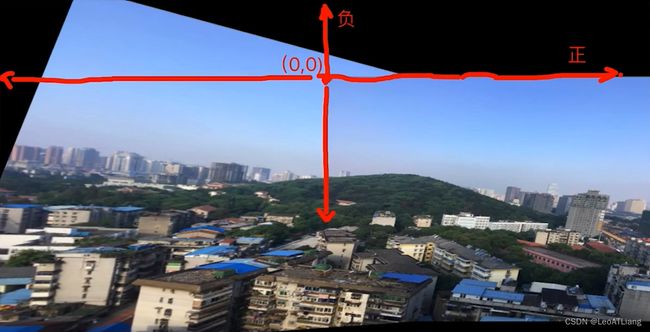
单应性矩阵变换:
放大窗口:

图像平移:
2、读取图像,设置相同尺寸
# 第一步,读取文件,将图片设置成一样大小,640*480(跟实际图像最接近的尺寸)
img1 = cv2.imread('../resource/hill_left.png')
img2 = cv2.imread('../resource/hill_right.png')
img1 = cv2.resize(img1, (640, 480))
img2 = cv2.resize(img2, (640, 480))
cv2.imshow('Hill', np.hstack((img1, img2)))
cv2.waitKey(0)
cv2.destroyAllWindows()

3、找特征点、描述子,计算单应性矩阵
# 计算单应性矩阵的方法
def get_homo(img1, img2):
# 1.创建特征转换对象
sift = cv2.xfeatures2d.SIFT_create()
# 2.通过特征转换对象获得特征点和描述子
k1, d1 = sift.detectAndCompute(img1, None) # k1为特征点,d1为描述子
k2, d2 = sift.detectAndCompute(img2, None)
# 3.创建特征匹配
# 4.进行特征匹配
# 5.过滤特征,找出有效的特征匹配点
bf = cv2.BFMatcher() # 采用暴力特征匹配
matches = bf.knnMatch(d1, d2, k=2) # 匹配特征点
verify_ratio = 0.8 # 过滤
verify_matches = []
for m1, m2 in matches: # m1,m2之间的距离越小越好,小于0.8认为有效,大于0.8无效
if m1.distance < verify_ratio * m2.distance:
verify_matches.append(m1)
# 最小匹配数
min_matches = 8
if len(verify_matches) > min_matches:
img1_pts = []
img2_pts = []
for m in verify_matches:
img1_pts.append(k1[m.queryIdx].pt) # 图像1的坐标特征点
img2_pts.append(k2[m.trainIdx].pt) # 图像2的坐标特征点
# [(x1, y1), (x2, y2), ...]
# [[x1, y1], [x2, y2], ...]
img1_pts = np.float32(img1_pts).reshape(-1, 1, 2) # 适应findHomography的格式
img2_pts = np.float32(img2_pts).reshape(-1, 1, 2)
H, mask = cv2.findHomography(img1_pts, img2_pts, cv2.RANSAC, 5.0) # 获取单应性矩阵
return H
else:
print('error: Not enough matches!')
exit()
# 第二步,找特征点,计算描述子,计算单应性矩阵
H = get_homo(img1, img2) # 获得单应性矩阵
4、根据单应性矩阵对图像进行变换,然后再平移
def stitch_image(img1, img2, H):
# 1.获得每张图片的4个角点
# 2.对图片进行变换,通过单应性矩阵使图像进行旋转,然后进行平移
# 3.创建一张大图,将两张图拼接到一起
# 4.将结果输出
h1, w1 = img1.shape[:2] # 获得原始图的高和宽
h2, w2 = img2.shape[:2]
img1_dims = np.float32([[0, 0], [0, h1], [w1, h1], [w1, 0]]).reshape(-1, 1, 2) # 四个角点逆时针进行排序
img2_dims = np.float32([[0, 0], [0, h2], [w2, h2], [w2, 0]]).reshape(-1, 1, 2)
# 图像变换
img1_transform = cv2.perspectiveTransform(img1_dims, H)
# print(img1_dims)
# print(img2_dims)
# print(img1_transform)
result_dims = np.concatenate((img2_dims, img1_transform), axis=0) # 横向拼接,主要是为了求出图像的最大值最小值
# print(result_dims) # 混合后的结果
[x_min, y_min] = np.int32(
result_dims.min(axis=0).ravel() - 0.5) # axis=0按x轴获取数值,ravel()将二维变为一维,根据四舍五入的原则,最小值-0.5,最大值+0.5
[x_max, y_max] = np.int32(result_dims.max(axis=0).ravel() + 0.5)
# 平移的距离
transform_dist = [-x_min, -y_min] # 最小的x距离和y
# [1, 0, dx]
# [0, 1, dy]
# [0, 0, 1 ]
# 矩阵平移的方法,乘以一个齐次矩阵
transform_array = np.array([[1, 0, transform_dist[0]],
[0, 1, transform_dist[1]],
[0, 0, 1]])
# 投影变换
result_img = cv2.warpPerspective(img1, transform_array.dot(H), (x_max - x_min, y_max - y_min))
result_img[transform_dist[1]:transform_dist[1] + h2,
transform_dist[0]:transform_dist[0] + w2] = img2
return result_img
# 第三步,根据单应性矩阵对图像进行变换,然后平移
result_image = stitch_image(img1, img2, H) # 进行图像拼接
5、拼接并输出最终结果(完整代码)
import cv2
import numpy as np
def stitch_image(img1, img2, H):
# 1.获得每张图片的4个角点
# 2.对图片进行变换,通过单应性矩阵使图像进行旋转,然后进行平移
# 3.创建一张大图,将两张图拼接到一起
# 4.将结果输出
h1, w1 = img1.shape[:2] # 获得原始图的高和宽
h2, w2 = img2.shape[:2]
img1_dims = np.float32([[0, 0], [0, h1], [w1, h1], [w1, 0]]).reshape(-1, 1, 2) # 四个角点逆时针进行排序
img2_dims = np.float32([[0, 0], [0, h2], [w2, h2], [w2, 0]]).reshape(-1, 1, 2)
# 图像变换
img1_transform = cv2.perspectiveTransform(img1_dims, H)
print(img1_dims)
print(img2_dims)
print(img1_transform)
result_dims = np.concatenate((img2_dims, img1_transform), axis=0) # 横向拼接,主要是为了求出图像的最大值最小值
print(result_dims) # 混合后的结果
[x_min, y_min] = np.int32(
result_dims.min(axis=0).ravel() - 0.5) # axis=0按x轴获取数值,ravel()将二维变为一维,根据四舍五入的原则,最小值-0.5,最大值+0.5
[x_max, y_max] = np.int32(result_dims.max(axis=0).ravel() + 0.5)
# 平移的距离
transform_dist = [-x_min, -y_min] # 最小的x距离和y
# [1, 0, dx]
# [0, 1, dy]
# [0, 0, 1 ]
# 矩阵平移的方法,乘以一个齐次矩阵
transform_array = np.array([[1, 0, transform_dist[0]],
[0, 1, transform_dist[1]],
[0, 0, 1]])
# 投影变换
result_img = cv2.warpPerspective(img1, transform_array.dot(H), (x_max - x_min, y_max - y_min))
result_img[transform_dist[1]:transform_dist[1] + h2,
transform_dist[0]:transform_dist[0] + w2] = img2
return result_img
# 计算单应性矩阵的方法
def get_homo(img1, img2):
# 1.创建特征转换对象
sift = cv2.xfeatures2d.SIFT_create()
# 2.通过特征转换对象获得特征点和描述子
k1, d1 = sift.detectAndCompute(img1, None) # k1为特征点,d1为描述子
k2, d2 = sift.detectAndCompute(img2, None)
# 3.创建特征匹配
# 4.进行特征匹配
# 5.过滤特征,找出有效的特征匹配点
bf = cv2.BFMatcher() # 采用暴力特征匹配
matches = bf.knnMatch(d1, d2, k=2) # 匹配特征点
verify_ratio = 0.8 # 过滤
verify_matches = []
for m1, m2 in matches: # m1,m2之间的距离越小越好,小于0.8认为有效,大于0.8无效
if m1.distance < verify_ratio * m2.distance:
verify_matches.append(m1)
# 最小匹配数
min_matches = 8
if len(verify_matches) > min_matches:
img1_pts = []
img2_pts = []
for m in verify_matches:
img1_pts.append(k1[m.queryIdx].pt) # 图像1的坐标特征点
img2_pts.append(k2[m.trainIdx].pt) # 图像2的坐标特征点
# [(x1, y1), (x2, y2), ...]
# [[x1, y1], [x2, y2], ...]
img1_pts = np.float32(img1_pts).reshape(-1, 1, 2) # 适应findHomography的格式
img2_pts = np.float32(img2_pts).reshape(-1, 1, 2)
H, mask = cv2.findHomography(img1_pts, img2_pts, cv2.RANSAC, 5.0) # 获取单应性矩阵
return H
else:
print('error: Not enough matches!')
exit()
# 第一步,读取文件,将图片设置成一样大小,640*480(跟实际图像最接近的尺寸)
img1 = cv2.imread('../resource/hill_left.png')
img2 = cv2.imread('../resource/hill_right.png')
img1 = cv2.resize(img1, (640, 480))
img2 = cv2.resize(img2, (640, 480))
# cv2.imshow('Hill', np.hstack((img1, img2)))
# 第二步,找特征点,计算描述子,计算单应性矩阵
H = get_homo(img1, img2) # 获得单应性矩阵
# 第三步,根据单应性矩阵对图像进行变换,然后平移
result_image = stitch_image(img1, img2, H) # 进行图像拼接
# 第四步,拼接并输出最终结果
cv2.imshow('input img', result_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
