高级数据结构——海量数据(位图,布隆过滤器)
目录
- 位图
-
- 位图介绍
- 位图代码实现
- 布隆过滤器
-
- 布隆过滤器介绍
- 布隆过滤器代码实现
- 布隆过滤器的优缺点
- 海量数据相关题目
位图
位图介绍
位图(bitmap),适用于存储海量,非负整数,不重复的数据.假设我们用int数组来存放数据,1GB相当于是10亿字节,那么当存储40亿整形数据时,一个整形数据占用4个字节,因此一共需要40*4/10=16G,而16G远远超过了普通电脑的内存.而用位图存储40亿整形数据时,因为1个bit来存储1个数据,因此只需要16/4/8=0.5G
此次位图的介绍采用的是byte数组,因此位图中1个元素实际上能够存储的元素个数为8(1byte = 8bit)
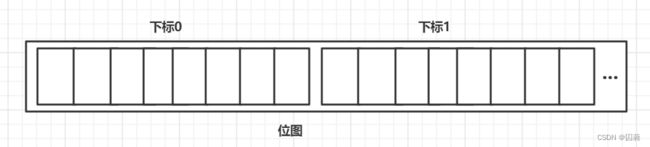
假设我们要存储的数据为3,7,11,14.那么我们首先需要将数据定位到某一个具体的下标里,我们可以通过除8来实现,之后我们需要将数据定位到某1位上,我们可以通过模8来实现
那么如何通过代码将11这个元素存储到具体的位置上?可以通过与运算得到
int arrIndex = val / 8; // 下标
int bitIndex = val % 8; // 位
bitSet[arrIndex] |= (1<< bitIndex); // 通过与运算实现存储
位图代码实现
public class MyBitSet {
// 1byte == 8bit,因此一个byte可以存放8个元素
private byte[] bitSet;
private int userSize;
public MyBitSet(){
this.bitSet = new byte[1];
}
public MyBitSet(int n){
// 这里进行初始化时存放n个元素实际上只需要(n/8+(byte)1)个大小
this.bitSet = new byte[n/8+(byte)1];
}
public byte[] getBitSet() {
return bitSet;
}
public void setBitSet(byte[] bitSet) {
this.bitSet = bitSet;
}
public int getUserSize() {
return userSize;
}
public void setUserSize(int userSize) {
this.userSize = userSize;
}
public void set(int val){
if(val < 0){
throw new IndexOutOfBoundsException();
}
int arrIndex = val / 8;
// bitmap空间不够时进行2倍扩容
while(arrIndex >= bitSet.length){
bitSet = Arrays.copyOf(bitSet,2*bitSet.length);
}
int bitIndex = val % 8;
// 对元素进行存储
bitSet[arrIndex] |= (1<< bitIndex);
userSize++;
}
public boolean get(int val){
if(val < 0){
throw new IndexOutOfBoundsException();
}
int arrIndex = val / 8;
int bitIndex = val % 8;
// 获取某个位上的元素的逻辑和存储元素的逻辑一致
return ((bitSet[arrIndex] >> bitIndex) & 1) != 0;
}
public int getSize(){
return userSize;
}
/**
* 去除掉位图上的某个元素
* @param val
*/
public void reSet(int val){
if(val < 0){
throw new IndexOutOfBoundsException();
}
int arrayIndex = val / 8;
int bitIndex = val % 8;
if((bitSet[arrayIndex] & (1 << bitIndex)) != 0){
userSize--;
}
bitSet[arrayIndex] &= ~(1 << bitIndex);
}
}
布隆过滤器
布隆过滤器介绍
布隆过滤器也是一种用于存储海量数据的数据结构,与位图相比,布隆过滤器能够存储的数据类型不仅仅是整数,还可以存储字符串.但布隆过滤器的缺点是在判断某个数据是否存在的情况时会有一定的误判率.
布隆过滤器也可以被称为是一种特殊的位图,它在普通位图的基础上通过使用多个哈希算法来将一个数据的不同哈希值存储到位图中.之所以使用多个哈希算法,是为了减少哈希的碰撞率.也正是因为哈希冲突才使得布隆过滤器在判断一个数据存在的时候会有一定的误判.
在实现布隆过滤器时,我们首先要设计几种不同的哈希算法.然后在向布隆过滤器中存储元素时,分别计算该元素的不同哈希值,然后将不同的哈希值存储到位图中,在查询某个元素是否存在时,也是查询该元素的所有哈希值是否存在,如果有1个不存在说明该元素是不存在的;如果都存在说明该元素在很大的概率上是存在的.
布隆过滤器代码实现
public class BloomFilter {
public BitSet bitSet;
public int usedSize;
SimpleHash[] simpleHashes;
static final int DEFAULT_SIZE = 1 << 16;
final int[] seeds = {5,7,11,13,17,19};
public BloomFilter(){
bitSet = new BitSet(DEFAULT_SIZE);
simpleHashes = new SimpleHash[seeds.length];
// 初始化哈希算法
for(int i = 0; i < simpleHashes.length; i++){
simpleHashes[i] = new SimpleHash(DEFAULT_SIZE,seeds[i]);
}
}
public void add(String val){
// 将该元素的所有哈希值存储到位图中
for(int i = 0; i < simpleHashes.length; i++){
int hash = simpleHashes[i].hash(val);
bitSet.set(hash);
usedSize++;
}
}
public boolean contains(String val){
// 判断该元素的所有哈希值是否都存在于位图中
for(SimpleHash s : simpleHashes){
int hash = s.hash(val);
// 如果有一个哈希值不存在,说明该元素不存在
if(!bitSet.get(hash)){
return false;
}
}
return true;
}
}
// 哈希数组
class SimpleHash{
// 位图大小
public int cap;
// 质数因子
public int seed;
public SimpleHash(int cap,int seed){
this.cap = cap;
this.seed = seed;
}
// 通过设置不同的质数因子来获得不同的哈希算法
final int hash(String key){
int h;
return (key == null) ? 0 : (seed * (cap - 1)) &((h = key.hashCode()) ^ (h >>> 16));
}
}
布隆过滤器的优缺点
- 优点
- 添加和查询元素的时间复杂度为O(k),k为哈希算法的个数
- 不需要存储数据本身,提高了数据的安全性
- 抛开一定的误判率,布隆过滤器的空间利用率比较高
- 缺点
- 存在一定的误判率
- 只能查询元素是否存在,不能获得到元素本身(哈希不可逆)
- 一般不能从布隆过滤器中删除某个元素,因为删除的某个元素的hash值可能也同时是其他元素的hash值
海量数据相关题目
- 给一个超过100G大小的log file文件,该文件中存在着IP地址,设计算法找出出现次数最多的IP地址,topK的IP地址
首先将这100G大小的文件切分成200个小文件,每个小文件的大小为0.5G,然后对IP地址求hash并对200取模将每个IP地址存储到对应的小文件中,然后分别遍历每个小文件,将每个IP地址以及其出现的次数存储到TreeMap中,通过TreeMap来获取出现次数最多的IP地址或者topK的IP地址
之所以不直接将100G大小的文件均分成200个文件,是因为文件中存储的是一个一个的IP地址,如果直接均分很可能造成一个IP地址的前半部分出现在上一个小文件中,后半部分出现在另一个小文件中. - 给定100亿个整数,设计算法找出只出现1次的整数
首先整数的范围2^32约为40亿,所以100亿个整数中肯定是有重复的数字的.
方法1:哈希切割.和问题1中的哈希切割的思路一致
方法2:使用位图- 使用2个位图
设这两个位图分为被A,B,当某个数字出现时,首先判断位图A上对应的位是否为1,如果不为1则把A上的位设为1,代表该数字出现了1次,如果A上的位为1,则判断B上对应的位是否为1,如果不为1,则把B上的位设为1,同时将A上的位设为0,代表该数字出现了2次,如果B上对应的位也为1,说明改数字出现了2次以上.
其实是利用00,01,10,11来表示数字出现的次数为0,1,2,>2 - 使用1个位图
思路和使用2个位图一致,只是在1个位图上使用2个相邻的位来表示一个数字,因此在计算下标时从除以8变为除以4,在计算位时从模8变为模4乘2.
- 使用2个位图
- 给两个文件,分别存储了100亿个整数,求两个文件中的交集
使用2个位图分别存储两个文件中的整数.存储完后同时遍历2个位图上的每一位,如果某一位上在2个位图上均为1,说明该位上对应的整数在两个文件中都出现过. - 给两个文件,分别存储了100亿个query,求两个文件中的交集,给出精准算法和近似算法
精准算法:对两个文件同时使用哈希切割,然后同时遍历两个文件对应切割的小文件
近似算法:使用布隆过滤器,先将1个文件中的query存储到布隆过滤器的位图上,然后遍历另1个文件中的query,如果该query对应的所有哈希值均在布隆过滤器上出现过,那么近似说明该query是两个文件的交集中的1个结果.