1.相关函数的讲解
image_to_data()的输出结果是表格形式,输出变量的类型依旧是字符串。
你会得到一个这样的列表['level', 'page_num', 'block_num', 'par_num', 'line_num', 'word_num', 'left', 'top', 'width', 'height', 'conf', 'text'],我们逐个解释下:
- level,当前项的层级;
- page_num,当前项所属页,一般情况下,单张图片的内容均会被分在同一个页;
- block_num ,当前项所属块,Tesseract会将图像分割为多个不同的block,block会出现1,2,3……等等值;
- par_num,当前图像中文字的段落分类;
- line_num,当前项所属行;
- word_num,为同一行中当前项所属的单词序号;
- left\ top\ width\ height,分别为当前项所在矩形区域的左上角坐标、宽度和高度;
- conf,当前检测字符的置信度,表示项无文字,值为-1,若Tesseract认为当前区域有文字,则其值得范围为0~100;
- text,即为当前项的文本,若无文字此项为空。
那么关于enumerate()函数,大家可以看看此文。
详解Python中enumerate函数的使用
2.代码展示
Detecting Words
import cv2
import pytesseract
import numpy as np
from PIL import ImageGrab
import time
pytesseract.pytesseract.tesseract_cmd = 'E:\pythonProject\Github\Tesseract-OCR\\tesseract.exe'
img = cv2.imread('1.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
##############################################
##### Detecting Words ######
##############################################
#[ 0 1 2 3 4 5 6 7 8 9 10 11 ]
#['level', 'page_num', 'block_num', 'par_num', 'line_num', 'word_num', 'left', 'top', 'width', 'height', 'conf', 'text']
boxes = pytesseract.image_to_data(img)
for a,b in enumerate(boxes.splitlines()):
print(b)
if a!=0:
b = b.split()
if len(b)==12:
x,y,w,h = int(b[6]),int(b[7]),int(b[8]),int(b[9])
cv2.putText(img,b[11],(x,y-5),cv2.FONT_HERSHEY_SIMPLEX,1,(50,50,255),2)
cv2.rectangle(img, (x,y), (x+w, y+h), (50, 50, 255), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
Detecting ONLY Digits
import cv2
import pytesseract
import numpy as np
from PIL import ImageGrab
import time
pytesseract.pytesseract.tesseract_cmd = 'E:\pythonProject\Github\Tesseract-OCR\\tesseract.exe'
img = cv2.imread('1.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
##############################################
##### Detecting ONLY Digits ######
##############################################
hImg, wImg,_ = img.shape
conf = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_boxes(img,config=conf)
for b in boxes.splitlines():
print(b)
b = b.split(' ')
print(b)
x, y, w, h = int(b[1]), int(b[2]), int(b[3]), int(b[4])
cv2.rectangle(img, (x,hImg- y), (w,hImg- h), (50, 50, 255), 2)
cv2.putText(img,b[0],(x,hImg- y+25),cv2.FONT_HERSHEY_SIMPLEX,1,(50,50,255),2)
cv2.imshow('img', img)
cv2.waitKey(0)
3.问题叙述
首先,我遇到的问题有
(1)无效的TeserAct版本:“TeserAct3.02”

可能是此版本太低了,但我找了找新的版本,在此更新一下路径:
点击此网址 Home · UB-Mannheim/tesseract Wiki · GitHub
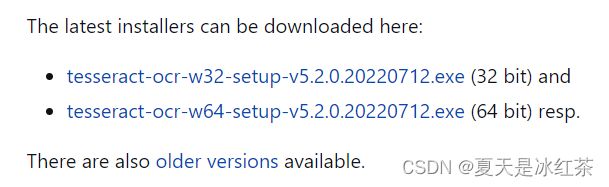
自行选择合适的就可以了。
(2)识别效果差

可以看到,将本来不是数字的字母也强行识别出来了,这简直说不过去了。
最后我们看看更改后的效果:

cool,非常的棒,快去试试吧!

对于数字又强差人意了,所以说它这个本身还是存在一点的问题。我觉得影响不大,你觉得不舒服,可以换张图试试。
4.image_to_data()配置讲解
oem讲解

OEM _ TESSERACТ_ ONLY 只以最快的速度运行Tesseract
OEM _ CUBE _ ONLY 仅运行多维数据集-精度更高,但速度更慢
OEM _ TESSERACT _ CUBE _ cOMBINED 同时运行并组合结果-最佳精度
OEM _ DEFAULT 在调用init_*0时指定此模式,以指示应根据特定于语言的配置中的变量自动推断上述任何模式。命令行配置,或者如果没有在上面任何一项中指定,则应设置为默认的OEM_ TESSERACT_ ONLY。
psm讲解
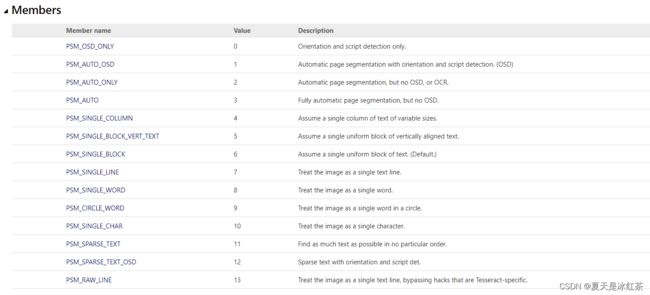
PSM _ OSD _ ONLY 仅用于方向和脚本检测。
PSM _ AUTO _ OSD 带有方向和脚本检测的自动页面分割。(OSD)
PSM _ AUTO _ ONLY 自动页面分割,但没有OSD或OCR。 PSM _ AUTO 完全自动页面分割,但没有OSD。
PSM _ SINGLE _ COLUMN 假设一列大小可变的文本。
PSM _ SINGLE _ BLOCK _ VERT _ TEXT 假设一个统一的垂直对齐文本块。
PSM _ SINGLE _ BLOCK 假设一个统一的文本块(默认值)
PSM _ SINGLE _ LINE 将图像视为单个文本行。
PSM _ SINGLE _ WORD 将图像视为单个单词。
PSM _ CIRCLE _ WORD 将图像视为圆圈中的单个单词。
PSM _ SINGLE _ CHAR 将图像视为单个字符。
PSM _ SPARSE _ TEXT 在没有特定顺序的情况下尽可能多地查找文本。
PSM _ SPARSE _ TEXT _ OSD 具有方向和脚本检测的稀疏文本。
PSM _ RAW _ LINE 将图像视为单个文本行,绕过特定于Tesseract的黑客攻击。
5.项目拓展
import cv2
import pytesseract
import numpy as np
from PIL import ImageGrab
import time
pytesseract.pytesseract.tesseract_cmd = 'E:\pythonProject\Github\Tesseract-OCR\\tesseract.exe'
img = cv2.imread('1.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
cap = cv2.VideoCapture(0)
cap.set(3,640)
cap.set(4,480)
def captureScreen(bbox=(300,300,1500,1000)):
capScr = np.array(ImageGrab.grab(bbox))
capScr = cv2.cvtColor(capScr, cv2.COLOR_RGB2BGR)
return capScr
while True:
timer = cv2.getTickCount()
_,img = cap.read()
#img = captureScreen()
#DETECTING CHARACTERES
hImg, wImg,_ = img.shape
boxes = pytesseract.image_to_boxes(img)
for b in boxes.splitlines():
#print(b)
b = b.split(' ')
#print(b)
x, y, w, h = int(b[1]), int(b[2]), int(b[3]), int(b[4])
cv2.rectangle(img, (x,hImg- y), (w,hImg- h), (50, 50, 255), 2)
cv2.putText(img,b[0],(x,hImg- y+25),cv2.FONT_HERSHEY_SIMPLEX,1,(50,50,255),2)
fps = cv2.getTickFrequency() / (cv2.getTickCount() - timer);
#cv2.putText(img, str(int(fps)), (75, 40), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (20,230,20), 2);
cv2.imshow("Result",img)
cv2.waitKey(1)
cv2.imshow('img', img)
cv2.waitKey(0)
进行网络摄像头的实时文字测试。
6.总结与评价
我是首次使用Tesseract,体验感很不好,这是我在b站的评论中看到的:
![]()
说实话,我还没有学到用算法的地步,学学了解一下就好了,反正我是准备项目实战的中后期去学习深度学习,以及其他的算法学习,这方面我不好说,但它的精度的确是不达标,你们也看到了,居然把文字也识别成了数字。而且开启摄像头识别的也不是很好,识别不完全or识别错误。
以上就是Python Opencv实战之文字检测OCR的详细内容,更多关于Python Opencv文字检测的资料请关注脚本之家其它相关文章!